
Setelah menerapkan TensorFlow Serving dan mengeluarkan permintaan dari klien, Anda mungkin menyadari bahwa permintaan membutuhkan waktu lebih lama dari yang diharapkan, atau Anda tidak mencapai throughput yang diinginkan.
Dalam panduan ini, kami akan menggunakan Profiler TensorBoard, yang mungkin sudah Anda gunakan untuk membuat profil pelatihan model , untuk melacak permintaan inferensi guna membantu kami melakukan debug dan meningkatkan kinerja inferensi.
Anda harus menggunakan panduan ini bersama dengan praktik terbaik yang ditunjukkan dalam Panduan Performa untuk mengoptimalkan model, permintaan, dan instance TensorFlow Serving Anda.
Ringkasan
Pada tingkat tinggi, kami akan mengarahkan alat Profil TensorBoard ke server gRPC TensorFlow Serving. Saat kami mengirimkan permintaan inferensi ke Tensorflow Serving, kami juga akan menggunakan UI TensorBoard secara bersamaan untuk memintanya menangkap jejak permintaan ini. Di balik layar, TensorBoard akan berkomunikasi dengan TensorFlow Serving melalui gRPC dan memintanya memberikan jejak mendetail tentang masa berlaku permintaan inferensi. TensorBoard kemudian akan memvisualisasikan aktivitas setiap thread di setiap perangkat komputasi (menjalankan kode yang terintegrasi dengan profiler::TraceMe ) selama masa permintaan di UI TensorBoard untuk kita konsumsi.
Prasyarat
-
Tensorflow>=2.0.0 - TensorBoard (harus dipasang jika TF dipasang melalui
pip) - Docker (yang akan kita gunakan untuk mengunduh dan menjalankan TF serve>=2.1.0 image)
Terapkan model dengan TensorFlow Serving
Untuk contoh ini, kita akan menggunakan Docker, cara yang disarankan untuk menerapkan Tensorflow Serving, untuk menghosting model mainan yang menghitung f(x) = x / 2 + 2 yang ditemukan di repositori Tensorflow Serving Github .
Unduh sumber TensorFlow Serving.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
Luncurkan TensorFlow Serving melalui Docker dan terapkan model half_plus_two.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
Di terminal lain, buat kueri model untuk memastikan model diterapkan dengan benar
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
Siapkan Profiler TensorBoard
Di terminal lain, luncurkan alat TensorBoard di mesin Anda, yang menyediakan direktori untuk menyimpan peristiwa pelacakan inferensi ke:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
Navigasikan ke http://localhost:6006/ untuk melihat UI TensorBoard. Gunakan menu tarik-turun di bagian atas untuk menavigasi ke tab Profil. Klik Ambil Profil dan berikan alamat server gRPC Tensorflow Serving.
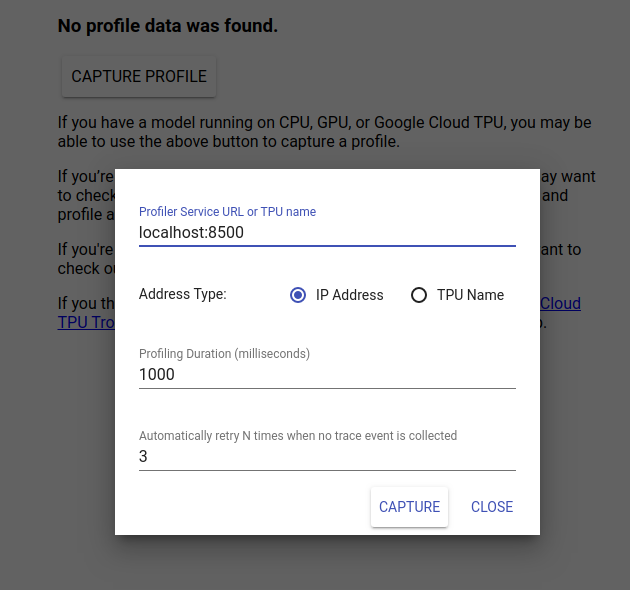
Segera setelah Anda menekan "Capture", TensorBoard akan mulai mengirimkan permintaan profil ke server model. Dalam dialog di atas, Anda dapat menetapkan tenggat waktu untuk setiap permintaan dan berapa kali Tensorboard akan mencoba ulang jika tidak ada peristiwa pelacakan yang dikumpulkan. Jika Anda membuat profil model yang mahal, Anda mungkin ingin menambah tenggat waktu untuk memastikan permintaan profil tidak habis waktunya sebelum permintaan inferensi selesai.
Kirim dan Profil Permintaan Inferensi
Tekan Tangkap di UI TensorBoard dan kirimkan permintaan inferensi ke TF Serving dengan cepat setelahnya.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
Anda akan melihat pesan "Tangkap profil berhasil. Harap segarkan." roti panggang muncul di bagian bawah layar. Ini berarti TensorBoard dapat mengambil peristiwa pelacakan dari TensorFlow Serving dan menyimpannya ke logdir Anda. Segarkan halaman untuk memvisualisasikan permintaan inferensi dengan Penampil Jejak Profiler, seperti yang terlihat di bagian berikutnya.
Analisis Jejak Permintaan Inferensi

Anda sekarang dapat dengan mudah melihat penghitungan apa yang terjadi sebagai hasil dari permintaan inferensi Anda. Anda dapat memperbesar dan mengklik salah satu persegi panjang (melacak peristiwa) untuk mendapatkan informasi lebih lanjut seperti waktu mulai yang tepat dan durasi dinding.
Pada tingkat tinggi, kita melihat dua thread milik runtime TensorFlow dan thread ketiga milik server REST, menangani penerimaan permintaan HTTP dan membuat Sesi TensorFlow.
Kita dapat memperbesar untuk melihat apa yang terjadi di dalam SessionRun.

Di thread kedua, kita melihat panggilan awal ExecutorState::Process yang tidak menjalankan operasi TensorFlow tetapi langkah inisialisasi dijalankan.
Di thread pertama, kita melihat panggilan untuk membaca variabel pertama, dan setelah variabel kedua juga tersedia, jalankan perkalian dan tambahkan kernel secara berurutan. Terakhir, Executor memberi sinyal bahwa komputasinya dilakukan dengan memanggil DoneCallback dan Sesi dapat ditutup.
Langkah Selanjutnya
Meskipun ini adalah contoh sederhana, Anda dapat menggunakan proses yang sama untuk membuat profil model yang jauh lebih kompleks, sehingga memungkinkan Anda mengidentifikasi operasi yang lambat atau hambatan dalam arsitektur model Anda untuk meningkatkan kinerjanya.
Silakan lihat Panduan Profiler TensorBoard untuk tutorial lebih lengkap tentang fitur Profiler TensorBoard dan Panduan Performa Penyajian TensorFlow untuk mempelajari lebih lanjut cara mengoptimalkan performa inferensi.