
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش به بررسی یادگیری فدرال تا حدی محلی، که در آن برخی از پارامترهای مشتری هرگز بر روی سرور جمع شده است. این برای مدلهایی با پارامترهای خاص کاربر (مثلاً مدلهای فاکتورسازی ماتریسی) و برای آموزش تنظیمات محدود به ارتباط مفید است. ما در مفاهیم در معرفی ساخت آموزش فدرال برای تصویر طبقه بندی آموزش. به عنوان در آن آموزش، API های سطح بالا را معرفی می کنیم در tff.learning برای آموزش فدرال و ارزیابی است.
ما با انگیزه یادگیری فدرال تا حدی محلی برای آغاز فاکتور ماتریس . ما توصیف فدرال بازسازی ، یک الگوریتم عملی برای یادگیری فدرال تا حدی محلی در مقیاس. ما مجموعه داده MovieLens 1M را آماده می کنیم، یک مدل جزئی محلی می سازیم و آن را آموزش می دهیم و ارزیابی می کنیم.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
زمینه: فاکتورسازی ماتریسی
ماتریس فاکتور شده است روش تاریخی محبوب برای توصیه های یادگیری و تعبیه تضمینی برای اقلام بر اساس فعل و انفعالات کاربر بوده است. مثال متعارف توصیه فیلم است، که در آن وجود دارد \(n\) کاربران و \(m\) فیلم، و کاربران برخی از فیلم امتیاز داده اند. با توجه به یک کاربر، از تاریخچه رتبهبندی او و رتبهبندی کاربران مشابه برای پیشبینی رتبهبندی کاربر برای فیلمهایی که ندیدهاند استفاده میکنیم. اگر مدلی داشته باشیم که بتواند رتبهبندیها را پیشبینی کند، به راحتی میتوان فیلمهای جدیدی را به کاربران توصیه کرد که از آن لذت ببرند.
برای این کار، آن را مفید برای نشان امتیازات کاربران به عنوان یک \(n \times m\) ماتریس \(R\):

این ماتریس عموماً پراکنده است، زیرا کاربران معمولاً تنها بخش کوچکی از فیلمهای موجود در مجموعه داده را میبینند. خروجی فاکتور ماتریس دو ماتریس است: یک \(n \times k\) ماتریس \(U\) نمایندگی \(k\)درونه گیریها کاربران بعدی برای هر کاربر، و \(m \times k\) ماتریس \(I\) نمایندگی \(k\)درونه گیریها مورد بعدی برای هر مورد. ساده ترین هدف آموزش این است که محصول از نقطه کاربر و مورد درونه گیریها پیش بینی از رتبه های مشاهده شده می \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
این معادل به حداقل رساندن میانگین مربعات خطا بین رتبهبندیهای مشاهدهشده و رتبهبندیهای پیشبینیشده با گرفتن حاصل ضرب نقطهای کاربر مربوطه و جاسازیهای آیتم است. راه دیگر برای تفسیر این است که این تضمین می کند که \(R \approx UI^T\) برای رتبه بندی شناخته شده است، از این رو "فاکتور ماتریس". اگر این گیج کننده است، نگران نباشید – برای بقیه آموزش نیازی به دانستن جزئیات فاکتورسازی ماتریس نخواهیم بود.
کاوش داده های MovieLens
بیایید با بارگذاری شروع MovieLens 1M داده، که متشکل از 1،000،209 رتبه بندی فیلم از کاربران 6040 در 3706 فیلم.
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
بیایید چند Pandas DataFrame را بارگیری و کاوش کنیم که حاوی دادههای رتبهبندی و فیلم است.
ratings_df, movies_df = load_movielens_data()
می بینیم که هر نمونه رتبه بندی دارای یک رتبه بندی از 1-5، یک UserID مربوطه، یک MovieID مربوطه، و یک مهر زمانی است.
ratings_df.head()
هر فیلم یک عنوان و ژانرهای بالقوه متعدد دارد.
movies_df.head()
همیشه ایده خوبی است که آمار اولیه مجموعه داده را درک کنید:
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
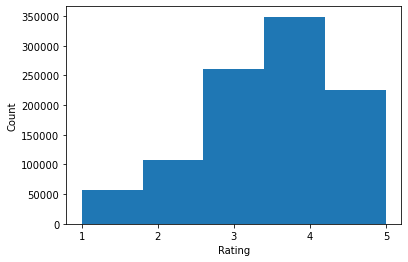
Average rating: 3.581564453029317 Median rating: 4.0
ما همچنین می توانیم محبوب ترین ژانرهای فیلم را ترسیم کنیم.
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
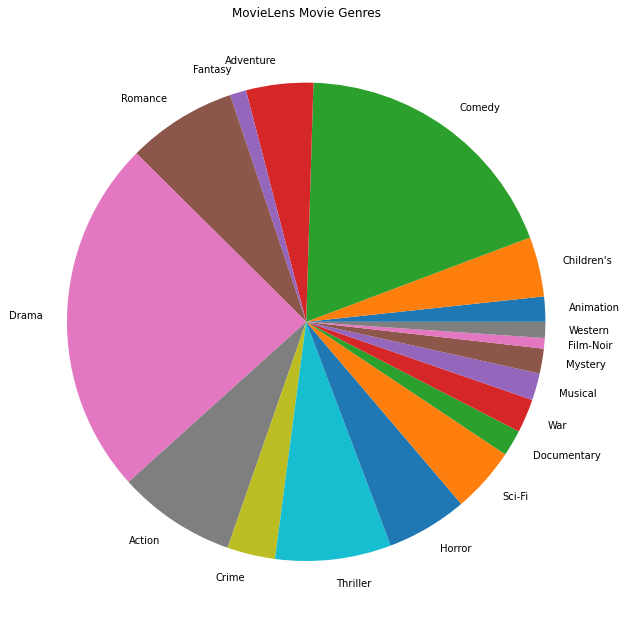
این دادهها بهطور طبیعی به رتبهبندیهای کاربران مختلف تقسیم میشوند، بنابراین انتظار داریم ناهمگونی در دادهها بین مشتریان وجود داشته باشد. در زیر متداول ترین ژانرهای فیلم را برای کاربران مختلف نمایش می دهیم. ما می توانیم تفاوت های قابل توجهی را بین کاربران مشاهده کنیم.
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
پیش پردازش داده های MovieLens
حال به سراغ مجموعه داده MovieLens عنوان یک لیست از آماده tf.data.Dataset بازدید کنندگان به نمایندگی از داده های هر کاربر را برای استفاده با TFF.
ما دو تابع را اجرا می کنیم:
-
create_tf_datasets: رتبه بندی ما DataFrame طول می کشد و یک لیست از کاربر تقسیم تولیدtf.data.Datasetاست. -
split_tf_datasets: یک لیست از مجموعه داده ها و تجزیه آنها را به قطار / وال / آزمون توسط کاربر، به طوری که وال / مجموعه آزمون شامل تنها رأی از کاربران در طول آموزش نهان. به طور معمول در استاندارد فاکتور ماتریس متمرکز ما در واقع تقسیم به طوری که مجموعه وال / آزمون شامل رتبه های برگزار کردن از کاربران دیده می شود، از آنجایی که کاربران نهان انجام درونه گیریها کاربران ندارد. در مورد ما، بعداً خواهیم دید که رویکردی که برای فعال کردن فاکتورسازی ماتریس در FL استفاده میکنیم، امکان بازسازی سریع جاسازیهای کاربر را برای کاربران نادیده نیز فراهم میکند.
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
به عنوان یک بررسی سریع، می توانیم دسته ای از داده های آموزشی را چاپ کنیم. میتوانیم ببینیم که هر مثال جداگانه حاوی یک MovieID در زیر کلید "x" و یک رتبه بندی در زیر کلید "y" است. توجه داشته باشید که ما به UserID نیاز نخواهیم داشت زیرا هر کاربر فقط داده های خود را می بیند.
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
ما می توانیم یک هیستوگرام را رسم کنیم که تعداد رتبه بندی های هر کاربر را نشان می دهد.
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
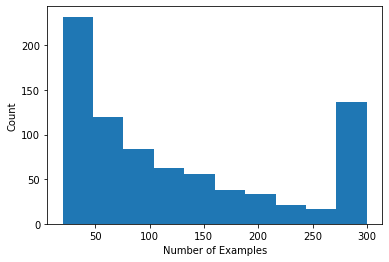
اکنون که داده ها را بارگیری و بررسی کردیم، در مورد چگونگی آوردن فاکتورسازی ماتریس به یادگیری فدرال بحث خواهیم کرد. در طول راه، ما انگیزه یادگیری فدرال تا حدی محلی را خواهیم داشت.
آوردن فاکتورسازی ماتریس به FL
در حالی که فاکتورسازی ماتریس به طور سنتی در تنظیمات متمرکز استفاده میشود، به ویژه در یادگیری فدرال مرتبط است: رتبهبندیهای کاربر ممکن است در دستگاههای مشتری جداگانه وجود داشته باشد، و ممکن است بخواهیم جاسازیها و توصیههایی را برای کاربران و موارد بدون متمرکز کردن دادهها یاد بگیریم. از آنجایی که هر کاربر یک جاسازی کاربر مربوطه دارد، طبیعی است که هر کلاینت جاسازی کاربر خود را ذخیره کند - این مقیاس بسیار بهتر از یک سرور مرکزی است که همه جاسازیهای کاربر را ذخیره میکند.
یک پیشنهاد برای آوردن فاکتورسازی ماتریس به FL به شرح زیر است:
- فروشگاه سرور و ماتریس مورد می فرستد \(I\) به مشتریان نمونه هر دور
- مشتریان به روز رسانی ماتریس مورد و کاربر شخصی خود تعبیه \(U_u\) با استفاده از SGD در به هدف فوق
- به روز رسانی به \(I\) بر روی سرور جمع آوری شده، به روز رسانی نسخه سرور از \(I\) برای دور بعدی
این رویکرد تا حدی محلی یعنی، برخی از پارامترهای مشتری هرگز توسط سرور جمع است. اگرچه این رویکرد جذاب است، اما مشتریان را ملزم میکند که وضعیت را در هر دور، یعنی جاسازیهای کاربر خود، حفظ کنند. الگوریتمهای فدرال حالت برای تنظیمات FL بین دستگاهی کمتر مناسب هستند: در این تنظیمات اندازه جمعیت اغلب بسیار بیشتر از تعداد کلاینتهایی است که در هر دور شرکت میکنند، و یک کلاینت معمولاً حداکثر یک بار در طول فرآیند آموزش شرکت میکند. علاوه بر این با تکیه بر دولت که ممکن است مقدار دهی اولیه می شود، الگوریتم stateful به می تواند در تخریب عملکرد در تنظیمات متقابل دستگاه با توجه به دولت کهنه در نتیجه هنگامی که مشتریان به ندرت نمونه. نکته مهم این است که در تنظیمات فاکتورسازی ماتریس، یک الگوریتم حالتی منجر به این میشود که همه کلاینتهای دیده نشده جاسازیهای کاربر آموزشدیده را از دست بدهند، و در آموزش در مقیاس بزرگ، اکثر کاربران ممکن است دیده نشوند. برای اطلاعات بیشتر در انگیزه برای الگوریتم های بدون تابعیت در متقابل دستگاه FL، و وانگ و همکاران 2021 ثانیه 3.1.1 و Reddi و همکاران 2020 ثانیه 5.1 .
فدرال بازسازی ( سینگال و همکاران 2021 ) یک جایگزین بدون تابعیت به روش فوق است. ایده کلیدی این است که به جای ذخیره سازی جاسازی های کاربر در هر دور، مشتریان در صورت نیاز جاسازی های کاربر را بازسازی می کنند. هنگامی که FedRecon برای فاکتورسازی ماتریس اعمال می شود، آموزش به صورت زیر پیش می رود:
- فروشگاه سرور و ماتریس مورد می فرستد \(I\) به مشتریان نمونه هر دور
- هر مشتری یخ \(I\) و آموزش کاربران خود تعبیه \(U_u\) با استفاده از یک یا چند مرحله از SGD (بازسازی)
- هر مشتری یخ \(U_u\) و قطار \(I\) با استفاده از یک یا چند مرحله از SGD
- به روز رسانی به \(I\) در سراسر کاربران جمع آوری شده، به روز رسانی نسخه سرور از \(I\) برای دور بعدی
این رویکرد به مشتری نیازی به حفظ حالت در سراسر دور ندارد. نویسندگان همچنین در مقاله نشان میدهند که این روش منجر به بازسازی سریع جاسازیهای کاربر برای مشتریان نادیده میشود (بخش 4.2، شکل 3، و جدول 1)، به اکثر مشتریانی که در آموزش شرکت نمیکنند، اجازه میدهد یک مدل آموزشدیده داشته باشند. ، توصیه هایی را برای این مشتریان فعال می کند.
تعریف مدل
در مرحله بعد مدل فاکتورسازی ماتریس محلی را برای آموزش در دستگاه های مشتری تعریف می کنیم. این مدل شامل کامل ماتریس مورد \(I\) و یک تعبیه کاربران \(U_u\) برای مشتری \(u\). توجه داشته باشید که مشتریان نمی خواهد نیاز به ذخیره کامل ماتریس کاربران \(U\).
موارد زیر را تعریف می کنیم:
-
UserEmbedding: یک لایه ساده Keras نمایندگی یکnum_latent_factorsتعبیه کاربران بعدی. -
get_matrix_factorization_model: یک تابع است که بازده یکtff.learning.reconstruction.Modelحاوی منطق مدل، از جمله که لایه ها در سطح جهانی بر روی سرور جمع و آن لایه های محلی باقی می ماند. ما به این اطلاعات اضافی نیاز داریم تا فرآیند آموزش بازسازی فدرال را آغاز کنیم. در اینجا ما تولیدtff.learning.reconstruction.Modelاز یک مدل با استفاده از Kerastff.learning.reconstruction.from_keras_model. مشابه بهtff.learning.Model، ما نیز می تواند سفارشی پیاده سازیtff.learning.reconstruction.Modelبا اجرای رابط طبقاتی.
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
مثابه به رابط برای متوسط فدرال، رابط کاربری را برای فدرال بازسازی انتظار model_fn بدون آرگومان که بازده یک tff.learning.reconstruction.Model .
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
که در ادامه خواهیم تعریف loss_fn و metrics_fn ، که در آن loss_fn یک تابع بدون آرگومان بازگشت از دست دادن Keras به استفاده از آموزش مدل است و metrics_fn یک تابع بدون آرگومان بازگشت یک لیست از معیارهای Keras برای ارزیابی است. اینها برای ساخت محاسبات آموزشی و ارزیابی مورد نیاز هستند.
همانطور که در بالا ذکر شد، از میانگین مربعات خطا به عنوان ضرر استفاده خواهیم کرد. برای ارزیابی، از دقت رتبهبندی استفاده میکنیم (زمانی که حاصل ضرب نقطهای پیشبینیشده مدل به نزدیکترین عدد کامل گرد شود، هر چند وقت یکبار با رتبهبندی برچسب مطابقت دارد؟).
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
آموزش و ارزشیابی
اکنون همه چیزهایی که برای تعریف فرآیند آموزش نیاز داریم در اختیار داریم. یکی از تفاوت های مهم را از رابط کاربری را برای به طور متوسط فدرال است که ما در حال حاضر در یک پاس reconstruction_optimizer_fn ، که هنگامی که بازسازی پارامترهای محلی (در مورد ما، درونه گیریها کاربر) استفاده خواهد شد. به طور کلی منطقی به استفاده از SGD در اینجا، با مشابه و یا کمی کاهش نرخ یادگیری از مشتری بهینه ساز نرخ یادگیری است. ما یک پیکربندی کاری را در زیر ارائه می دهیم. این به دقت تنظیم نشده است، پس با خیال راحت با مقادیر مختلف بازی کنید.
اتمام مستندات برای جزئیات بیشتر و گزینه های بیشتر.
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
ما همچنین می توانیم یک محاسبات برای ارزیابی مدل جهانی آموزش دیده خود تعریف کنیم.
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
می توانیم حالت فرآیند آموزش را مقداردهی اولیه کرده و آن را بررسی کنیم. مهمتر از همه، میتوانیم ببینیم که این حالت سرور فقط متغیرهای آیتم را ذخیره میکند (در حال حاضر به صورت تصادفی مقداردهی اولیه شده است) و نه تعبیههای کاربر.
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
ما همچنین میتوانیم سعی کنیم مدل بهطور تصادفی اولیهشده خود را روی مشتریان اعتبارسنجی ارزیابی کنیم. ارزیابی بازسازی فدرال در اینجا شامل موارد زیر است:
- سرور ماتریس مورد می فرستد \(I\) به مشتریان ارزیابی نمونه
- هر مشتری یخ \(I\) و آموزش کاربران خود تعبیه \(U_u\) با استفاده از یک یا چند مرحله از SGD (بازسازی)
- هر مشتری از دست دادن محاسبه و معیارهای استفاده از سرور \(I\) و بازسازی \(U_u\) در یک بخش دیده نشده از داده های محلی خود
- تلفات و معیارها در بین کاربران به طور میانگین برای محاسبه ضرر و معیارهای کلی محاسبه می شود
توجه داشته باشید که مراحل 1 و 2 مانند آموزش است. این اتصال مهم است، از آموزش به همان شیوه ما منجر ارزیابی به صورت متا یادگیری، و یا یادگیری چگونگی یادگیری. در این مورد، مدل در حال یادگیری نحوه یادگیری متغیرهای سراسری (ماتریس آیتم) است که منجر به بازسازی عملکردی متغیرهای محلی (جاسازیهای کاربر) میشود. برای اطلاعات بیشتر در این، و ثانیه. 4.2 از مقاله است.
همچنین برای اطمینان از ارزیابی منصفانه، انجام مراحل 2 و 3 با استفاده از بخشهای مجزا از دادههای محلی مشتریان مهم است. بهطور پیشفرض، هم فرآیند آموزش و هم محاسبات ارزیابی از هر مثال دیگری برای بازسازی استفاده میکنند و از نیمه دیگر پس از بازسازی استفاده میکنند. این رفتار را می توان با استفاده از سفارشی dataset_split_fn استدلال (ما این بیشتر بعد کشف).
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
بعداً میتوانیم یک دور تمرین را اجرا کنیم. برای واقعیتر کردن موارد، 50 مشتری را در هر دور بهطور تصادفی و بدون جایگزینی نمونهگیری میکنیم. ما همچنان باید انتظار داشته باشیم که معیارهای قطار ضعیف باشد، زیرا ما فقط یک دوره آموزشی را انجام می دهیم.
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
حالا بیایید یک حلقه آموزشی برای تمرین در چندین دور راه اندازی کنیم.
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
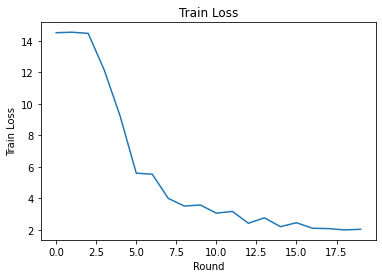
ما می توانیم از دست دادن و دقت تمرین را در طول راند ترسیم کنیم. فراپارامترهای این نوت بوک به دقت تنظیم نشده اند، بنابراین برای بهبود این نتایج، کلاینت های مختلف در هر دور، نرخ یادگیری، تعداد دورها و تعداد کل مشتریان را امتحان کنید.
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
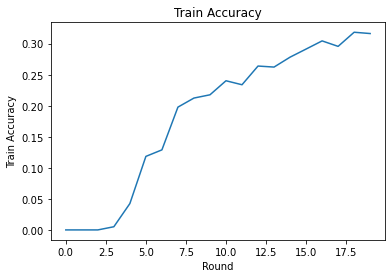
در نهایت، میتوانیم پس از اتمام تنظیم، معیارها را روی یک مجموعه آزمایشی نادیده محاسبه کنیم.
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
کاوش های بیشتر
کار خوبی برای تکمیل این دفترچه یادداشت. ما تمرینهای زیر را برای بررسی بیشتر یادگیری فدرال محلی که تقریباً با افزایش دشواری ترتیب داده شدهاند، پیشنهاد میکنیم:
پیادهسازیهای معمول میانگینسازی فدرال چندین پاس محلی (دوران) روی دادهها میگیرند (علاوه بر این که یک پاس از دادهها در چندین دسته انجام میدهند). برای بازسازی فدرال ممکن است بخواهیم تعداد مراحل را به طور جداگانه برای آموزش بازسازی و پس از بازسازی کنترل کنیم. عبور از
dataset_split_fnاستدلال به آموزش و ارزیابی سازندگان محاسبات قادر می سازد کنترل از تعداد مراحل و دوره بیش از هر دو بازسازی و پس از بازسازی مجموعه داده. به عنوان یک تمرین، سعی کنید 3 دوره محلی آموزش بازسازی را با 50 مرحله و 1 دوره محلی آموزش پس از بازسازی با 50 مرحله انجام دهید. نکته: شما پیدا کردنtff.learning.reconstruction.build_dataset_split_fnمفید است. هنگامی که این کار را انجام دادید، سعی کنید این هایپرپارامترها و سایر موارد مرتبط مانند نرخ یادگیری و اندازه دسته را تنظیم کنید تا نتایج بهتری بگیرید.رفتار پیشفرض آموزش و ارزیابی بازسازی فدرال این است که دادههای محلی مشتریان را برای هر یک از بازسازی و پس از بازسازی به نصف تقسیم میکند. در مواردی که مشتریان داده های محلی بسیار کمی دارند، استفاده مجدد از داده ها برای بازسازی و پس از بازسازی فقط برای فرآیند آموزشی (نه برای ارزیابی، این امر منجر به ارزیابی ناعادلانه می شود) منطقی است. سعی کنید این تغییر برای فرآیند آموزش، حصول اطمینان از
dataset_split_fnبرای ارزیابی هنوز هم نگه می دارد بازسازی و پس از بازسازی متلاشی شدن داده ها. نکته:tff.learning.reconstruction.simple_dataset_split_fnممکن است مفید باشد.بالا، ما یک تولید
tff.learning.Modelاز یک مدل با استفاده از Kerastff.learning.reconstruction.from_keras_model. ما همچنین می توانید یک مدل سفارشی با استفاده از TensorFlow خالص 2.0 توسط پیاده سازی پیاده سازی رابط مدل . تلاش اصلاحget_matrix_factorization_modelبرای ساخت و بازگشت یک کلاس است که گسترشtff.learning.reconstruction.Model، اجرای روش های آن است. نکته: کد منبع ازtff.learning.reconstruction.from_keras_modelیک مثال از گسترش فراهم می کندtff.learning.reconstruction.Modelکلاس. همچنین به مراجعه اجرای مدل سفارشی در تصویر EMNIST آموزش طبقه بندی برای یک تمرین مشابه در درازtff.learning.Model.در این آموزش، ما انگیزه یادگیری فدرال محلی تا حدی را در زمینه فاکتورسازی ماتریس ایجاد کردهایم، جایی که ارسال جاسازیهای کاربر به سرور بهطور بیاهمیت ترجیحات کاربر را لو میدهد. همچنین میتوانیم بازسازی فدرال را در تنظیمات دیگر بهعنوان روشی برای آموزش مدلهای شخصیتر (از آنجایی که بخشی از مدل کاملاً محلی برای هر کاربر است) و در عین حال کاهش ارتباطات (از آنجایی که پارامترهای محلی به سرور ارسال نمیشوند) اعمال کنیم. به طور کلی، با استفاده از رابطی که در اینجا ارائه شده است، میتوانیم هر مدل فدرالی را که معمولاً به طور کامل آموزش داده میشود، انتخاب کنیم و در عوض متغیرهای آن را به متغیرهای سراسری و متغیرهای محلی تقسیم کنیم. به عنوان مثال بررسی شده در این مقاله فدرال بازسازی شخصی پیش بینی کلمه بعدی است: در اینجا، هر کاربر دارای مجموعه محلی خود تعبیه شده کلمه برای کلمات خارج از واژگان، را قادر می سازد که مدل را به زبان عامیانه ضبط کاربران و دستیابی به شخصی بدون ارتباط اضافی. به عنوان یک تمرین، سعی کنید (به عنوان یک مدل Keras یا یک مدل سفارشی TensorFlow 2.0) یک مدل متفاوت را برای استفاده در بازسازی فدرال اجرا کنید. یک پیشنهاد: یک مدل طبقهبندی EMNIST را با تعبیه کاربر شخصی اجرا کنید، که در آن جاسازی کاربر شخصی قبل از آخرین لایه متراکم مدل به ویژگیهای تصویر CNN متصل میشود. شما می توانید بسیاری از کد از این آموزش (به عنوان مثال استفاده مجدد
UserEmbeddingکلاس) و تصویر طبقه بندی آموزش .
اگر شما هنوز هم به دنبال بیشتر در یادگیری فدرال تا حدی محلی، چک کردن فدرال بازسازی کاغذ و منبع باز کد آزمایش .