
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Dalam panduan sebelumnya, Anda telah mempelajari tentang tensor , variabel , pita gradien , dan modul . Dalam panduan ini, Anda akan menggabungkan semua ini untuk melatih model.
TensorFlow juga menyertakan tf.Keras API , API jaringan saraf tingkat tinggi yang menyediakan abstraksi yang berguna untuk mengurangi boilerplate. Namun, dalam panduan ini, Anda akan menggunakan kelas dasar.
Mempersiapkan
import tensorflow as tf
import matplotlib.pyplot as plt
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
Memecahkan masalah pembelajaran mesin
Memecahkan masalah pembelajaran mesin biasanya terdiri dari langkah-langkah berikut:
- Dapatkan data pelatihan.
- Tentukan modelnya.
- Tentukan fungsi kerugian.
- Jalankan melalui data pelatihan, hitung kerugian dari nilai ideal
- Hitung gradien untuk kerugian itu dan gunakan pengoptimal untuk menyesuaikan variabel agar sesuai dengan data.
- Evaluasi hasil Anda.
Untuk tujuan ilustrasi, dalam panduan ini Anda akan mengembangkan model linier sederhana, \(f(x) = x * W + b\), yang memiliki dua variabel: \(W\) (bobot) dan \(b\) (bias).
Ini adalah masalah pembelajaran mesin yang paling mendasar: Mengingat \(x\) dan \(y\), coba temukan kemiringan dan offset garis melalui regresi linier sederhana .
Data
Pembelajaran yang diawasi menggunakan input (biasanya dilambangkan dengan x ) dan output (dilambangkan dengan y , sering disebut label ). Tujuannya adalah untuk belajar dari input dan output yang dipasangkan sehingga Anda dapat memprediksi nilai output dari sebuah input.
Setiap input data Anda, di TensorFlow, hampir selalu diwakili oleh tensor, dan sering kali berupa vektor. Dalam pelatihan yang diawasi, output (atau nilai yang ingin Anda prediksi) juga merupakan tensor.
Berikut adalah beberapa data yang disintesis dengan menambahkan noise Gaussian (Normal) ke titik-titik di sepanjang garis.
# The actual line
TRUE_W = 3.0
TRUE_B = 2.0
NUM_EXAMPLES = 201
# A vector of random x values
x = tf.linspace(-2,2, NUM_EXAMPLES)
x = tf.cast(x, tf.float32)
def f(x):
return x * TRUE_W + TRUE_B
# Generate some noise
noise = tf.random.normal(shape=[NUM_EXAMPLES])
# Calculate y
y = f(x) + noise
# Plot all the data
plt.plot(x, y, '.')
plt.show()
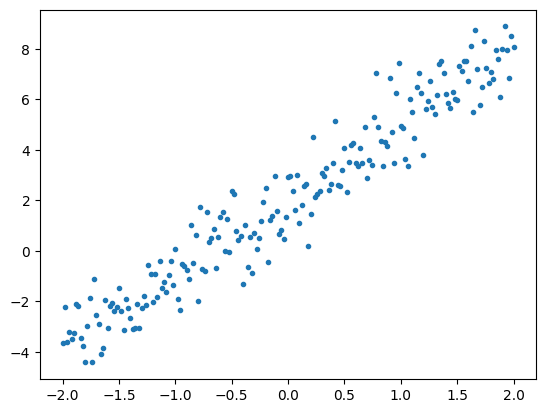
Tensor biasanya dikumpulkan bersama dalam batch , atau kelompok input dan output yang ditumpuk bersama. Batching dapat memberikan beberapa manfaat pelatihan dan bekerja dengan baik dengan akselerator dan komputasi vektor. Mengingat betapa kecilnya kumpulan data ini, Anda dapat memperlakukan seluruh kumpulan data sebagai satu kumpulan.
Tentukan modelnya
Gunakan tf.Variable untuk mewakili semua bobot dalam model. Sebuah tf.Variable menyimpan nilai dan menyediakannya dalam bentuk tensor sesuai kebutuhan. Lihat panduan variabel untuk lebih jelasnya.
Gunakan tf.Module untuk merangkum variabel dan perhitungan. Anda dapat menggunakan objek Python apa pun, tetapi dengan cara ini objek tersebut dapat disimpan dengan mudah.
Di sini, Anda mendefinisikan w dan b sebagai variabel.
class MyModel(tf.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
# Initialize the weights to `5.0` and the bias to `0.0`
# In practice, these should be randomly initialized
self.w = tf.Variable(5.0)
self.b = tf.Variable(0.0)
def __call__(self, x):
return self.w * x + self.b
model = MyModel()
# List the variables tf.modules's built-in variable aggregation.
print("Variables:", model.variables)
# Verify the model works
assert model(3.0).numpy() == 15.0
Variables: (<tf.Variable 'Variable:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'Variable:0' shape=() dtype=float32, numpy=5.0>) 2021-12-08 17:11:44.542944: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
Variabel awal diatur di sini dengan cara yang tetap, tetapi Keras hadir dengan sejumlah initalizer yang dapat Anda gunakan, dengan atau tanpa Keras lainnya.
Tentukan fungsi kerugian
Sebuah fungsi kerugian mengukur seberapa baik output dari model untuk input yang diberikan sesuai dengan output target. Tujuannya adalah untuk meminimalkan perbedaan ini selama pelatihan. Tentukan kerugian L2 standar, juga dikenal sebagai kesalahan "kuadrat rata-rata":
# This computes a single loss value for an entire batch
def loss(target_y, predicted_y):
return tf.reduce_mean(tf.square(target_y - predicted_y))
Sebelum melatih model, Anda dapat memvisualisasikan nilai kerugian dengan memplot prediksi model dengan warna merah dan data pelatihan dengan warna biru:
plt.plot(x, y, '.', label="Data")
plt.plot(x, f(x), label="Ground truth")
plt.plot(x, model(x), label="Predictions")
plt.legend()
plt.show()
print("Current loss: %1.6f" % loss(y, model(x)).numpy())
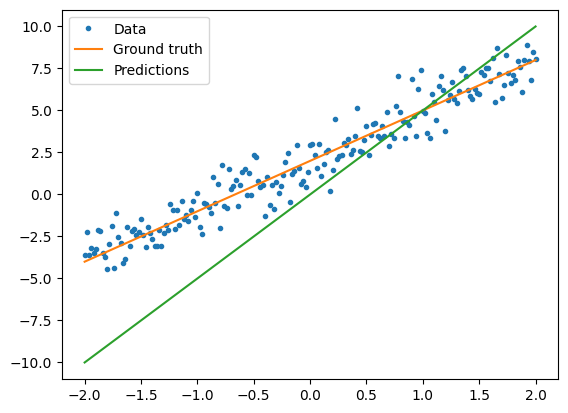
Current loss: 10.301712
Tentukan lingkaran pelatihan
Loop pelatihan terdiri dari berulang kali melakukan tiga tugas secara berurutan:
- Mengirim sekumpulan input melalui model untuk menghasilkan output
- Menghitung kerugian dengan membandingkan output ke output (atau label)
- Menggunakan pita gradien untuk menemukan gradien
- Mengoptimalkan variabel dengan gradien tersebut
Untuk contoh ini, Anda dapat melatih model menggunakan penurunan gradien .
Ada banyak varian skema penurunan gradien yang ditangkap di tf.keras.optimizers . Tetapi dengan semangat membangun dari prinsip pertama, di sini Anda akan menerapkan sendiri matematika dasar dengan bantuan tf.GradientTape untuk diferensiasi otomatis dan tf.assign_sub untuk mengurangi nilai (yang menggabungkan tf.assign dan tf.sub ):
# Given a callable model, inputs, outputs, and a learning rate...
def train(model, x, y, learning_rate):
with tf.GradientTape() as t:
# Trainable variables are automatically tracked by GradientTape
current_loss = loss(y, model(x))
# Use GradientTape to calculate the gradients with respect to W and b
dw, db = t.gradient(current_loss, [model.w, model.b])
# Subtract the gradient scaled by the learning rate
model.w.assign_sub(learning_rate * dw)
model.b.assign_sub(learning_rate * db)
Untuk melihat pelatihan, Anda dapat mengirim kumpulan x dan y yang sama melalui loop pelatihan, dan melihat bagaimana W dan b berevolusi.
model = MyModel()
# Collect the history of W-values and b-values to plot later
weights = []
biases = []
epochs = range(10)
# Define a training loop
def report(model, loss):
return f"W = {model.w.numpy():1.2f}, b = {model.b.numpy():1.2f}, loss={current_loss:2.5f}"
def training_loop(model, x, y):
for epoch in epochs:
# Update the model with the single giant batch
train(model, x, y, learning_rate=0.1)
# Track this before I update
weights.append(model.w.numpy())
biases.append(model.b.numpy())
current_loss = loss(y, model(x))
print(f"Epoch {epoch:2d}:")
print(" ", report(model, current_loss))
Lakukan pelatihan
current_loss = loss(y, model(x))
print(f"Starting:")
print(" ", report(model, current_loss))
training_loop(model, x, y)
Starting:
W = 5.00, b = 0.00, loss=10.30171
Epoch 0:
W = 4.46, b = 0.40, loss=10.30171
Epoch 1:
W = 4.06, b = 0.72, loss=10.30171
Epoch 2:
W = 3.77, b = 0.97, loss=10.30171
Epoch 3:
W = 3.56, b = 1.18, loss=10.30171
Epoch 4:
W = 3.40, b = 1.34, loss=10.30171
Epoch 5:
W = 3.29, b = 1.47, loss=10.30171
Epoch 6:
W = 3.21, b = 1.58, loss=10.30171
Epoch 7:
W = 3.15, b = 1.66, loss=10.30171
Epoch 8:
W = 3.10, b = 1.73, loss=10.30171
Epoch 9:
W = 3.07, b = 1.78, loss=10.30171
Plot evolusi bobot dari waktu ke waktu:
plt.plot(epochs, weights, label='Weights', color=colors[0])
plt.plot(epochs, [TRUE_W] * len(epochs), '--',
label = "True weight", color=colors[0])
plt.plot(epochs, biases, label='bias', color=colors[1])
plt.plot(epochs, [TRUE_B] * len(epochs), "--",
label="True bias", color=colors[1])
plt.legend()
plt.show()
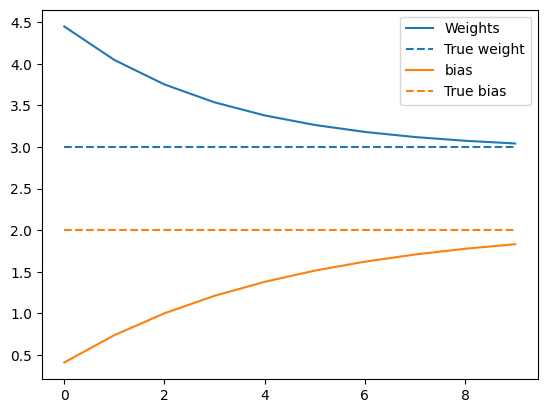
Visualisasikan bagaimana kinerja model yang terlatih
plt.plot(x, y, '.', label="Data")
plt.plot(x, f(x), label="Ground truth")
plt.plot(x, model(x), label="Predictions")
plt.legend()
plt.show()
print("Current loss: %1.6f" % loss(model(x), y).numpy())
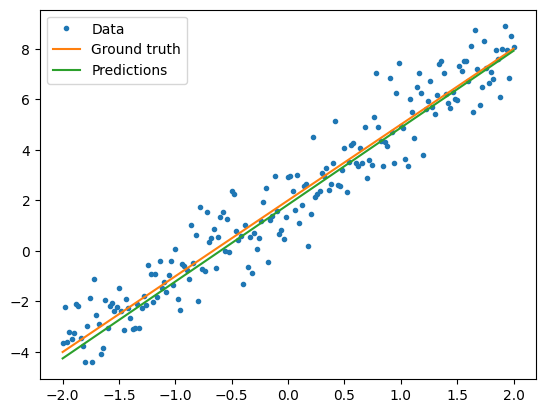
Current loss: 0.897898
Solusi yang sama, tetapi dengan Keras
Sangat berguna untuk membedakan kode di atas dengan yang setara di Keras.
Mendefinisikan model terlihat persis sama jika Anda tf.keras.Model . Ingatlah bahwa model Keras pada akhirnya mewarisi dari modul.
class MyModelKeras(tf.keras.Model):
def __init__(self, **kwargs):
super().__init__(**kwargs)
# Initialize the weights to `5.0` and the bias to `0.0`
# In practice, these should be randomly initialized
self.w = tf.Variable(5.0)
self.b = tf.Variable(0.0)
def call(self, x):
return self.w * x + self.b
keras_model = MyModelKeras()
# Reuse the training loop with a Keras model
training_loop(keras_model, x, y)
# You can also save a checkpoint using Keras's built-in support
keras_model.save_weights("my_checkpoint")
Epoch 0:
W = 4.46, b = 0.40, loss=10.30171
Epoch 1:
W = 4.06, b = 0.72, loss=10.30171
Epoch 2:
W = 3.77, b = 0.97, loss=10.30171
Epoch 3:
W = 3.56, b = 1.18, loss=10.30171
Epoch 4:
W = 3.40, b = 1.34, loss=10.30171
Epoch 5:
W = 3.29, b = 1.47, loss=10.30171
Epoch 6:
W = 3.21, b = 1.58, loss=10.30171
Epoch 7:
W = 3.15, b = 1.66, loss=10.30171
Epoch 8:
W = 3.10, b = 1.73, loss=10.30171
Epoch 9:
W = 3.07, b = 1.78, loss=10.30171
Daripada menulis loop pelatihan baru setiap kali Anda membuat model, Anda dapat menggunakan fitur bawaan Keras sebagai pintasan. Ini bisa berguna ketika Anda tidak ingin menulis atau men-debug loop pelatihan Python.
Jika ya, Anda perlu menggunakan model.compile() untuk mengatur parameter, dan model.fit() untuk melatih. Mungkin lebih sedikit kode untuk menggunakan implementasi Keras dari kehilangan L2 dan penurunan gradien, sekali lagi sebagai jalan pintas. Kehilangan dan pengoptimal keras dapat digunakan di luar fungsi kenyamanan ini juga, dan contoh sebelumnya dapat menggunakannya.
keras_model = MyModelKeras()
# compile sets the training parameters
keras_model.compile(
# By default, fit() uses tf.function(). You can
# turn that off for debugging, but it is on now.
run_eagerly=False,
# Using a built-in optimizer, configuring as an object
optimizer=tf.keras.optimizers.SGD(learning_rate=0.1),
# Keras comes with built-in MSE error
# However, you could use the loss function
# defined above
loss=tf.keras.losses.mean_squared_error,
)
Keras fit mengharapkan data batch atau dataset lengkap sebagai array NumPy. Array NumPy dipotong menjadi batch dan default ke ukuran batch 32.
Dalam hal ini, untuk mencocokkan perilaku loop tulisan tangan, Anda harus memasukkan x sebagai satu kumpulan ukuran 1000.
print(x.shape[0])
keras_model.fit(x, y, epochs=10, batch_size=1000)
201 Epoch 1/10 1/1 [==============================] - 0s 242ms/step - loss: 10.3017 Epoch 2/10 1/1 [==============================] - 0s 3ms/step - loss: 6.3148 Epoch 3/10 1/1 [==============================] - 0s 3ms/step - loss: 4.0341 Epoch 4/10 1/1 [==============================] - 0s 3ms/step - loss: 2.7191 Epoch 5/10 1/1 [==============================] - 0s 3ms/step - loss: 1.9548 Epoch 6/10 1/1 [==============================] - 0s 2ms/step - loss: 1.5068 Epoch 7/10 1/1 [==============================] - 0s 3ms/step - loss: 1.2422 Epoch 8/10 1/1 [==============================] - 0s 2ms/step - loss: 1.0845 Epoch 9/10 1/1 [==============================] - 0s 2ms/step - loss: 0.9899 Epoch 10/10 1/1 [==============================] - 0s 3ms/step - loss: 0.9327 <keras.callbacks.History at 0x7f02ad940050>
Perhatikan bahwa Keras mencetak kerugian setelah pelatihan, bukan sebelumnya, sehingga kerugian pertama tampak lebih rendah, tetapi sebaliknya ini menunjukkan kinerja pelatihan yang pada dasarnya sama.
Langkah selanjutnya
Dalam panduan ini, Anda telah melihat cara menggunakan kelas inti tensor, variabel, modul, dan pita gradien untuk membangun dan melatih model, dan selanjutnya bagaimana ide-ide tersebut dipetakan ke Keras.
Namun, ini adalah masalah yang sangat sederhana. Untuk pengenalan yang lebih praktis, lihat Panduan pelatihan khusus .
Untuk informasi lebih lanjut tentang menggunakan loop pelatihan Keras bawaan, lihat panduan ini . Untuk lebih lanjut tentang loop pelatihan dan Keras, lihat panduan ini . Untuk menulis loop pelatihan terdistribusi khusus, lihat panduan ini .