
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
في الأدلة السابقة ، تعرفت على الموترات والمتغيرات وشريط التدرج والوحدات النمطية . في هذا الدليل ، ستلائم كل هذه الأشياء معًا لتدريب النماذج.
يتضمن TensorFlow أيضًا tf.Keras API ، وهي واجهة برمجة تطبيقات شبكة عصبية عالية المستوى توفر تجريدات مفيدة لتقليل النموذج المعياري. ومع ذلك ، في هذا الدليل ، سوف تستخدم الفصول الأساسية.
يثبت
import tensorflow as tf
import matplotlib.pyplot as plt
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
حل مشاكل التعلم الآلي
عادةً ما يتكون حل مشكلة التعلم الآلي من الخطوات التالية:
- الحصول على بيانات التدريب.
- حدد النموذج.
- حدد دالة الخسارة.
- قم بتشغيل بيانات التدريب ، وحساب الخسارة من القيمة المثالية
- احسب التدرجات لهذه الخسارة واستخدم مُحسِّنًا لضبط المتغيرات لتناسب البيانات.
- قيم نتائجك.
لأغراض التوضيح ، ستقوم في هذا الدليل بتطوير نموذج خطي بسيط ، \(f(x) = x * W + b\)، والذي يحتوي على متغيرين: \(W\) (أوزان) و \(b\) (تحيز).
هذه هي أبسط مشاكل التعلم الآلي: بالنظر \(x\) و \(y\)، حاول إيجاد ميل الخط وإزاحته عن طريق الانحدار الخطي البسيط .
البيانات
يستخدم التعلم الخاضع للإشراف المدخلات (عادةً ما يشار إليها بـ x ) والمخرجات (يُشار إليها بـ y ، وغالبًا ما تسمى التسميات ). الهدف هو التعلم من المدخلات والمخرجات المقترنة بحيث يمكنك التنبؤ بقيمة المخرجات من المدخلات.
يتم دائمًا تمثيل كل إدخال لبياناتك ، في TensorFlow ، بواسطة موتر ، وغالبًا ما يكون متجهًا. في التدريب الخاضع للإشراف ، يكون الناتج (أو القيمة التي ترغب في توقعها) أيضًا موترًا.
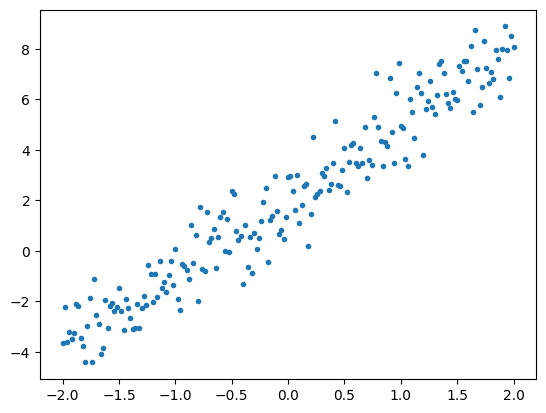
فيما يلي بعض البيانات التي تم توليفها عن طريق إضافة ضوضاء Gaussian (عادي) إلى نقاط على طول الخط.
# The actual line
TRUE_W = 3.0
TRUE_B = 2.0
NUM_EXAMPLES = 201
# A vector of random x values
x = tf.linspace(-2,2, NUM_EXAMPLES)
x = tf.cast(x, tf.float32)
def f(x):
return x * TRUE_W + TRUE_B
# Generate some noise
noise = tf.random.normal(shape=[NUM_EXAMPLES])
# Calculate y
y = f(x) + noise
# Plot all the data
plt.plot(x, y, '.')
plt.show()
عادة ما يتم تجميع الموترات معًا في مجموعات ، أو مجموعات من المدخلات والمخرجات مكدسة معًا. يمكن أن يمنح التجميع بعض مزايا التدريب ويعمل بشكل جيد مع المسرعات والحساب المتجه. نظرًا لمدى صغر مجموعة البيانات هذه ، يمكنك التعامل مع مجموعة البيانات بأكملها كدفعة واحدة.
حدد النموذج
استخدم tf.Variable لتمثيل جميع الأوزان في النموذج. يخزن tf.Variable قيمة ويقدمها في شكل موتر حسب الحاجة. راجع دليل المتغير لمزيد من التفاصيل.
استخدم tf.Module لتغليف المتغيرات والحسابات. يمكنك استخدام أي كائن Python ، ولكن بهذه الطريقة يمكن حفظه بسهولة.
هنا ، تحدد كلاً من w و b كمتغيرات.
class MyModel(tf.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
# Initialize the weights to `5.0` and the bias to `0.0`
# In practice, these should be randomly initialized
self.w = tf.Variable(5.0)
self.b = tf.Variable(0.0)
def __call__(self, x):
return self.w * x + self.b
model = MyModel()
# List the variables tf.modules's built-in variable aggregation.
print("Variables:", model.variables)
# Verify the model works
assert model(3.0).numpy() == 15.0
Variables: (<tf.Variable 'Variable:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'Variable:0' shape=() dtype=float32, numpy=5.0>) 2021-12-08 17:11:44.542944: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
يتم تعيين المتغيرات الأولية هنا بطريقة ثابتة ، لكن Keras تأتي مع أي عدد من المُنشّطات التي يمكنك استخدامها ، مع أو بدون باقي Keras.
حدد دالة الخسارة
تقيس دالة الخسارة مدى تطابق ناتج نموذج لمدخل معين مع المخرجات المستهدفة. الهدف هو تقليل هذا الاختلاف أثناء التدريب. حدد خسارة L2 القياسية ، والمعروفة أيضًا باسم خطأ "متوسط التربيع":
# This computes a single loss value for an entire batch
def loss(target_y, predicted_y):
return tf.reduce_mean(tf.square(target_y - predicted_y))
قبل تدريب النموذج ، يمكنك تصور قيمة الخسارة عن طريق رسم تنبؤات النموذج باللون الأحمر وبيانات التدريب باللون الأزرق:
plt.plot(x, y, '.', label="Data")
plt.plot(x, f(x), label="Ground truth")
plt.plot(x, model(x), label="Predictions")
plt.legend()
plt.show()
print("Current loss: %1.6f" % loss(y, model(x)).numpy())
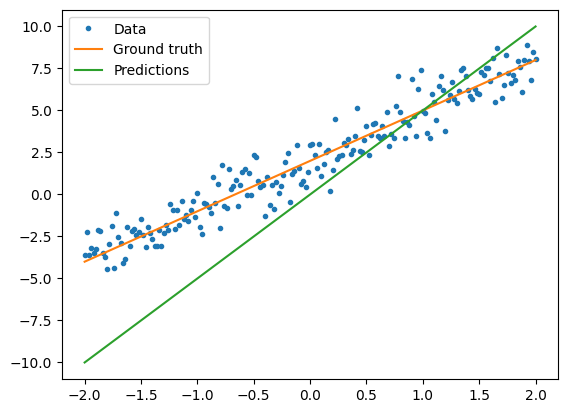
Current loss: 10.301712
تحديد حلقة التدريب
تتكون حلقة التدريب من القيام بثلاث مهام بشكل متكرر بالترتيب:
- إرسال دفعة من المدخلات من خلال النموذج لتوليد المخرجات
- حساب الخسارة بمقارنة المخرجات بالمخرجات (أو التسمية)
- استخدام شريط التدرج لإيجاد التدرجات
- تحسين المتغيرات مع تلك التدرجات
في هذا المثال ، يمكنك تدريب النموذج باستخدام النسب المتدرج .
هناك العديد من المتغيرات لنظام النسب المتدرج التي تم التقاطها في tf.keras.optimizers . ولكن انطلاقاً من روح البناء من المبادئ الأولى ، هنا ستقوم بتنفيذ الرياضيات الأساسية بنفسك بمساعدة tf.GradientTape التلقائي و tf.assign_sub القيمة (التي تجمع بين tf.assign و tf.sub ):
# Given a callable model, inputs, outputs, and a learning rate...
def train(model, x, y, learning_rate):
with tf.GradientTape() as t:
# Trainable variables are automatically tracked by GradientTape
current_loss = loss(y, model(x))
# Use GradientTape to calculate the gradients with respect to W and b
dw, db = t.gradient(current_loss, [model.w, model.b])
# Subtract the gradient scaled by the learning rate
model.w.assign_sub(learning_rate * dw)
model.b.assign_sub(learning_rate * db)
لإلقاء نظرة على التدريب ، يمكنك إرسال نفس الدفعة من x و y من خلال حلقة التدريب ، ومعرفة كيف يتطور W و b .
model = MyModel()
# Collect the history of W-values and b-values to plot later
weights = []
biases = []
epochs = range(10)
# Define a training loop
def report(model, loss):
return f"W = {model.w.numpy():1.2f}, b = {model.b.numpy():1.2f}, loss={current_loss:2.5f}"
def training_loop(model, x, y):
for epoch in epochs:
# Update the model with the single giant batch
train(model, x, y, learning_rate=0.1)
# Track this before I update
weights.append(model.w.numpy())
biases.append(model.b.numpy())
current_loss = loss(y, model(x))
print(f"Epoch {epoch:2d}:")
print(" ", report(model, current_loss))
قم بالتدريب
current_loss = loss(y, model(x))
print(f"Starting:")
print(" ", report(model, current_loss))
training_loop(model, x, y)
Starting:
W = 5.00, b = 0.00, loss=10.30171
Epoch 0:
W = 4.46, b = 0.40, loss=10.30171
Epoch 1:
W = 4.06, b = 0.72, loss=10.30171
Epoch 2:
W = 3.77, b = 0.97, loss=10.30171
Epoch 3:
W = 3.56, b = 1.18, loss=10.30171
Epoch 4:
W = 3.40, b = 1.34, loss=10.30171
Epoch 5:
W = 3.29, b = 1.47, loss=10.30171
Epoch 6:
W = 3.21, b = 1.58, loss=10.30171
Epoch 7:
W = 3.15, b = 1.66, loss=10.30171
Epoch 8:
W = 3.10, b = 1.73, loss=10.30171
Epoch 9:
W = 3.07, b = 1.78, loss=10.30171
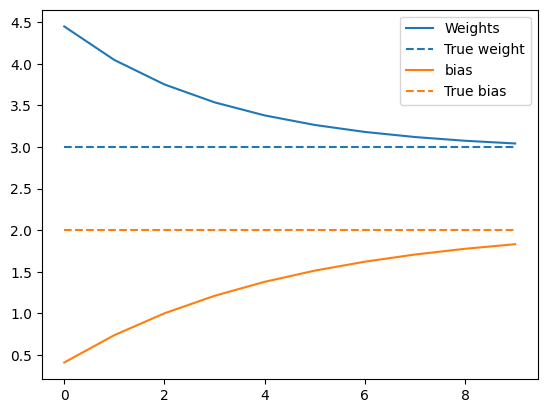
ارسم تطور الأوزان بمرور الوقت:
plt.plot(epochs, weights, label='Weights', color=colors[0])
plt.plot(epochs, [TRUE_W] * len(epochs), '--',
label = "True weight", color=colors[0])
plt.plot(epochs, biases, label='bias', color=colors[1])
plt.plot(epochs, [TRUE_B] * len(epochs), "--",
label="True bias", color=colors[1])
plt.legend()
plt.show()
تصور كيف يعمل النموذج المدرب
plt.plot(x, y, '.', label="Data")
plt.plot(x, f(x), label="Ground truth")
plt.plot(x, model(x), label="Predictions")
plt.legend()
plt.show()
print("Current loss: %1.6f" % loss(model(x), y).numpy())
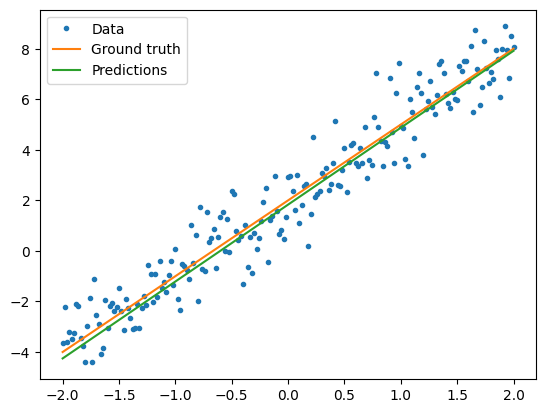
Current loss: 0.897898
نفس الحل ولكن مع Keras
من المفيد مقارنة الكود أعلاه بالمكافئ في Keras.
يبدو تحديد النموذج هو نفسه تمامًا إذا كنت من الفئة الفرعية tf.keras.Model . تذكر أن نماذج Keras ترث في النهاية من الوحدة.
class MyModelKeras(tf.keras.Model):
def __init__(self, **kwargs):
super().__init__(**kwargs)
# Initialize the weights to `5.0` and the bias to `0.0`
# In practice, these should be randomly initialized
self.w = tf.Variable(5.0)
self.b = tf.Variable(0.0)
def call(self, x):
return self.w * x + self.b
keras_model = MyModelKeras()
# Reuse the training loop with a Keras model
training_loop(keras_model, x, y)
# You can also save a checkpoint using Keras's built-in support
keras_model.save_weights("my_checkpoint")
Epoch 0:
W = 4.46, b = 0.40, loss=10.30171
Epoch 1:
W = 4.06, b = 0.72, loss=10.30171
Epoch 2:
W = 3.77, b = 0.97, loss=10.30171
Epoch 3:
W = 3.56, b = 1.18, loss=10.30171
Epoch 4:
W = 3.40, b = 1.34, loss=10.30171
Epoch 5:
W = 3.29, b = 1.47, loss=10.30171
Epoch 6:
W = 3.21, b = 1.58, loss=10.30171
Epoch 7:
W = 3.15, b = 1.66, loss=10.30171
Epoch 8:
W = 3.10, b = 1.73, loss=10.30171
Epoch 9:
W = 3.07, b = 1.78, loss=10.30171
بدلاً من كتابة حلقات تدريب جديدة في كل مرة تقوم فيها بإنشاء نموذج ، يمكنك استخدام الميزات المضمنة في Keras كاختصار. يمكن أن يكون هذا مفيدًا عندما لا ترغب في كتابة أو تصحيح حلقات تدريب Python.
إذا قمت بذلك ، فستحتاج إلى استخدام model.compile() لتعيين المعلمات ، و model.fit() للتدريب. قد يكون استخدام تطبيقات Keras لفقد L2 وهبوط التدرج أقل من التعليمات البرمجية ، مرة أخرى كاختصار. يمكن استخدام خسائر ومحسنات Keras خارج وظائف الراحة هذه أيضًا ، وكان من الممكن أن يستخدمها المثال السابق.
keras_model = MyModelKeras()
# compile sets the training parameters
keras_model.compile(
# By default, fit() uses tf.function(). You can
# turn that off for debugging, but it is on now.
run_eagerly=False,
# Using a built-in optimizer, configuring as an object
optimizer=tf.keras.optimizers.SGD(learning_rate=0.1),
# Keras comes with built-in MSE error
# However, you could use the loss function
# defined above
loss=tf.keras.losses.mean_squared_error,
)
يتوقع Keras fit البيانات المجمعة أو مجموعة البيانات الكاملة كمصفوفة NumPy. يتم تقطيع مصفوفات NumPy إلى دُفعات وافتراضية إلى حجم دُفعة 32.
في هذه الحالة ، لمطابقة سلوك الحلقة المكتوبة بخط اليد ، يجب أن تمرر x كدفعة واحدة بحجم 1000.
print(x.shape[0])
keras_model.fit(x, y, epochs=10, batch_size=1000)
201 Epoch 1/10 1/1 [==============================] - 0s 242ms/step - loss: 10.3017 Epoch 2/10 1/1 [==============================] - 0s 3ms/step - loss: 6.3148 Epoch 3/10 1/1 [==============================] - 0s 3ms/step - loss: 4.0341 Epoch 4/10 1/1 [==============================] - 0s 3ms/step - loss: 2.7191 Epoch 5/10 1/1 [==============================] - 0s 3ms/step - loss: 1.9548 Epoch 6/10 1/1 [==============================] - 0s 2ms/step - loss: 1.5068 Epoch 7/10 1/1 [==============================] - 0s 3ms/step - loss: 1.2422 Epoch 8/10 1/1 [==============================] - 0s 2ms/step - loss: 1.0845 Epoch 9/10 1/1 [==============================] - 0s 2ms/step - loss: 0.9899 Epoch 10/10 1/1 [==============================] - 0s 3ms/step - loss: 0.9327 <keras.callbacks.History at 0x7f02ad940050>
لاحظ أن Keras يطبع الخسارة بعد التدريب ، وليس قبل ذلك ، لذا فإن الخسارة الأولى تظهر أقل ، ولكن بخلاف ذلك ، يُظهر هذا بشكل أساسي نفس أداء التدريب.
الخطوات التالية
في هذا الدليل ، رأيت كيفية استخدام الفئات الأساسية من الموترات والمتغيرات والوحدات وشريط التدرج لبناء نموذج وتدريبه ، وكذلك كيفية تعيين هذه الأفكار إلى Keras.
هذه ، مع ذلك ، مشكلة بسيطة للغاية. للحصول على مقدمة أكثر عملية ، راجع الإرشادات التفصيلية للتدريب المخصص .
لمزيد من المعلومات حول استخدام حلقات تدريب Keras المضمنة ، راجع هذا الدليل . لمزيد من المعلومات حول حلقات التدريب و Keras ، راجع هذا الدليل . لكتابة حلقات تدريب مخصصة موزعة ، انظر هذا الدليل .