| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Обзор
GPU и TPU могут радикально сократить время, необходимое для выполнения одного шага обучения. Для достижения максимальной производительности требуется эффективный входной конвейер, который доставляет данные для следующего шага до завершения текущего шага. API tf.data помогает создавать гибкие и эффективные конвейеры ввода. В этом документе показано, как использовать API tf.data для создания высокопроизводительных входных конвейеров TensorFlow.
Прежде чем продолжить, ознакомьтесь с руководством по сборке входных конвейеров TensorFlow, чтобы узнать, как использовать API tf.data .
Ресурсы
- Создание входных конвейеров TensorFlow
-
tf.data.DatasetAPI набора данных - Анализ производительности
tf.dataс помощью TF Profiler
Настраивать
import tensorflow as tf
import time
В этом руководстве вы будете повторять набор данных и измерять производительность. Создание воспроизводимых тестов производительности может быть затруднено. Различные факторы, влияющие на воспроизводимость, включают:
- Текущая загрузка процессора
- Сетевой трафик
- Сложные механизмы, такие как кеш
Чтобы получить воспроизводимый бенчмарк, вы создадите искусственный пример.
Набор данных
Начните с определения класса, наследуемого от tf.data.Dataset называется ArtificialDataset . Этот набор данных:
- Генерирует выборки
num_samples(по умолчанию 3) - Засыпает на некоторое время перед первым элементом, чтобы имитировать открытие файла
- Некоторое время спит перед созданием каждого элемента, чтобы имитировать чтение данных из файла.
class ArtificialDataset(tf.data.Dataset):
def _generator(num_samples):
# Opening the file
time.sleep(0.03)
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
time.sleep(0.015)
yield (sample_idx,)
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_signature = tf.TensorSpec(shape = (1,), dtype = tf.int64),
args=(num_samples,)
)
Этот набор данных аналогичен tf.data.Dataset.range , добавляя фиксированную задержку в начале и между каждой выборкой.
Тренировочный цикл
Затем напишите фиктивный цикл обучения, который измеряет, сколько времени требуется для повторения набора данных. Время обучения моделируется.
def benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
for sample in dataset:
# Performing a training step
time.sleep(0.01)
print("Execution time:", time.perf_counter() - start_time)
Оптимизация производительности
Чтобы продемонстрировать, как можно оптимизировать производительность, вы улучшите производительность ArtificialDataset .
Наивный подход
Начните с наивного конвейера, не используя никаких трюков, перебирая набор данных как есть.
benchmark(ArtificialDataset())
Execution time: 0.26497629899995445
Под капотом вот как было потрачено ваше время выполнения:

График показывает, что выполнение шага обучения включает в себя:
- Открытие файла, если он еще не открыт
- Получение записи данных из файла
- Использование данных для обучения
Однако в наивной синхронной реализации, такой как здесь, пока ваш конвейер извлекает данные, ваша модель простаивает. И наоборот, пока ваша модель обучается, входной конвейер простаивает. Таким образом, время шага обучения представляет собой сумму времени открытия, чтения и обучения.
Следующие разделы основаны на этом конвейере ввода, иллюстрируя передовые методы проектирования производительных конвейеров ввода TensorFlow.
Предварительная загрузка
Предварительная выборка перекрывает предварительную обработку и выполнение модели этапа обучения. Пока модель выполняет шаг обучения s , входной конвейер считывает данные для шага s+1 . Это сокращает время шага до максимума (в отличие от суммы) обучения и времени, необходимого для извлечения данных.
API tf.data обеспечивает преобразование tf.data.Dataset.prefetch . Его можно использовать для отделения времени создания данных от времени их потребления. В частности, преобразование использует фоновый поток и внутренний буфер для предварительной выборки элементов из входного набора данных до того, как они будут запрошены. Количество элементов для предварительной выборки должно быть равно (или, возможно, больше) количеству пакетов, потребляемых одним этапом обучения. Вы можете либо вручную настроить это значение, либо установить его в tf.data.AUTOTUNE , что предложит среде выполнения tf.data динамически настроить значение во время выполнения.
Обратите внимание, что преобразование предварительной выборки дает преимущества каждый раз, когда есть возможность совместить работу «производителя» с работой «потребителя».
benchmark(
ArtificialDataset()
.prefetch(tf.data.AUTOTUNE)
)
Execution time: 0.21731788600027357

Теперь, как показывает график времени выполнения данных, пока шаг обучения выполняется для выборки 0, входной конвейер считывает данные для выборки 1 и так далее.
Распараллеливание извлечения данных
В реальных условиях входные данные могут храниться удаленно (например, в Google Cloud Storage или HDFS). Конвейер наборов данных, который хорошо работает при локальном чтении данных, может стать узким местом при вводе-выводе при удаленном чтении данных из-за следующих различий между локальным и удаленным хранилищем:
- Время до первого байта : Чтение первого байта файла из удаленного хранилища может занять на несколько порядков больше времени, чем из локального хранилища.
- Пропускная способность при чтении. Хотя удаленное хранилище обычно предлагает большую совокупную пропускную способность, при чтении одного файла может использоваться только небольшая часть этой пропускной способности.
Кроме того, после загрузки необработанных байтов в память может также потребоваться десериализация и/или расшифровка данных (например, protobuf ), что требует дополнительных вычислений. Эти накладные расходы присутствуют независимо от того, хранятся ли данные локально или удаленно, но могут быть хуже в удаленном случае, если данные не эффективно упреждаются.
Чтобы смягчить влияние различных накладных расходов на извлечение данных, можно использовать преобразование tf.data.Dataset.interleave для распараллеливания этапа загрузки данных, чередуя содержимое других наборов данных (например, средств чтения файлов данных). Количество перекрывающихся наборов данных можно указать аргументом cycle_length , а уровень параллелизма можно указать аргументом num_parallel_calls . Подобно преобразованию prefetch , преобразование interleave поддерживает tf.data.AUTOTUNE , что делегирует решение о том, какой уровень параллелизма использовать, среде выполнения tf.data .
Последовательное чередование
Аргументы по умолчанию преобразования tf.data.Dataset.interleave заставляют последовательно чередовать отдельные выборки из двух наборов данных.
benchmark(
tf.data.Dataset.range(2)
.interleave(lambda _: ArtificialDataset())
)
Execution time: 0.4987426460002098

Этот график времени выполнения данных позволяет продемонстрировать поведение преобразования interleave , поочередно выбирая выборки из двух доступных наборов данных. Однако никакого улучшения производительности здесь нет.
Параллельное чередование
Теперь используйте аргумент num_parallel_calls преобразования interleave . Это загружает несколько наборов данных параллельно, сокращая время ожидания открытия файлов.
benchmark(
tf.data.Dataset.range(2)
.interleave(
lambda _: ArtificialDataset(),
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.283668874000341

На этот раз, как показывает график времени выполнения данных, чтение двух наборов данных распараллелено, что сокращает общее время обработки данных.
Распараллеливание преобразования данных
При подготовке данных может потребоваться предварительная обработка входных элементов. С этой целью API tf.data предлагает преобразование tf.data.Dataset.map , которое применяет определяемую пользователем функцию к каждому элементу входного набора данных. Поскольку входные элементы не зависят друг от друга, предварительная обработка может быть распараллелена между несколькими ядрами ЦП. Чтобы сделать это возможным, подобно преобразованиям prefetch и interleave , преобразование map предоставляет аргумент num_parallel_calls для указания уровня параллелизма.
Выбор наилучшего значения для аргумента num_parallel_calls зависит от вашего оборудования, характеристик ваших обучающих данных (таких как их размер и форма), стоимости вашей функции сопоставления и того, какая другая обработка выполняется на ЦП в то же время. Простая эвристика — использовать количество доступных ядер ЦП. Однако, что касается преобразования prefetch и interleave , преобразование map поддерживает tf.data.AUTOTUNE , который делегирует решение о том, какой уровень параллелизма использовать, среде выполнения tf.data .
def mapped_function(s):
# Do some hard pre-processing
tf.py_function(lambda: time.sleep(0.03), [], ())
return s
Последовательное отображение
Начните с использования преобразования map без параллелизма в качестве базового примера.
benchmark(
ArtificialDataset()
.map(mapped_function)
)
Execution time: 0.4505277170001136

Что касается наивного подхода , то здесь, как показывает сюжет, время, затрачиваемое на шаги открытия, чтения, предварительной обработки (отображения) и обучения, суммируется за одну итерацию.
Параллельное отображение
Теперь используйте ту же функцию предварительной обработки, но примените ее параллельно к нескольким образцам.
benchmark(
ArtificialDataset()
.map(
mapped_function,
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.2839677860001757

Как видно из графика данных, этапы предварительной обработки перекрываются, что сокращает общее время для одной итерации.
Кэширование
Преобразование tf.data.Dataset.cache может кэшировать набор данных либо в памяти, либо в локальном хранилище. Это предотвратит выполнение некоторых операций (таких как открытие файлов и чтение данных) в течение каждой эпохи.
benchmark(
ArtificialDataset()
.map( # Apply time consuming operations before cache
mapped_function
).cache(
),
5
)
Execution time: 0.3848854380003104

Здесь график времени выполнения данных показывает, что при кэшировании набора данных преобразования перед cache (такие как открытие файла и чтение данных) выполняются только в течение первой эпохи. Следующие эпохи будут повторно использовать данные, кэшированные преобразованием cache .
Если определяемая пользователем функция, переданная в преобразование map , требует больших затрат, примените преобразование cache после преобразования map , пока результирующий набор данных все еще может поместиться в памяти или локальном хранилище. Если определяемая пользователем функция увеличивает пространство, необходимое для хранения набора данных, за пределы емкости кэша, либо примените ее после преобразования cache , либо рассмотрите возможность предварительной обработки данных перед заданием обучения, чтобы сократить использование ресурсов.
Векторизация карт
Вызов пользовательской функции, переданной в преобразование map , связан с планированием и выполнением пользовательской функции. Векторизуйте определяемую пользователем функцию (то есть заставьте ее работать с пакетом входных данных одновременно) и примените batch преобразование перед преобразованием map .
Чтобы проиллюстрировать эту хорошую практику, ваш искусственный набор данных не подходит. Задержка планирования составляет около 10 микросекунд (10e-6 секунд), что намного меньше десятков миллисекунд, используемых в ArtificialDataset , поэтому ее влияние трудно увидеть.
В этом примере используйте базовую функцию tf.data.Dataset.range и упростите цикл обучения до его простейшей формы.
fast_dataset = tf.data.Dataset.range(10000)
def fast_benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for _ in tf.data.Dataset.range(num_epochs):
for _ in dataset:
pass
tf.print("Execution time:", time.perf_counter() - start_time)
def increment(x):
return x+1
Скалярное отображение
fast_benchmark(
fast_dataset
# Apply function one item at a time
.map(increment)
# Batch
.batch(256)
)
Execution time: 0.2712608739998359

График выше иллюстрирует, что происходит (с меньшим количеством выборок) с использованием метода скалярного отображения. Он показывает, что сопоставленная функция применяется для каждого образца. Хотя эта функция работает очень быстро, она имеет некоторые накладные расходы, влияющие на производительность по времени.
Векторизованное картографирование
fast_benchmark(
fast_dataset
.batch(256)
# Apply function on a batch of items
# The tf.Tensor.__add__ method already handle batches
.map(increment)
)
Execution time: 0.02737950600021577

На этот раз сопоставленная функция вызывается один раз и применяется к партии образцов. Как показывает график времени выполнения данных, несмотря на то, что выполнение функции может занять больше времени, накладные расходы возникают только один раз, что улучшает общую производительность по времени.
Уменьшение объема памяти
Ряд преобразований, в том числе interleave , prefetch и shuffle , поддерживают внутренний буфер элементов. Если определяемая пользователем функция, переданная в преобразование map , изменяет размер элементов, то порядок преобразования карты и преобразований, которые буферизуют элементы, влияют на использование памяти. Как правило, выбирайте порядок, который приводит к меньшему объему памяти, если для повышения производительности не требуется другой порядок.
Кэширование частичных вычислений
Рекомендуется кэшировать набор данных после преобразования map , за исключением случаев, когда это преобразование делает данные слишком большими для размещения в памяти. Компромисс может быть достигнут, если отображаемую функцию можно разделить на две части: часть, занимающую много времени, и часть, потребляющую память. В этом случае вы можете связать свои преобразования, как показано ниже:
dataset.map(time_consuming_mapping).cache().map(memory_consuming_mapping)
Таким образом, трудоемкая часть выполняется только в течение первой эпохи, и вы избегаете использования слишком большого объема кэш-памяти.
Краткое изложение передового опыта
Вот краткое изложение лучших практик по проектированию производительных входных конвейеров TensorFlow:
- Используйте преобразование
prefetch, чтобы перекрыть работу производителя и потребителя. - Распараллелить преобразование чтения данных с помощью преобразования
interleave - Распараллелить преобразование
map, установив аргументnum_parallel_calls - Используйте
cacheкеша для кэширования данных в памяти в течение первой эпохи. - Векторизация пользовательских функций, переданных в преобразование
map - Уменьшите использование памяти при применении преобразований
interleave,prefetchиshuffle.
Воспроизведение фигур
Чтобы глубже понять API tf.data.Dataset , вы можете поиграть со своими собственными пайплайнами. Ниже приведен код, используемый для построения изображений из этого руководства. Это может быть хорошей отправной точкой, показывающей некоторые обходные пути для распространенных проблем, таких как:
- Воспроизводимость времени выполнения
- Сопоставленные функции с нетерпением ждут выполнения
- вызываемое преобразование
interleave
import itertools
from collections import defaultdict
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
Набор данных
Как и в случае с ArtificialDataset , вы можете создать набор данных, возвращающий время, затраченное на каждый шаг.
class TimeMeasuredDataset(tf.data.Dataset):
# OUTPUT: (steps, timings, counters)
OUTPUT_TYPES = (tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32)
OUTPUT_SHAPES = ((2, 1), (2, 2), (2, 3))
_INSTANCES_COUNTER = itertools.count() # Number of datasets generated
_EPOCHS_COUNTER = defaultdict(itertools.count) # Number of epochs done for each dataset
def _generator(instance_idx, num_samples):
epoch_idx = next(TimeMeasuredDataset._EPOCHS_COUNTER[instance_idx])
# Opening the file
open_enter = time.perf_counter()
time.sleep(0.03)
open_elapsed = time.perf_counter() - open_enter
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
read_enter = time.perf_counter()
time.sleep(0.015)
read_elapsed = time.perf_counter() - read_enter
yield (
[("Open",), ("Read",)],
[(open_enter, open_elapsed), (read_enter, read_elapsed)],
[(instance_idx, epoch_idx, -1), (instance_idx, epoch_idx, sample_idx)]
)
open_enter, open_elapsed = -1., -1. # Negative values will be filtered
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_types=cls.OUTPUT_TYPES,
output_shapes=cls.OUTPUT_SHAPES,
args=(next(cls._INSTANCES_COUNTER), num_samples)
)
Этот набор данных содержит образцы формы [[2, 1], [2, 2], [2, 3]] и типа [tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32] . Каждый образец:
(
[("Open"), ("Read")],
[(t0, d), (t0, d)],
[(i, e, -1), (i, e, s)]
)
Где:
-
OpenиRead— идентификаторы шагов -
t0— метка времени начала соответствующего шага. -
d- время, затраченное на соответствующий шаг -
iиндекс экземпляра -
e- индекс эпохи (количество итераций набора данных) -
s- индекс выборки
Цикл итераций
Немного усложните итерационный цикл, чтобы агрегировать все тайминги. Это будет работать только с наборами данных, генерирующими выборки, как описано выше.
def timelined_benchmark(dataset, num_epochs=2):
# Initialize accumulators
steps_acc = tf.zeros([0, 1], dtype=tf.dtypes.string)
times_acc = tf.zeros([0, 2], dtype=tf.dtypes.float32)
values_acc = tf.zeros([0, 3], dtype=tf.dtypes.int32)
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
epoch_enter = time.perf_counter()
for (steps, times, values) in dataset:
# Record dataset preparation informations
steps_acc = tf.concat((steps_acc, steps), axis=0)
times_acc = tf.concat((times_acc, times), axis=0)
values_acc = tf.concat((values_acc, values), axis=0)
# Simulate training time
train_enter = time.perf_counter()
time.sleep(0.01)
train_elapsed = time.perf_counter() - train_enter
# Record training informations
steps_acc = tf.concat((steps_acc, [["Train"]]), axis=0)
times_acc = tf.concat((times_acc, [(train_enter, train_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [values[-1]]), axis=0)
epoch_elapsed = time.perf_counter() - epoch_enter
# Record epoch informations
steps_acc = tf.concat((steps_acc, [["Epoch"]]), axis=0)
times_acc = tf.concat((times_acc, [(epoch_enter, epoch_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [[-1, epoch_num, -1]]), axis=0)
time.sleep(0.001)
tf.print("Execution time:", time.perf_counter() - start_time)
return {"steps": steps_acc, "times": times_acc, "values": values_acc}
Метод построения
Наконец, определите функцию, способную строить временную шкалу с учетом значений, возвращаемых функцией timelined_benchmark .
def draw_timeline(timeline, title, width=0.5, annotate=False, save=False):
# Remove invalid entries (negative times, or empty steps) from the timelines
invalid_mask = np.logical_and(timeline['times'] > 0, timeline['steps'] != b'')[:,0]
steps = timeline['steps'][invalid_mask].numpy()
times = timeline['times'][invalid_mask].numpy()
values = timeline['values'][invalid_mask].numpy()
# Get a set of different steps, ordered by the first time they are encountered
step_ids, indices = np.stack(np.unique(steps, return_index=True))
step_ids = step_ids[np.argsort(indices)]
# Shift the starting time to 0 and compute the maximal time value
min_time = times[:,0].min()
times[:,0] = (times[:,0] - min_time)
end = max(width, (times[:,0]+times[:,1]).max() + 0.01)
cmap = mpl.cm.get_cmap("plasma")
plt.close()
fig, axs = plt.subplots(len(step_ids), sharex=True, gridspec_kw={'hspace': 0})
fig.suptitle(title)
fig.set_size_inches(17.0, len(step_ids))
plt.xlim(-0.01, end)
for i, step in enumerate(step_ids):
step_name = step.decode()
ax = axs[i]
ax.set_ylabel(step_name)
ax.set_ylim(0, 1)
ax.set_yticks([])
ax.set_xlabel("time (s)")
ax.set_xticklabels([])
ax.grid(which="both", axis="x", color="k", linestyle=":")
# Get timings and annotation for the given step
entries_mask = np.squeeze(steps==step)
serie = np.unique(times[entries_mask], axis=0)
annotations = values[entries_mask]
ax.broken_barh(serie, (0, 1), color=cmap(i / len(step_ids)), linewidth=1, alpha=0.66)
if annotate:
for j, (start, width) in enumerate(serie):
annotation = "\n".join([f"{l}: {v}" for l,v in zip(("i", "e", "s"), annotations[j])])
ax.text(start + 0.001 + (0.001 * (j % 2)), 0.55 - (0.1 * (j % 2)), annotation,
horizontalalignment='left', verticalalignment='center')
if save:
plt.savefig(title.lower().translate(str.maketrans(" ", "_")) + ".svg")
Используйте обертки для сопоставленной функции
Чтобы запустить сопоставленную функцию в активном контексте, вы должны обернуть их внутри вызова tf.py_function .
def map_decorator(func):
def wrapper(steps, times, values):
# Use a tf.py_function to prevent auto-graph from compiling the method
return tf.py_function(
func,
inp=(steps, times, values),
Tout=(steps.dtype, times.dtype, values.dtype)
)
return wrapper
Сравнение трубопроводов
_batch_map_num_items = 50
def dataset_generator_fun(*args):
return TimeMeasuredDataset(num_samples=_batch_map_num_items)
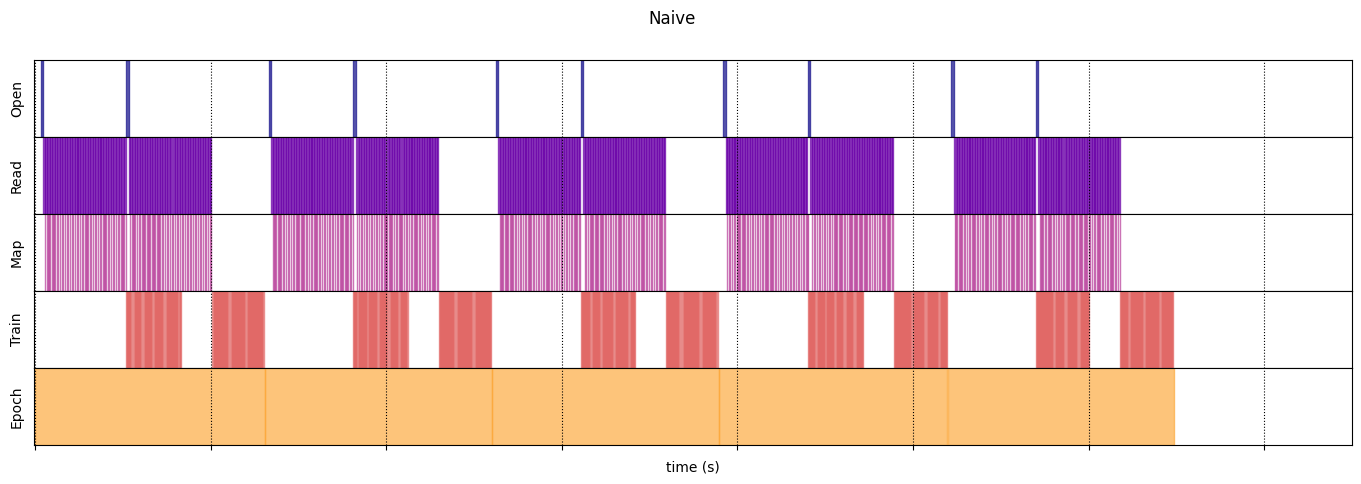
Наивный
@map_decorator
def naive_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001) # Time consuming step
time.sleep(0.0001) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, [["Map"]]), axis=0),
tf.concat((times, [[map_enter, map_elapsed]]), axis=0),
tf.concat((values, [values[-1]]), axis=0)
)
naive_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.flat_map(dataset_generator_fun)
.map(naive_map)
.batch(_batch_map_num_items, drop_remainder=True)
.unbatch(),
5
)
WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_types is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_shapes is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead Execution time: 13.13538893499981
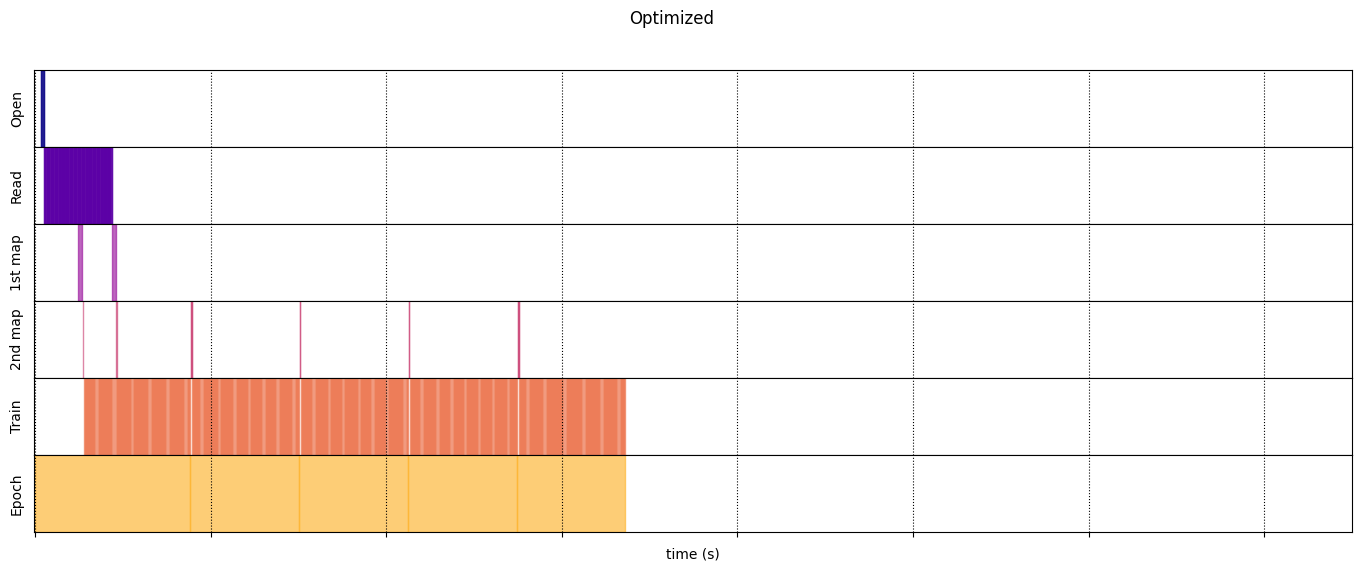
Оптимизировано
@map_decorator
def time_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001 * values.shape[0]) # Time consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, tf.tile([[["1st map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
@map_decorator
def memory_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.0001 * values.shape[0]) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
# Use tf.tile to handle batch dimension
return (
tf.concat((steps, tf.tile([[["2nd map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
optimized_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.interleave( # Parallelize data reading
dataset_generator_fun,
num_parallel_calls=tf.data.AUTOTUNE
)
.batch( # Vectorize your mapped function
_batch_map_num_items,
drop_remainder=True)
.map( # Parallelize map transformation
time_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.cache() # Cache data
.map( # Reduce memory usage
memory_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.prefetch( # Overlap producer and consumer works
tf.data.AUTOTUNE
)
.unbatch(),
5
)
Execution time: 6.723691489999965
draw_timeline(naive_timeline, "Naive", 15)
draw_timeline(optimized_timeline, "Optimized", 15)