| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Ringkasan
GPU dan TPU dapat secara radikal mengurangi waktu yang diperlukan untuk menjalankan satu langkah pelatihan. Mencapai kinerja puncak memerlukan saluran input yang efisien yang mengirimkan data untuk langkah berikutnya sebelum langkah saat ini selesai. tf.data API membantu membangun jalur input yang fleksibel dan efisien. Dokumen ini menunjukkan cara menggunakan tf.data API untuk membuat pipeline input TensorFlow yang berperforma tinggi.
Sebelum melanjutkan, lihat panduan pipeline input Build TensorFlow untuk mempelajari cara menggunakan tf.data API.
Sumber daya
Mempersiapkan
import tensorflow as tf
import time
Sepanjang panduan ini, Anda akan melakukan iterasi di seluruh kumpulan data dan mengukur kinerjanya. Membuat tolok ukur kinerja yang dapat direproduksi bisa jadi sulit. Berbagai faktor yang mempengaruhi reproduktifitas meliputi:
- Beban CPU saat ini
- Lalu lintas jaringan
- Mekanisme kompleks, seperti cache
Untuk mendapatkan tolok ukur yang dapat direproduksi, Anda akan membuat contoh buatan.
kumpulan data
Mulailah dengan mendefinisikan kelas yang diwarisi dari tf.data.Dataset disebut ArtificialDataset . kumpulan data ini:
- Menghasilkan
num_samplessampel (default adalah 3) - Tidur selama beberapa waktu sebelum item pertama untuk mensimulasikan membuka file
- Tidur selama beberapa waktu sebelum memproduksi setiap item untuk mensimulasikan membaca data dari file
class ArtificialDataset(tf.data.Dataset):
def _generator(num_samples):
# Opening the file
time.sleep(0.03)
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
time.sleep(0.015)
yield (sample_idx,)
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_signature = tf.TensorSpec(shape = (1,), dtype = tf.int64),
args=(num_samples,)
)
Dataset ini mirip dengan tf.data.Dataset.range satu, menambahkan penundaan tetap di awal dan di antara setiap sampel.
Lingkaran pelatihan
Selanjutnya, tulis loop pelatihan dummy yang mengukur berapa lama waktu yang dibutuhkan untuk melakukan iterasi pada set data. Waktu pelatihan disimulasikan.
def benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
for sample in dataset:
# Performing a training step
time.sleep(0.01)
print("Execution time:", time.perf_counter() - start_time)
Optimalkan kinerja
Untuk menunjukkan bagaimana kinerja dapat dioptimalkan, Anda akan meningkatkan kinerja ArtificialDataset .
Pendekatan naif
Mulailah dengan pipeline naif tanpa menggunakan trik, mengulangi set data apa adanya.
benchmark(ArtificialDataset())
Execution time: 0.26497629899995445
Di bawah tenda, ini adalah bagaimana waktu eksekusi Anda dihabiskan:

Plot menunjukkan bahwa melakukan langkah pelatihan melibatkan:
- Membuka file jika belum dibuka
- Mengambil entri data dari file
- Menggunakan data untuk pelatihan
Namun, dalam implementasi sinkron naif seperti di sini, saat pipeline Anda mengambil data, model Anda tidak digunakan. Sebaliknya, saat model Anda sedang berlatih, saluran input tidak digunakan. Dengan demikian, waktu langkah pelatihan adalah jumlah waktu pembukaan, membaca, dan pelatihan.
Bagian berikutnya dibuat berdasarkan pipeline input ini, yang menggambarkan praktik terbaik untuk mendesain pipeline input TensorFlow yang berkinerja baik.
Mengambil terlebih dahulu
Prefetching tumpang tindih dengan preprocessing dan eksekusi model dari langkah pelatihan. Saat model mengeksekusi langkah pelatihan s , pipa input membaca data untuk langkah s+1 . Melakukannya akan mengurangi waktu langkah secara maksimal (berlawanan dengan jumlah) pelatihan dan waktu yang diperlukan untuk mengekstrak data.
API tf.data menyediakan transformasi tf.data.Dataset.prefetch . Ini dapat digunakan untuk memisahkan waktu ketika data diproduksi dari saat data dikonsumsi. Secara khusus, transformasi menggunakan utas latar belakang dan buffer internal untuk mengambil elemen lebih dulu dari kumpulan data input sebelum mereka diminta. Jumlah elemen yang akan diambil sebelumnya harus sama dengan (atau mungkin lebih besar dari) jumlah batch yang dikonsumsi oleh satu langkah pelatihan. Anda dapat menyetel nilai ini secara manual, atau menyetelnya ke tf.data.AUTOTUNE , yang akan meminta runtime tf.data untuk menyetel nilai secara dinamis saat runtime.
Perhatikan bahwa transformasi prefetch memberikan manfaat setiap kali ada kesempatan untuk tumpang tindih pekerjaan "produser" dengan pekerjaan "konsumen."
benchmark(
ArtificialDataset()
.prefetch(tf.data.AUTOTUNE)
)
Execution time: 0.21731788600027357

Sekarang, seperti yang ditunjukkan oleh plot waktu eksekusi data, saat langkah pelatihan berjalan untuk sampel 0, pipa input membaca data untuk sampel 1, dan seterusnya.
Memparalelkan ekstraksi data
Dalam pengaturan dunia nyata, data input dapat disimpan dari jarak jauh (misalnya, di Google Cloud Storage atau HDFS). Pipeline kumpulan data yang berfungsi dengan baik saat membaca data secara lokal mungkin mengalami hambatan pada I/O saat membaca data dari jarak jauh karena perbedaan berikut antara penyimpanan lokal dan jarak jauh:
- Time-to-first-byte : Membaca byte pertama file dari penyimpanan jarak jauh dapat memakan waktu lebih lama daripada dari penyimpanan lokal.
- Baca throughput : Sementara penyimpanan jarak jauh biasanya menawarkan bandwidth agregat yang besar, membaca satu file mungkin hanya dapat memanfaatkan sebagian kecil dari bandwidth ini.
Selain itu, setelah byte mentah dimuat ke dalam memori, mungkin juga perlu untuk melakukan deserialize dan/atau mendekripsi data (misalnya protobuf ), yang memerlukan perhitungan tambahan. Overhead ini ada terlepas dari apakah data disimpan secara lokal atau jarak jauh, tetapi bisa lebih buruk dalam kasus jarak jauh jika data tidak diambil secara efektif.
Untuk mengurangi dampak dari berbagai biaya ekstraksi data, transformasi tf.data.Dataset.interleave dapat digunakan untuk memparalelkan langkah pemuatan data, dengan menyisipkan konten kumpulan data lain (seperti pembaca file data). Jumlah kumpulan data yang tumpang tindih dapat ditentukan oleh argumen cycle_length , sedangkan tingkat paralelisme dapat ditentukan oleh argumen num_parallel_calls . Mirip dengan transformasi prefetch , transformasi interleave mendukung tf.data.AUTOTUNE , yang akan mendelegasikan keputusan tentang tingkat paralelisme yang akan digunakan untuk runtime tf.data .
Interleave berurutan
Argumen default dari transformasi tf.data.Dataset.interleave membuatnya menyisipkan sampel tunggal dari dua set data secara berurutan.
benchmark(
tf.data.Dataset.range(2)
.interleave(lambda _: ArtificialDataset())
)
Execution time: 0.4987426460002098

Plot waktu eksekusi data ini memungkinkan untuk menunjukkan perilaku transformasi interleave , mengambil sampel secara alternatif dari dua kumpulan data yang tersedia. Namun, tidak ada peningkatan kinerja yang terlibat di sini.
Interleave paralel
Sekarang, gunakan argumen num_parallel_calls dari transformasi interleave . Ini memuat beberapa kumpulan data secara paralel, mengurangi waktu menunggu file dibuka.
benchmark(
tf.data.Dataset.range(2)
.interleave(
lambda _: ArtificialDataset(),
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.283668874000341

Kali ini, seperti yang ditunjukkan oleh plot waktu eksekusi data, pembacaan dua set data diparalelkan, mengurangi waktu pemrosesan data global.
Memparalelkan transformasi data
Saat menyiapkan data, elemen input mungkin perlu diproses terlebih dahulu. Untuk tujuan ini, tf.data API menawarkan transformasi tf.data.Dataset.map , yang menerapkan fungsi yang ditentukan pengguna ke setiap elemen set data input. Karena elemen input independen satu sama lain, pra-pemrosesan dapat diparalelkan di beberapa inti CPU. Untuk memungkinkan hal ini, mirip dengan transformasi prefetch dan interleave , transformasi map menyediakan argumen num_parallel_calls untuk menentukan tingkat paralelisme.
Memilih nilai terbaik untuk argumen num_parallel_calls bergantung pada perangkat keras Anda, karakteristik data pelatihan Anda (seperti ukuran dan bentuknya), biaya fungsi peta Anda, dan pemrosesan lain apa yang terjadi pada CPU pada saat yang bersamaan. Heuristik sederhana adalah dengan menggunakan jumlah inti CPU yang tersedia. Namun, untuk transformasi prefetch dan interleave , transformasi map mendukung tf.data.AUTOTUNE yang akan mendelegasikan keputusan tentang tingkat paralelisme yang akan digunakan untuk runtime tf.data .
def mapped_function(s):
# Do some hard pre-processing
tf.py_function(lambda: time.sleep(0.03), [], ())
return s
Pemetaan berurutan
Mulailah dengan menggunakan transformasi map tanpa paralelisme sebagai contoh dasar.
benchmark(
ArtificialDataset()
.map(mapped_function)
)
Execution time: 0.4505277170001136

Adapun pendekatan naif , di sini, seperti yang ditunjukkan plot, waktu yang dihabiskan untuk membuka, membaca, pra-pemrosesan (pemetaan) dan langkah-langkah pelatihan dijumlahkan untuk satu iterasi.
Pemetaan paralel
Sekarang, gunakan fungsi pra-pemrosesan yang sama tetapi terapkan secara paralel pada beberapa sampel.
benchmark(
ArtificialDataset()
.map(
mapped_function,
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.2839677860001757

Seperti yang ditunjukkan plot data, langkah-langkah pra-pemrosesan tumpang tindih, mengurangi waktu keseluruhan untuk satu iterasi.
Cache
Transformasi tf.data.Dataset.cache dapat meng-cache set data, baik di memori atau di penyimpanan lokal. Ini akan menghemat beberapa operasi (seperti pembukaan file dan pembacaan data) agar tidak dieksekusi selama setiap zaman.
benchmark(
ArtificialDataset()
.map( # Apply time consuming operations before cache
mapped_function
).cache(
),
5
)
Execution time: 0.3848854380003104

Di sini, plot waktu eksekusi data menunjukkan bahwa ketika Anda men-cache set data, transformasi sebelum cache (seperti pembukaan file dan pembacaan data) dijalankan hanya selama epoch pertama. Epoch berikutnya akan menggunakan kembali data yang di-cache oleh transformasi cache .
Jika fungsi yang ditentukan pengguna yang diteruskan ke dalam transformasi map mahal, terapkan transformasi cache setelah transformasi map selama dataset yang dihasilkan masih dapat masuk ke dalam memori atau penyimpanan lokal. Jika fungsi yang ditentukan pengguna menambah ruang yang diperlukan untuk menyimpan kumpulan data di luar kapasitas cache, terapkan itu setelah transformasi cache atau pertimbangkan untuk melakukan pra-pemrosesan data Anda sebelum pekerjaan pelatihan Anda untuk mengurangi penggunaan sumber daya.
Pemetaan vektorisasi
Memanggil fungsi yang ditentukan pengguna yang diteruskan ke transformasi map memiliki overhead yang terkait dengan penjadwalan dan menjalankan fungsi yang ditentukan pengguna. Membuat vektor dari fungsi yang ditentukan pengguna (yaitu, membuatnya beroperasi pada sekumpulan input sekaligus) dan menerapkan transformasi batch sebelum transformasi map .
Untuk mengilustrasikan praktik yang baik ini, kumpulan data buatan Anda tidak cocok. Penundaan penjadwalan sekitar 10 mikrodetik (10e-6 detik), jauh lebih sedikit daripada puluhan milidetik yang digunakan dalam ArtificialDataset , dan dengan demikian dampaknya sulit untuk dilihat.
Untuk contoh ini, gunakan fungsi dasar tf.data.Dataset.range dan sederhanakan loop pelatihan ke bentuknya yang paling sederhana.
fast_dataset = tf.data.Dataset.range(10000)
def fast_benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for _ in tf.data.Dataset.range(num_epochs):
for _ in dataset:
pass
tf.print("Execution time:", time.perf_counter() - start_time)
def increment(x):
return x+1
Pemetaan skalar
fast_benchmark(
fast_dataset
# Apply function one item at a time
.map(increment)
# Batch
.batch(256)
)
Execution time: 0.2712608739998359

Plot di atas menggambarkan apa yang terjadi (dengan sampel lebih sedikit) menggunakan metode pemetaan skalar. Ini menunjukkan bahwa fungsi yang dipetakan diterapkan untuk setiap sampel. Meskipun fungsi ini sangat cepat, ia memiliki beberapa overhead yang memengaruhi kinerja waktu.
Pemetaan vektor
fast_benchmark(
fast_dataset
.batch(256)
# Apply function on a batch of items
# The tf.Tensor.__add__ method already handle batches
.map(increment)
)
Execution time: 0.02737950600021577

Kali ini, fungsi yang dipetakan dipanggil sekali dan berlaku untuk sekumpulan sampel. Seperti yang ditunjukkan oleh plot waktu eksekusi data, sementara fungsi membutuhkan lebih banyak waktu untuk dieksekusi, overhead hanya muncul sekali, meningkatkan kinerja waktu secara keseluruhan.
Mengurangi jejak memori
Sejumlah transformasi, termasuk interleave , prefetch , dan shuffle , mempertahankan buffer internal elemen. Jika fungsi yang ditentukan pengguna yang diteruskan ke transformasi map mengubah ukuran elemen, maka urutan transformasi peta dan transformasi elemen penyangga mempengaruhi penggunaan memori. Secara umum, pilih urutan yang menghasilkan jejak memori yang lebih rendah, kecuali urutan yang berbeda diinginkan untuk kinerja.
Caching komputasi parsial
Direkomendasikan untuk menyimpan dataset setelah transformasi map kecuali jika transformasi ini membuat data terlalu besar untuk disimpan dalam memori. Pertukaran dapat dicapai jika fungsi Anda yang dipetakan dapat dibagi menjadi dua bagian: bagian yang memakan waktu dan bagian yang memakan memori. Dalam hal ini, Anda dapat merantai transformasi Anda seperti di bawah ini:
dataset.map(time_consuming_mapping).cache().map(memory_consuming_mapping)
Dengan cara ini, bagian yang memakan waktu hanya dieksekusi selama epoch pertama, dan Anda menghindari penggunaan terlalu banyak ruang cache.
Ringkasan praktik terbaik
Berikut adalah ringkasan praktik terbaik untuk mendesain pipeline input TensorFlow yang berkinerja baik:
- Gunakan transformasi
prefetchuntuk tumpang tindih dengan pekerjaan produsen dan konsumen - Sejajarkan transformasi pembacaan data menggunakan transformasi
interleave - Sejajarkan transformasi
mapdengan menyetel argumennum_parallel_calls - Gunakan transformasi
cacheuntuk menyimpan data dalam memori selama epoch pertama - Vektorisasi fungsi yang ditentukan pengguna yang diteruskan ke transformasi
map - Kurangi penggunaan memori saat menerapkan transformasi
interleave,prefetch, danshuffle
Mereproduksi angka
Untuk memahami lebih dalam pemahaman tf.data.Dataset API, Anda dapat bermain dengan pipeline Anda sendiri. Di bawah ini adalah kode yang digunakan untuk memplot gambar dari panduan ini. Ini bisa menjadi titik awal yang baik, menunjukkan beberapa solusi untuk kesulitan umum seperti:
- Reproduksibilitas waktu eksekusi
- Fungsi yang dipetakan ingin dieksekusi
- transformasi
interleavedapat dipanggil
import itertools
from collections import defaultdict
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
kumpulan data
Mirip dengan ArtificialDataset , Anda dapat membuat kumpulan data yang mengembalikan waktu yang dihabiskan di setiap langkah.
class TimeMeasuredDataset(tf.data.Dataset):
# OUTPUT: (steps, timings, counters)
OUTPUT_TYPES = (tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32)
OUTPUT_SHAPES = ((2, 1), (2, 2), (2, 3))
_INSTANCES_COUNTER = itertools.count() # Number of datasets generated
_EPOCHS_COUNTER = defaultdict(itertools.count) # Number of epochs done for each dataset
def _generator(instance_idx, num_samples):
epoch_idx = next(TimeMeasuredDataset._EPOCHS_COUNTER[instance_idx])
# Opening the file
open_enter = time.perf_counter()
time.sleep(0.03)
open_elapsed = time.perf_counter() - open_enter
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
read_enter = time.perf_counter()
time.sleep(0.015)
read_elapsed = time.perf_counter() - read_enter
yield (
[("Open",), ("Read",)],
[(open_enter, open_elapsed), (read_enter, read_elapsed)],
[(instance_idx, epoch_idx, -1), (instance_idx, epoch_idx, sample_idx)]
)
open_enter, open_elapsed = -1., -1. # Negative values will be filtered
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_types=cls.OUTPUT_TYPES,
output_shapes=cls.OUTPUT_SHAPES,
args=(next(cls._INSTANCES_COUNTER), num_samples)
)
Dataset ini menyediakan contoh bentuk [[2, 1], [2, 2], [2, 3]] dan tipe [tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32] . Setiap sampel adalah:
(
[("Open"), ("Read")],
[(t0, d), (t0, d)],
[(i, e, -1), (i, e, s)]
)
Di mana:
-
OpendanReadadalah pengidentifikasi langkah -
t0adalah stempel waktu ketika langkah yang sesuai dimulai -
dadalah waktu yang dihabiskan dalam langkah yang sesuai -
iadalah indeks instance -
eadalah indeks Epoch (berapa kali dataset telah diulang) -
sadalah indeks sampel
Lingkaran iterasi
Buat loop iterasi sedikit lebih rumit untuk menggabungkan semua pengaturan waktu. Ini hanya akan berfungsi dengan kumpulan data yang menghasilkan sampel seperti yang dijelaskan di atas.
def timelined_benchmark(dataset, num_epochs=2):
# Initialize accumulators
steps_acc = tf.zeros([0, 1], dtype=tf.dtypes.string)
times_acc = tf.zeros([0, 2], dtype=tf.dtypes.float32)
values_acc = tf.zeros([0, 3], dtype=tf.dtypes.int32)
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
epoch_enter = time.perf_counter()
for (steps, times, values) in dataset:
# Record dataset preparation informations
steps_acc = tf.concat((steps_acc, steps), axis=0)
times_acc = tf.concat((times_acc, times), axis=0)
values_acc = tf.concat((values_acc, values), axis=0)
# Simulate training time
train_enter = time.perf_counter()
time.sleep(0.01)
train_elapsed = time.perf_counter() - train_enter
# Record training informations
steps_acc = tf.concat((steps_acc, [["Train"]]), axis=0)
times_acc = tf.concat((times_acc, [(train_enter, train_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [values[-1]]), axis=0)
epoch_elapsed = time.perf_counter() - epoch_enter
# Record epoch informations
steps_acc = tf.concat((steps_acc, [["Epoch"]]), axis=0)
times_acc = tf.concat((times_acc, [(epoch_enter, epoch_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [[-1, epoch_num, -1]]), axis=0)
time.sleep(0.001)
tf.print("Execution time:", time.perf_counter() - start_time)
return {"steps": steps_acc, "times": times_acc, "values": values_acc}
Metode merencanakan
Terakhir, tentukan fungsi yang dapat memplot garis waktu berdasarkan nilai yang dikembalikan oleh fungsi timelined_benchmark .
def draw_timeline(timeline, title, width=0.5, annotate=False, save=False):
# Remove invalid entries (negative times, or empty steps) from the timelines
invalid_mask = np.logical_and(timeline['times'] > 0, timeline['steps'] != b'')[:,0]
steps = timeline['steps'][invalid_mask].numpy()
times = timeline['times'][invalid_mask].numpy()
values = timeline['values'][invalid_mask].numpy()
# Get a set of different steps, ordered by the first time they are encountered
step_ids, indices = np.stack(np.unique(steps, return_index=True))
step_ids = step_ids[np.argsort(indices)]
# Shift the starting time to 0 and compute the maximal time value
min_time = times[:,0].min()
times[:,0] = (times[:,0] - min_time)
end = max(width, (times[:,0]+times[:,1]).max() + 0.01)
cmap = mpl.cm.get_cmap("plasma")
plt.close()
fig, axs = plt.subplots(len(step_ids), sharex=True, gridspec_kw={'hspace': 0})
fig.suptitle(title)
fig.set_size_inches(17.0, len(step_ids))
plt.xlim(-0.01, end)
for i, step in enumerate(step_ids):
step_name = step.decode()
ax = axs[i]
ax.set_ylabel(step_name)
ax.set_ylim(0, 1)
ax.set_yticks([])
ax.set_xlabel("time (s)")
ax.set_xticklabels([])
ax.grid(which="both", axis="x", color="k", linestyle=":")
# Get timings and annotation for the given step
entries_mask = np.squeeze(steps==step)
serie = np.unique(times[entries_mask], axis=0)
annotations = values[entries_mask]
ax.broken_barh(serie, (0, 1), color=cmap(i / len(step_ids)), linewidth=1, alpha=0.66)
if annotate:
for j, (start, width) in enumerate(serie):
annotation = "\n".join([f"{l}: {v}" for l,v in zip(("i", "e", "s"), annotations[j])])
ax.text(start + 0.001 + (0.001 * (j % 2)), 0.55 - (0.1 * (j % 2)), annotation,
horizontalalignment='left', verticalalignment='center')
if save:
plt.savefig(title.lower().translate(str.maketrans(" ", "_")) + ".svg")
Gunakan pembungkus untuk fungsi yang dipetakan
Untuk menjalankan fungsi yang dipetakan dalam konteks yang bersemangat, Anda harus membungkusnya di dalam panggilan tf.py_function .
def map_decorator(func):
def wrapper(steps, times, values):
# Use a tf.py_function to prevent auto-graph from compiling the method
return tf.py_function(
func,
inp=(steps, times, values),
Tout=(steps.dtype, times.dtype, values.dtype)
)
return wrapper
Perbandingan saluran pipa
_batch_map_num_items = 50
def dataset_generator_fun(*args):
return TimeMeasuredDataset(num_samples=_batch_map_num_items)
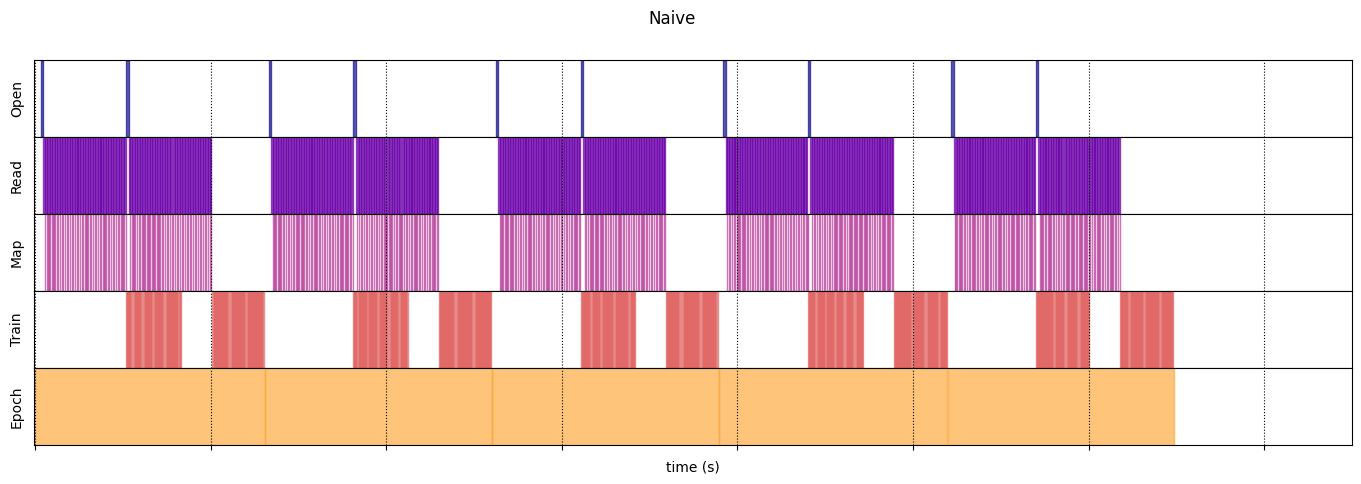
Naif
@map_decorator
def naive_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001) # Time consuming step
time.sleep(0.0001) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, [["Map"]]), axis=0),
tf.concat((times, [[map_enter, map_elapsed]]), axis=0),
tf.concat((values, [values[-1]]), axis=0)
)
naive_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.flat_map(dataset_generator_fun)
.map(naive_map)
.batch(_batch_map_num_items, drop_remainder=True)
.unbatch(),
5
)
WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_types is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_shapes is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead Execution time: 13.13538893499981
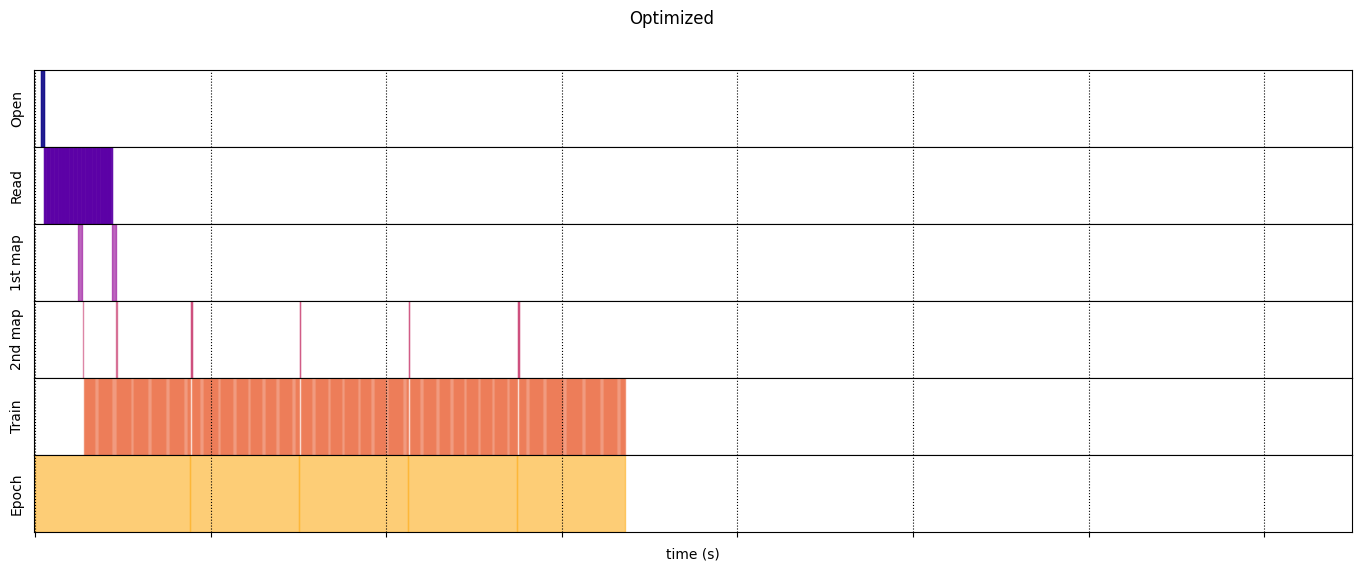
Dioptimalkan
@map_decorator
def time_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001 * values.shape[0]) # Time consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, tf.tile([[["1st map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
@map_decorator
def memory_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.0001 * values.shape[0]) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
# Use tf.tile to handle batch dimension
return (
tf.concat((steps, tf.tile([[["2nd map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
optimized_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.interleave( # Parallelize data reading
dataset_generator_fun,
num_parallel_calls=tf.data.AUTOTUNE
)
.batch( # Vectorize your mapped function
_batch_map_num_items,
drop_remainder=True)
.map( # Parallelize map transformation
time_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.cache() # Cache data
.map( # Reduce memory usage
memory_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.prefetch( # Overlap producer and consumer works
tf.data.AUTOTUNE
)
.unbatch(),
5
)
Execution time: 6.723691489999965
draw_timeline(naive_timeline, "Naive", 15)
draw_timeline(optimized_timeline, "Optimized", 15)