| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ওভারভিউ
জিপিইউ এবং টিপিইউগুলি একটি একক প্রশিক্ষণ পদক্ষেপ কার্যকর করার জন্য প্রয়োজনীয় সময়কে আমূল কমাতে পারে। সর্বোচ্চ কর্মক্ষমতা অর্জনের জন্য একটি দক্ষ ইনপুট পাইপলাইন প্রয়োজন যা বর্তমান পদক্ষেপটি শেষ হওয়ার আগে পরবর্তী ধাপের জন্য ডেটা সরবরাহ করে। tf.data API নমনীয় এবং দক্ষ ইনপুট পাইপলাইন তৈরি করতে সাহায্য করে। এই ডকুমেন্টটি দেখায় কিভাবে tf.data API ব্যবহার করে অত্যন্ত পারফরম্যান্ট TensorFlow ইনপুট পাইপলাইন তৈরি করতে হয়।
আপনি চালিয়ে যাওয়ার আগে, tf.data API কীভাবে ব্যবহার করবেন তা শিখতে বিল্ড টেনসরফ্লো ইনপুট পাইপলাইন গাইড দেখুন।
সম্পদ
- টেনসরফ্লো ইনপুট পাইপলাইন তৈরি করুন
-
tf.data.DatasetAPI - TF প্রোফাইলারের সাথে
tf.dataকর্মক্ষমতা বিশ্লেষণ করুন
সেটআপ
import tensorflow as tf
import time
এই নির্দেশিকা জুড়ে, আপনি একটি ডেটাসেট জুড়ে পুনরাবৃত্তি করবেন এবং কর্মক্ষমতা পরিমাপ করবেন। পুনরুত্পাদনযোগ্য কর্মক্ষমতা বেঞ্চমার্ক তৈরি করা কঠিন হতে পারে। প্রজননযোগ্যতাকে প্রভাবিত করে এমন বিভিন্ন কারণের মধ্যে রয়েছে:
- বর্তমান CPU লোড
- নেটওয়ার্ক ট্রাফিক
- জটিল প্রক্রিয়া, যেমন ক্যাশে
একটি প্রজননযোগ্য বেঞ্চমার্ক পেতে, আপনি একটি কৃত্রিম উদাহরণ তৈরি করবেন।
ডেটাসেট
ArtificialDataset ডেটাসেট নামক tf.data.Dataset থেকে উত্তরাধিকারসূত্রে প্রাপ্ত একটি শ্রেণী সংজ্ঞায়িত করে শুরু করুন। এই ডেটাসেট:
-
num_samplesনমুনা তৈরি করে (ডিফল্ট হল 3) - একটি ফাইল খোলার অনুকরণ করার জন্য প্রথম আইটেমের আগে কিছু সময়ের জন্য ঘুমায়
- একটি ফাইল থেকে ডেটা পড়ার অনুকরণ করতে প্রতিটি আইটেম তৈরি করার আগে কিছু সময়ের জন্য ঘুমায়
class ArtificialDataset(tf.data.Dataset):
def _generator(num_samples):
# Opening the file
time.sleep(0.03)
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
time.sleep(0.015)
yield (sample_idx,)
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_signature = tf.TensorSpec(shape = (1,), dtype = tf.int64),
args=(num_samples,)
)
এই ডেটাসেটটি tf.data.Dataset.range একের অনুরূপ, প্রতিটি নমুনার শুরুতে এবং এর মধ্যে একটি নির্দিষ্ট বিলম্ব যোগ করে।
প্রশিক্ষণ লুপ
এর পরে, একটি ডামি প্রশিক্ষণ লুপ লিখুন যা একটি ডেটাসেটের উপর পুনরাবৃত্তি করতে কতক্ষণ সময় নেয় তা পরিমাপ করে। প্রশিক্ষণ সময় অনুকরণ করা হয়.
def benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
for sample in dataset:
# Performing a training step
time.sleep(0.01)
print("Execution time:", time.perf_counter() - start_time)
কর্মক্ষমতা অপ্টিমাইজ করুন
কিভাবে কর্মক্ষমতা অপ্টিমাইজ করা যায় তা প্রদর্শন করতে, আপনি ArtificialDataset কর্মক্ষমতা উন্নত করবেন।
নিষ্পাপ পন্থা
কোনো কৌশল ব্যবহার না করে একটি নিষ্পাপ পাইপলাইন দিয়ে শুরু করুন, ডেটাসেট যেমন আছে তেমনিভাবে পুনরাবৃত্তি করুন।
benchmark(ArtificialDataset())
Execution time: 0.26497629899995445
হুডের নিচে, আপনার মৃত্যুদন্ডের সময় এভাবেই কেটেছে:

প্লটটি দেখায় যে একটি প্রশিক্ষণের পদক্ষেপের মধ্যে রয়েছে:
- একটি ফাইল খোলা হচ্ছে যদি এটি এখনও খোলা না হয়
- ফাইল থেকে একটি ডাটা এন্ট্রি আনা হচ্ছে
- প্রশিক্ষণের জন্য ডেটা ব্যবহার করা
যাইহোক, এখানকার মতো একটি নিষ্পাপ সিঙ্ক্রোনাস বাস্তবায়নে, আপনার পাইপলাইন ডেটা আনার সময়, আপনার মডেলটি নিষ্ক্রিয় বসে আছে। বিপরীতভাবে, আপনার মডেল প্রশিক্ষণের সময়, ইনপুট পাইপলাইন নিষ্ক্রিয় বসে আছে। প্রশিক্ষণের ধাপের সময়টি এইভাবে খোলা, পড়া এবং প্রশিক্ষণের সময়ের সমষ্টি।
পরবর্তী বিভাগগুলি এই ইনপুট পাইপলাইনের উপর তৈরি করে, পারফরম্যান্ট টেনসরফ্লো ইনপুট পাইপলাইনগুলি ডিজাইন করার জন্য সর্বোত্তম অনুশীলনগুলিকে চিত্রিত করে৷
প্রিফেচিং
প্রিফেচিং একটি প্রশিক্ষণ ধাপের প্রিপ্রসেসিং এবং মডেল এক্সিকিউশনকে ওভারল্যাপ করে। মডেলটি যখন ট্রেনিং স্টেপ s চালাচ্ছে, ইনপুট পাইপলাইন স্টেপ s+1 জন্য ডেটা পড়ছে। এটি করার ফলে প্রশিক্ষণের ধাপের সময় সর্বাধিক (সমষ্টির বিপরীতে) এবং ডেটা বের করতে যে সময় লাগে তা হ্রাস করে।
tf.data API tf.data.Dataset.prefetch রূপান্তর প্রদান করে। এটি ডেটা ব্যবহার করার সময় থেকে ডেটা উত্পাদিত হওয়ার সময়কে দ্বিগুণ করতে ব্যবহার করা যেতে পারে। বিশেষ করে, ট্রান্সফরমেশন একটি ব্যাকগ্রাউন্ড থ্রেড এবং একটি অভ্যন্তরীণ বাফার ব্যবহার করে ইনপুট ডেটাসেট থেকে উপাদানগুলিকে অনুরোধ করার আগে প্রিফেচ করতে। প্রি-ফেচ করার জন্য উপাদানের সংখ্যা একটি একক প্রশিক্ষণ ধাপে ব্যবহৃত ব্যাচের সংখ্যার সমান (বা সম্ভবত এর চেয়ে বেশি) হওয়া উচিত। আপনি হয় ম্যানুয়ালি এই মানটি টিউন করতে পারেন, অথবা এটিকে tf.data.AUTOTUNE সেট করতে পারেন, যা tf.data রানটাইমকে রানটাইমে গতিশীলভাবে মান টিউন করতে অনুরোধ করবে।
মনে রাখবেন যে প্রিফেচ ট্রান্সফরমেশন সুবিধা প্রদান করে যে কোন সময় একটি "উৎপাদক" এর কাজকে "ভোক্তার" কাজের সাথে ওভারল্যাপ করার সুযোগ থাকে।
benchmark(
ArtificialDataset()
.prefetch(tf.data.AUTOTUNE)
)
Execution time: 0.21731788600027357

এখন, যেমন ডেটা এক্সিকিউশন টাইম প্লট দেখায়, যখন নমুনা 0-এর জন্য প্রশিক্ষণের ধাপ চলছে, ইনপুট পাইপলাইন নমুনা 1-এর জন্য ডেটা পড়ছে, ইত্যাদি।
সমান্তরাল তথ্য নিষ্কাশন
একটি বাস্তব-বিশ্বের সেটিংসে, ইনপুট ডেটা দূরবর্তীভাবে সংরক্ষণ করা যেতে পারে (উদাহরণস্বরূপ, Google ক্লাউড স্টোরেজ বা HDFS-এ)। একটি ডেটাসেট পাইপলাইন যা স্থানীয়ভাবে ডেটা পড়ার সময় ভাল কাজ করে তা স্থানীয় এবং দূরবর্তী স্টোরেজের মধ্যে নিম্নলিখিত পার্থক্যগুলির কারণে দূরবর্তীভাবে ডেটা পড়ার সময় I/O তে বাধা হয়ে যেতে পারে:
- টাইম-টু-ফার্স্ট-বাইট : রিমোট স্টোরেজ থেকে ফাইলের প্রথম বাইট পড়া স্থানীয় স্টোরেজের চেয়ে বেশি মাত্রার অর্ডার নিতে পারে।
- রিড থ্রুপুট : রিমোট স্টোরেজ সাধারণত বড় সামগ্রিক ব্যান্ডউইথ অফার করে, একটি একক ফাইল পড়া শুধুমাত্র এই ব্যান্ডউইথের একটি ছোট ভগ্নাংশ ব্যবহার করতে সক্ষম হতে পারে।
উপরন্তু, একবার কাঁচা বাইটগুলি মেমরিতে লোড হয়ে গেলে, ডেটা ডিসিরিয়ালাইজ এবং/অথবা ডিক্রিপ্ট করার প্রয়োজন হতে পারে (যেমন protobuf ), যার জন্য অতিরিক্ত গণনার প্রয়োজন। ডেটা স্থানীয়ভাবে বা দূরবর্তীভাবে সংরক্ষিত হোক না কেন এই ওভারহেডটি উপস্থিত থাকে, তবে ডেটা কার্যকরভাবে প্রিফেচ করা না হলে দূরবর্তী ক্ষেত্রে আরও খারাপ হতে পারে।
বিভিন্ন ডেটা এক্সট্রাকশন ওভারহেডের প্রভাব কমাতে, tf.data.Dataset.interleave ট্রান্সফরমেশন ডেটা লোডিং ধাপকে সমান্তরাল করতে ব্যবহার করা যেতে পারে, অন্যান্য ডেটাসেটের বিষয়বস্তু (যেমন ডেটা ফাইল রিডার) ইন্টারলিভ করে। ওভারল্যাপ করার জন্য ডেটাসেটের সংখ্যা cycle_length যুক্তি দ্বারা নির্দিষ্ট করা যেতে পারে, যখন সমান্তরালতার num_parallel_calls আর্গুমেন্ট দ্বারা নির্দিষ্ট করা যেতে পারে। prefetch ট্রান্সফর্মেশনের মতোই, interleave ট্রান্সফরমেশন tf.data.AUTOTUNE সমর্থন করে, যা tf.data রানটাইমে কোন স্তরের সমান্তরালতা ব্যবহার করবে সে বিষয়ে সিদ্ধান্ত অর্পণ করবে।
অনুক্রমিক ইন্টারলিভ
tf.data.Dataset.interleave ট্রান্সফরমেশনের ডিফল্ট আর্গুমেন্ট এটিকে দুটি ডেটাসেট থেকে ক্রমিকভাবে আন্তঃলিভ একক নমুনা তৈরি করে।
benchmark(
tf.data.Dataset.range(2)
.interleave(lambda _: ArtificialDataset())
)
Execution time: 0.4987426460002098

এই ডেটা এক্সিকিউশন টাইম প্লটটি interleave ট্রান্সফরমেশনের আচরণ প্রদর্শন করতে দেয়, বিকল্পভাবে উপলব্ধ দুটি ডেটাসেট থেকে নমুনা সংগ্রহ করে। যাইহোক, কোন কর্মক্ষমতা উন্নতি এখানে জড়িত নেই.
সমান্তরাল ইন্টারলিভ
এখন, interleave ট্রান্সফর্মেশনের num_parallel_calls আর্গুমেন্ট ব্যবহার করুন। এটি সমান্তরালভাবে একাধিক ডেটাসেট লোড করে, ফাইলগুলি খোলার জন্য অপেক্ষা করার সময় কমিয়ে দেয়।
benchmark(
tf.data.Dataset.range(2)
.interleave(
lambda _: ArtificialDataset(),
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.283668874000341

এই সময়, ডেটা এক্সিকিউশন টাইম প্লট দেখায়, দুটি ডেটাসেটের রিডিং সমান্তরালভাবে করা হয়েছে, যা গ্লোবাল ডেটা প্রসেসিং টাইম কমিয়েছে।
সমান্তরাল তথ্য রূপান্তর
ডেটা প্রস্তুত করার সময়, ইনপুট উপাদানগুলিকে প্রি-প্রসেস করার প্রয়োজন হতে পারে। এই লক্ষ্যে, tf.data API tf.data.Dataset.map রূপান্তর অফার করে, যা ইনপুট ডেটাসেটের প্রতিটি উপাদানে একটি ব্যবহারকারী-সংজ্ঞায়িত ফাংশন প্রয়োগ করে। যেহেতু ইনপুট উপাদান একে অপরের থেকে স্বাধীন, তাই প্রাক-প্রক্রিয়াকরণ একাধিক CPU কোর জুড়ে সমান্তরাল হতে পারে। এটি সম্ভব করার জন্য, একইভাবে prefetch এবং interleave ট্রান্সফর্মেশন, map ট্রান্সফর্মেশন সমান্তরালতার স্তর নির্দিষ্ট করার জন্য num_parallel_calls আর্গুমেন্ট প্রদান করে।
num_parallel_calls আর্গুমেন্টের জন্য সর্বোত্তম মান নির্বাচন করা আপনার হার্ডওয়্যার, আপনার প্রশিক্ষণ ডেটার বৈশিষ্ট্য (যেমন এর আকার এবং আকৃতি), আপনার মানচিত্র ফাংশনের খরচ এবং একই সময়ে CPU-তে অন্যান্য প্রক্রিয়াকরণের উপর নির্ভর করে। একটি সহজ হিউরিস্টিক হল উপলব্ধ CPU কোরের সংখ্যা ব্যবহার করা। যাইহোক, prefetch এবং interleave ট্রান্সফর্মেশনের জন্য, map ট্রান্সফরমেশন tf.data.AUTOTUNE সমর্থন করে যা tf.data রানটাইমে কোন স্তরের সমান্তরালতা ব্যবহার করবে সে বিষয়ে সিদ্ধান্ত অর্পণ করবে।
def mapped_function(s):
# Do some hard pre-processing
tf.py_function(lambda: time.sleep(0.03), [], ())
return s
অনুক্রমিক ম্যাপিং
বেসলাইন উদাহরণ হিসাবে সমান্তরালতা ছাড়াই map রূপান্তর ব্যবহার করে শুরু করুন।
benchmark(
ArtificialDataset()
.map(mapped_function)
)
Execution time: 0.4505277170001136

নিষ্পাপ পদ্ধতির জন্য, এখানে, যেমন প্লট দেখায়, খোলা, পড়া, প্রাক-প্রক্রিয়াকরণ (ম্যাপিং) এবং প্রশিক্ষণের ধাপগুলির জন্য ব্যয় করা সময়গুলি একক পুনরাবৃত্তির জন্য একসাথে।
সমান্তরাল ম্যাপিং
এখন, একই প্রাক-প্রসেসিং ফাংশন ব্যবহার করুন কিন্তু একাধিক নমুনায় সমান্তরালভাবে প্রয়োগ করুন।
benchmark(
ArtificialDataset()
.map(
mapped_function,
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.2839677860001757

ডেটা প্লট যেমন দেখায়, প্রি-প্রসেসিং ধাপগুলি ওভারল্যাপ করে, একটি একক পুনরাবৃত্তির জন্য সামগ্রিক সময় হ্রাস করে।
ক্যাশিং
tf.data.Dataset.cache রূপান্তর একটি ডেটাসেট ক্যাশে করতে পারে, হয় মেমরিতে বা স্থানীয় স্টোরেজে। এটি প্রতিটি যুগে কিছু ক্রিয়াকলাপ (যেমন ফাইল খোলা এবং ডেটা রিডিং) কার্যকর করা থেকে বাঁচাবে।
benchmark(
ArtificialDataset()
.map( # Apply time consuming operations before cache
mapped_function
).cache(
),
5
)
Execution time: 0.3848854380003104

এখানে, ডেটা এক্সিকিউশন টাইম প্লট দেখায় যে আপনি যখন একটি ডেটাসেট ক্যাশে করেন, তখন cache একের আগে রূপান্তরগুলি (যেমন ফাইল খোলার এবং ডেটা রিডিং) শুধুমাত্র প্রথম যুগে কার্যকর হয়৷ পরবর্তী যুগগুলি cache রূপান্তর দ্বারা ক্যাশে করা ডেটা পুনঃব্যবহার করবে।
map রূপান্তরে পাস করা ব্যবহারকারী-সংজ্ঞায়িত ফাংশন ব্যয়বহুল হলে, map রূপান্তরের পরে cache রূপান্তর প্রয়োগ করুন যতক্ষণ না ফলস্বরূপ ডেটাসেট এখনও মেমরি বা স্থানীয় স্টোরেজে ফিট হতে পারে। যদি ব্যবহারকারী-সংজ্ঞায়িত ফাংশন ক্যাশে ক্ষমতার বাইরে ডেটাসেট সংরক্ষণ করার জন্য প্রয়োজনীয় স্থান বাড়ায়, হয় cache রূপান্তরের পরে এটি প্রয়োগ করুন বা সম্পদ ব্যবহার কমাতে আপনার প্রশিক্ষণ কাজের আগে আপনার ডেটা প্রাক-প্রসেস করার কথা বিবেচনা করুন।
ভেক্টরাইজিং ম্যাপিং
map রূপান্তরে পাস করা একটি ব্যবহারকারী-সংজ্ঞায়িত ফাংশন আহ্বান করা ব্যবহারকারী-সংজ্ঞায়িত ফাংশন নির্ধারণ এবং কার্যকর করার সাথে সম্পর্কিত ওভারহেড রয়েছে। ব্যবহারকারী-সংজ্ঞায়িত ফাংশন ভেক্টরাইজ করুন (অর্থাৎ, এটিকে একবারে ইনপুটগুলির একটি ব্যাচের উপর পরিচালনা করুন) এবং map রূপান্তরের আগে batch রূপান্তর প্রয়োগ করুন।
এই ভাল অভ্যাসটি ব্যাখ্যা করার জন্য, আপনার কৃত্রিম ডেটাসেট উপযুক্ত নয়। সময়সূচী বিলম্ব প্রায় 10 মাইক্রোসেকেন্ড (10e-6 সেকেন্ড), ArtificialDataset ডেটাসেটে ব্যবহৃত দশ মিলিসেকেন্ডের চেয়ে অনেক কম, এবং এইভাবে এর প্রভাব দেখা কঠিন।
এই উদাহরণের জন্য, বেস tf.data.Dataset.range ফাংশনটি ব্যবহার করুন এবং প্রশিক্ষণ লুপটিকে তার সহজতম ফর্মে সরল করুন।
fast_dataset = tf.data.Dataset.range(10000)
def fast_benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for _ in tf.data.Dataset.range(num_epochs):
for _ in dataset:
pass
tf.print("Execution time:", time.perf_counter() - start_time)
def increment(x):
return x+1
স্কেলার ম্যাপিং
fast_benchmark(
fast_dataset
# Apply function one item at a time
.map(increment)
# Batch
.batch(256)
)
Execution time: 0.2712608739998359

উপরের প্লটটি স্কেলার ম্যাপিং পদ্ধতি ব্যবহার করে (কম নমুনা সহ) কী চলছে তা চিত্রিত করে। এটি দেখায় যে ম্যাপ করা ফাংশন প্রতিটি নমুনার জন্য প্রয়োগ করা হয়। যদিও এই ফাংশনটি খুব দ্রুত, এটির কিছু ওভারহেড রয়েছে যা সময়ের কর্মক্ষমতাকে প্রভাবিত করে।
ভেক্টরাইজড ম্যাপিং
fast_benchmark(
fast_dataset
.batch(256)
# Apply function on a batch of items
# The tf.Tensor.__add__ method already handle batches
.map(increment)
)
Execution time: 0.02737950600021577

এই সময়, ম্যাপ করা ফাংশন একবার বলা হয় এবং নমুনার একটি ব্যাচে প্রযোজ্য। ডেটা এক্সিকিউশন টাইম প্লট দেখায়, যখন ফাংশনটি কার্যকর করতে আরও সময় লাগতে পারে, ওভারহেড শুধুমাত্র একবার প্রদর্শিত হয়, সামগ্রিক সময়ের কর্মক্ষমতা উন্নত করে।
মেমরি পদচিহ্ন হ্রাস
interleave , prefetch , এবং shuffle সহ অনেকগুলি রূপান্তর উপাদানগুলির একটি অভ্যন্তরীণ বাফার বজায় রাখে৷ map রূপান্তরে পাস করা ব্যবহারকারী-সংজ্ঞায়িত ফাংশন উপাদানগুলির আকার পরিবর্তন করে, তাহলে মানচিত্র রূপান্তরের ক্রম এবং উপাদানগুলিকে বাফার করে এমন রূপান্তরগুলি মেমরি ব্যবহারকে প্রভাবিত করে৷ সাধারণভাবে, এমন ক্রম বেছে নিন যার ফলে মেমরির পদচিহ্ন কম হয়, যদি না পারফরম্যান্সের জন্য ভিন্ন ক্রম পছন্দ হয়।
আংশিক গণনা ক্যাশিং
map রূপান্তরের পরে ডেটাসেট ক্যাশে করার পরামর্শ দেওয়া হয় যদি এই রূপান্তরটি মেমরিতে ফিট করার জন্য ডেটাকে খুব বড় করে তোলে। একটি ট্রেড-অফ অর্জন করা যেতে পারে যদি আপনার ম্যাপ করা ফাংশন দুটি ভাগে বিভক্ত করা যায়: একটি সময় গ্রাসকারী এবং একটি মেমরি গ্রাসকারী অংশ। এই ক্ষেত্রে, আপনি নীচের মত আপনার রূপান্তর চেইন করতে পারেন:
dataset.map(time_consuming_mapping).cache().map(memory_consuming_mapping)
এইভাবে, সময় গ্রাসকারী অংশটি শুধুমাত্র প্রথম যুগের সময় কার্যকর করা হয় এবং আপনি অত্যধিক ক্যাশে স্থান ব্যবহার করা এড়িয়ে যান।
সেরা অনুশীলনের সারাংশ
এখানে পারফরম্যান্স টেনসরফ্লো ইনপুট পাইপলাইন ডিজাইন করার জন্য সর্বোত্তম অনুশীলনের একটি সারসংক্ষেপ রয়েছে:
- একটি প্রযোজক এবং ভোক্তার কাজ ওভারল্যাপ করতে
prefetchরূপান্তর ব্যবহার করুন -
interleaveট্রান্সফর্মেশন ব্যবহার করে ডেটা রিডিং ট্রান্সফর্মেশনকে সমান্তরাল করুন -
num_parallel_callsআর্গুমেন্ট সেট করেmapরূপান্তরকে সমান্তরাল করুন - প্রথম যুগের সময় মেমরিতে ডেটা ক্যাশে করতে
cacheরূপান্তর ব্যবহার করুন - ভেক্টরাইজ ব্যবহারকারী-সংজ্ঞায়িত ফাংশন
mapরূপান্তরে পাস করে -
interleave,prefetchএবংshuffleট্রান্সফর্মেশন প্রয়োগ করার সময় মেমরির ব্যবহার হ্রাস করুন
পরিসংখ্যান পুনরুত্পাদন
tf.data.Dataset API বোঝার আরও গভীরে যেতে, আপনি নিজের পাইপলাইনগুলির সাথে খেলতে পারেন৷ নীচে এই নির্দেশিকা থেকে ইমেজ প্লট ব্যবহৃত কোড. এটি একটি ভাল সূচনা বিন্দু হতে পারে, সাধারণ অসুবিধাগুলির জন্য কিছু সমাধান দেখায় যেমন:
- সঞ্চালনের সময় প্রজননযোগ্যতা
- ম্যাপ করা ফাংশন আগ্রহী এক্সিকিউশন
-
interleaveট্রান্সফরমেশন কলেবল
import itertools
from collections import defaultdict
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
ডেটাসেট
ArtificialDataset ডেটাসেটের অনুরূপ আপনি প্রতিটি ধাপে ব্যয় করা সময় ফেরত দিয়ে একটি ডেটাসেট তৈরি করতে পারেন।
class TimeMeasuredDataset(tf.data.Dataset):
# OUTPUT: (steps, timings, counters)
OUTPUT_TYPES = (tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32)
OUTPUT_SHAPES = ((2, 1), (2, 2), (2, 3))
_INSTANCES_COUNTER = itertools.count() # Number of datasets generated
_EPOCHS_COUNTER = defaultdict(itertools.count) # Number of epochs done for each dataset
def _generator(instance_idx, num_samples):
epoch_idx = next(TimeMeasuredDataset._EPOCHS_COUNTER[instance_idx])
# Opening the file
open_enter = time.perf_counter()
time.sleep(0.03)
open_elapsed = time.perf_counter() - open_enter
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
read_enter = time.perf_counter()
time.sleep(0.015)
read_elapsed = time.perf_counter() - read_enter
yield (
[("Open",), ("Read",)],
[(open_enter, open_elapsed), (read_enter, read_elapsed)],
[(instance_idx, epoch_idx, -1), (instance_idx, epoch_idx, sample_idx)]
)
open_enter, open_elapsed = -1., -1. # Negative values will be filtered
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_types=cls.OUTPUT_TYPES,
output_shapes=cls.OUTPUT_SHAPES,
args=(next(cls._INSTANCES_COUNTER), num_samples)
)
এই ডেটাসেটটি [[2, 1], [2, 2], [2, 3]] এবং [tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32] ধরনের নমুনা প্রদান করে। প্রতিটি নমুনা হল:
(
[("Open"), ("Read")],
[(t0, d), (t0, d)],
[(i, e, -1), (i, e, s)]
)
কোথায়:
-
OpenএবংReadহল ধাপ শনাক্তকারী -
t0হল টাইমস্ট্যাম্প যখন সংশ্লিষ্ট ধাপ শুরু হয় -
dহল সংশ্লিষ্ট ধাপে ব্যয় করা সময় -
iউদাহরণ সূচক -
eহল যুগের সূচক (ডেটাসেটটি পুনরাবৃত্তি করা হয়েছে এমন সংখ্যা) -
sহল নমুনা সূচক
পুনরাবৃত্তি লুপ
সমস্ত সময় একত্রিত করতে পুনরাবৃত্তি লুপটিকে একটু জটিল করে তুলুন। এটি শুধুমাত্র উপরে বর্ণিত নমুনা তৈরি করা ডেটাসেটের সাথে কাজ করবে।
def timelined_benchmark(dataset, num_epochs=2):
# Initialize accumulators
steps_acc = tf.zeros([0, 1], dtype=tf.dtypes.string)
times_acc = tf.zeros([0, 2], dtype=tf.dtypes.float32)
values_acc = tf.zeros([0, 3], dtype=tf.dtypes.int32)
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
epoch_enter = time.perf_counter()
for (steps, times, values) in dataset:
# Record dataset preparation informations
steps_acc = tf.concat((steps_acc, steps), axis=0)
times_acc = tf.concat((times_acc, times), axis=0)
values_acc = tf.concat((values_acc, values), axis=0)
# Simulate training time
train_enter = time.perf_counter()
time.sleep(0.01)
train_elapsed = time.perf_counter() - train_enter
# Record training informations
steps_acc = tf.concat((steps_acc, [["Train"]]), axis=0)
times_acc = tf.concat((times_acc, [(train_enter, train_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [values[-1]]), axis=0)
epoch_elapsed = time.perf_counter() - epoch_enter
# Record epoch informations
steps_acc = tf.concat((steps_acc, [["Epoch"]]), axis=0)
times_acc = tf.concat((times_acc, [(epoch_enter, epoch_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [[-1, epoch_num, -1]]), axis=0)
time.sleep(0.001)
tf.print("Execution time:", time.perf_counter() - start_time)
return {"steps": steps_acc, "times": times_acc, "values": values_acc}
চক্রান্ত পদ্ধতি
পরিশেষে, timelined_benchmark ফাংশন দ্বারা প্রত্যাবর্তিত মানগুলি দিয়ে একটি টাইমলাইন প্লট করতে সক্ষম একটি ফাংশন সংজ্ঞায়িত করুন।
def draw_timeline(timeline, title, width=0.5, annotate=False, save=False):
# Remove invalid entries (negative times, or empty steps) from the timelines
invalid_mask = np.logical_and(timeline['times'] > 0, timeline['steps'] != b'')[:,0]
steps = timeline['steps'][invalid_mask].numpy()
times = timeline['times'][invalid_mask].numpy()
values = timeline['values'][invalid_mask].numpy()
# Get a set of different steps, ordered by the first time they are encountered
step_ids, indices = np.stack(np.unique(steps, return_index=True))
step_ids = step_ids[np.argsort(indices)]
# Shift the starting time to 0 and compute the maximal time value
min_time = times[:,0].min()
times[:,0] = (times[:,0] - min_time)
end = max(width, (times[:,0]+times[:,1]).max() + 0.01)
cmap = mpl.cm.get_cmap("plasma")
plt.close()
fig, axs = plt.subplots(len(step_ids), sharex=True, gridspec_kw={'hspace': 0})
fig.suptitle(title)
fig.set_size_inches(17.0, len(step_ids))
plt.xlim(-0.01, end)
for i, step in enumerate(step_ids):
step_name = step.decode()
ax = axs[i]
ax.set_ylabel(step_name)
ax.set_ylim(0, 1)
ax.set_yticks([])
ax.set_xlabel("time (s)")
ax.set_xticklabels([])
ax.grid(which="both", axis="x", color="k", linestyle=":")
# Get timings and annotation for the given step
entries_mask = np.squeeze(steps==step)
serie = np.unique(times[entries_mask], axis=0)
annotations = values[entries_mask]
ax.broken_barh(serie, (0, 1), color=cmap(i / len(step_ids)), linewidth=1, alpha=0.66)
if annotate:
for j, (start, width) in enumerate(serie):
annotation = "\n".join([f"{l}: {v}" for l,v in zip(("i", "e", "s"), annotations[j])])
ax.text(start + 0.001 + (0.001 * (j % 2)), 0.55 - (0.1 * (j % 2)), annotation,
horizontalalignment='left', verticalalignment='center')
if save:
plt.savefig(title.lower().translate(str.maketrans(" ", "_")) + ".svg")
ম্যাপ করা ফাংশন জন্য wrappers ব্যবহার করুন
একটি আগ্রহী প্রেক্ষাপটে ম্যাপ করা ফাংশন চালানোর জন্য, আপনাকে সেগুলিকে একটি tf.py_function কলের মধ্যে আবৃত করতে হবে।
def map_decorator(func):
def wrapper(steps, times, values):
# Use a tf.py_function to prevent auto-graph from compiling the method
return tf.py_function(
func,
inp=(steps, times, values),
Tout=(steps.dtype, times.dtype, values.dtype)
)
return wrapper
পাইপলাইন তুলনা
_batch_map_num_items = 50
def dataset_generator_fun(*args):
return TimeMeasuredDataset(num_samples=_batch_map_num_items)
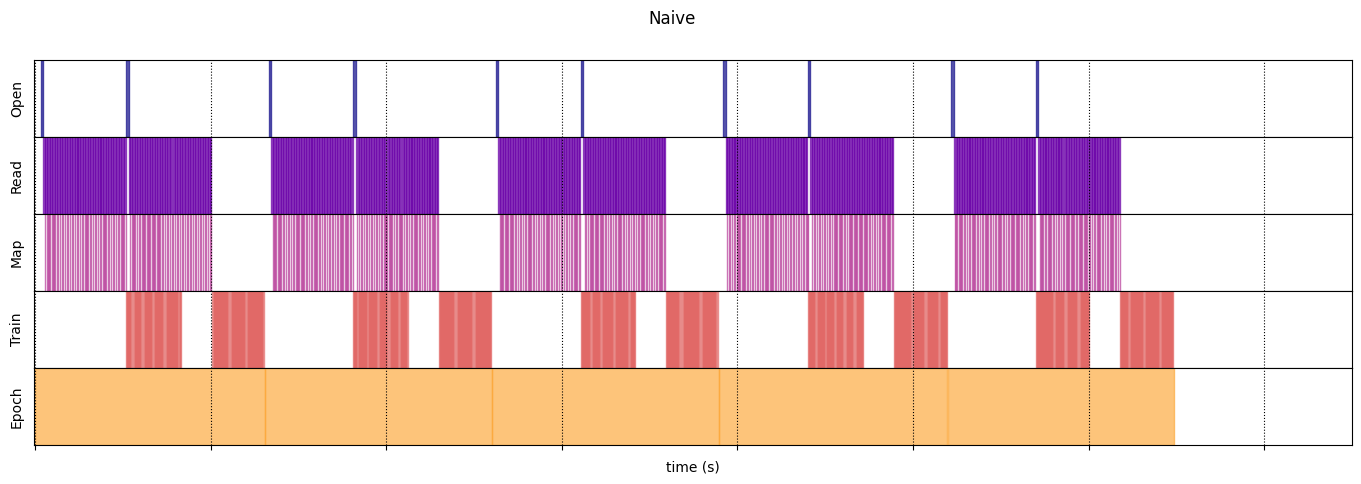
নিষ্পাপ
@map_decorator
def naive_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001) # Time consuming step
time.sleep(0.0001) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, [["Map"]]), axis=0),
tf.concat((times, [[map_enter, map_elapsed]]), axis=0),
tf.concat((values, [values[-1]]), axis=0)
)
naive_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.flat_map(dataset_generator_fun)
.map(naive_map)
.batch(_batch_map_num_items, drop_remainder=True)
.unbatch(),
5
)
WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_types is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_shapes is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead Execution time: 13.13538893499981
অপ্টিমাইজ করা হয়েছে
@map_decorator
def time_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001 * values.shape[0]) # Time consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, tf.tile([[["1st map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
@map_decorator
def memory_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.0001 * values.shape[0]) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
# Use tf.tile to handle batch dimension
return (
tf.concat((steps, tf.tile([[["2nd map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
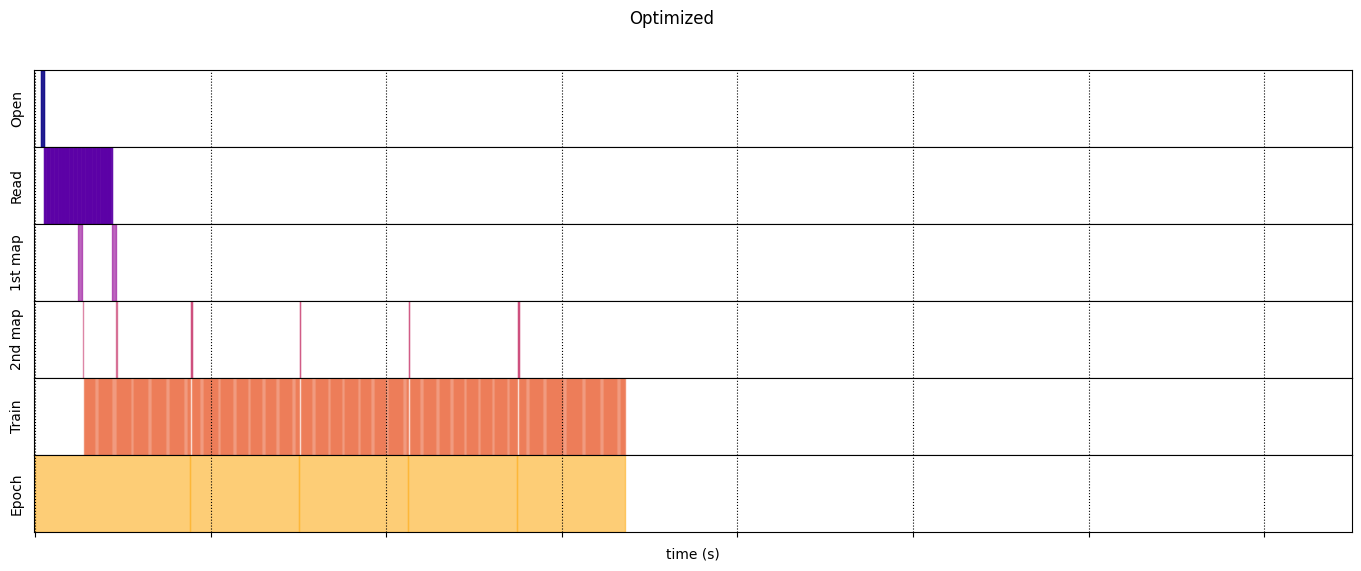
optimized_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.interleave( # Parallelize data reading
dataset_generator_fun,
num_parallel_calls=tf.data.AUTOTUNE
)
.batch( # Vectorize your mapped function
_batch_map_num_items,
drop_remainder=True)
.map( # Parallelize map transformation
time_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.cache() # Cache data
.map( # Reduce memory usage
memory_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.prefetch( # Overlap producer and consumer works
tf.data.AUTOTUNE
)
.unbatch(),
5
)
Execution time: 6.723691489999965
draw_timeline(naive_timeline, "Naive", 15)
draw_timeline(optimized_timeline, "Optimized", 15)