
| | |  Lihat sumber di GitHub Lihat sumber di GitHub |
Dokumentasi API: tf.RaggedTensor tf.ragged
Mempersiapkan
import math
import tensorflow as tf
Ringkasan
Data Anda datang dalam berbagai bentuk; tensor Anda juga harus. Tensor kasar adalah TensorFlow yang setara dengan daftar panjang variabel bersarang. Mereka memudahkan untuk menyimpan dan memproses data dengan bentuk yang tidak seragam, termasuk:
- Fitur panjang variabel, seperti set aktor dalam film.
- Kumpulan input berurutan dengan panjang variabel, seperti kalimat atau klip video.
- Input hierarkis, seperti dokumen teks yang dibagi lagi menjadi beberapa bagian, paragraf, kalimat, dan kata.
- Bidang individu dalam input terstruktur, seperti buffer protokol.
Apa yang dapat Anda lakukan dengan tensor compang-camping
Tensor kasar didukung oleh lebih dari seratus operasi TensorFlow, termasuk operasi matematika (seperti tf.add dan tf.reduce_mean ), operasi array (seperti tf.concat dan tf.tile ), operasi manipulasi string (seperti tf.substr ), mengontrol operasi aliran (seperti tf.while_loop dan tf.map_fn ), dan banyak lainnya:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
Ada juga sejumlah metode dan operasi yang khusus untuk tensor kasar, termasuk metode pabrik, metode konversi, dan operasi pemetaan nilai. Untuk daftar operasi yang didukung, lihat dokumentasi paket tf.ragged .
Tensor kasar didukung oleh banyak API TensorFlow, termasuk Keras , Datasets , tf.function , SavedModels , dan tf.Example . Untuk informasi selengkapnya, periksa bagian tentang TensorFlow API di bawah.
Seperti halnya tensor normal, Anda dapat menggunakan pengindeksan gaya Python untuk mengakses irisan tertentu dari tensor yang tidak rata. Untuk informasi lebih lanjut, lihat bagian Pengindeksan di bawah ini.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
Dan seperti tensor normal, Anda dapat menggunakan operator aritmatika dan perbandingan Python untuk melakukan operasi elemen. Untuk informasi lebih lanjut, periksa bagian Operator kelebihan beban di bawah ini.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
Jika Anda perlu melakukan transformasi elemen ke nilai RaggedTensor , Anda dapat menggunakan tf.ragged.map_flat_values , yang mengambil fungsi plus satu atau beberapa argumen, dan menerapkan fungsi untuk mengubah nilai RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Tensor yang tidak rata dapat dikonversi ke list Python bersarang s dan array NumPy s:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
Membangun tensor yang tidak rata
Cara paling sederhana untuk membuat tensor ragged adalah menggunakan tf.ragged.constant , yang membangun RaggedTensor yang sesuai dengan list Python bersarang yang diberikan atau array NumPy :
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
Tensor kasar juga dapat dibuat dengan memasangkan tensor nilai datar dengan tensor partisi baris yang menunjukkan bagaimana nilai tersebut harus dibagi menjadi baris, menggunakan metode kelas pabrik seperti tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths , dan tf.RaggedTensor.from_row_splits .
tf.RaggedTensor.from_value_rowids
Jika Anda mengetahui baris mana yang dimiliki oleh setiap nilai, Anda dapat membuat RaggedTensor menggunakan tensor partisi baris value_rowids :
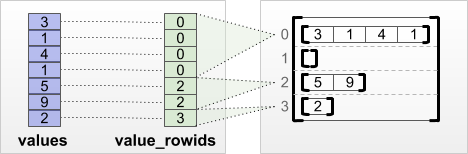
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
Jika Anda tahu berapa panjang setiap baris, maka Anda dapat menggunakan tensor partisi baris row_lengths :
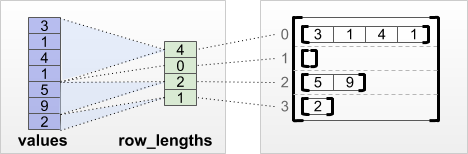
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
Jika Anda mengetahui indeks di mana setiap baris dimulai dan diakhiri, maka Anda dapat menggunakan tensor partisi baris row_splits :
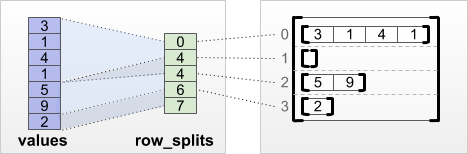
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Lihat dokumentasi kelas tf.RaggedTensor untuk daftar lengkap metode pabrik.
Apa yang dapat Anda simpan dalam tensor yang tidak rata
Seperti halnya Tensor s normal, nilai dalam RaggedTensor harus memiliki tipe yang sama; dan semua nilai harus berada pada kedalaman bersarang yang sama ( peringkat tensor):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
Contoh kasus penggunaan
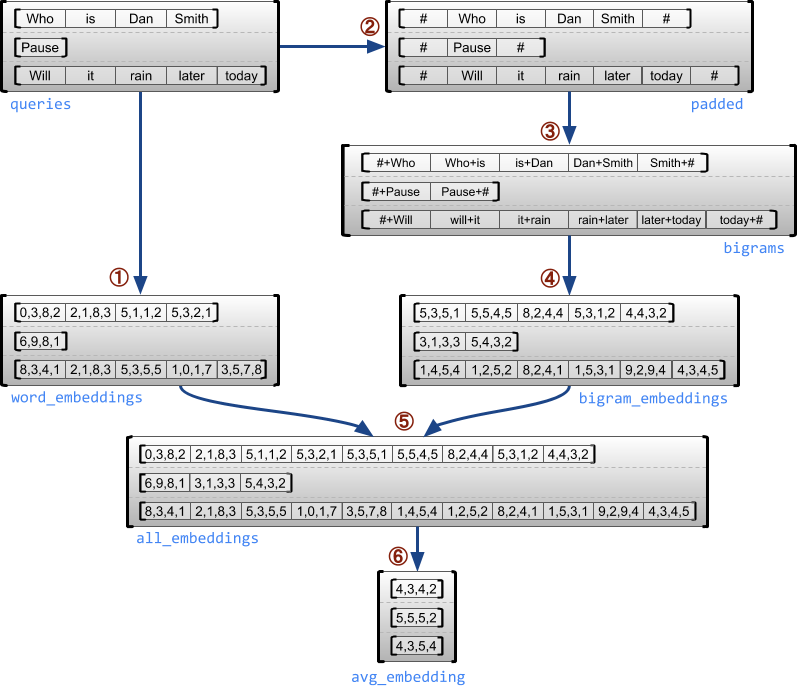
Contoh berikut menunjukkan bagaimana RaggedTensor s dapat digunakan untuk membuat dan menggabungkan penyematan unigram dan bigram untuk kumpulan kueri panjang variabel, menggunakan penanda khusus untuk awal dan akhir setiap kalimat. Untuk detail lebih lanjut tentang operasi yang digunakan dalam contoh ini, periksa dokumentasi paket tf.ragged .
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
Dimensi kasar dan seragam
Dimensi tidak rata adalah dimensi yang irisannya mungkin memiliki panjang yang berbeda. Misalnya, dimensi dalam (kolom) dari rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] tidak rata, karena irisan kolom ( rt[0, :] , ..., rt[4, :] ) memiliki panjang yang berbeda. Dimensi yang semua irisannya memiliki panjang yang sama disebut dimensi seragam .
Dimensi terluar dari ragged tensor selalu seragam, karena terdiri dari satu irisan (dan, oleh karena itu, tidak ada kemungkinan untuk panjang irisan yang berbeda). Dimensi yang tersisa dapat berupa compang-camping atau seragam. Misalnya, Anda dapat menyimpan penyisipan kata untuk setiap kata dalam kumpulan kalimat menggunakan tensor kasar dengan bentuk [num_sentences, (num_words), embedding_size] , di mana tanda kurung di sekitar (num_words) menunjukkan bahwa dimensi tidak rata.
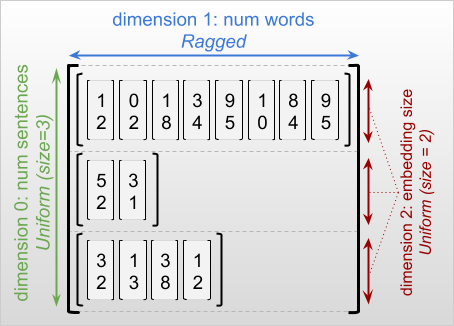
Tensor yang tidak rata mungkin memiliki beberapa dimensi yang tidak rata. Misalnya, Anda dapat menyimpan sekumpulan dokumen teks terstruktur menggunakan tensor dengan bentuk [num_documents, (num_paragraphs), (num_sentences), (num_words)] (di mana lagi tanda kurung digunakan untuk menunjukkan dimensi yang tidak rata).
Seperti halnya tf.Tensor , peringkat tensor kasar adalah jumlah total dimensinya (termasuk dimensi kasar dan seragam). Tensor yang berpotensi compang-camping adalah nilai yang mungkin berupa tf.Tensor atau tf.RaggedTensor .
Saat mendeskripsikan bentuk RaggedTensor, dimensi kasar secara konvensional ditunjukkan dengan melampirkannya dalam tanda kurung. Misalnya, seperti yang Anda lihat di atas, bentuk RaggedTensor 3D yang menyimpan penyisipan kata untuk setiap kata dalam kumpulan kalimat dapat ditulis sebagai [num_sentences, (num_words), embedding_size] .
Atribut RaggedTensor.shape mengembalikan tf.TensorShape untuk tensor ragged di mana dimensi ragged memiliki ukuran None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
Metode tf.RaggedTensor.bounding_shape dapat digunakan untuk menemukan bentuk pembatas ketat untuk RaggedTensor yang diberikan :
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Kasar vs jarang
Tensor yang tidak rata tidak boleh dianggap sebagai jenis tensor yang jarang. Secara khusus, sparse tensor adalah pengkodean yang efisien untuk tf.Tensor yang memodelkan data yang sama dalam format yang ringkas; tetapi ragged tensor adalah ekstensi untuk tf.Tensor yang memodelkan kelas data yang diperluas. Perbedaan ini sangat penting ketika mendefinisikan operasi:
- Menerapkan op ke tensor yang jarang atau padat harus selalu memberikan hasil yang sama.
- Menerapkan op ke tensor yang tidak rata atau jarang dapat memberikan hasil yang berbeda.
Sebagai contoh ilustrasi, pertimbangkan bagaimana operasi larik seperti concat , stack , dan tile didefinisikan untuk tensor ragged vs. sparse. Tensor kasar yang digabungkan bergabung dengan setiap baris untuk membentuk satu baris dengan panjang gabungan:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
Namun, menggabungkan tensor jarang sama dengan menggabungkan tensor padat yang sesuai, seperti yang diilustrasikan oleh contoh berikut (di mana menunjukkan nilai yang hilang):
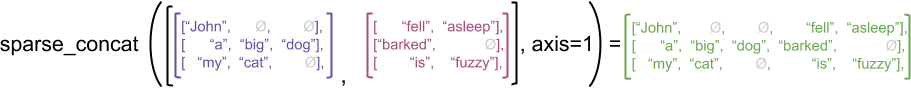
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
Untuk contoh lain mengapa perbedaan ini penting, pertimbangkan definisi "nilai rata-rata setiap baris" untuk operasi seperti tf.reduce_mean . Untuk tensor yang tidak rata, nilai rata-rata untuk suatu baris adalah jumlah nilai baris dibagi dengan lebar baris. Tetapi untuk tensor jarang, nilai rata-rata untuk suatu baris adalah jumlah nilai baris dibagi dengan lebar keseluruhan tensor jarang (yang lebih besar dari atau sama dengan lebar baris terpanjang).
API TensorFlow
Keras
tf.keras adalah API tingkat tinggi TensorFlow untuk membangun dan melatih model pembelajaran mendalam. Tensor yang tidak rata dapat diteruskan sebagai input ke model Keras dengan menyetel ragged=True pada tf.keras.Input atau tf.keras.layers.InputLayer . Tensor kasar juga dapat dilewatkan di antara lapisan Keras, dan dikembalikan oleh model Keras. Contoh berikut menunjukkan model LSTM mainan yang dilatih menggunakan tensor kasar.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.Contoh
tf.Example adalah enkode protobuf standar untuk data TensorFlow. Data yang dikodekan dengan tf.Example s sering kali menyertakan fitur panjang variabel. Misalnya, kode berikut mendefinisikan kumpulan empat pesan tf.Example dengan panjang fitur yang berbeda:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
Anda dapat mengurai data yang disandikan ini menggunakan tf.io.parse_example , yang mengambil tensor dari string bersambung dan kamus spesifikasi fitur, dan mengembalikan nama fitur pemetaan kamus ke tensor. Untuk membaca fitur panjang variabel menjadi tensor kasar, Anda cukup menggunakan tf.io.RaggedFeature dalam kamus spesifikasi fitur:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature juga dapat digunakan untuk membaca fitur dengan beberapa dimensi yang tidak rata. Untuk detailnya, lihat dokumentasi API .
Kumpulan data
tf.data adalah API yang memungkinkan Anda membangun saluran input yang kompleks dari bagian sederhana yang dapat digunakan kembali. Struktur data intinya adalah tf.data.Dataset , yang mewakili urutan elemen, di mana setiap elemen terdiri dari satu atau lebih komponen.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
Membangun Kumpulan Data dengan tensor kasar
Kumpulan data dapat dibuat dari tensor yang tidak rata menggunakan metode yang sama yang digunakan untuk membuatnya dari tf.Tensor s atau NumPy array , seperti Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Batching dan unbatching Dataset dengan tensor kasar
Kumpulan data dengan tensor kasar dapat di-batch (yang menggabungkan n elemen berurutan menjadi satu elemen) menggunakan metode Dataset.batch .
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
Sebaliknya, kumpulan data batch dapat diubah menjadi kumpulan data datar menggunakan Dataset.unbatch .
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Batching Dataset dengan tensor non-ragged dengan panjang variabel
Jika Anda memiliki Dataset yang berisi tensor tidak kasar, dan panjang tensor bervariasi antar elemen, maka Anda dapat mengelompokkan tensor tidak kasar tersebut menjadi tensor tidak rata dengan menerapkan transformasi dense_to_ragged_batch :
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
Mengubah Kumpulan Data dengan tensor kasar
Anda juga dapat membuat atau mengubah tensor yang tidak rata di Dataset menggunakan Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.fungsi
tf.function adalah dekorator yang menghitung grafik TensorFlow untuk fungsi Python, yang secara substansial dapat meningkatkan kinerja kode TensorFlow Anda. Tensor yang tidak rata dapat digunakan secara transparan dengan fungsi yang didekorasi dengan @tf.function . Misalnya, fungsi berikut ini berfungsi dengan tensor yang tidak rata dan tidak kasar:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
Jika Anda ingin secara eksplisit menentukan input_signature untuk tf.function , maka Anda dapat melakukannya menggunakan tf.RaggedTensorSpec .
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
Fungsi konkret
Fungsi konkret merangkum grafik terlacak individu yang dibangun oleh tf.function . Tensor kasar dapat digunakan secara transparan dengan fungsi konkret.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
Model Tersimpan
SavedModel adalah program TensorFlow serial, termasuk bobot dan komputasi. Itu dapat dibangun dari model Keras atau dari model khusus. Dalam kedua kasus tersebut, tensor yang tidak rata dapat digunakan secara transparan dengan fungsi dan metode yang ditentukan oleh SavedModel.
Contoh: menyimpan model Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
Contoh: menyimpan model khusus
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
Operator kelebihan beban
Kelas RaggedTensor membebani operator aritmatika dan perbandingan Python standar, membuatnya mudah untuk melakukan matematika elementwise dasar:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
Karena operator yang kelebihan beban melakukan perhitungan elemen, input ke semua operasi biner harus memiliki bentuk yang sama atau dapat disiarkan ke bentuk yang sama. Dalam kasus penyiaran paling sederhana, skalar tunggal digabungkan secara elemen dengan setiap nilai dalam tensor yang tidak rata:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Untuk diskusi tentang kasus yang lebih lanjut, periksa bagian Penyiaran .
Tensor kasar membebani set operator yang sama seperti Tensor s normal: operator unary - , ~ , dan abs() ; dan operator biner + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > , dan >= .
pengindeksan
Tensor kasar mendukung pengindeksan gaya Python, termasuk pengindeksan dan pemotongan multidimensi. Contoh berikut menunjukkan pengindeksan ragged tensor dengan tensor ragged 2D dan 3D.
Contoh pengindeksan: tensor compang-camping 2D
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
Contoh pengindeksan: tensor compang-camping 3D
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor mendukung pengindeksan dan pemotongan multidimensi dengan satu batasan: pengindeksan ke dimensi kasar tidak diperbolehkan. Kasus ini bermasalah karena nilai yang ditunjukkan mungkin ada di beberapa baris tetapi tidak di baris lainnya. Dalam kasus seperti itu, tidak jelas apakah Anda harus (1) menaikkan IndexError ; (2) menggunakan nilai default; atau (3) lewati nilai itu dan kembalikan tensor dengan baris lebih sedikit dari yang Anda mulai. Mengikuti prinsip panduan Python ("Dalam menghadapi ambiguitas, tolak godaan untuk menebak"), operasi ini saat ini tidak diizinkan.
Konversi jenis tensor
Kelas RaggedTensor mendefinisikan metode yang dapat digunakan untuk mengonversi antara RaggedTensor s dan tf.Tensor s atau tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
Mengevaluasi tensor yang tidak rata
Untuk mengakses nilai dalam tensor yang tidak rata, Anda dapat:
- Gunakan
tf.RaggedTensor.to_listuntuk mengonversi tensor yang tidak rata menjadi daftar Python bersarang. - Gunakan
tf.RaggedTensor.numpyuntuk mengonversi tensor yang tidak rata menjadi array NumPy yang nilainya adalah array NumPy bersarang. - Dekomposisi tensor kasar menjadi komponennya, menggunakan properti
tf.RaggedTensor.valuesdantf.RaggedTensor.row_splits, atau metode pembagian baris sepertitf.RaggedTensor.row_lengthsdantf.RaggedTensor.value_rowids. - Gunakan pengindeksan Python untuk memilih nilai dari tensor yang tidak rata.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
Penyiaran
Broadcasting adalah proses membuat tensor dengan bentuk yang berbeda memiliki bentuk yang kompatibel untuk operasi elemen. Untuk latar belakang lebih lanjut tentang penyiaran, lihat:
Langkah-langkah dasar untuk menyiarkan dua input x dan y agar memiliki bentuk yang kompatibel adalah:
Jika
xdanytidak memiliki jumlah dimensi yang sama, maka tambahkan dimensi luar (dengan ukuran 1) sampai ada.Untuk setiap dimensi di mana
xdanymemiliki ukuran yang berbeda:
- Jika
xatauymemiliki ukuran1dalam dimensid, maka ulangi nilainya di seluruh dimensidagar sesuai dengan ukuran input lainnya. - Jika tidak, buat pengecualian (
xdanytidak kompatibel dengan siaran).
Di mana ukuran tensor dalam dimensi seragam adalah satu angka (ukuran irisan melintasi dimensi itu); dan ukuran tensor dalam dimensi kasar adalah daftar panjang irisan (untuk semua irisan di dimensi tersebut).
Contoh penyiaran
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
Berikut beberapa contoh bentuk yang tidak menyiarkan:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
Pengkodean RaggedTensor
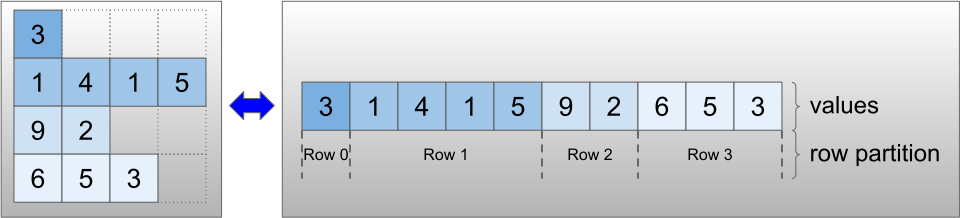
Tensor kasar dikodekan menggunakan kelas RaggedTensor . Secara internal, setiap RaggedTensor terdiri dari:
-
valuestensor, yang menggabungkan baris dengan panjang variabel ke dalam daftar yang diratakan. - Sebuah
row_partition, yang menunjukkan bagaimana nilai-nilai yang diratakan itu dibagi menjadi beberapa baris.
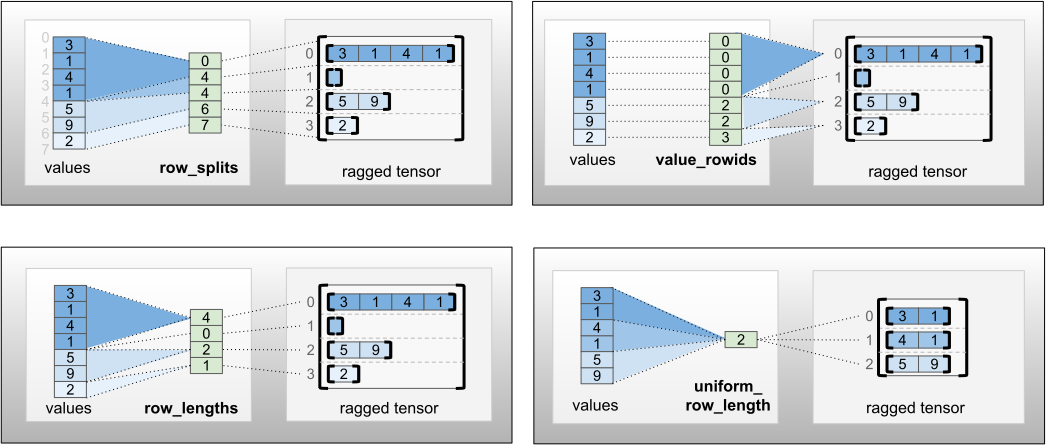
row_partition dapat disimpan menggunakan empat penyandian berbeda:
-
row_splitsadalah vektor bilangan bulat yang menentukan titik pemisahan antara baris. -
value_rowidsadalah vektor bilangan bulat yang menentukan indeks baris untuk setiap nilai. -
row_lengthsadalah vektor bilangan bulat yang menentukan panjang setiap baris. -
uniform_row_lengthadalah skalar bilangan bulat yang menentukan panjang tunggal untuk semua baris.
Sebuah nrows skalar integer juga dapat dimasukkan dalam pengkodean row_partition untuk memperhitungkan baris trailing kosong dengan value_rowids atau baris kosong dengan uniform_row_length .
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Pilihan pengkodean yang akan digunakan untuk partisi baris dikelola secara internal oleh tensor kasar untuk meningkatkan efisiensi dalam beberapa konteks. Secara khusus, beberapa keuntungan dan kerugian dari skema partisi baris yang berbeda adalah:
- Pengindeksan yang efisien :
row_splitsmemungkinkan pengindeksan dan pemotongan waktu konstan menjadi tensor yang tidak rata. - Penggabungan yang efisien : Pengkodean
row_lengthslebih efisien saat menggabungkan tensor yang tidak rata, karena panjang baris tidak berubah saat dua tensor digabungkan bersama. - Ukuran encoding kecil : Encoding
value_rowidslebih efisien saat menyimpan tensor kasar yang memiliki banyak baris kosong, karena ukuran tensor hanya bergantung pada jumlah total nilai. Di sisi lain, pengkodeanrow_splitsdanrow_lengthslebih efisien saat menyimpan tensor kasar dengan baris yang lebih panjang, karena hanya membutuhkan satu nilai skalar untuk setiap baris. - Kompatibilitas : Skema
value_rowidscocok dengan format segmentasi yang digunakan oleh operasi, sepertitf.segment_sum. Skemarow_limitscocok dengan format yang digunakan oleh operasi sepertitf.sequence_mask. - Dimensi seragam : Seperti yang dibahas di bawah ini, pengkodean
uniform_row_lengthdigunakan untuk mengkodekan tensor yang tidak rata dengan dimensi yang seragam.
Beberapa dimensi compang-camping
Tensor kasar dengan beberapa dimensi tidak rata dikodekan dengan menggunakan RaggedTensor bersarang untuk tensor values . Setiap RaggedTensor bersarang menambahkan satu dimensi kasar.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
Fungsi pabrik tf.RaggedTensor.from_nested_row_splits dapat digunakan untuk membuat RaggedTensor dengan beberapa dimensi compang-camping secara langsung dengan memberikan daftar tensor row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
Peringkat compang-camping dan nilai datar
Peringkat ragged tensor ragged adalah berapa kali tensor values yang mendasari telah dipartisi (yaitu kedalaman sarang objek RaggedTensor ). Tensor values terdalam dikenal sebagai flat_values . Dalam contoh berikut, conversations memiliki ragged_rank=3, dan flat_values -nya adalah Tensor 1D dengan 24 string:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
Dimensi bagian dalam seragam
Tensor kasar dengan dimensi dalam yang seragam dikodekan dengan menggunakan tf.Tensor multidimensi untuk flat_values (yaitu, values terdalam ).
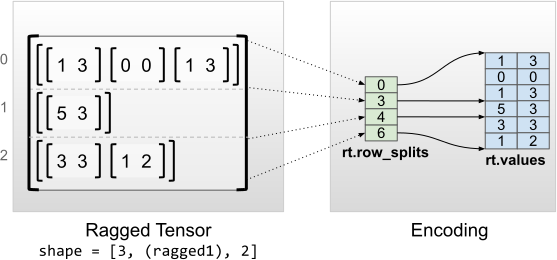
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
Dimensi non-dalam yang seragam
Tensor kasar dengan dimensi non-dalam yang seragam dikodekan dengan mempartisi baris dengan uniform_row_length .
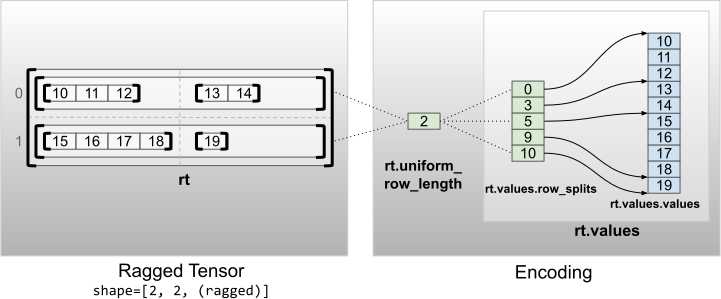
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2