
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub |
اسناد API: tf.RaggedTensor tf.ragged
برپایی
import math
import tensorflow as tf
بررسی اجمالی
داده های شما به اشکال مختلفی می آیند. تانسورهای شما نیز باید. تانسورهای Ragged معادل TensorFlow لیستهای طول متغیر تودرتو هستند. آنها ذخیره و پردازش داده ها را با اشکال غیر یکنواخت آسان می کنند، از جمله:
- ویژگی های با طول متغیر، مانند مجموعه بازیگران در یک فیلم.
- دستهای از ورودیهای متوالی با طول متغیر، مانند جملات یا کلیپهای ویدیویی.
- ورودی های سلسله مراتبی، مانند اسناد متنی که به بخش ها، پاراگراف ها، جملات و کلمات تقسیم می شوند.
- فیلدهای مجزا در ورودی های ساخت یافته، مانند بافرهای پروتکل.
کاری که می توانید با یک تانسور ناهموار انجام دهید
تانسورهای Ragged توسط بیش از صد عملیات TensorFlow پشتیبانی می شوند، از جمله عملیات ریاضی (مانند tf.add و tf.reduce_mean )، عملیات آرایه (مانند tf.concat و tf.tile )، عملیات دستکاری رشته (مانند tf.substr ، کنترل عملیات جریان (مانند tf.while_loop و tf.map_fn )، و بسیاری دیگر:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
تعدادی روش و عملیات نیز وجود دارد که مختص تانسورهای ناهموار است، از جمله روش های کارخانه، روش های تبدیل، و عملیات نگاشت ارزش. برای لیستی از عملیات های پشتیبانی شده، به مستندات بسته tf.ragged مراجعه کنید.
تانسورهای Ragged توسط بسیاری از APIهای TensorFlow پشتیبانی میشوند، از جمله Keras ، Datasets ، tf.function ، SavedModels ، و tf.Example . برای اطلاعات بیشتر، بخش مربوط به API های TensorFlow را در زیر بررسی کنید.
همانند تانسورهای معمولی، میتوانید از نمایهسازی به سبک پایتون برای دسترسی به برشهای خاصی از یک تانسور ناهموار استفاده کنید. برای اطلاعات بیشتر به بخش نمایه سازی زیر مراجعه کنید.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
و درست مانند تانسورهای معمولی، میتوانید از عملگرهای محاسباتی و مقایسه پایتون برای انجام عملیات عنصری استفاده کنید. برای اطلاعات بیشتر، بخش اپراتورهای Overloaded را در زیر بررسی کنید.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
اگر نیاز به تبدیل عنصری به مقادیر یک RaggedTensor دارید، میتوانید از tf.ragged.map_flat_values استفاده کنید که یک تابع به اضافه یک یا چند آرگومان میگیرد و تابع را برای تبدیل مقادیر RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
تانسورهای Ragged را می توان به list های پایتون تودرتو و array NumPy تبدیل کرد:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
ساخت یک تانسور ناهموار
ساده ترین راه برای ساختن یک تانسور ragged استفاده از tf.ragged.constant است که RaggedTensor مربوط به یک list تودرتو پایتون یا array NumPy می سازد:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
تانسورهای Ragged را میتوان با جفت کردن تانسورهای مقادیر مسطح با تانسورهای تقسیمبندی ردیفی ساخت که نشان میدهد چگونه آن مقادیر باید به ردیفها تقسیم شوند، با استفاده از روشهای tf.RaggedTensor.from_row_splits کارخانهای مانند tf.RaggedTensor.from_value_rowids ، tf.RaggedTensor.from_row_lengths .
tf.RaggedTensor.from_value_rowids
اگر میدانید هر مقدار به کدام ردیف تعلق دارد، میتوانید با استفاده از یک تانسور تقسیمبندی ردیف value_rowids یک RaggedTensor بسازید:
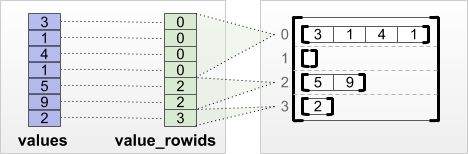
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
اگر میدانید طول هر ردیف چقدر است، میتوانید از یک تانسور تقسیمبندی ردیف row_lengths استفاده کنید:
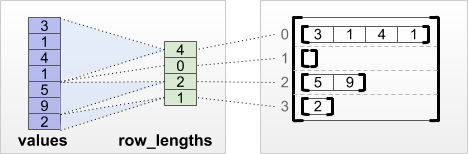
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
اگر ایندکس را می دانید که هر سطر از آنجا شروع و به پایان می رسد، می توانید از یک row_splits row-partitioning استفاده کنید:
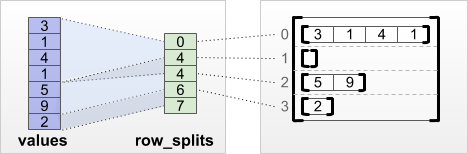
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
برای لیست کامل روش های کارخانه به مستندات کلاس tf.RaggedTensor مراجعه کنید.
آنچه می توانید در یک تانسور ناهموار ذخیره کنید
همانند Tensor معمولی، مقادیر در یک RaggedTensor همگی باید از یک نوع باشند. و همه مقادیر باید در یک عمق تودرتو باشند ( رتبه تانسور):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
مثال استفاده
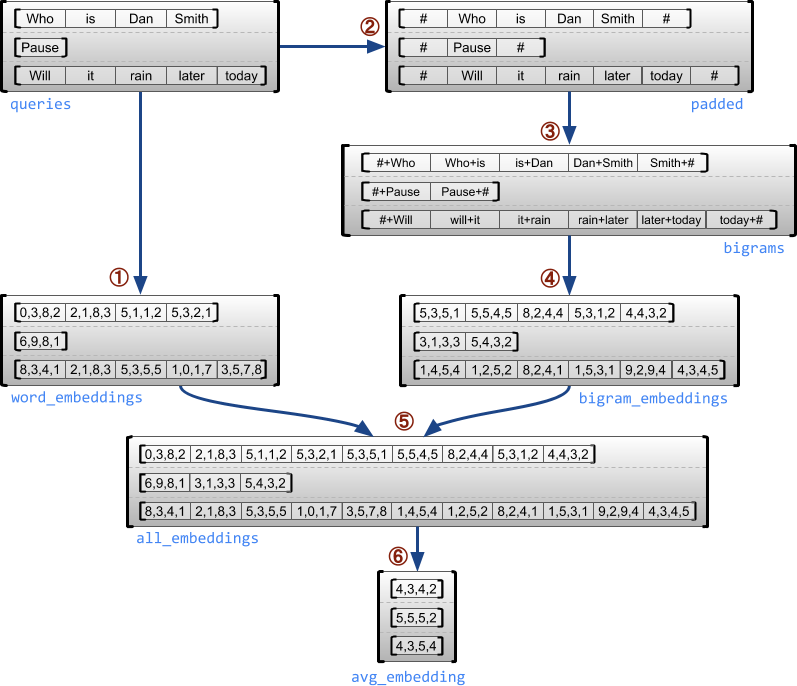
مثال زیر نشان میدهد که چگونه از RaggedTensor میتوان برای ساخت و ترکیب جاسازیهای unigram و bigram برای دستهای از جستارهای با طول متغیر، با استفاده از نشانگرهای ویژه برای ابتدا و انتهای هر جمله استفاده کرد. برای جزئیات بیشتر در مورد عملیات استفاده شده در این مثال، مستندات بسته tf.ragged را بررسی کنید.
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
ابعاد ناهموار و یکنواخت
بُعد ژندهدار ابعادی است که برشهای آن ممکن است طولهای متفاوتی داشته باشند. به عنوان مثال، بعد داخلی (ستون) rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] ناهموار است، زیرا ستون برش ( rt[0, :] , ..., rt[4, :] ) طول های مختلفی دارند. به ابعادی که برش های آن ها طول یکسانی دارند، ابعاد یکنواخت می گویند.
بیرونیترین بعد یک تانسور ژندهدار همیشه یکنواخت است، زیرا از یک تکه تشکیل شده است (و بنابراین، هیچ امکانی برای طولهای برش متفاوت وجود ندارد). ابعاد باقیمانده ممکن است ناهموار یا یکنواخت باشند. برای مثال، میتوانید واژههای embeddings را برای هر کلمه در دستهای از جملات با استفاده از یک تانسور ژندهدار با شکل [num_sentences, (num_words), embedding_size] ، جایی که پرانتزهای اطراف (num_words) نشان میدهند که بعد ناهموار است.
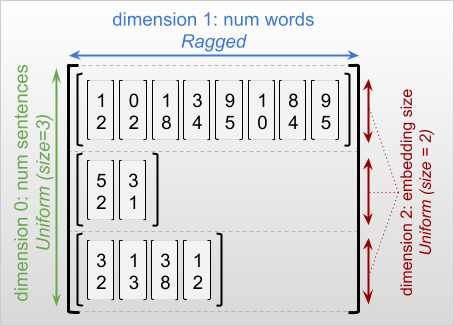
تانسورهای پاره پاره ممکن است چندین بعد ناهموار داشته باشند. برای مثال، میتوانید دستهای از اسناد متنی ساختاریافته را با استفاده از یک تانسور با شکل [num_documents, (num_paragraphs), (num_sentences), (num_words)] (که دوباره از پرانتز برای نشان دادن ابعاد ناهموار استفاده میشود) ذخیره کنید.
مانند tf.Tensor ، رتبه یک تانسور ژندهدار تعداد کل ابعاد آن است (شامل ابعاد ناهموار و یکنواخت). یک تانسور بالقوه ناهموار مقداری است که ممکن است tf.Tensor یا tf.RaggedTensor باشد.
هنگام توصیف شکل RaggedTensor، ابعاد ناهموار به طور معمول با قرار دادن آنها در پرانتز نشان داده می شوند. به عنوان مثال، همانطور که در بالا دیدید، شکل یک RaggedTensor سه بعدی که جاسازی کلمات را برای هر کلمه در دسته ای از جملات ذخیره می کند، می تواند به صورت [num_sentences, (num_words), embedding_size] نوشته شود.
ویژگی RaggedTensor.shape یک tf.TensorShape را برای یک تانسور ناهموار که در آن ابعاد ragged اندازه None ، برمیگرداند:
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
روش tf.RaggedTensor.bounding_shape را می توان برای یافتن یک شکل محدود برای یک RaggedTensor معین استفاده کرد:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Ragged vs Sparse
یک تانسور ژندهدار نباید به عنوان نوعی تانسور پراکنده در نظر گرفته شود. به طور خاص، تانسورهای پراکنده کدگذاری کارآمدی برای tf.Tensor که همان دادهها را در قالب فشرده مدلسازی میکنند. اما تانسور ژندهدار یک پسوند tf.Tensor است که کلاس گستردهای از دادهها را مدلسازی میکند. این تفاوت هنگام تعریف عملیات بسیار مهم است:
- اعمال یک op روی یک تانسور پراکنده یا متراکم باید همیشه نتیجه یکسانی داشته باشد.
- اعمال یک op روی یک تانسور ناهموار یا پراکنده ممکن است نتایج متفاوتی به همراه داشته باشد.
به عنوان یک مثال گویا، در نظر بگیرید که چگونه عملیات آرایه مانند concat ، stack و tile برای تانسورهای ناهموار در مقابل پراکنده تعریف می شوند. تانسورهای ناهموار به هم پیوسته به هر ردیف می پیوندند تا یک ردیف با طول ترکیبی تشکیل دهند:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
با این حال، الحاق تانسورهای پراکنده معادل الحاق تانسورهای متراکم مربوطه است، همانطور که در مثال زیر نشان داده شده است (که در آن Ø مقادیر گم شده را نشان می دهد):
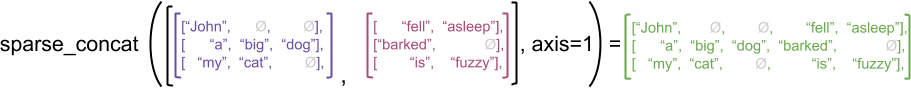
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
برای مثال دیگری از اهمیت این تمایز، تعریف «مقدار میانگین هر ردیف» را برای عملیاتی مانند tf.reduce_mean در نظر بگیرید. برای یک تانسور ناهموار، مقدار میانگین برای یک ردیف، مجموع مقادیر سطر تقسیم بر عرض سطر است. اما برای یک تانسور پراکنده، مقدار میانگین برای یک ردیف، مجموع مقادیر سطر تقسیم بر عرض کلی تانسور پراکنده (که بزرگتر یا مساوی عرض طولانیترین ردیف است) است.
API های TensorFlow
کراس
tf.keras API سطح بالای TensorFlow برای ساخت و آموزش مدل های یادگیری عمیق است. با تنظیم ragged ragged=True در tf.keras.Input یا tf.keras.layers.InputLayer ، تانسورهای Ragged ممکن است به عنوان ورودی به مدل Keras ارسال شوند. تانسورهای ناهموار نیز ممکن است از بین لایههای Keras عبور داده شوند و توسط مدلهای Keras برگردانده شوند. مثال زیر یک مدل LSTM اسباب بازی را نشان می دهد که با استفاده از تانسورهای پاره شده آموزش داده شده است.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf. مثال
tf.Example یک کد پروتوباف استاندارد برای داده های TensorFlow است. داده های کدگذاری شده با tf.Example s اغلب شامل ویژگی های طول متغیر است. به عنوان مثال، کد زیر دسته ای از چهار پیام tf.Example را تعریف می کند. نمونه پیام با طول ویژگی های مختلف:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
میتوانید این دادههای رمزگذاریشده را با استفاده از tf.io.parse_example ، که یک تانسور رشتههای متوالی و یک فرهنگ لغت مشخصات ویژگی را میگیرد، و نام ویژگیهای نگاشت فرهنگ لغت را به تانسورها برمیگرداند، تجزیه کنید. برای خواندن ویژگی های با طول متغیر در تانسورهای ناهموار، به سادگی از tf.io.RaggedFeature در فرهنگ لغت مشخصات ویژگی استفاده کنید:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature همچنین میتواند برای خواندن ویژگیهایی با چندین ابعاد ناهموار استفاده شود. برای جزئیات، به مستندات API مراجعه کنید.
مجموعه داده ها
tf.data یک API است که شما را قادر می سازد خطوط لوله ورودی پیچیده را از قطعات ساده و قابل استفاده مجدد بسازید. ساختار داده اصلی آن tf.data.Dataset است که نشان دهنده دنباله ای از عناصر است که در آن هر عنصر از یک یا چند جزء تشکیل شده است.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
ساخت مجموعه داده با تانسورهای ناهموار
مجموعه دادهها را میتوان با استفاده از روشهای مشابهی که برای ساخت آنها از tf.Tensor یا NumPy array میشود، مانند Dataset.from_tensor_slices ، از تانسورهای ناهموار ساختند:
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
دسته بندی و جداسازی مجموعه داده ها با تانسورهای ناهموار
مجموعه های داده با تانسورهای ناهموار را می توان با استفاده از روش Dataset.batch بندی کرد (که n عنصر متوالی را در یک عنصر واحد ترکیب می کند).
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
برعکس، یک مجموعه داده دستهای میتواند با استفاده از Dataset.unbatch به یک مجموعه داده مسطح تبدیل شود.
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
دستهبندی مجموعههای داده با تانسورهای غیر رگهدار با طول متغیر
اگر مجموعه دادهای دارید که حاوی تانسورهای غیر رگهدار است و طول تانسورها در عناصر مختلف متفاوت است، میتوانید با اعمال تبدیل dense_to_ragged_batch، آن تانسورهای غیر ژندهدار را به تانسورهای dense_to_ragged_batch تبدیل کنید:
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
تبدیل مجموعه داده ها با تانسورهای ناهموار
همچنین میتوانید با استفاده از Dataset.map ، تانسورهای ناهموار را در Datasets ایجاد یا تبدیل کنید:
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.function
tf.function یک دکوراتور است که نمودارهای TensorFlow را برای توابع پایتون از قبل محاسبه می کند، که می تواند عملکرد کد TensorFlow شما را به طور قابل ملاحظه ای بهبود بخشد. تانسورهای پاره شده را می توان به صورت شفاف با توابع @tf.function -decorated استفاده کرد. به عنوان مثال، تابع زیر با هر دو تانسور ragged و non-ragged کار می کند:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
اگر می خواهید به صراحت input_signature را برای input_signature tf.function کنید، می توانید این کار را با استفاده از tf.RaggedTensorSpec انجام دهید.
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
توابع بتنی
توابع بتن ، نمودارهای ردیابی شده را که توسط tf.function ساخته شده اند، محصور می کنند. تانسورهای پاره شده را می توان به صورت شفاف با عملکردهای بتنی استفاده کرد.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
SavedModels
SavedModel یک برنامه TensorFlow سریالی است که هم وزن و هم محاسبات را شامل می شود. می توان آن را از یک مدل Keras یا از یک مدل سفارشی ساخت. در هر صورت، تانسورهای پاره پاره شده را می توان به طور شفاف با توابع و روش های تعریف شده توسط SavedModel استفاده کرد.
مثال: ذخیره یک مدل Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
مثال: ذخیره یک مدل سفارشی
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
اپراتورهای اضافه بار
کلاس RaggedTensor عملگرهای محاسبه و مقایسه پایتون استاندارد را بارگذاری می کند و انجام ریاضیات پایه را آسان می کند:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
از آنجایی که عملگرهای بارگذاری شده محاسبات عنصری را انجام می دهند، ورودی های تمام عملیات دودویی باید یک شکل داشته باشند یا به یک شکل قابل پخش باشند. در ساده ترین حالت پخش، یک اسکالر منفرد به صورت عنصری با هر مقدار در یک تانسور ناهموار ترکیب می شود:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
برای بحث در مورد موارد پیشرفته تر، بخش پخش را بررسی کنید.
تانسورهای Ragged مجموعه ای از عملگرها را به عنوان Tensor معمولی بارگذاری می کنند: عملگرهای unary - ~ و abs() ; و عملگرهای باینری + , - , * , / , // , % , ** , & , | ، ^ ، == ، < ، <= ، > و >= .
نمایه سازی
تانسورهای Ragged از نمایه سازی به سبک پایتون، از جمله نمایه سازی چند بعدی و برش پشتیبانی می کنند. مثالهای زیر نمایهسازی تانسور ناهموار را با یک تانسور دو بعدی و سه بعدی نشان میدهند.
مثالهای نمایهسازی: تانسور ناهموار دوبعدی
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
مثالهای نمایهسازی: تانسور سهبعدی ژندهدار
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor از نمایه سازی و برش چند بعدی با یک محدودیت پشتیبانی می کند: نمایه سازی در ابعاد ناهموار مجاز نیست. این مورد مشکل ساز است زیرا مقدار مشخص شده ممکن است در برخی از ردیف ها وجود داشته باشد اما در برخی دیگر وجود نداشته باشد. در چنین مواردی، مشخص نیست که آیا باید (1) IndexError را مطرح کنید. (2) از یک مقدار پیش فرض استفاده کنید. یا (3) از آن مقدار بگذرید و یک تانسور با ردیفهای کمتر از آنچه که با آن شروع کردهاید برگردانید. با پیروی از اصول راهنمای پایتون ("در مواجهه با ابهام، از وسوسه حدس زدن خودداری کنید")، این عملیات در حال حاضر مجاز نیست.
تبدیل نوع تانسور
کلاس RaggedTensor روش هایی را تعریف می کند که می توانند برای تبدیل بین RaggedTensor s و tf.Tensor s یا tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
ارزیابی تانسورهای ناهموار
برای دسترسی به مقادیر موجود در یک تانسور ناهموار، می توانید:
- از
tf.RaggedTensor.to_listبرای تبدیل تانسور ناهموار به لیست پایتون تو در تو استفاده کنید. - از
tf.RaggedTensor.numpyبرای تبدیل تانسور ناهموار به آرایه NumPy استفاده کنید که مقادیر آن آرایه های NumPy تو در تو هستند. - با استفاده از
tf.RaggedTensor.valuesوtf.RaggedTensor.row_splitsیا روشهای تقسیمبندی ردیف مانندtf.RaggedTensor.row_lengthsوtf.RaggedTensor.value_rowids، تانسور ragged را به اجزای آن تجزیه کنید. - از نمایه سازی پایتون برای انتخاب مقادیر از تانسور ناهموار استفاده کنید.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
صدا و سیما
پخش فرآیندی است که در آن تانسورها با اشکال مختلف دارای اشکال سازگار برای عملیات عنصری هستند. برای پیشینه بیشتر در مورد پخش به زیر مراجعه کنید:
مراحل اساسی برای پخش دو ورودی x و y برای داشتن اشکال سازگار عبارتند از:
اگر
xوyتعداد ابعاد یکسانی ندارند، سپس ابعاد بیرونی (با اندازه 1) را اضافه کنید تا زمانی که دارای ابعاد باشند.برای هر بعد که
xوyاندازه های متفاوتی دارند:
- اگر
xیاyاندازه1در بعدdدارند، سپس مقادیر آن را در بعدdتکرار کنید تا با اندازه ورودی دیگر مطابقت داشته باشد. - در غیر این صورت، یک استثنا مطرح کنید (
xوyبا پخش سازگار نیستند).
در جایی که اندازه یک تانسور در یک بعد یکنواخت یک عدد است (اندازه برش های آن بعد). و اندازه یک تانسور در یک بعد ژندهدار فهرستی از طول برشها (برای همه برشهای آن بعد) است.
نمونه های پخش
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
در اینجا چند نمونه از اشکالی وجود دارد که پخش نمی شوند:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
رمزگذاری RaggedTensor
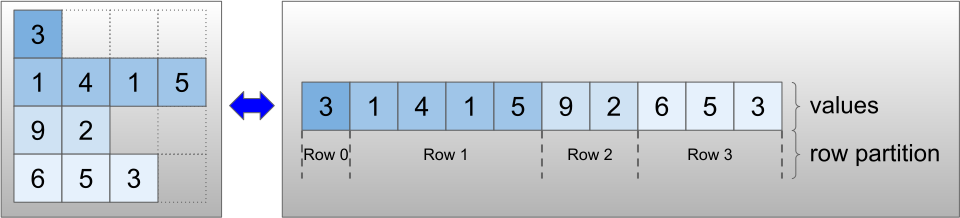
تانسورهای Ragged با استفاده از کلاس RaggedTensor کدگذاری می شوند. در داخل، هر RaggedTensor شامل موارد زیر است:
- یک تانسور
values، که ردیفهای با طول متغیر را به یک لیست مسطح متصل میکند. - یک
row_partition، که نشان میدهد چگونه آن مقادیر مسطح به ردیفها تقسیم میشوند.
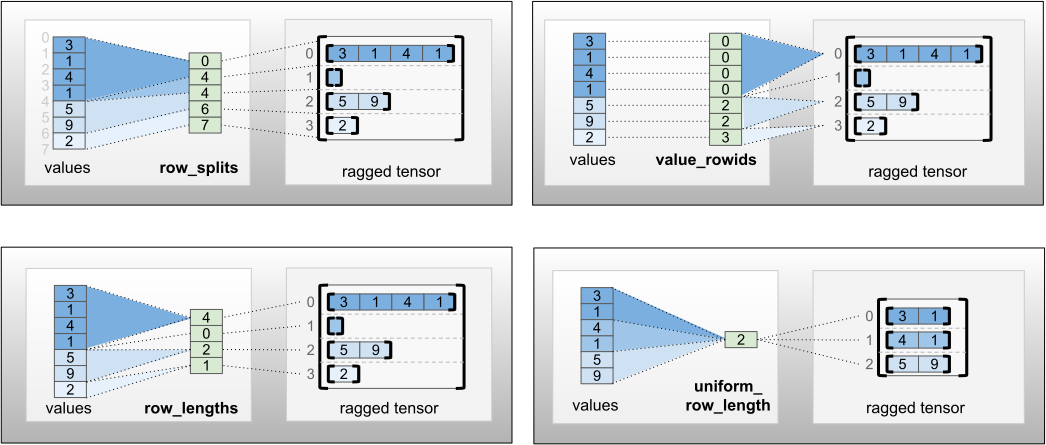
row_partition را می توان با استفاده از چهار رمزگذاری مختلف ذخیره کرد:
-
row_splitsیک بردار عدد صحیح است که نقاط تقسیم بین سطرها را مشخص می کند. -
value_rowidsیک بردار عدد صحیح است که شاخص ردیف را برای هر مقدار مشخص می کند. -
row_lengthsیک بردار عدد صحیح است که طول هر سطر را مشخص می کند. -
uniform_row_lengthیک عدد صحیح اسکالر است که یک طول واحد را برای همه سطرها مشخص می کند.
یک عدد عدد صحیح اسکالر را نیز میتوان در رمزگذاری nrows row_partition تا ردیفهای انتهایی خالی با value_rowids یا ردیفهای خالی با uniform_row_length را محاسبه کند.
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
انتخاب کدگذاری برای استفاده برای پارتیشنهای ردیف به صورت داخلی توسط تانسورهای ناهموار مدیریت میشود تا کارایی را در برخی زمینهها بهبود بخشد. به طور خاص، برخی از مزایا و معایب طرح های مختلف پارتیشن بندی ردیف عبارتند از:
- نمایه سازی کارآمد : رمزگذاری
row_splitsنمایه سازی با زمان ثابت و برش به تانسورهای ناهموار را امکان پذیر می کند. - الحاق کارآمد : رمزگذاری
row_lengthsهنگام به هم پیوستن تانسورهای ناهموار کارآمدتر است، زیرا وقتی دو تانسور به هم متصل می شوند طول ردیف تغییر نمی کند. - اندازه رمزگذاری کوچک : رمزگذاری
value_rowidsهنگام ذخیره تانسورهای ناهموار که دارای تعداد زیادی ردیف خالی هستند کارآمدتر است، زیرا اندازه تانسور فقط به تعداد کل مقادیر بستگی دارد. از سوی دیگر، رمزگذاریهایrow_splitsوrow_lengthsهنگام ذخیرهسازی تانسورهای ژندهدار با ردیفهای طولانیتر کارآمدتر هستند، زیرا فقط به یک مقدار اسکالر برای هر ردیف نیاز دارند. - سازگاری : طرح
value_rowidsبا قالب تقسیمبندی استفاده شده توسط عملیاتها، مانندtf.segment_sumدارد. طرحrow_limitsبا قالب استفاده شده توسط عملیاتی مانندtf.sequence_maskدارد. - ابعاد یکنواخت : همانطور که در زیر بحث شد، رمزگذاری
uniform_row_lengthبرای رمزگذاری تانسورهای ناهموار با ابعاد یکنواخت استفاده می شود.
چند ابعاد ناهموار
یک تانسور ژندهدار با چند ابعاد ناهموار با استفاده از یک تانسور RaggedTensor برای تانسور values کدگذاری میشود. هر RaggedTensor تو در تو یک بعد ناهموار اضافه می کند.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
تابع کارخانه tf.RaggedTensor.from_nested_row_splits ممکن است برای ساختن یک RaggedTensor با چندین ابعاد ناهموار مستقیماً با ارائه لیستی از تانسورهای row_splits شود:
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
رتبه ناهموار و مقادیر مسطح
رتبه ناهموار یک تانسور ناهموار تعداد دفعاتی است که تانسور values زیرین تقسیم شده است (یعنی عمق تودرتو اشیاء RaggedTensor ). درونیترین تانسور values به عنوان flat_values آن شناخته میشود. در مثال زیر، conversations دارای ragged_rank=3 هستند و flat_values آن یک Tensor 1 بعدی با 24 رشته است:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
ابعاد داخلی یکنواخت
تانسورهای ناهموار با ابعاد داخلی یکنواخت با استفاده از یک tf.Tensor چند بعدی برای مقادیر مسطح (یعنی درونی ترین values ) کدگذاری می شوند.

rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
ابعاد غیر داخلی یکنواخت
تانسورهای ناهموار با ابعاد غیر داخلی یکنواخت با پارتیشن بندی ردیف هایی با uniform_row_length می شوند.
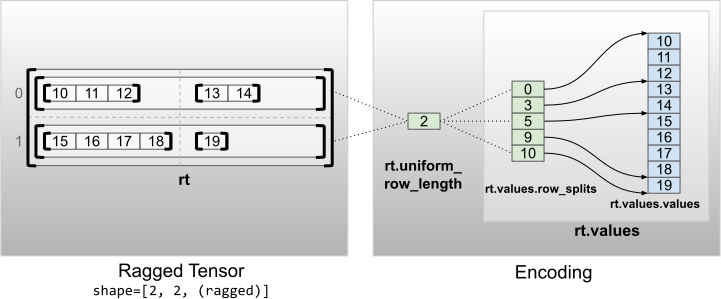
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2