| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Ringkasan
TensorFlow mengimplementasikan subset dari NumPy API , tersedia sebagai tf.experimental.numpy . Hal ini memungkinkan menjalankan kode NumPy, yang dipercepat oleh TensorFlow, sekaligus memungkinkan akses ke semua API TensorFlow.
Mempersiapkan
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
import timeit
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.6.0
Mengaktifkan perilaku NumPy
Untuk menggunakan tnp sebagai NumPy, aktifkan perilaku NumPy untuk TensorFlow:
tnp.experimental_enable_numpy_behavior()
Panggilan ini mengaktifkan promosi jenis di TensorFlow dan juga mengubah inferensi jenis, saat mengonversi literal ke tensor, untuk mengikuti standar NumPy dengan lebih ketat.
TensorFlow NumPy ND array
Sebuah instance dari tf.experimental.numpy.ndarray , yang disebut ND Array , mewakili array padat multidimensi dari tipe- dtype tertentu yang ditempatkan pada perangkat tertentu. Ini adalah alias untuk tf.Tensor . Lihat kelas array ND untuk metode yang berguna seperti ndarray.T , ndarray.reshape , ndarray.ravel dan lainnya.
Pertama, buat objek larik ND, lalu panggil metode yang berbeda.
# Create an ND array and check out different attributes.
ones = tnp.ones([5, 3], dtype=tnp.float32)
print("Created ND array with shape = %s, rank = %s, "
"dtype = %s on device = %s\n" % (
ones.shape, ones.ndim, ones.dtype, ones.device))
# `ndarray` is just an alias to `tf.Tensor`.
print("Is `ones` an instance of tf.Tensor: %s\n" % isinstance(ones, tf.Tensor))
# Try commonly used member functions.
print("ndarray.T has shape %s" % str(ones.T.shape))
print("narray.reshape(-1) has shape %s" % ones.reshape(-1).shape)
Created ND array with shape = (5, 3), rank = 2, dtype = <dtype: 'float32'> on device = /job:localhost/replica:0/task:0/device:GPU:0 Is `ones` an instance of tf.Tensor: True ndarray.T has shape (3, 5) narray.reshape(-1) has shape (15,)
Jenis promosi
TensorFlow NumPy API memiliki semantik yang terdefinisi dengan baik untuk mengonversi literal ke array ND, serta untuk melakukan promosi jenis pada input array ND. Silakan lihat np.result_type untuk lebih jelasnya.
API TensorFlow membiarkan input tf.Tensor tidak berubah dan tidak melakukan promosi jenis pada input tersebut, sementara TensorFlow NumPy API mempromosikan semua input sesuai dengan aturan promosi jenis NumPy. Pada contoh berikutnya, Anda akan melakukan promosi jenis. Pertama, jalankan penambahan pada input array ND dari tipe yang berbeda dan perhatikan tipe outputnya. Tidak satu pun dari jenis promosi ini akan diizinkan oleh TensorFlow API.
print("Type promotion for operations")
values = [tnp.asarray(1, dtype=d) for d in
(tnp.int32, tnp.int64, tnp.float32, tnp.float64)]
for i, v1 in enumerate(values):
for v2 in values[i + 1:]:
print("%s + %s => %s" %
(v1.dtype.name, v2.dtype.name, (v1 + v2).dtype.name))
Type promotion for operations int32 + int64 => int64 int32 + float32 => float64 int32 + float64 => float64 int64 + float32 => float64 int64 + float64 => float64 float32 + float64 => float64
Terakhir, konversi literal ke array ND menggunakan ndarray.asarray dan catat jenis yang dihasilkan.
print("Type inference during array creation")
print("tnp.asarray(1).dtype == tnp.%s" % tnp.asarray(1).dtype.name)
print("tnp.asarray(1.).dtype == tnp.%s\n" % tnp.asarray(1.).dtype.name)
Type inference during array creation tnp.asarray(1).dtype == tnp.int64 tnp.asarray(1.).dtype == tnp.float64
Saat mengonversi literal ke array ND, NumPy lebih menyukai tipe lebar seperti tnp.int64 dan tnp.float64 . Sebaliknya, tf.convert_to_tensor lebih memilih tipe tf.int32 dan tf.float32 untuk mengonversi konstanta ke tf.Tensor . TensorFlow NumPy API mematuhi perilaku NumPy untuk bilangan bulat. Untuk float, argumen prefer_float32 dari experimental_enable_numpy_behavior memungkinkan Anda mengontrol apakah akan memilih tf.float32 daripada tf.float64 (default ke False ). Sebagai contoh:
tnp.experimental_enable_numpy_behavior(prefer_float32=True)
print("When prefer_float32 is True:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
tnp.experimental_enable_numpy_behavior(prefer_float32=False)
print("When prefer_float32 is False:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
When prefer_float32 is True: tnp.asarray(1.).dtype == tnp.float32 tnp.add(1., 2.).dtype == tnp.float32 When prefer_float32 is False: tnp.asarray(1.).dtype == tnp.float64 tnp.add(1., 2.).dtype == tnp.float64
Penyiaran
Mirip dengan TensorFlow, NumPy mendefinisikan semantik yang kaya untuk nilai "penyiaran". Anda dapat melihat panduan penyiaran NumPy untuk informasi lebih lanjut dan membandingkannya dengan semantik penyiaran TensorFlow .
x = tnp.ones([2, 3])
y = tnp.ones([3])
z = tnp.ones([1, 2, 1])
print("Broadcasting shapes %s, %s and %s gives shape %s" % (
x.shape, y.shape, z.shape, (x + y + z).shape))
Broadcasting shapes (2, 3), (3,) and (1, 2, 1) gives shape (1, 2, 3)
pengindeksan
NumPy mendefinisikan aturan pengindeksan yang sangat canggih. Lihat panduan Pengindeksan NumPy . Perhatikan penggunaan array ND sebagai indeks di bawah ini.
x = tnp.arange(24).reshape(2, 3, 4)
print("Basic indexing")
print(x[1, tnp.newaxis, 1:3, ...], "\n")
print("Boolean indexing")
print(x[:, (True, False, True)], "\n")
print("Advanced indexing")
print(x[1, (0, 0, 1), tnp.asarray([0, 1, 1])])
Basic indexing tf.Tensor( [[[16 17 18 19] [20 21 22 23]]], shape=(1, 2, 4), dtype=int64) Boolean indexing tf.Tensor( [[[ 0 1 2 3] [ 8 9 10 11]] [[12 13 14 15] [20 21 22 23]]], shape=(2, 2, 4), dtype=int64) Advanced indexing tf.Tensor([12 13 17], shape=(3,), dtype=int64)
# Mutation is currently not supported
try:
tnp.arange(6)[1] = -1
except TypeError:
print("Currently, TensorFlow NumPy does not support mutation.")
Currently, TensorFlow NumPy does not support mutation.
Contoh Model
Selanjutnya, Anda dapat melihat cara membuat model dan menjalankan inferensi di atasnya. Model sederhana ini menerapkan lapisan relu diikuti dengan proyeksi linier. Bagian selanjutnya akan menunjukkan cara menghitung gradien untuk model ini menggunakan GradientTape TensorFlow.
class Model(object):
"""Model with a dense and a linear layer."""
def __init__(self):
self.weights = None
def predict(self, inputs):
if self.weights is None:
size = inputs.shape[1]
# Note that type `tnp.float32` is used for performance.
stddev = tnp.sqrt(size).astype(tnp.float32)
w1 = tnp.random.randn(size, 64).astype(tnp.float32) / stddev
bias = tnp.random.randn(64).astype(tnp.float32)
w2 = tnp.random.randn(64, 2).astype(tnp.float32) / 8
self.weights = (w1, bias, w2)
else:
w1, bias, w2 = self.weights
y = tnp.matmul(inputs, w1) + bias
y = tnp.maximum(y, 0) # Relu
return tnp.matmul(y, w2) # Linear projection
model = Model()
# Create input data and compute predictions.
print(model.predict(tnp.ones([2, 32], dtype=tnp.float32)))
tf.Tensor( [[-1.7706785 1.1137733] [-1.7706785 1.1137733]], shape=(2, 2), dtype=float32)
TensorFlow NumPy dan NumPy
TensorFlow NumPy mengimplementasikan subset dari spesifikasi NumPy lengkap. Sementara lebih banyak simbol akan ditambahkan dari waktu ke waktu, ada fitur sistematis yang tidak akan didukung dalam waktu dekat. Ini termasuk dukungan NumPy C API, integrasi Swig, urutan penyimpanan Fortran, views dan stride_tricks , dan beberapa dtype s (seperti np.recarray dan np.object ). Untuk detail selengkapnya, lihat Dokumentasi TensorFlow NumPy API .
Interoperabilitas NumPy
Array TensorFlow ND dapat beroperasi dengan fungsi NumPy. Objek-objek ini mengimplementasikan antarmuka __array__ . NumPy menggunakan antarmuka ini untuk mengonversi argumen fungsi ke nilai np.ndarray sebelum memprosesnya.
Demikian pula, fungsi TensorFlow NumPy dapat menerima input dari berbagai jenis termasuk np.ndarray . Input ini dikonversi ke array ND dengan memanggil ndarray.asarray pada input tersebut.
Konversi larik ND ke dan dari np.ndarray dapat memicu salinan data aktual. Silakan lihat bagian tentang salinan buffer untuk lebih jelasnya.
# ND array passed into NumPy function.
np_sum = np.sum(tnp.ones([2, 3]))
print("sum = %s. Class: %s" % (float(np_sum), np_sum.__class__))
# `np.ndarray` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(np.ones([2, 3]))
print("sum = %s. Class: %s" % (float(tnp_sum), tnp_sum.__class__))
sum = 6.0. Class: <class 'numpy.float64'> sum = 6.0. Class: <class 'tensorflow.python.framework.ops.EagerTensor'>
# It is easy to plot ND arrays, given the __array__ interface.
labels = 15 + 2 * tnp.random.randn(1, 1000)
_ = plt.hist(labels)
Salinan penyangga
Mencampur TensorFlow NumPy dengan kode NumPy dapat memicu salinan data. Ini karena TensorFlow NumPy memiliki persyaratan yang lebih ketat pada penyelarasan memori daripada NumPy.
Saat np.ndarray diteruskan ke TensorFlow NumPy, np.ndarray akan memeriksa persyaratan penyelarasan dan memicu salinan jika diperlukan. Saat meneruskan buffer CPU array ND ke NumPy, umumnya buffer akan memenuhi persyaratan penyelarasan dan NumPy tidak perlu membuat salinan.
Array ND dapat merujuk ke buffer yang ditempatkan pada perangkat selain memori CPU lokal. Dalam kasus seperti itu, menjalankan fungsi NumPy akan memicu salinan di seluruh jaringan atau perangkat sesuai kebutuhan.
Mengingat hal ini, pencampuran dengan panggilan API NumPy umumnya harus dilakukan dengan hati-hati dan pengguna harus berhati-hati terhadap overhead penyalinan data. Menyela panggilan TensorFlow NumPy dengan panggilan TensorFlow umumnya aman dan menghindari penyalinan data. Lihat bagian tentang interoperabilitas TensorFlow untuk detail selengkapnya.
Prioritas operator
TensorFlow NumPy mendefinisikan __array_priority__ lebih tinggi dari NumPy. Ini berarti bahwa untuk operator yang melibatkan larik ND dan np.ndarray , yang pertama akan diutamakan, yaitu, input np.ndarray akan dikonversi ke larik ND dan implementasi TensorFlow NumPy dari operator akan dipanggil.
x = tnp.ones([2]) + np.ones([2])
print("x = %s\nclass = %s" % (x, x.__class__))
x = tf.Tensor([2. 2.], shape=(2,), dtype=float64) class = <class 'tensorflow.python.framework.ops.EagerTensor'>
TF NumPy dan TensorFlow
TensorFlow NumPy dibangun di atas TensorFlow dan karenanya beroperasi secara lancar dengan TensorFlow.
tf.Tensor dan larik ND
Array ND adalah alias untuk tf.Tensor , jadi jelas mereka dapat dicampur tanpa memicu salinan data yang sebenarnya.
x = tf.constant([1, 2])
print(x)
# `asarray` and `convert_to_tensor` here are no-ops.
tnp_x = tnp.asarray(x)
print(tnp_x)
print(tf.convert_to_tensor(tnp_x))
# Note that tf.Tensor.numpy() will continue to return `np.ndarray`.
print(x.numpy(), x.numpy().__class__)
tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) [1 2] <class 'numpy.ndarray'>
Interoperabilitas TensorFlow
Array ND dapat diteruskan ke API TensorFlow, karena array ND hanyalah alias untuk tf.Tensor . Seperti disebutkan sebelumnya, interoperasi tersebut tidak melakukan salinan data, bahkan untuk data yang ditempatkan pada akselerator atau perangkat jarak jauh.
Sebaliknya, objek tf.Tensor dapat diteruskan ke tf.experimental.numpy API, tanpa melakukan penyalinan data.
# ND array passed into TensorFlow function.
tf_sum = tf.reduce_sum(tnp.ones([2, 3], tnp.float32))
print("Output = %s" % tf_sum)
# `tf.Tensor` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(tf.ones([2, 3]))
print("Output = %s" % tnp_sum)
Output = tf.Tensor(6.0, shape=(), dtype=float32) Output = tf.Tensor(6.0, shape=(), dtype=float32)
Gradien dan Jacobian: tf.GradientTape
GradientTape TensorFlow dapat digunakan untuk backpropagation melalui kode TensorFlow dan TensorFlow NumPy.
Gunakan model yang dibuat di bagian Model Contoh , dan hitung gradien dan jacobian.
def create_batch(batch_size=32):
"""Creates a batch of input and labels."""
return (tnp.random.randn(batch_size, 32).astype(tnp.float32),
tnp.random.randn(batch_size, 2).astype(tnp.float32))
def compute_gradients(model, inputs, labels):
"""Computes gradients of squared loss between model prediction and labels."""
with tf.GradientTape() as tape:
assert model.weights is not None
# Note that `model.weights` need to be explicitly watched since they
# are not tf.Variables.
tape.watch(model.weights)
# Compute prediction and loss
prediction = model.predict(inputs)
loss = tnp.sum(tnp.square(prediction - labels))
# This call computes the gradient through the computation above.
return tape.gradient(loss, model.weights)
inputs, labels = create_batch()
gradients = compute_gradients(model, inputs, labels)
# Inspect the shapes of returned gradients to verify they match the
# parameter shapes.
print("Parameter shapes:", [w.shape for w in model.weights])
print("Gradient shapes:", [g.shape for g in gradients])
# Verify that gradients are of type ND array.
assert isinstance(gradients[0], tnp.ndarray)
Parameter shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])] Gradient shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])]
# Computes a batch of jacobians. Each row is the jacobian of an element in the
# batch of outputs w.r.t. the corresponding input batch element.
def prediction_batch_jacobian(inputs):
with tf.GradientTape() as tape:
tape.watch(inputs)
prediction = model.predict(inputs)
return prediction, tape.batch_jacobian(prediction, inputs)
inp_batch = tnp.ones([16, 32], tnp.float32)
output, batch_jacobian = prediction_batch_jacobian(inp_batch)
# Note how the batch jacobian shape relates to the input and output shapes.
print("Output shape: %s, input shape: %s" % (output.shape, inp_batch.shape))
print("Batch jacobian shape:", batch_jacobian.shape)
Output shape: (16, 2), input shape: (16, 32) Batch jacobian shape: (16, 2, 32)
Kompilasi jejak: tf.function
tf.function tf.function bekerja dengan "mengkompilasi jejak" kode dan kemudian mengoptimalkan jejak ini untuk kinerja yang jauh lebih cepat. Lihat Pengantar Grafik dan Fungsi .
tf.function juga dapat digunakan untuk mengoptimalkan kode TensorFlow NumPy. Berikut adalah contoh sederhana untuk mendemonstrasikan speedups. Perhatikan bahwa isi kode tf.function menyertakan panggilan ke TensorFlow NumPy API.
inputs, labels = create_batch(512)
print("Eager performance")
compute_gradients(model, inputs, labels)
print(timeit.timeit(lambda: compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
print("\ntf.function compiled performance")
compiled_compute_gradients = tf.function(compute_gradients)
compiled_compute_gradients(model, inputs, labels) # warmup
print(timeit.timeit(lambda: compiled_compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
Eager performance 1.291419400013183 ms tf.function compiled performance 0.5561202000080812 ms
Vektorisasi: tf.vectorized_map
TensorFlow memiliki dukungan bawaan untuk membuat vektor loop paralel, yang memungkinkan percepatan satu hingga dua kali lipat. Percepatan ini dapat diakses melalui tf.vectorized_map API dan juga berlaku untuk kode TensorFlow NumPy.
Kadang-kadang berguna untuk menghitung gradien setiap output dalam satu batch dengan elemen batch input yang sesuai. Perhitungan tersebut dapat dilakukan secara efisien menggunakan tf.vectorized_map seperti yang ditunjukkan di bawah ini.
@tf.function
def vectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
# Note that a call to `tf.vectorized_map` semantically maps
# `single_example_gradient` over each row of `inputs` and `labels`.
# The interface is similar to `tf.map_fn`.
# The underlying machinery vectorizes away this map loop which gives
# nice speedups.
return tf.vectorized_map(single_example_gradient, (inputs, labels))
batch_size = 128
inputs, labels = create_batch(batch_size)
per_example_gradients = vectorized_per_example_gradients(inputs, labels)
for w, p in zip(model.weights, per_example_gradients):
print("Weight shape: %s, batch size: %s, per example gradient shape: %s " % (
w.shape, batch_size, p.shape))
Weight shape: (32, 64), batch size: 128, per example gradient shape: (128, 32, 64) Weight shape: (64,), batch size: 128, per example gradient shape: (128, 64) Weight shape: (64, 2), batch size: 128, per example gradient shape: (128, 64, 2)
# Benchmark the vectorized computation above and compare with
# unvectorized sequential computation using `tf.map_fn`.
@tf.function
def unvectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
return tf.map_fn(single_example_gradient, (inputs, labels),
fn_output_signature=(tf.float32, tf.float32, tf.float32))
print("Running vectorized computation")
print(timeit.timeit(lambda: vectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
print("\nRunning unvectorized computation")
per_example_gradients = unvectorized_per_example_gradients(inputs, labels)
print(timeit.timeit(lambda: unvectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
Running vectorized computation 0.5265710999992734 ms Running unvectorized computation 40.35122630002661 ms
Penempatan perangkat
TensorFlow NumPy dapat menempatkan operasi pada CPU, GPU, TPU, dan perangkat jarak jauh. Ini menggunakan mekanisme TensorFlow standar untuk penempatan perangkat. Di bawah contoh sederhana menunjukkan bagaimana membuat daftar semua perangkat dan kemudian menempatkan beberapa perhitungan pada perangkat tertentu.
TensorFlow juga memiliki API untuk mereplikasi komputasi di seluruh perangkat dan melakukan pengurangan kolektif yang tidak akan dibahas di sini.
Daftar perangkat
tf.config.list_logical_devices dan tf.config.list_physical_devices dapat digunakan untuk menemukan perangkat yang akan digunakan.
print("All logical devices:", tf.config.list_logical_devices())
print("All physical devices:", tf.config.list_physical_devices())
# Try to get the GPU device. If unavailable, fallback to CPU.
try:
device = tf.config.list_logical_devices(device_type="GPU")[0]
except IndexError:
device = "/device:CPU:0"
All logical devices: [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:GPU:0', device_type='GPU')] All physical devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Menempatkan operasi: tf.device
Operasi dapat ditempatkan pada perangkat dengan memanggilnya dalam lingkup tf.device .
print("Using device: %s" % str(device))
# Run operations in the `tf.device` scope.
# If a GPU is available, these operations execute on the GPU and outputs are
# placed on the GPU memory.
with tf.device(device):
prediction = model.predict(create_batch(5)[0])
print("prediction is placed on %s" % prediction.device)
Using device: LogicalDevice(name='/device:GPU:0', device_type='GPU') prediction is placed on /job:localhost/replica:0/task:0/device:GPU:0
Menyalin array ND di seluruh perangkat: tnp.copy
Panggilan ke tnp.copy , ditempatkan di lingkup perangkat tertentu, akan menyalin data ke perangkat itu, kecuali data sudah ada di perangkat itu.
with tf.device("/device:CPU:0"):
prediction_cpu = tnp.copy(prediction)
print(prediction.device)
print(prediction_cpu.device)
/job:localhost/replica:0/task:0/device:GPU:0 /job:localhost/replica:0/task:0/device:CPU:0
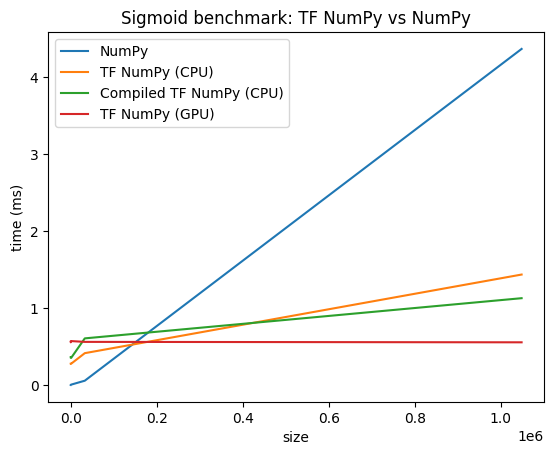
Perbandingan kinerja
TensorFlow NumPy menggunakan kernel TensorFlow yang sangat dioptimalkan yang dapat dikirim pada CPU, GPU, dan TPU. TensorFlow juga melakukan banyak pengoptimalan kompiler, seperti penggabungan operasi, yang menghasilkan peningkatan kinerja dan memori. Lihat pengoptimalan grafik TensorFlow dengan Grappler untuk mempelajari lebih lanjut.
Namun TensorFlow memiliki overhead yang lebih tinggi untuk operasi pengiriman dibandingkan dengan NumPy. Untuk beban kerja yang terdiri dari operasi kecil (kurang dari sekitar 10 mikrodetik), overhead ini dapat mendominasi runtime dan NumPy dapat memberikan kinerja yang lebih baik. Untuk kasus lain, TensorFlow umumnya harus memberikan kinerja yang lebih baik.
Jalankan tolok ukur di bawah ini untuk membandingkan kinerja NumPy dan TensorFlow NumPy untuk ukuran input yang berbeda.
def benchmark(f, inputs, number=30, force_gpu_sync=False):
"""Utility to benchmark `f` on each value in `inputs`."""
times = []
for inp in inputs:
def _g():
if force_gpu_sync:
one = tnp.asarray(1)
f(inp)
if force_gpu_sync:
with tf.device("CPU:0"):
tnp.copy(one) # Force a sync for GPU case
_g() # warmup
t = timeit.timeit(_g, number=number)
times.append(t * 1000. / number)
return times
def plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu):
"""Plot the different runtimes."""
plt.xlabel("size")
plt.ylabel("time (ms)")
plt.title("Sigmoid benchmark: TF NumPy vs NumPy")
plt.plot(sizes, np_times, label="NumPy")
plt.plot(sizes, tnp_times, label="TF NumPy (CPU)")
plt.plot(sizes, compiled_tnp_times, label="Compiled TF NumPy (CPU)")
if has_gpu:
plt.plot(sizes, tnp_times_gpu, label="TF NumPy (GPU)")
plt.legend()
# Define a simple implementation of `sigmoid`, and benchmark it using
# NumPy and TensorFlow NumPy for different input sizes.
def np_sigmoid(y):
return 1. / (1. + np.exp(-y))
def tnp_sigmoid(y):
return 1. / (1. + tnp.exp(-y))
@tf.function
def compiled_tnp_sigmoid(y):
return tnp_sigmoid(y)
sizes = (2 ** 0, 2 ** 5, 2 ** 10, 2 ** 15, 2 ** 20)
np_inputs = [np.random.randn(size).astype(np.float32) for size in sizes]
np_times = benchmark(np_sigmoid, np_inputs)
with tf.device("/device:CPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times = benchmark(tnp_sigmoid, tnp_inputs)
compiled_tnp_times = benchmark(compiled_tnp_sigmoid, tnp_inputs)
has_gpu = len(tf.config.list_logical_devices("GPU"))
if has_gpu:
with tf.device("/device:GPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times_gpu = benchmark(compiled_tnp_sigmoid, tnp_inputs, 100, True)
else:
tnp_times_gpu = None
plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu)