
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
genel bakış
Bu öğretici, TensorFlow Lattice (TFL) kitaplığı tarafından sağlanan kısıtlamalara ve düzenleyicilere genel bir bakış niteliğindedir. Burada sentetik veri kümelerinde TFL hazır tahmin edicileri kullanıyoruz, ancak bu eğitimdeki her şeyin TFL Keras katmanlarından oluşturulan modellerle de yapılabileceğini unutmayın.
Devam etmeden önce, çalışma zamanınızda gerekli tüm paketlerin kurulu olduğundan emin olun (aşağıdaki kod hücrelerinde içe aktarıldığı gibi).
Kurmak
TF Kafes paketini yükleme:
pip install -q tensorflow-lattice
Gerekli paketleri içe aktarma:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Bu kılavuzda kullanılan varsayılan değerler:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Restoranları Sıralamak için Eğitim Veri Kümesi
Kullanıcıların bir restoran arama sonucuna tıklayıp tıklamayacağını belirlemek istediğimiz basitleştirilmiş bir senaryo hayal edin. Görev, verilen girdi özelliklerine tıklama oranını (TO) tahmin etmektir:
- Ortalama değeri (
avg_rating) aralığında [1,5] değerleri ile sayısal bir özelliktir. - Yorum sayısı (
num_reviews): Biz trendiness bir ölçüsü olarak kullanmak 200'de şapkalı değerlere sahip bir sayısal özellik. - Dolar değerlendirmesi (
dollar_rating): set { "D", "DD", "DDD", "DDDD"} dize değerleri olan kategorik özellik.
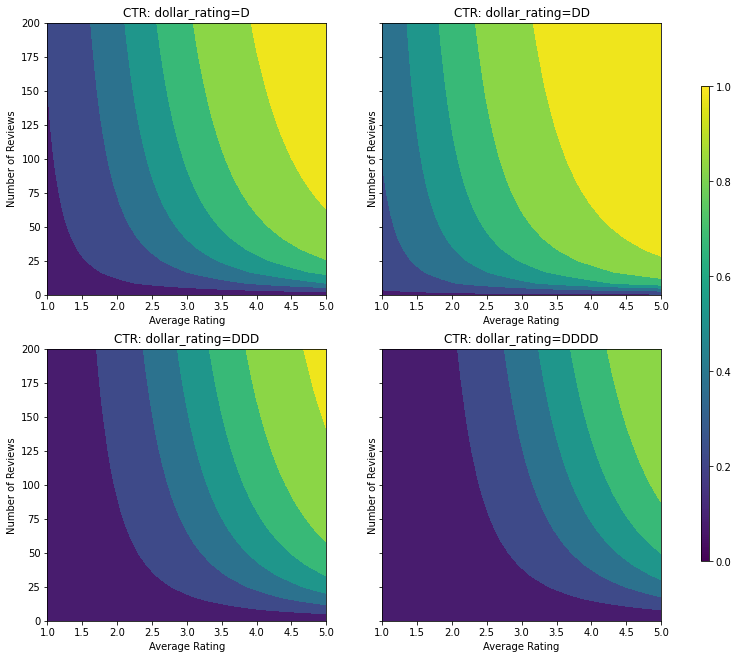
Burada, gerçek TO'nun aşağıdaki formülle verildiği sentetik bir veri kümesi oluşturuyoruz:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
burada \(b(\cdot)\) her çevirir dollar_rating bir temel değere:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Bu formül, tipik kullanıcı kalıplarını yansıtır. örneğin, diğer her şey sabitlendiğinde, kullanıcılar daha yüksek yıldız derecelendirmesine sahip restoranları tercih eder ve "\$\$" restoranları "\$" yerine daha fazla tıklama alır, ardından "\$\$\$" ve "\$\$\$ gelir \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Bu CTR fonksiyonunun kontur grafiklerine bir göz atalım.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Veri Hazırlama
Şimdi sentetik veri kümelerimizi oluşturmamız gerekiyor. Simüle edilmiş bir restoran veri seti ve özellikleri oluşturarak başlıyoruz.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
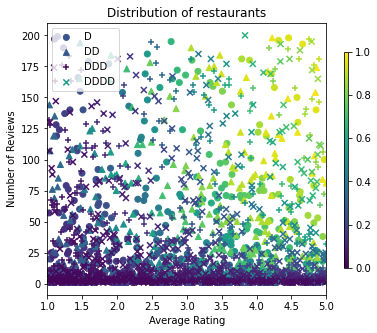
Eğitim, doğrulama ve test veri setlerini üretelim. Arama sonuçlarında bir restoran görüntülendiğinde, kullanıcının etkileşimini (tıklama veya tıklama olmaması) örnek bir nokta olarak kaydedebiliriz.
Uygulamada, kullanıcılar çoğu zaman tüm arama sonuçlarını incelemezler. Bu, kullanıcıların yalnızca kullanımda olan mevcut sıralama modeline göre zaten "iyi" kabul edilen restoranları göreceği anlamına gelir. Sonuç olarak, "iyi" restoranlar daha sık etkilenir ve eğitim veri setlerinde fazla temsil edilir. Daha fazla özellik kullanıldığında, eğitim veri kümesi, özellik alanının "kötü" bölümlerinde büyük boşluklara sahip olabilir.
Model sıralama için kullanıldığında, genellikle eğitim veri kümesi tarafından iyi temsil edilmeyen daha tekdüze bir dağılımla ilgili tüm sonuçlar üzerinde değerlendirilir. Bu durumda esnek ve karmaşık bir model, aşırı temsil edilen veri noktalarının gereğinden fazla uydurulması nedeniyle başarısız olabilir ve dolayısıyla genelleştirilebilirlikten yoksun olabilir. Biz eğitim veri kümesi onları almak edemez makul tahminlerde bulunmak için bir model kılavuz şekil kısıtlamaları eklemek için alan bilgisine uygulayarak bu sorunu ele.
Bu örnekte, eğitim veri seti çoğunlukla iyi ve popüler restoranlarla kullanıcı etkileşimlerinden oluşmaktadır. Test veri kümesi, yukarıda tartışılan değerlendirme ayarını simüle etmek için tek tip bir dağılıma sahiptir. Bu tür test veri setinin gerçek bir problem ortamında kullanılamayacağını unutmayın.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
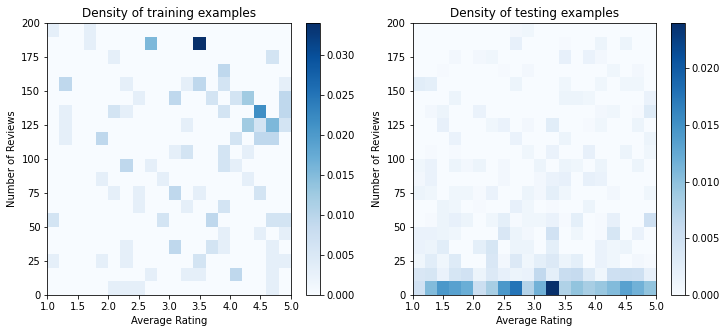
Eğitim ve değerlendirme için kullanılan input_fns'yi tanımlama:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Gradyan Artırılmış Ağaçları Sığdırma
: Sadece iki özellikleri ile başlayalım avg_rating ve num_reviews .
Doğrulama ve test ölçümlerini çizmek ve hesaplamak için birkaç yardımcı fonksiyon oluşturuyoruz.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
TensorFlow gradyan destekli karar ağaçlarını veri kümesine sığdırabiliriz:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
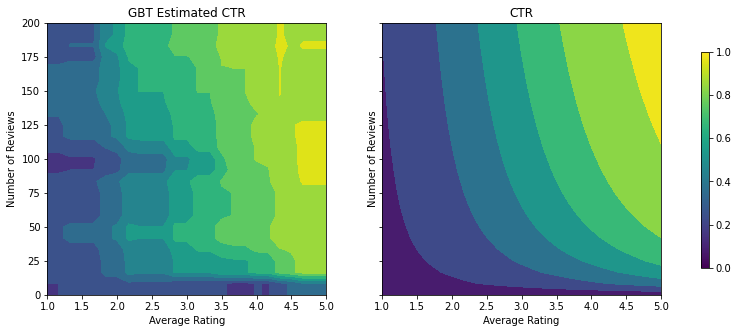
Model, gerçek TO'nun genel şeklini yakalamış ve yeterli doğrulama metriklerine sahip olsa da, giriş alanının çeşitli bölümlerinde sezgisel olmayan davranışlara sahiptir: ortalama puan veya inceleme sayısı arttıkça tahmini TO azalır. Bunun nedeni, eğitim veri kümesi tarafından iyi kapsanmayan alanlarda örnek noktaların olmamasıdır. Modelin yalnızca verilerden doğru davranışı çıkarması mümkün değildir.
Bu sorunu çözmek için, modelin hem ortalama derecelendirme hem de inceleme sayısı açısından monoton olarak artan değerler vermesi gerektiği şeklindeki şekil kısıtlamasını uyguluyoruz. Bunu TFL'de nasıl uygulayacağımızı daha sonra göreceğiz.
DNN takma
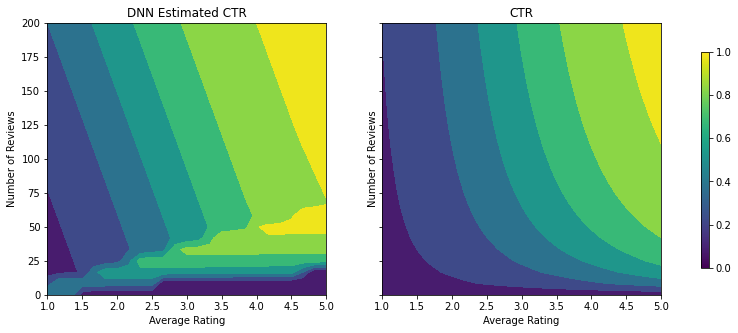
Aynı adımları bir DNN sınıflandırıcı ile tekrarlayabiliriz. Benzer bir model gözlemleyebiliriz: az sayıda inceleme ile yeterli örnek noktasına sahip olmamak, anlamsız ekstrapolasyona neden olur. Doğrulama metriği ağaç çözümünden daha iyi olsa da, test metriğinin çok daha kötü olduğunu unutmayın.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
Şekil Kısıtlamaları
TensorFlow Lattice (TFL), eğitim verilerinin ötesinde model davranışını korumak için şekil kısıtlamalarını uygulamaya odaklanır. Bu şekil kısıtlamaları, TFL Keras katmanlarına uygulanır. Onların ayrıntılar bulunabilir bizim JMLR kağıdı .
Bu öğreticide, çeşitli şekil kısıtlamalarını kapsamak için TF hazır tahmin edicileri kullanıyoruz, ancak tüm bu adımların TFL Keras katmanlarından oluşturulan modellerle yapılabileceğini unutmayın.
Başka tahmin TensorFlow gibi, TFL tahmin kullanımı konserve özelliği sütun giriş biçimini tanımlamak ve veri geçirmek için bir eğitim input_fn kullanımı. TFL hazır tahmin edicilerini kullanmak ayrıca şunları gerektirir:
- örnek yapılandırma: Model mimarisi ve başına özelliği şekil kısıtlamalar ve regularizers tanımlanması.
- özelliği analiz input_fn: TFL başlatma verilerini geçen input_fn TF.
Daha kapsamlı bir açıklama için lütfen hazır tahminciler eğitimine veya API belgelerine bakın.
monotonluk
İlk önce monotonluk endişelerini, her iki özelliğe de monotonluk şekil kısıtlamaları ekleyerek ele alıyoruz.
Şekil kısıtlamaları uygulamak için TFL talimatını vermek biz özellik yapılandırmasında içinde kısıtlamaları belirtin. Biz çıkışı gerektiren nasıl Aşağıdaki kod gösterileri monoton olarak hem bakımından artan olmaya num_reviews ve avg_rating ayarlayarak monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
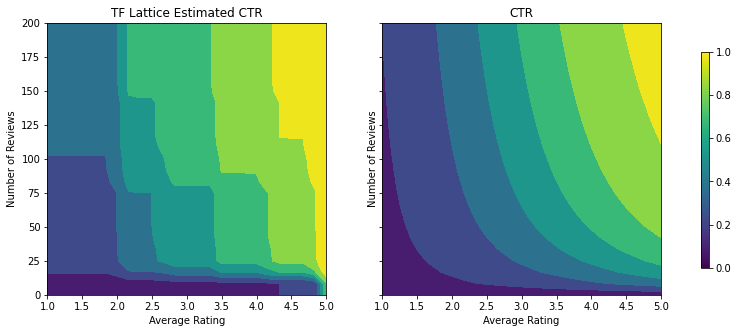
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
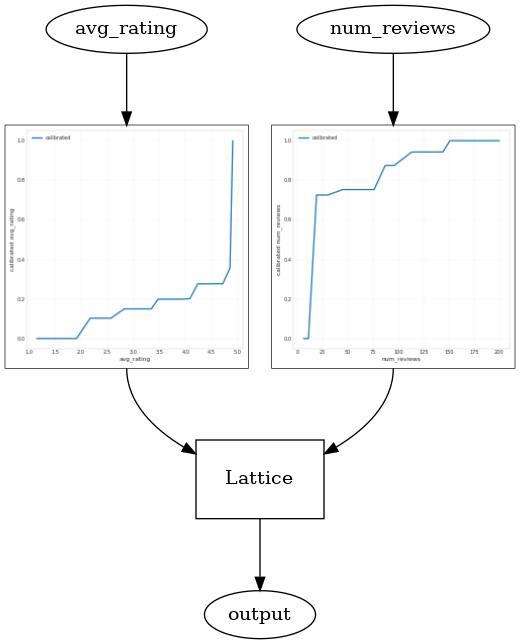
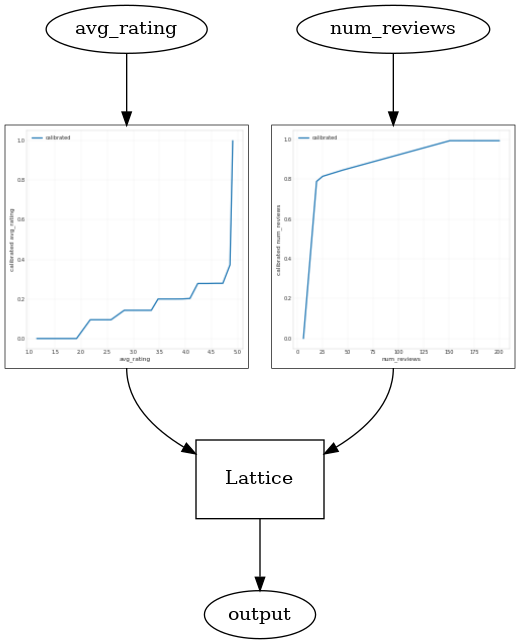
Bir kullanma CalibratedLatticeConfig önce, her bir giriş (sayısal özellikler için bir parça-bazlı doğrusal fonksiyonu) bir kalibrasyon cihazı geçerli olduğu bir konserve sınıflandırıcı oluşturur kalibre özellikleri sigorta doğrusal olmayan bir kafes tabaka takip eder. Biz kullanabilirsiniz tfl.visualization modeli görselleştirmek için. Özellikle, aşağıdaki çizim, hazır sınıflandırıcıya dahil edilen iki eğitimli kalibratörü göstermektedir.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
Eklenen kısıtlamalarla birlikte, ortalama puan arttıkça veya inceleme sayısı arttıkça tahmini TO her zaman artacaktır. Bu, kalibratörlerin ve kafesin monoton olduğundan emin olarak yapılır.
Azalan Getiriler
Döner Azalan biz değerini artırmak gibi belirli bir özellik değerini artırarak marjinal kazanç azalacak demektir. Bizim durumumuzda biz bekliyoruz num_reviews biz buna göre kalibratörünüzü yapılandırabilir böylece özellik, bu modeli takip eder. Azalan getirileri iki yeterli koşula ayırabileceğimize dikkat edin:
- kalibratör monoton olarak artıyor ve
- kalibratör içbükeydir.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
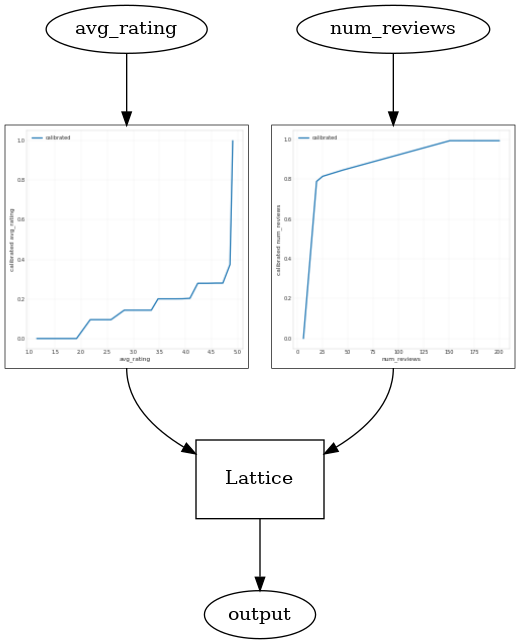
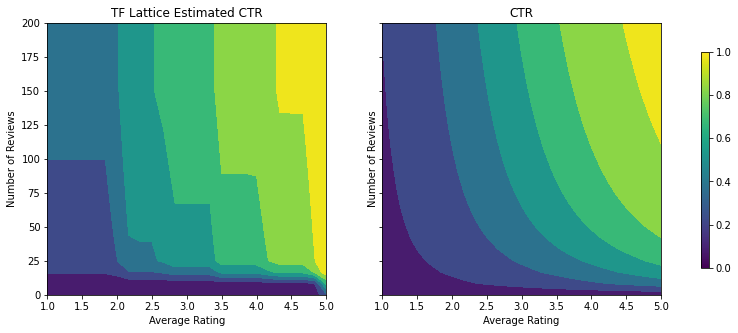
İçbükeylik kısıtlamasını ekleyerek test metriğinin nasıl geliştiğine dikkat edin. Tahmin planı da temel gerçeğe daha çok benziyor.
2B Şekil Kısıtlaması: Güven
Yalnızca bir veya iki yoruma sahip bir restoran için 5 yıldızlı bir puan büyük olasılıkla güvenilmez bir puandır (restoran aslında iyi olmayabilir), oysa yüzlerce yoruma sahip bir restoran için 4 yıldızlı bir puan çok daha güvenilirdir (restoran bu durumda muhtemelen iyi). Bir restoranın yorum sayısının, ortalama puanına ne kadar güvendiğimizi etkilediğini görebiliriz.
Modele, bir özelliğin daha büyük (veya daha küçük) değerinin başka bir özelliğe daha fazla güveni veya güveni gösterdiğini bildirmek için TFL güven kısıtlamaları uygulayabiliriz. Bu ayar yapılır reflects_trust_in özelliği config yapılandırmayı.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
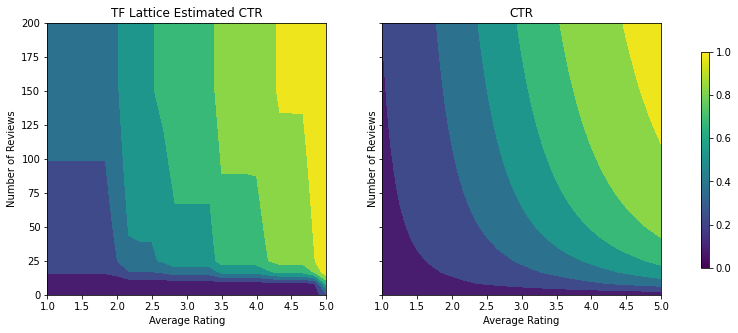
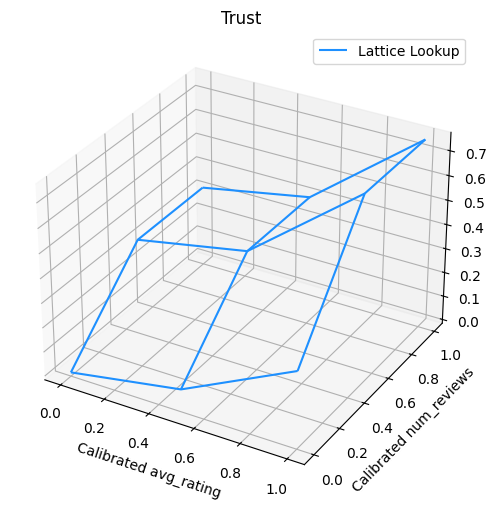
Aşağıdaki çizim, eğitilmiş kafes işlevini sunar. Güven kısıtlaması nedeniyle, kalibre daha büyük değerler bekliyoruz num_reviews kalibre göre daha yüksek eğime zorlayacaktır avg_rating kafes üretimde daha önemli bir hareket sonuçlanan.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
Pürüzsüzleştirici Kalibratörler
Şimdi bir kalibratör bir göz atalım avg_rating . Monoton bir şekilde artmasına rağmen, eğimlerindeki değişiklikler ani ve yorumlanması zor. Yani, biz bir regularizer kurulumu kullanarak bu kalibratörünüzü yumuşatma düşünebilirsiniz anlaşılacağı regularizer_configs .
Burada bir başvuruda wrinkle eğrilik değişiklikleri azaltmak için regularizer. Ayrıca kullanabilirsiniz laplacian kalibratörünü ve düzleştirmek için regularizer hessian daha doğrusal hale getirmek için regularizer.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
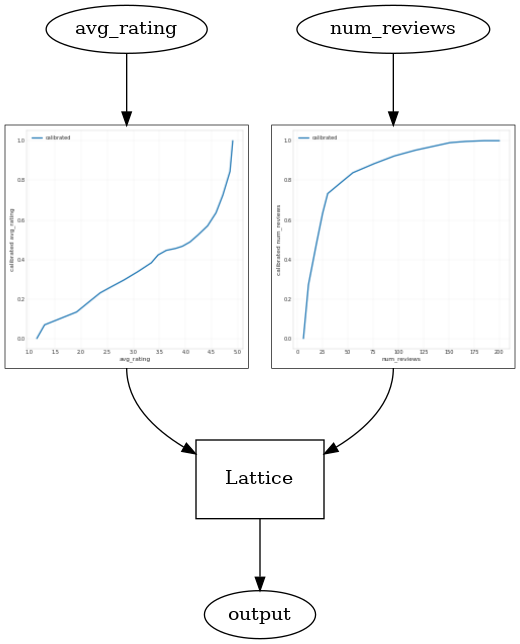
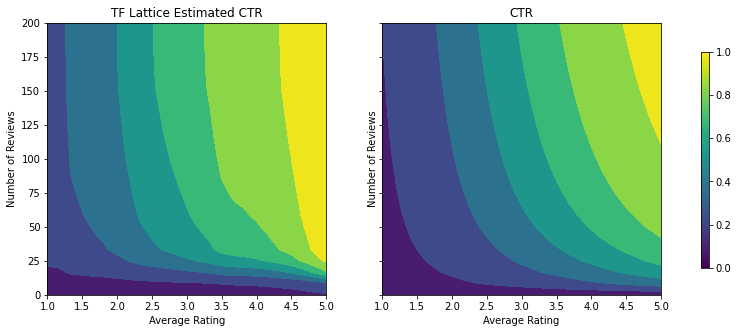
Kalibratörler artık sorunsuzdur ve genel olarak tahmini TO, temel gerçekle daha iyi eşleşir. Bu, hem test metriğinde hem de kontur grafiklerinde yansıtılır.
Kategorik Kalibrasyon için Kısmi Monotonluk
Şimdiye kadar modeldeki sayısal özelliklerden sadece ikisini kullandık. Burada kategorik bir kalibrasyon katmanı kullanarak üçüncü bir özellik ekleyeceğiz. Yine, çizim ve metrik hesaplama için yardımcı fonksiyonları ayarlayarak başlıyoruz.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Üçüncü özelliği dahil etmek dollar_rating , biz kategorik özellikler özellik sütunu olarak ve bir özellik yapılandırma olarak hem TFL biraz farklı tedavi gerektirir hatırlamak gerekir. Burada, diğer tüm girdiler sabitlendiğinde "DD" restoranlarının çıktılarının "D" restoranlarından daha büyük olması gerektiği şeklindeki kısmi monotonluk kısıtlamasını uyguluyoruz. Bu kullanılarak yapılır monotonicity özelliği config ayarı.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
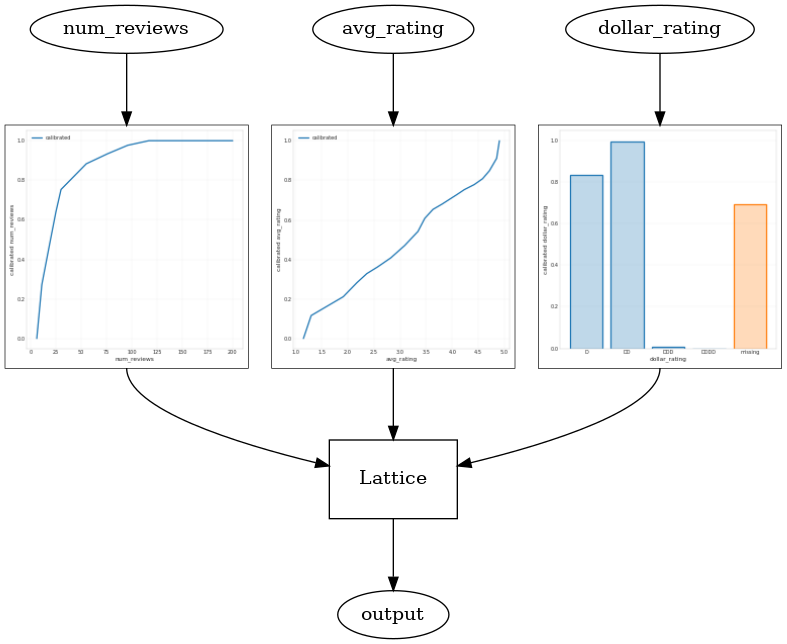
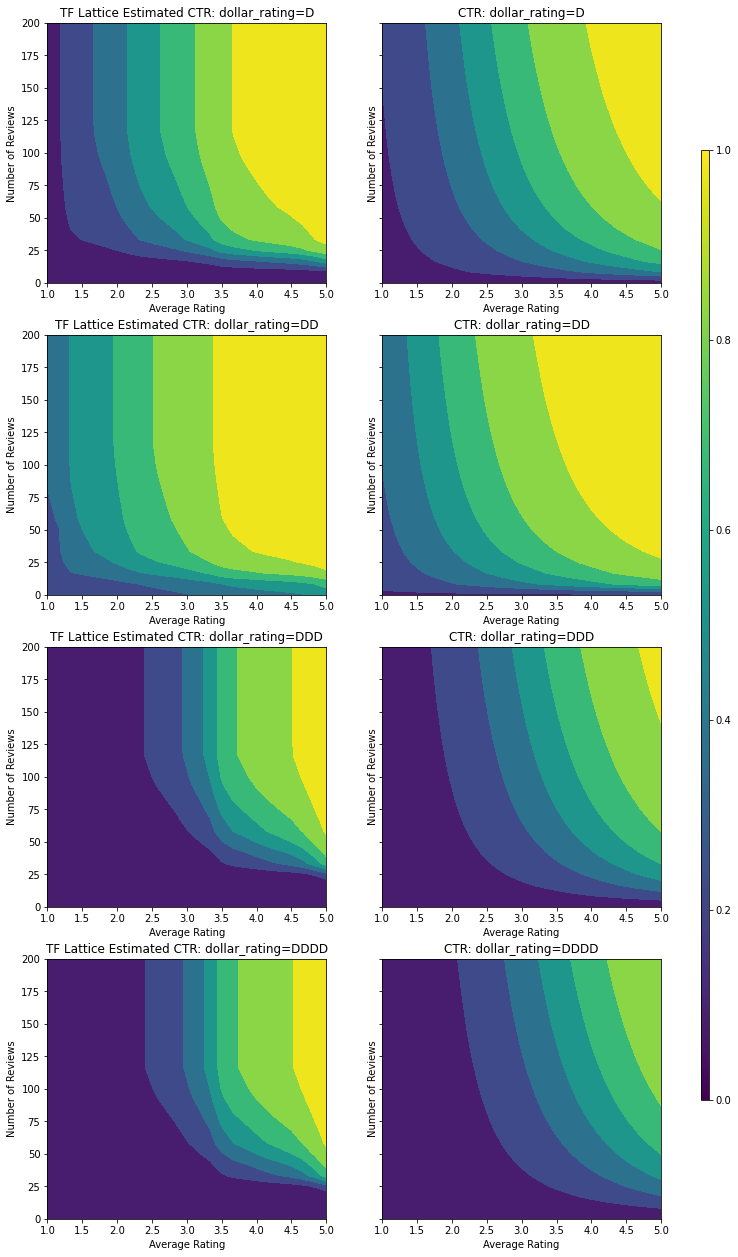
Bu kategorik kalibratör, kurulumumuzla tutarlı olan DD > D > DDD > DDDD model çıktısının tercihini gösterir. Ayrıca eksik değerler için bir sütun olduğuna dikkat edin. Eğitim ve test verilerimizde eksik bir özellik olmamasına rağmen, model, aşağı yönlü model sunumu sırasında meydana gelmesi durumunda eksik değer için bize bir atama sağlar.
İşte biz de şartına bu modelin tahmin TO çizmek dollar_rating . Gerekli tüm kısıtlamaların dilimlerin her birinde karşılandığına dikkat edin.
Çıkış Kalibrasyonu
Şimdiye kadar eğittiğimiz tüm TFL modelleri için, kafes katmanı (model grafiğinde "Kafes" olarak gösterilir) doğrudan model tahminini verir. Bazen kafes çıktısının model çıktılarını yaymak için yeniden ölçeklendirilmesi gerekip gerekmediğinden emin değiliz:
- özellikleri şunlardır \(log\) etiketler sayar iken sayar.
- kafes çok az köşeye sahip olacak şekilde yapılandırılmıştır ancak etiket dağılımı nispeten karmaşıktır.
Bu durumlarda, model esnekliğini artırmak için kafes çıktısı ile model çıktısı arasına başka bir kalibratör ekleyebiliriz. Burada yeni oluşturduğumuz modele 5 anahtar nokta içeren bir kalibratör katmanı ekleyelim. Fonksiyonu düzgün tutmak için çıkış kalibratörü için bir düzenleyici de ekledik.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
Son test metriği ve grafikler, sağduyu kısıtlamalarının kullanılmasının, modelin beklenmeyen davranışlardan kaçınmasına ve tüm girdi alanına daha iyi tahminde bulunmasına nasıl yardımcı olabileceğini gösterir.
,| | | Kaynağı GitHub'da görüntüleyin | |
genel bakış
Bu öğretici, TensorFlow Lattice (TFL) kitaplığı tarafından sağlanan kısıtlamalara ve düzenleyicilere genel bir bakış niteliğindedir. Burada sentetik veri kümelerinde TFL hazır tahmin edicileri kullanıyoruz, ancak bu eğitimdeki her şeyin TFL Keras katmanlarından oluşturulan modellerle de yapılabileceğini unutmayın.
Devam etmeden önce, çalışma zamanınızda gerekli tüm paketlerin kurulu olduğundan emin olun (aşağıdaki kod hücrelerinde içe aktarıldığı gibi).
Kurmak
TF Kafes paketini yükleme:
pip install -q tensorflow-lattice
Gerekli paketleri içe aktarma:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Bu kılavuzda kullanılan varsayılan değerler:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Restoranları Sıralamak için Eğitim Veri Kümesi
Kullanıcıların bir restoran arama sonucuna tıklayıp tıklamayacağını belirlemek istediğimiz basitleştirilmiş bir senaryo hayal edin. Görev, verilen girdi özelliklerine tıklama oranını (TO) tahmin etmektir:
- Ortalama değeri (
avg_rating) aralığında [1,5] değerleri ile sayısal bir özelliktir. - Yorum sayısı (
num_reviews): Biz trendiness bir ölçüsü olarak kullanmak 200'de şapkalı değerlere sahip bir sayısal özellik. - Dolar değerlendirmesi (
dollar_rating): set { "D", "DD", "DDD", "DDDD"} dize değerleri olan kategorik özellik.
Burada, gerçek TO'nun aşağıdaki formülle verildiği sentetik bir veri kümesi oluşturuyoruz:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
burada \(b(\cdot)\) her çevirir dollar_rating bir temel değere:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Bu formül, tipik kullanıcı kalıplarını yansıtır. örneğin, diğer her şey sabitlendiğinde, kullanıcılar daha yüksek yıldız derecelendirmesine sahip restoranları tercih eder ve "\$\$" restoranları "\$" yerine daha fazla tıklama alır, ardından "\$\$\$" ve "\$\$\$ gelir \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Bu CTR fonksiyonunun kontur grafiklerine bir göz atalım.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Veri Hazırlama
Şimdi sentetik veri kümelerimizi oluşturmamız gerekiyor. Simüle edilmiş bir restoran veri seti ve özellikleri oluşturarak başlıyoruz.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
Eğitim, doğrulama ve test veri setlerini üretelim. Arama sonuçlarında bir restoran görüntülendiğinde, kullanıcının etkileşimini (tıklama veya tıklama olmaması) örnek bir nokta olarak kaydedebiliriz.
Uygulamada, kullanıcılar çoğu zaman tüm arama sonuçlarını incelemezler. Bu, kullanıcıların yalnızca kullanımda olan mevcut sıralama modeline göre zaten "iyi" kabul edilen restoranları göreceği anlamına gelir. Sonuç olarak, "iyi" restoranlar daha sık etkilenir ve eğitim veri setlerinde fazla temsil edilir. Daha fazla özellik kullanıldığında, eğitim veri kümesi, özellik alanının "kötü" bölümlerinde büyük boşluklara sahip olabilir.
Model sıralama için kullanıldığında, genellikle eğitim veri kümesi tarafından iyi temsil edilmeyen daha tekdüze bir dağılımla ilgili tüm sonuçlar üzerinde değerlendirilir. Bu durumda esnek ve karmaşık bir model, aşırı temsil edilen veri noktalarının gereğinden fazla uydurulması nedeniyle başarısız olabilir ve dolayısıyla genelleştirilebilirlikten yoksun olabilir. Biz eğitim veri kümesi onları almak edemez makul tahminlerde bulunmak için bir model kılavuz şekil kısıtlamaları eklemek için alan bilgisine uygulayarak bu sorunu ele.
Bu örnekte, eğitim veri seti çoğunlukla iyi ve popüler restoranlarla kullanıcı etkileşimlerinden oluşmaktadır. Test veri kümesi, yukarıda tartışılan değerlendirme ayarını simüle etmek için tek tip bir dağılıma sahiptir. Bu tür test veri setinin gerçek bir problem ortamında kullanılamayacağını unutmayın.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
Eğitim ve değerlendirme için kullanılan input_fns'yi tanımlama:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Gradyan Artırılmış Ağaçları Sığdırma
: Sadece iki özellikleri ile başlayalım avg_rating ve num_reviews .
Doğrulama ve test ölçümlerini çizmek ve hesaplamak için birkaç yardımcı fonksiyon oluşturuyoruz.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
TensorFlow gradyan destekli karar ağaçlarını veri kümesine sığdırabiliriz:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
Model, gerçek TO'nun genel şeklini yakalamış ve yeterli doğrulama metriklerine sahip olsa da, giriş alanının çeşitli bölümlerinde sezgisel olmayan davranışlara sahiptir: ortalama puan veya inceleme sayısı arttıkça tahmini TO azalır. Bunun nedeni, eğitim veri kümesi tarafından iyi kapsanmayan alanlarda örnek noktaların olmamasıdır. Modelin yalnızca verilerden doğru davranışı çıkarması mümkün değildir.
Bu sorunu çözmek için, modelin hem ortalama derecelendirme hem de inceleme sayısı açısından monoton olarak artan değerler vermesi gerektiği şeklindeki şekil kısıtlamasını uyguluyoruz. Bunu TFL'de nasıl uygulayacağımızı daha sonra göreceğiz.
DNN takma
Aynı adımları bir DNN sınıflandırıcı ile tekrarlayabiliriz. Benzer bir model gözlemleyebiliriz: az sayıda inceleme ile yeterli örnek noktasına sahip olmamak, anlamsız ekstrapolasyona neden olur. Doğrulama metriği ağaç çözümünden daha iyi olsa da, test metriğinin çok daha kötü olduğunu unutmayın.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
Şekil Kısıtlamaları
TensorFlow Lattice (TFL), eğitim verilerinin ötesinde model davranışını korumak için şekil kısıtlamalarını uygulamaya odaklanır. Bu şekil kısıtlamaları, TFL Keras katmanlarına uygulanır. Onların ayrıntılar bulunabilir bizim JMLR kağıdı .
Bu öğreticide, çeşitli şekil kısıtlamalarını kapsamak için TF hazır tahmin edicileri kullanıyoruz, ancak tüm bu adımların TFL Keras katmanlarından oluşturulan modellerle yapılabileceğini unutmayın.
Başka tahmin TensorFlow gibi, TFL tahmin kullanımı konserve özelliği sütun giriş biçimini tanımlamak ve veri geçirmek için bir eğitim input_fn kullanımı. TFL hazır tahmin edicilerini kullanmak ayrıca şunları gerektirir:
- örnek yapılandırma: Model mimarisi ve başına özelliği şekil kısıtlamalar ve regularizers tanımlanması.
- özelliği analiz input_fn: TFL başlatma verilerini geçen input_fn TF.
Daha kapsamlı bir açıklama için lütfen hazır tahminciler eğitimine veya API belgelerine bakın.
monotonluk
İlk önce monotonluk endişelerini, her iki özelliğe de monotonluk şekil kısıtlamaları ekleyerek ele alıyoruz.
Şekil kısıtlamaları uygulamak için TFL talimatını vermek biz özellik yapılandırmasında içinde kısıtlamaları belirtin. Biz çıkışı gerektiren nasıl Aşağıdaki kod gösterileri monoton olarak hem bakımından artan olmaya num_reviews ve avg_rating ayarlayarak monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
Bir kullanma CalibratedLatticeConfig önce, her bir giriş (sayısal özellikler için bir parça-bazlı doğrusal fonksiyonu) bir kalibrasyon cihazı geçerli olduğu bir konserve sınıflandırıcı oluşturur kalibre özellikleri sigorta doğrusal olmayan bir kafes tabaka takip eder. Biz kullanabilirsiniz tfl.visualization modeli görselleştirmek için. Özellikle, aşağıdaki çizim, hazır sınıflandırıcıya dahil edilen iki eğitimli kalibratörü göstermektedir.
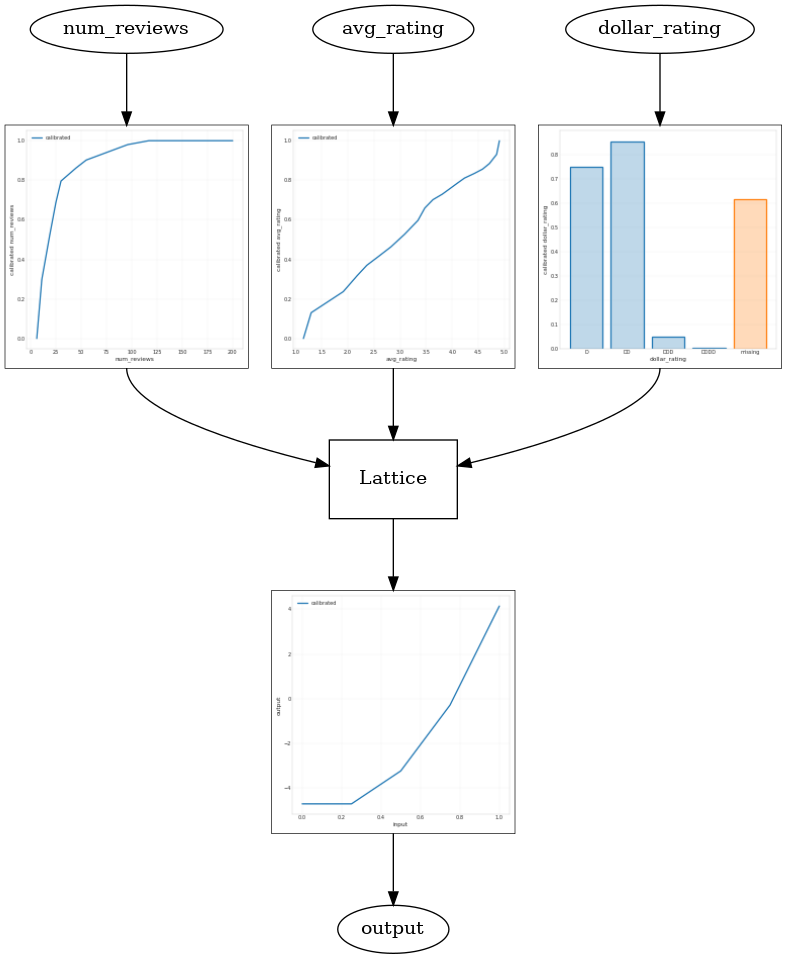
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
Eklenen kısıtlamalarla birlikte, ortalama puan arttıkça veya inceleme sayısı arttıkça tahmini TO her zaman artacaktır. Bu, kalibratörlerin ve kafesin monoton olduğundan emin olarak yapılır.
Azalan Getiriler
Döner Azalan biz değerini artırmak gibi belirli bir özellik değerini artırarak marjinal kazanç azalacak demektir. Bizim durumumuzda biz bekliyoruz num_reviews biz buna göre kalibratörünüzü yapılandırabilir böylece özellik, bu modeli takip eder. Azalan getirileri iki yeterli koşula ayırabileceğimize dikkat edin:
- kalibratör monoton olarak artıyor ve
- kalibratör içbükeydir.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
İçbükeylik kısıtlamasını ekleyerek test metriğinin nasıl geliştiğine dikkat edin. Tahmin planı da temel gerçeğe daha çok benziyor.
2B Şekil Kısıtlaması: Güven
Yalnızca bir veya iki yoruma sahip bir restoran için 5 yıldızlı bir puan büyük olasılıkla güvenilmez bir puandır (restoran aslında iyi olmayabilir), oysa yüzlerce yoruma sahip bir restoran için 4 yıldızlı bir puan çok daha güvenilirdir (restoran bu durumda muhtemelen iyi). Bir restoranın yorum sayısının, ortalama puanına ne kadar güvendiğimizi etkilediğini görebiliriz.
Modele, bir özelliğin daha büyük (veya daha küçük) değerinin başka bir özelliğe daha fazla güveni veya güveni gösterdiğini bildirmek için TFL güven kısıtlamaları uygulayabiliriz. Bu ayar yapılır reflects_trust_in özelliği config yapılandırmayı.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
Aşağıdaki çizim, eğitilmiş kafes işlevini sunar. Güven kısıtlaması nedeniyle, kalibre daha büyük değerler bekliyoruz num_reviews kalibre göre daha yüksek eğime zorlayacaktır avg_rating kafes üretimde daha önemli bir hareket sonuçlanan.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
Pürüzsüzleştirici Kalibratörler
Şimdi bir kalibratör bir göz atalım avg_rating . Monoton bir şekilde artmasına rağmen, eğimlerindeki değişiklikler ani ve yorumlanması zor. Yani, biz bir regularizer kurulumu kullanarak bu kalibratörünüzü yumuşatma düşünebilirsiniz anlaşılacağı regularizer_configs .
Burada bir başvuruda wrinkle eğrilik değişiklikleri azaltmak için regularizer. Ayrıca kullanabilirsiniz laplacian kalibratörünü ve düzleştirmek için regularizer hessian daha doğrusal hale getirmek için regularizer.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
Kalibratörler artık sorunsuzdur ve genel olarak tahmini TO, temel gerçekle daha iyi eşleşir. Bu, hem test metriğinde hem de kontur grafiklerinde yansıtılır.
Kategorik Kalibrasyon için Kısmi Monotonluk
Şimdiye kadar modeldeki sayısal özelliklerden sadece ikisini kullandık. Burada kategorik bir kalibrasyon katmanı kullanarak üçüncü bir özellik ekleyeceğiz. Yine, çizim ve metrik hesaplama için yardımcı fonksiyonları ayarlayarak başlıyoruz.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
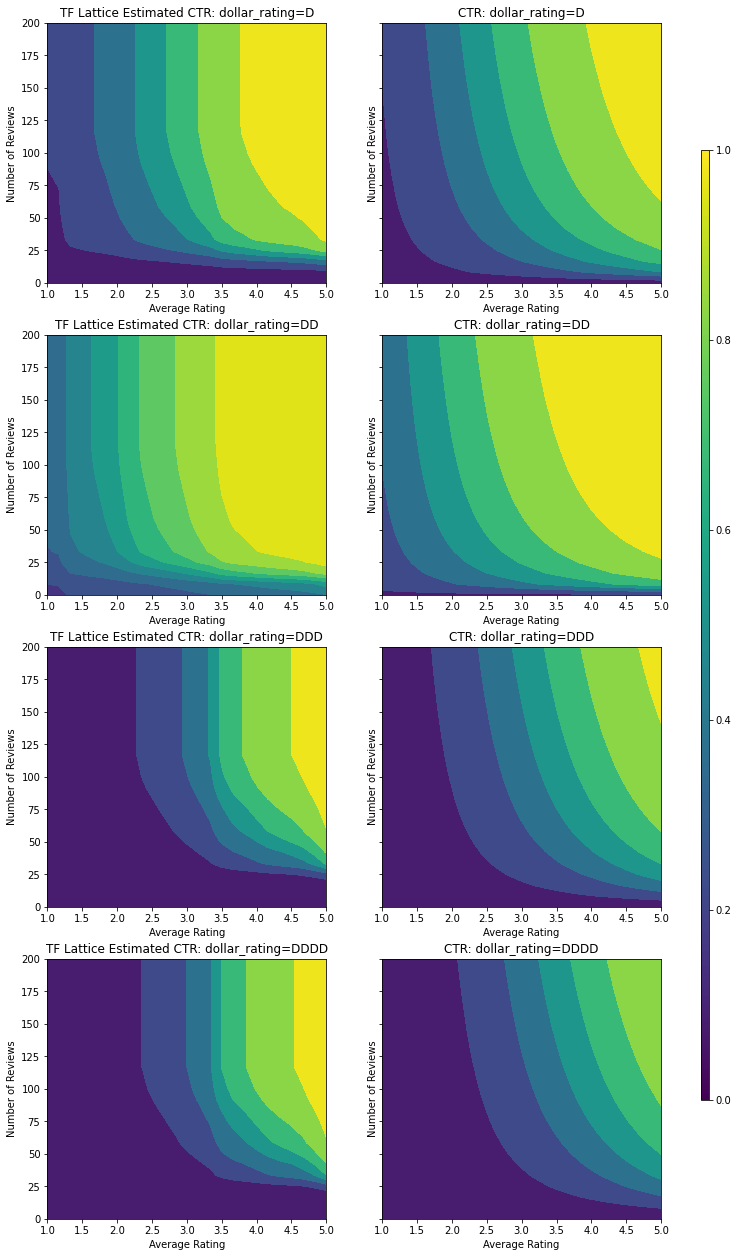
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Üçüncü özelliği dahil etmek dollar_rating , biz kategorik özellikler özellik sütunu olarak ve bir özellik yapılandırma olarak hem TFL biraz farklı tedavi gerektirir hatırlamak gerekir. Burada, diğer tüm girdiler sabitlendiğinde "DD" restoranlarının çıktılarının "D" restoranlarından daha büyük olması gerektiği şeklindeki kısmi monotonluk kısıtlamasını uyguluyoruz. Bu kullanılarak yapılır monotonicity özelliği config ayarı.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
Bu kategorik kalibratör, kurulumumuzla tutarlı olan DD > D > DDD > DDDD model çıktısının tercihini gösterir. Ayrıca eksik değerler için bir sütun olduğuna dikkat edin. Eğitim ve test verilerimizde eksik bir özellik olmamasına rağmen, model, aşağı yönlü model sunumu sırasında meydana gelmesi durumunda eksik değer için bize bir atama sağlar.
İşte biz de şartına bu modelin tahmin TO çizmek dollar_rating . Gerekli tüm kısıtlamaların dilimlerin her birinde karşılandığına dikkat edin.
Çıkış Kalibrasyonu
Şimdiye kadar eğittiğimiz tüm TFL modelleri için, kafes katmanı (model grafiğinde "Kafes" olarak gösterilir) doğrudan model tahminini verir. Bazen kafes çıktısının model çıktılarını yaymak için yeniden ölçeklendirilmesi gerekip gerekmediğinden emin değiliz:
- özellikleri şunlardır \(log\) etiketler sayar iken sayar.
- kafes çok az köşeye sahip olacak şekilde yapılandırılmıştır ancak etiket dağılımı nispeten karmaşıktır.
Bu durumlarda, model esnekliğini artırmak için kafes çıktısı ile model çıktısı arasına başka bir kalibratör ekleyebiliriz. Burada yeni oluşturduğumuz modele 5 anahtar nokta içeren bir kalibratör katmanı ekleyelim. Fonksiyonu düzgün tutmak için çıkış kalibratörü için bir düzenleyici de ekledik.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
Son test metriği ve grafikler, sağduyu kısıtlamalarının kullanılmasının, modelin beklenmeyen davranışlardan kaçınmasına ve tüm girdi alanına daha iyi tahminde bulunmasına nasıl yardımcı olabileceğini gösterir.