
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
genel bakış
Bu eğitim TensorFlow Kafes (TFL) kütüphane sorumlu davranmaya tren modelleri için kullanılabilir ve etik veya adil olan belirli varsayımlar ihlal etmediğinden nasıl kullanılacağını gösterir. Özellikle, belirli niteliklerin haksız cezalarla karşılaşmamak için monotonluk kısıtlamaları kullanarak odaklanacaktır. Bu öğretici kağıdı gelen deneylerin gösteriler içeren Deontolojik Etik By Monotonluk Şekli Kısıtlar yayınlanan Serena Wang ve Maya Gupta tarafından AISTATS 2020 .
Genel veri kümelerinde TFL hazır tahmin edicilerini kullanacağız, ancak bu eğitimdeki her şeyin TFL Keras katmanlarından oluşturulan modellerle de yapılabileceğini unutmayın.
Devam etmeden önce, çalışma zamanınızda gerekli tüm paketlerin kurulu olduğundan emin olun (aşağıdaki kod hücrelerinde içe aktarıldığı gibi).
Kurmak
TF Kafes paketini yükleme:
pip install tensorflow-lattice seaborn
Gerekli paketleri içe aktarma:
import tensorflow as tf
import logging
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Bu öğreticide kullanılan varsayılan değerler:
# List of learning rate hyperparameters to try.
# For a longer list of reasonable hyperparameters, try [0.001, 0.01, 0.1].
LEARNING_RATES = [0.01]
# Default number of training epochs and batch sizes.
NUM_EPOCHS = 1000
BATCH_SIZE = 1000
# Directory containing dataset files.
DATA_DIR = 'https://raw.githubusercontent.com/serenalwang/shape_constraints_for_ethics/master'
Örnek olay 1: Hukuk fakültesine kabul
Bu öğreticinin ilk bölümünde, Hukuk Okulu Kabul Konseyi'nden (LSAC) Hukuk Okulu Kabulleri veri setini kullanan bir vaka çalışmasını ele alacağız. İki özelliği kullanarak bir öğrencinin çıtayı geçip geçmeyeceğini tahmin etmek için bir sınıflandırıcı eğiteceğiz: öğrencinin LSAT puanı ve lisans not ortalaması.
Sınıflandırıcının puanının hukuk fakültesine kabulleri veya bursları yönlendirmek için kullanıldığını varsayalım. Başarıya dayalı sosyal normlara göre, daha yüksek GPA ve daha yüksek LSAT puanına sahip öğrencilerin sınıflandırıcıdan daha yüksek puan almalarını bekleriz. Ancak, modellerin bu sezgisel normları ihlal etmesinin kolay olduğunu ve bazen insanları daha yüksek bir GPA veya LSAT puanına sahip oldukları için cezalandırdığını gözlemleyeceğiz.
Bir modelin asla yüksek not ortalaması veya üstü LSAT puanı, her şeyin eşit cezalandırmaktadır böylece bu haksız cezalandırma sorunu çözmek için, biz monotonluk kısıtlamalar empoze edebilecek. Bu derste, TFL kullanarak bu monotonluk kısıtlamalarının nasıl uygulanacağını göstereceğiz.
Hukuk Fakültesi Verilerini Yükle
# Load data file.
law_file_name = 'lsac.csv'
law_file_path = os.path.join(DATA_DIR, law_file_name)
raw_law_df = pd.read_csv(law_file_path, delimiter=',')
Ön işleme veri kümesi:
# Define label column name.
LAW_LABEL = 'pass_bar'
def preprocess_law_data(input_df):
# Drop rows with where the label or features of interest are missing.
output_df = input_df[~input_df[LAW_LABEL].isna() & ~input_df['ugpa'].isna() &
(input_df['ugpa'] > 0) & ~input_df['lsat'].isna()]
return output_df
law_df = preprocess_law_data(raw_law_df)
Verileri tren/doğrulama/test setlerine ayırın
def split_dataset(input_df, random_state=888):
"""Splits an input dataset into train, val, and test sets."""
train_df, test_val_df = train_test_split(
input_df, test_size=0.3, random_state=random_state)
val_df, test_df = train_test_split(
test_val_df, test_size=0.66, random_state=random_state)
return train_df, val_df, test_df
law_train_df, law_val_df, law_test_df = split_dataset(law_df)
Veri dağıtımını görselleştirin
İlk önce verilerin dağılımını görselleştireceğiz. Barı geçen tüm öğrenciler ve ayrıca barı geçemeyen tüm öğrenciler için GPA ve LSAT puanlarını çizeceğiz.
def plot_dataset_contour(input_df, title):
plt.rcParams['font.family'] = ['serif']
g = sns.jointplot(
x='ugpa',
y='lsat',
data=input_df,
kind='kde',
xlim=[1.4, 4],
ylim=[0, 50])
g.plot_joint(plt.scatter, c='b', s=10, linewidth=1, marker='+')
g.ax_joint.collections[0].set_alpha(0)
g.set_axis_labels('Undergraduate GPA', 'LSAT score', fontsize=14)
g.fig.suptitle(title, fontsize=14)
# Adust plot so that the title fits.
plt.subplots_adjust(top=0.9)
plt.show()
law_df_pos = law_df[law_df[LAW_LABEL] == 1]
plot_dataset_contour(
law_df_pos, title='Distribution of students that passed the bar')

law_df_neg = law_df[law_df[LAW_LABEL] == 0]
plot_dataset_contour(
law_df_neg, title='Distribution of students that failed the bar')

Çubuk sınav geçişini tahmin etmek için kalibre edilmiş doğrusal modeli eğitin
Sonra, bir öğrenci barı geçecek olup olmadığını tahmin etmek TFL bir kalibre doğrusal modelini eğitim verecek. İki girdi özelliği, LSAT puanı ve lisans not ortalaması olacak ve eğitim etiketi, öğrencinin çıtayı geçip geçmediği olacaktır.
İlk önce herhangi bir kısıtlama olmaksızın kalibre edilmiş bir lineer modeli eğiteceğiz. Ardından, monotonluk kısıtlamaları ile kalibre edilmiş bir doğrusal modeli eğiteceğiz ve model çıktısı ve doğruluğundaki farkı gözlemleyeceğiz.
TFL ile kalibre edilmiş bir doğrusal tahminciyi eğitmek için yardımcı işlevler
Bu işlevler, bu hukuk fakültesi vaka çalışması ve ayrıca aşağıdaki kredi temerrüt vaka çalışması için kullanılacaktır.
def train_tfl_estimator(train_df, monotonicity, learning_rate, num_epochs,
batch_size, get_input_fn,
get_feature_columns_and_configs):
"""Trains a TFL calibrated linear estimator.
Args:
train_df: pandas dataframe containing training data.
monotonicity: if 0, then no monotonicity constraints. If 1, then all
features are constrained to be monotonically increasing.
learning_rate: learning rate of Adam optimizer for gradient descent.
num_epochs: number of training epochs.
batch_size: batch size for each epoch. None means the batch size is the full
dataset size.
get_input_fn: function that returns the input_fn for a TF estimator.
get_feature_columns_and_configs: function that returns TFL feature columns
and configs.
Returns:
estimator: a trained TFL calibrated linear estimator.
"""
feature_columns, feature_configs = get_feature_columns_and_configs(
monotonicity)
model_config = tfl.configs.CalibratedLinearConfig(
feature_configs=feature_configs, use_bias=False)
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=get_input_fn(input_df=train_df, num_epochs=1),
optimizer=tf.keras.optimizers.Adam(learning_rate))
estimator.train(
input_fn=get_input_fn(
input_df=train_df, num_epochs=num_epochs, batch_size=batch_size))
return estimator
def optimize_learning_rates(
train_df,
val_df,
test_df,
monotonicity,
learning_rates,
num_epochs,
batch_size,
get_input_fn,
get_feature_columns_and_configs,
):
"""Optimizes learning rates for TFL estimators.
Args:
train_df: pandas dataframe containing training data.
val_df: pandas dataframe containing validation data.
test_df: pandas dataframe containing test data.
monotonicity: if 0, then no monotonicity constraints. If 1, then all
features are constrained to be monotonically increasing.
learning_rates: list of learning rates to try.
num_epochs: number of training epochs.
batch_size: batch size for each epoch. None means the batch size is the full
dataset size.
get_input_fn: function that returns the input_fn for a TF estimator.
get_feature_columns_and_configs: function that returns TFL feature columns
and configs.
Returns:
A single TFL estimator that achieved the best validation accuracy.
"""
estimators = []
train_accuracies = []
val_accuracies = []
test_accuracies = []
for lr in learning_rates:
estimator = train_tfl_estimator(
train_df=train_df,
monotonicity=monotonicity,
learning_rate=lr,
num_epochs=num_epochs,
batch_size=batch_size,
get_input_fn=get_input_fn,
get_feature_columns_and_configs=get_feature_columns_and_configs)
estimators.append(estimator)
train_acc = estimator.evaluate(
input_fn=get_input_fn(train_df, num_epochs=1))['accuracy']
val_acc = estimator.evaluate(
input_fn=get_input_fn(val_df, num_epochs=1))['accuracy']
test_acc = estimator.evaluate(
input_fn=get_input_fn(test_df, num_epochs=1))['accuracy']
print('accuracies for learning rate %f: train: %f, val: %f, test: %f' %
(lr, train_acc, val_acc, test_acc))
train_accuracies.append(train_acc)
val_accuracies.append(val_acc)
test_accuracies.append(test_acc)
max_index = val_accuracies.index(max(val_accuracies))
return estimators[max_index]
Hukuk fakültesi veri kümesi özelliklerini yapılandırmak için yardımcı işlevler
Bu yardımcı işlevler, hukuk fakültesi vaka çalışmasına özgüdür.
def get_input_fn_law(input_df, num_epochs, batch_size=None):
"""Gets TF input_fn for law school models."""
return tf.compat.v1.estimator.inputs.pandas_input_fn(
x=input_df[['ugpa', 'lsat']],
y=input_df['pass_bar'],
num_epochs=num_epochs,
batch_size=batch_size or len(input_df),
shuffle=False)
def get_feature_columns_and_configs_law(monotonicity):
"""Gets TFL feature configs for law school models."""
feature_columns = [
tf.feature_column.numeric_column('ugpa'),
tf.feature_column.numeric_column('lsat'),
]
feature_configs = [
tfl.configs.FeatureConfig(
name='ugpa',
lattice_size=2,
pwl_calibration_num_keypoints=20,
monotonicity=monotonicity,
pwl_calibration_always_monotonic=False),
tfl.configs.FeatureConfig(
name='lsat',
lattice_size=2,
pwl_calibration_num_keypoints=20,
monotonicity=monotonicity,
pwl_calibration_always_monotonic=False),
]
return feature_columns, feature_configs
Eğitilmiş model çıktılarının görselleştirilmesi için yardımcı işlevler
def get_predicted_probabilities(estimator, input_df, get_input_fn):
predictions = estimator.predict(
input_fn=get_input_fn(input_df=input_df, num_epochs=1))
return [prediction['probabilities'][1] for prediction in predictions]
def plot_model_contour(estimator, input_df, num_keypoints=20):
x = np.linspace(min(input_df['ugpa']), max(input_df['ugpa']), num_keypoints)
y = np.linspace(min(input_df['lsat']), max(input_df['lsat']), num_keypoints)
x_grid, y_grid = np.meshgrid(x, y)
positions = np.vstack([x_grid.ravel(), y_grid.ravel()])
plot_df = pd.DataFrame(positions.T, columns=['ugpa', 'lsat'])
plot_df[LAW_LABEL] = np.ones(len(plot_df))
predictions = get_predicted_probabilities(
estimator=estimator, input_df=plot_df, get_input_fn=get_input_fn_law)
grid_predictions = np.reshape(predictions, x_grid.shape)
plt.rcParams['font.family'] = ['serif']
plt.contour(
x_grid,
y_grid,
grid_predictions,
colors=('k',),
levels=np.linspace(0, 1, 11))
plt.contourf(
x_grid,
y_grid,
grid_predictions,
cmap=plt.cm.bone,
levels=np.linspace(0, 1, 11)) # levels=np.linspace(0,1,8));
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
cbar = plt.colorbar()
cbar.ax.set_ylabel('Model score', fontsize=20)
cbar.ax.tick_params(labelsize=20)
plt.xlabel('Undergraduate GPA', fontsize=20)
plt.ylabel('LSAT score', fontsize=20)
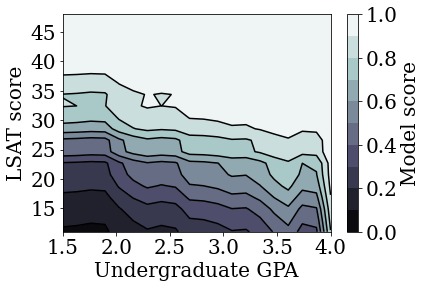
Kısıtlanmamış (monoton olmayan) kalibre edilmiş doğrusal modeli eğitin
nomon_linear_estimator = optimize_learning_rates(
train_df=law_train_df,
val_df=law_val_df,
test_df=law_test_df,
monotonicity=0,
learning_rates=LEARNING_RATES,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
get_input_fn=get_input_fn_law,
get_feature_columns_and_configs=get_feature_columns_and_configs_law)
2021-09-30 20:56:50.475180: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected accuracies for learning rate 0.010000: train: 0.949061, val: 0.945876, test: 0.951781
plot_model_contour(nomon_linear_estimator, input_df=law_df)
Monotonik kalibre edilmiş doğrusal modeli eğitin
mon_linear_estimator = optimize_learning_rates(
train_df=law_train_df,
val_df=law_val_df,
test_df=law_test_df,
monotonicity=1,
learning_rates=LEARNING_RATES,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
get_input_fn=get_input_fn_law,
get_feature_columns_and_configs=get_feature_columns_and_configs_law)
accuracies for learning rate 0.010000: train: 0.949249, val: 0.945447, test: 0.951781
plot_model_contour(mon_linear_estimator, input_df=law_df)

Diğer kısıtlanmamış modelleri eğitin
TFL ile kalibre edilmiş lineer modellerin, doğruluktan çok fazla ödün vermeden hem LSAT skorunda hem de GPA'da monoton olacak şekilde eğitilebileceğini gösterdik.
Ancak, kalibre edilmiş doğrusal model, derin sinir ağları (DNN'ler) veya gradyan destekli ağaçlar (GBT'ler) gibi diğer model türleriyle nasıl karşılaştırılır? DNN'ler ve GBT'ler makul ölçüde adil çıktılara sahip görünüyor mu? Bu soruyu ele almak için daha sonra kısıtlanmamış bir DNN ve GBT eğiteceğiz. Aslında, DNN ve GBT'nin hem LSAT puanı hem de lisans not ortalamasında monotonluğu kolayca ihlal ettiğini gözlemleyeceğiz.
Kısıtlanmamış bir Derin Sinir Ağı (DNN) modeli eğitin
Mimari daha önce yüksek doğrulama doğruluğu elde etmek için optimize edilmiştir.
feature_names = ['ugpa', 'lsat']
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=[
tf.feature_column.numeric_column(feature) for feature in feature_names
],
hidden_units=[100, 100],
optimizer=tf.keras.optimizers.Adam(learning_rate=0.008),
activation_fn=tf.nn.relu)
dnn_estimator.train(
input_fn=get_input_fn_law(
law_train_df, batch_size=BATCH_SIZE, num_epochs=NUM_EPOCHS))
dnn_train_acc = dnn_estimator.evaluate(
input_fn=get_input_fn_law(law_train_df, num_epochs=1))['accuracy']
dnn_val_acc = dnn_estimator.evaluate(
input_fn=get_input_fn_law(law_val_df, num_epochs=1))['accuracy']
dnn_test_acc = dnn_estimator.evaluate(
input_fn=get_input_fn_law(law_test_df, num_epochs=1))['accuracy']
print('accuracies for DNN: train: %f, val: %f, test: %f' %
(dnn_train_acc, dnn_val_acc, dnn_test_acc))
accuracies for DNN: train: 0.948874, val: 0.946735, test: 0.951559
plot_model_contour(dnn_estimator, input_df=law_df)

Kısıtlanmamış bir Gradient Boosted Trees (GBT) modeli eğitin
Ağaç yapısı daha önce yüksek doğrulama doğruluğu elde etmek için optimize edilmiştir.
tree_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=[
tf.feature_column.numeric_column(feature) for feature in feature_names
],
n_batches_per_layer=2,
n_trees=20,
max_depth=4)
tree_estimator.train(
input_fn=get_input_fn_law(
law_train_df, num_epochs=NUM_EPOCHS, batch_size=BATCH_SIZE))
tree_train_acc = tree_estimator.evaluate(
input_fn=get_input_fn_law(law_train_df, num_epochs=1))['accuracy']
tree_val_acc = tree_estimator.evaluate(
input_fn=get_input_fn_law(law_val_df, num_epochs=1))['accuracy']
tree_test_acc = tree_estimator.evaluate(
input_fn=get_input_fn_law(law_test_df, num_epochs=1))['accuracy']
print('accuracies for GBT: train: %f, val: %f, test: %f' %
(tree_train_acc, tree_val_acc, tree_test_acc))
accuracies for GBT: train: 0.949249, val: 0.945017, test: 0.950896
plot_model_contour(tree_estimator, input_df=law_df)

Örnek olay #2: Kredi Temerrüdü
Bu eğitimde ele alacağımız ikinci örnek olay, bir bireyin kredi temerrüt olasılığını tahmin etmektir. UCI deposundan Kredi Kartı Müşterilerinin Varsayılanı veri setini kullanacağız. Bu veriler 30.000 Tayvanlı kredi kartı kullanıcısından toplanmıştır ve bir kullanıcının bir zaman aralığında bir ödemede temerrüde düşüp düşmediğine ilişkin ikili bir etiket içerir. Özellikler arasında medeni durum, cinsiyet, eğitim ve bir kullanıcının Nisan-Eylül 2005 aylarının her biri için mevcut faturalarını ödemede ne kadar geciktiği yer alır.
Biz ilk örnek çalışma ile yaptığı gibi, yine haksız cezalarla karşılaşmamak için monotonluk kısıtları kullanarak göstermektedir: modeli kullanıcının kredi puanı belirlemek için kullanılabilir olsaydı onlar er faturalarını ödemekten cezalandırılmış olsaydı, birçok haksızlık hissediyordu, Her şey eşit. Bu nedenle, modeli erken ödemeleri cezalandırmaktan alıkoyan bir monotonluk kısıtlaması uyguluyoruz.
Kredi Varsayılan verilerini yükle
# Load data file.
credit_file_name = 'credit_default.csv'
credit_file_path = os.path.join(DATA_DIR, credit_file_name)
credit_df = pd.read_csv(credit_file_path, delimiter=',')
# Define label column name.
CREDIT_LABEL = 'default'
Verileri tren/doğrulama/test setlerine ayırın
credit_train_df, credit_val_df, credit_test_df = split_dataset(credit_df)
Veri dağıtımını görselleştirin
İlk önce verilerin dağılımını görselleştireceğiz. Farklı medeni durumları ve geri ödeme durumları olan kişiler için gözlemlenen temerrüt oranının ortalamasını ve standart hatasını çizeceğiz. Geri ödeme durumu, bir kişinin kredisini geri ödediği ayların sayısını temsil eder (Nisan 2005 itibariyle).
def get_agg_data(df, x_col, y_col, bins=11):
xbins = pd.cut(df[x_col], bins=bins)
data = df[[x_col, y_col]].groupby(xbins).agg(['mean', 'sem'])
return data
def plot_2d_means_credit(input_df, x_col, y_col, x_label, y_label):
plt.rcParams['font.family'] = ['serif']
_, ax = plt.subplots(nrows=1, ncols=1)
plt.setp(ax.spines.values(), color='black', linewidth=1)
ax.tick_params(
direction='in', length=6, width=1, top=False, right=False, labelsize=18)
df_single = get_agg_data(input_df[input_df['MARRIAGE'] == 1], x_col, y_col)
df_married = get_agg_data(input_df[input_df['MARRIAGE'] == 2], x_col, y_col)
ax.errorbar(
df_single[(x_col, 'mean')],
df_single[(y_col, 'mean')],
xerr=df_single[(x_col, 'sem')],
yerr=df_single[(y_col, 'sem')],
color='orange',
marker='s',
capsize=3,
capthick=1,
label='Single',
markersize=10,
linestyle='')
ax.errorbar(
df_married[(x_col, 'mean')],
df_married[(y_col, 'mean')],
xerr=df_married[(x_col, 'sem')],
yerr=df_married[(y_col, 'sem')],
color='b',
marker='^',
capsize=3,
capthick=1,
label='Married',
markersize=10,
linestyle='')
leg = ax.legend(loc='upper left', fontsize=18, frameon=True, numpoints=1)
ax.set_xlabel(x_label, fontsize=18)
ax.set_ylabel(y_label, fontsize=18)
ax.set_ylim(0, 1.1)
ax.set_xlim(-2, 8.5)
ax.patch.set_facecolor('white')
leg.get_frame().set_edgecolor('black')
leg.get_frame().set_facecolor('white')
leg.get_frame().set_linewidth(1)
plt.show()
plot_2d_means_credit(credit_train_df, 'PAY_0', 'default',
'Repayment Status (April)', 'Observed default rate')

Kredi temerrüt oranını tahmin etmek için kalibre edilmiş doğrusal model eğitin
Sonra, bir kişinin bir kredi yerine getirememesi olsun veya olmasın tahmin etmek TFL bir kalibre doğrusal modelini eğitim verecek. İki girdi özelliği, kişinin medeni durumu ve kişinin Nisan ayında kredilerini geri ödemesinde kaç ay geride kaldığı (geri ödeme durumu) olacaktır. Eğitim etiketi, kişinin bir krediyi temerrüde düşürüp düşürmediği olacaktır.
İlk önce herhangi bir kısıtlama olmaksızın kalibre edilmiş bir lineer modeli eğiteceğiz. Ardından, monotonluk kısıtlamaları ile kalibre edilmiş bir doğrusal modeli eğiteceğiz ve model çıktısı ve doğruluğundaki farkı gözlemleyeceğiz.
Kredi varsayılan veri kümesi özelliklerini yapılandırmak için yardımcı işlevler
Bu yardımcı işlevler, kredi temerrüdü vaka çalışmasına özeldir.
def get_input_fn_credit(input_df, num_epochs, batch_size=None):
"""Gets TF input_fn for credit default models."""
return tf.compat.v1.estimator.inputs.pandas_input_fn(
x=input_df[['MARRIAGE', 'PAY_0']],
y=input_df['default'],
num_epochs=num_epochs,
batch_size=batch_size or len(input_df),
shuffle=False)
def get_feature_columns_and_configs_credit(monotonicity):
"""Gets TFL feature configs for credit default models."""
feature_columns = [
tf.feature_column.numeric_column('MARRIAGE'),
tf.feature_column.numeric_column('PAY_0'),
]
feature_configs = [
tfl.configs.FeatureConfig(
name='MARRIAGE',
lattice_size=2,
pwl_calibration_num_keypoints=3,
monotonicity=monotonicity,
pwl_calibration_always_monotonic=False),
tfl.configs.FeatureConfig(
name='PAY_0',
lattice_size=2,
pwl_calibration_num_keypoints=10,
monotonicity=monotonicity,
pwl_calibration_always_monotonic=False),
]
return feature_columns, feature_configs
Eğitilmiş model çıktılarının görselleştirilmesi için yardımcı işlevler
def plot_predictions_credit(input_df,
estimator,
x_col,
x_label='Repayment Status (April)',
y_label='Predicted default probability'):
predictions = get_predicted_probabilities(
estimator=estimator, input_df=input_df, get_input_fn=get_input_fn_credit)
new_df = input_df.copy()
new_df.loc[:, 'predictions'] = predictions
plot_2d_means_credit(new_df, x_col, 'predictions', x_label, y_label)
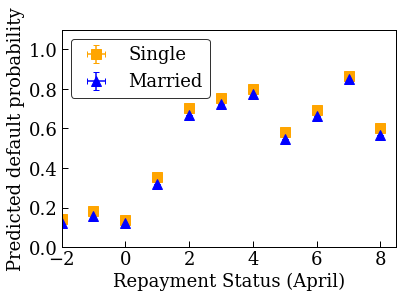
Kısıtlanmamış (monoton olmayan) kalibre edilmiş doğrusal modeli eğitin
nomon_linear_estimator = optimize_learning_rates(
train_df=credit_train_df,
val_df=credit_val_df,
test_df=credit_test_df,
monotonicity=0,
learning_rates=LEARNING_RATES,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
get_input_fn=get_input_fn_credit,
get_feature_columns_and_configs=get_feature_columns_and_configs_credit)
accuracies for learning rate 0.010000: train: 0.818762, val: 0.830065, test: 0.817172
plot_predictions_credit(credit_train_df, nomon_linear_estimator, 'PAY_0')
Monotonik kalibre edilmiş doğrusal modeli eğitin
mon_linear_estimator = optimize_learning_rates(
train_df=credit_train_df,
val_df=credit_val_df,
test_df=credit_test_df,
monotonicity=1,
learning_rates=LEARNING_RATES,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
get_input_fn=get_input_fn_credit,
get_feature_columns_and_configs=get_feature_columns_and_configs_credit)
accuracies for learning rate 0.010000: train: 0.818762, val: 0.830065, test: 0.817172
plot_predictions_credit(credit_train_df, mon_linear_estimator, 'PAY_0')
