| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
Korzystanie z projektora TensorBoard Osadzanie można graficznie przedstawiają wysokie zanurzeń wymiarowych. Może to być pomocne w wizualizacji, badaniu i zrozumieniu warstw osadzania.

W tym samouczku dowiesz się, jak wizualizować ten rodzaj wytrenowanej warstwy.
Ustawiać
W tym samouczku użyjemy TensorBoard do wizualizacji warstwy osadzania wygenerowanej do klasyfikowania danych recenzji filmu.
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
Dane IMDB
Będziemy używać zestawu danych zawierającego 25 000 recenzji filmów IMDB, z których każda ma etykietę sentymentu (pozytywna/negatywna). Każda recenzja jest wstępnie przetwarzana i kodowana jako sekwencja indeksów słownych (liczby całkowite). Dla uproszczenia, słowa są indeksowane według ogólnej częstotliwości w zbiorze danych, na przykład liczba całkowita „3” koduje trzecie najczęstsze słowo pojawiające się we wszystkich recenzjach. Pozwala to na szybkie operacje filtrowania, takie jak: „rozważ tylko 10 000 najpopularniejszych słów, ale wyeliminuj 20 najpopularniejszych słów”.
Zgodnie z konwencją „0” nie oznacza żadnego konkretnego słowa, ale jest używane do zakodowania dowolnego nieznanego słowa. W dalszej części samouczka usuniemy wiersz z wartością „0” z wizualizacji.
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Warstwa do osadzania Keras
Keras Osadzanie warstwy mogą być używane do szkolenia się osadzanie dla każdego słowa w Twoim słowniku. Każde słowo (lub w tym przypadku słowo podrzędne) będzie skojarzone z 16-wymiarowym wektorem (lub osadzaniem), który będzie szkolony przez model.
Zobacz ten poradnik , aby dowiedzieć się więcej o zanurzeń słownych.
# Create an embedding layer.
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Configure the embedding layer as part of a keras model.
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model.
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model for one epoch.
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 13s 5ms/step - loss: 0.5330 - accuracy: 0.6769 - val_loss: 0.4043 - val_accuracy: 0.7800
Zapisywanie danych dla TensorBoard
TensorBoard odczytuje tensory i metadane z dzienników Twoich projektów tensorflow. Ścieżka do katalogu dziennika jest określona log_dir poniżej. W tym tutorialu będziemy używać /logs/imdb-example/ .
Aby wczytać dane do Tensorboard, musimy zapisać w tym katalogu treningowy punkt kontrolny wraz z metadanymi pozwalającymi na wizualizację określonej warstwy zainteresowania w modelu.
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown".
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%tensorboard --logdir /logs/imdb-example/
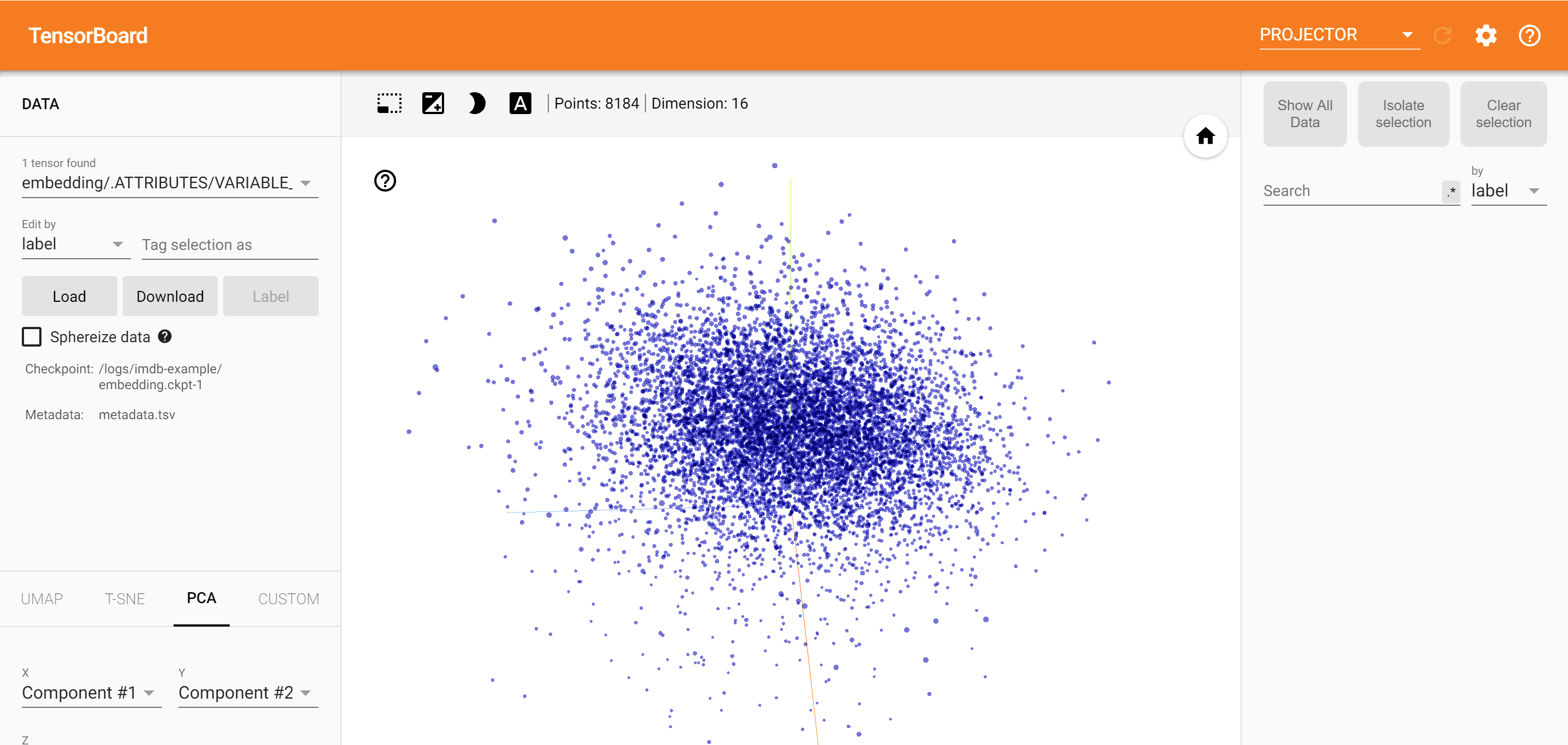
Analiza
Projektor TensorBoard jest doskonałym narzędziem do interpretacji i wizualizacji osadzania. Pulpit nawigacyjny umożliwia użytkownikom wyszukiwanie określonych terminów i wyróżnia słowa, które sąsiadują ze sobą w przestrzeni osadzenia (niskowymiarowej). Na tym przykładzie widzimy, że Wes Anderson i Alfred Hitchcock oba terminy są raczej neutralne, ale że są one odwoływać się w różnych kontekstach.
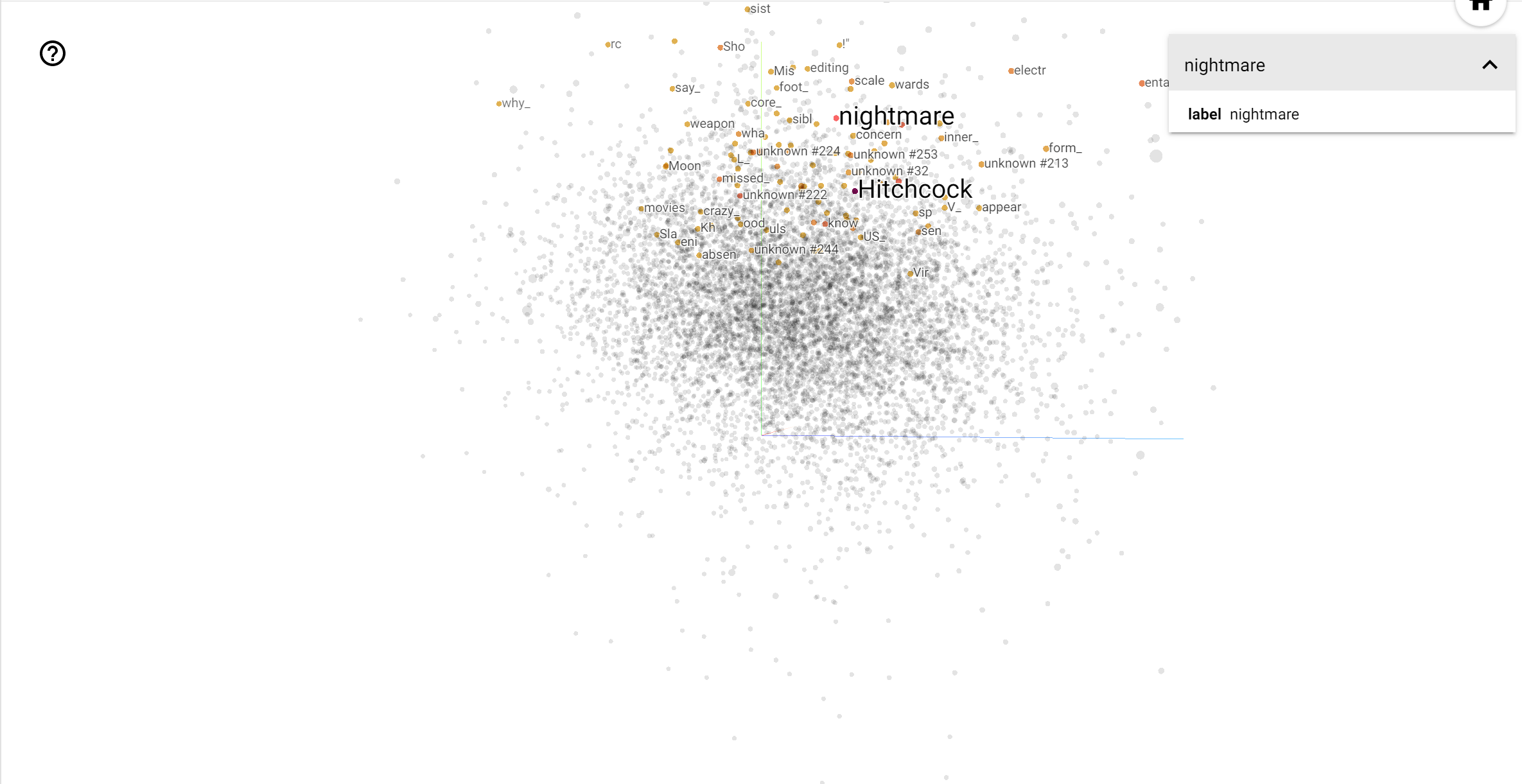
W tej przestrzeni, Hitchcock jest bliżej do słów takich jak nightmare , który jest prawdopodobnie ze względu na fakt, że jest on znany jako „Mistrz suspensu”, natomiast Anderson jest bliżej słowu heart , co jest zgodne z jego nieustannie szczegółowe i pogodnej stylu .