
Validasi Data TensorFlow (TFDV) dapat menganalisis data pelatihan dan penyajian untuk:
menghitung statistik deskriptif,
menyimpulkan skema ,
mendeteksi anomali data .
API inti mendukung setiap fungsionalitas, dengan metode praktis yang dibangun di atas dan dapat dipanggil dalam konteks notebook.
Menghitung statistik data deskriptif
TFDV dapat menghitung statistik deskriptif yang memberikan gambaran singkat tentang data dalam hal fitur yang ada dan bentuk distribusi nilainya. Alat seperti Ikhtisar Aspek dapat memberikan visualisasi singkat dari statistik ini untuk kemudahan penelusuran.
Misalnya, path tersebut menunjuk ke file dalam format TFRecord (yang menyimpan catatan bertipe tensorflow.Example ). Cuplikan berikut menggambarkan perhitungan statistik menggunakan TFDV:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
Nilai yang dikembalikan adalah buffer protokol DatasetFeatureStatisticsList . Contoh buku catatan berisi visualisasi statistik menggunakan Ikhtisar Faset :
tfdv.visualize_statistics(stats)
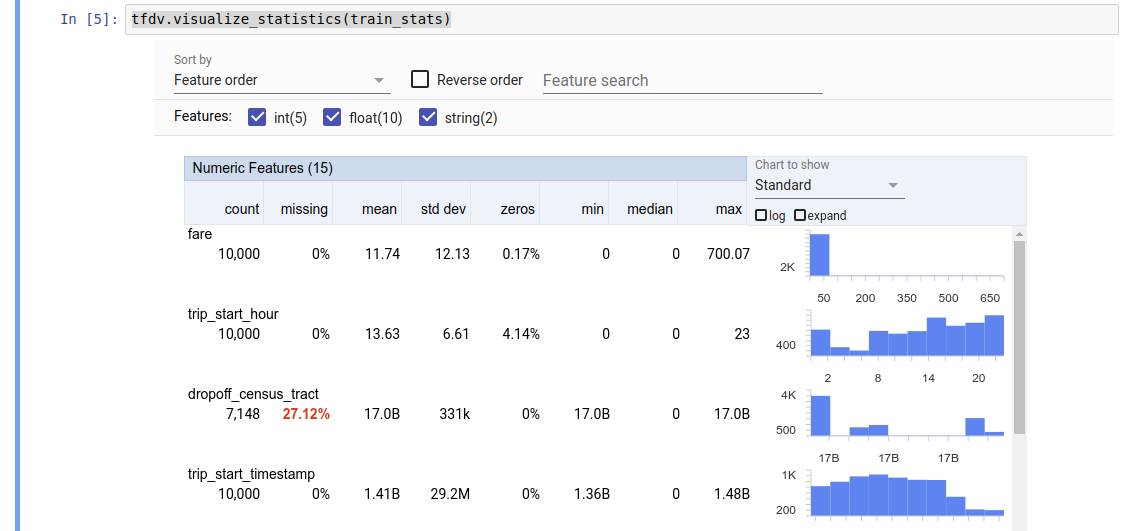
Contoh sebelumnya mengasumsikan bahwa data disimpan dalam file TFRecord . TFDV juga mendukung format masukan CSV, dengan ekstensibilitas untuk format umum lainnya. Anda dapat menemukan decoder data yang tersedia di sini . Selain itu, TFDV menyediakan fungsi utilitas tfdv.generate_statistics_from_dataframe untuk pengguna dengan data dalam memori yang direpresentasikan sebagai Pandas DataFrame.
Selain menghitung kumpulan statistik data default, TFDV juga dapat menghitung statistik untuk domain semantik (misalnya gambar, teks). Untuk mengaktifkan penghitungan statistik domain semantik, teruskan objek tfdv.StatsOptions dengan enable_semantic_domain_stats yang disetel ke True ke tfdv.generate_statistics_from_tfrecord .
Berjalan di Google Cloud
Secara internal, TFDV menggunakan kerangka pemrosesan paralel data Apache Beam untuk menskalakan komputasi statistik pada kumpulan data besar. Untuk aplikasi yang ingin berintegrasi lebih dalam dengan TFDV (misalnya melampirkan pembuatan statistik di akhir jalur pembuatan data, menghasilkan statistik untuk data dalam format khusus ), API juga memaparkan Beam PTransform untuk pembuatan statistik.
Untuk menjalankan TFDV di Google Cloud, file roda TFDV harus diunduh dan diberikan kepada pekerja Dataflow. Unduh file roda ke direktori saat ini sebagai berikut:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
Cuplikan berikut menunjukkan contoh penggunaan TFDV di Google Cloud:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
Dalam hal ini, proto statistik yang dihasilkan disimpan dalam file TFRecord yang ditulis ke GCS_STATS_OUTPUT_PATH .
CATATAN Saat memanggil salah satu fungsi tfdv.generate_statistics_... (misalnya, tfdv.generate_statistics_from_tfrecord ) di Google Cloud, Anda harus memberikan output_path . Menentukan Tidak Ada dapat menyebabkan kesalahan.
Menyimpulkan skema atas data
Skema ini menjelaskan properti data yang diharapkan. Beberapa properti tersebut adalah:
- fitur apa saja yang diharapkan hadir
- tipe mereka
- jumlah nilai untuk suatu fitur di setiap contoh
- kehadiran setiap fitur di semua contoh
- domain fitur yang diharapkan.
Singkatnya, skema ini menggambarkan ekspektasi terhadap data yang "benar" dan dengan demikian dapat digunakan untuk mendeteksi kesalahan dalam data (dijelaskan di bawah). Selain itu, skema yang sama dapat digunakan untuk menyiapkan Transformasi TensorFlow untuk transformasi data. Perhatikan bahwa skema diharapkan cukup statis, misalnya, beberapa kumpulan data dapat menyesuaikan diri dengan skema yang sama, sedangkan statistik (dijelaskan di atas) dapat bervariasi per kumpulan data.
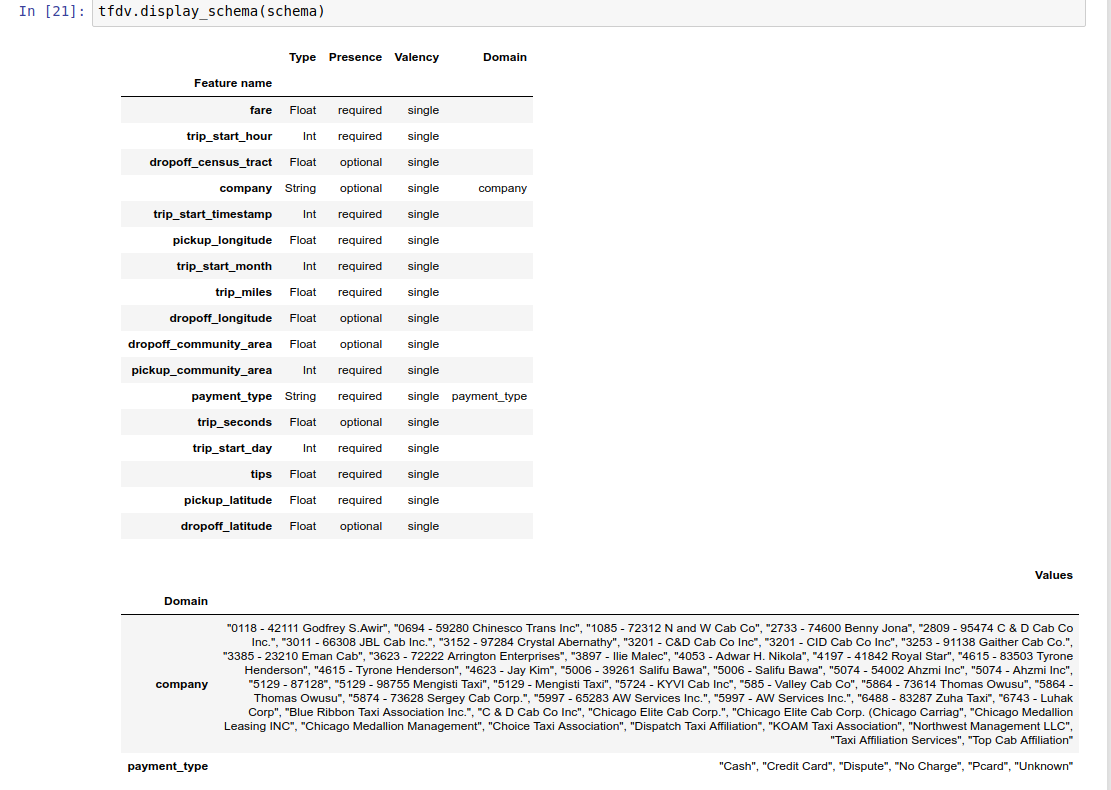
Karena menulis skema bisa menjadi tugas yang membosankan, terutama untuk kumpulan data dengan banyak fitur, TFDV menyediakan metode untuk menghasilkan versi awal skema berdasarkan statistik deskriptif:
schema = tfdv.infer_schema(stats)
Secara umum, TFDV menggunakan heuristik konservatif untuk menyimpulkan properti data yang stabil dari statistik untuk menghindari penyesuaian skema yang berlebihan dengan kumpulan data tertentu. Sangat disarankan untuk meninjau skema yang disimpulkan dan memperbaikinya sesuai kebutuhan , untuk menangkap pengetahuan domain apa pun tentang data yang mungkin terlewatkan oleh heuristik TFDV.
Secara default, tfdv.infer_schema menyimpulkan bentuk setiap fitur yang diperlukan, jika value_count.min sama dengan value_count.max untuk fitur tersebut. Setel argumen infer_feature_shape ke False untuk menonaktifkan inferensi bentuk.
Skema itu sendiri disimpan sebagai buffer protokol Skema dan dengan demikian dapat diperbarui/diedit menggunakan API buffer protokol standar. TFDV juga menyediakan beberapa metode utilitas untuk mempermudah pembaruan ini. Misalnya, skema berisi bait berikut untuk mendeskripsikan fitur string yang diperlukan payment_type yang mengambil nilai tunggal:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
Untuk menandai bahwa fitur tersebut harus diisi setidaknya di 50% contoh:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
Contoh buku catatan berisi visualisasi sederhana skema sebagai tabel, mencantumkan setiap fitur dan karakteristik utamanya seperti yang dikodekan dalam skema.
Memeriksa data untuk kesalahan
Dengan adanya skema, dimungkinkan untuk memeriksa apakah kumpulan data sesuai dengan ekspektasi yang ditetapkan dalam skema atau apakah terdapat anomali data . Anda dapat memeriksa kesalahan pada data Anda (a) secara agregat di seluruh kumpulan data dengan mencocokkan statistik kumpulan data dengan skema, atau (b) dengan memeriksa kesalahan berdasarkan per contoh.
Mencocokkan statistik kumpulan data dengan skema
Untuk memeriksa kesalahan secara agregat, TFDV mencocokkan statistik kumpulan data dengan skema dan menandai setiap perbedaan. Misalnya:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
Hasilnya adalah contoh buffer protokol Anomali dan menjelaskan kesalahan apa pun yang statistiknya tidak sesuai dengan skema. Misalnya, data di other_path berisi contoh dengan nilai untuk fitur payment_type di luar domain yang ditentukan dalam skema.
Hal ini menghasilkan sebuah anomali
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
menunjukkan bahwa nilai di luar domain ditemukan dalam statistik di <1% nilai fitur.
Jika hal ini diharapkan, maka skema dapat diperbarui sebagai berikut:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
Jika anomali benar-benar menunjukkan kesalahan data, maka data yang mendasarinya harus diperbaiki sebelum digunakan untuk pelatihan.
Berbagai jenis anomali yang dapat dideteksi oleh modul ini tercantum di sini .
Contoh buku catatan berisi visualisasi sederhana anomali dalam bentuk tabel, daftar fitur di mana kesalahan terdeteksi, dan deskripsi singkat setiap kesalahan.

Memeriksa kesalahan berdasarkan per contoh
TFDV juga menyediakan opsi untuk memvalidasi data berdasarkan per contoh, alih-alih membandingkan statistik seluruh kumpulan data dengan skema. TFDV menyediakan fungsi untuk memvalidasi data berdasarkan per contoh dan kemudian menghasilkan statistik ringkasan untuk contoh anomali yang ditemukan. Misalnya:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
anomalous_example_stats yang dikembalikan validate_examples_in_tfrecord adalah buffering protokol DatasetFeatureStatisticsList di mana setiap set data terdiri dari kumpulan contoh yang menunjukkan anomali tertentu. Anda dapat menggunakan ini untuk menentukan jumlah contoh dalam kumpulan data Anda yang menunjukkan anomali tertentu dan karakteristik contoh tersebut.
Lingkungan Skema
Secara default, validasi mengasumsikan bahwa semua himpunan data dalam alur mematuhi satu skema. Dalam beberapa kasus, diperlukan sedikit variasi skema, misalnya fitur yang digunakan sebagai label diperlukan selama pelatihan (dan harus divalidasi), namun hilang selama penayangan.
Lingkungan dapat digunakan untuk menyatakan persyaratan tersebut. Secara khusus, fitur dalam skema dapat dikaitkan dengan sekumpulan lingkungan menggunakan default_environment, in_environment, dan not_in_environment.
Misalnya, jika fitur tips digunakan sebagai label dalam pelatihan, namun tidak ada dalam penyajian data. Tanpa lingkungan yang ditentukan, ini akan muncul sebagai anomali.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

Untuk memperbaikinya, kita perlu menyetel lingkungan default untuk semua fitur menjadi 'PELATIHAN' dan 'SERVING', dan mengecualikan fitur 'tips' dari lingkungan SERVING.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
Memeriksa data yang miring dan menyimpang
Selain memeriksa apakah kumpulan data sesuai dengan ekspektasi yang ditetapkan dalam skema, TFDV juga menyediakan fungsi untuk mendeteksi:
- kemiringan antara pelatihan dan penyajian data
- melayang di antara hari-hari data pelatihan yang berbeda
TFDV melakukan pemeriksaan ini dengan membandingkan statistik kumpulan data yang berbeda berdasarkan pembanding penyimpangan/kemiringan yang ditentukan dalam skema. Misalnya, untuk memeriksa apakah ada perbedaan antara fitur 'jenis_pembayaran' dalam kumpulan data pelatihan dan penyajian:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
CATATAN Norma L-infinity hanya akan mendeteksi kemiringan untuk fitur kategorikal. Daripada menentukan ambang batas infinity_norm , menentukan ambang batas jensen_shannon_divergence di skew_comparator akan mendeteksi kemiringan untuk fitur numerik dan kategorikal.
Sama dengan memeriksa apakah kumpulan data sesuai dengan ekspektasi yang ditetapkan dalam skema, hasilnya juga merupakan instance dari buffer protokol Anomali dan menjelaskan setiap ketidaksesuaian antara kumpulan data pelatihan dan penyajian. Misalnya, data penayangan berisi lebih banyak contoh dengan fitur payement_type yang memiliki nilai Cash , hal ini menghasilkan anomali miring
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
Jika anomali tersebut benar-benar menunjukkan adanya kesenjangan antara pelatihan dan penyajian data, maka penyelidikan lebih lanjut diperlukan karena hal ini dapat berdampak langsung pada performa model.
Buku catatan contoh berisi contoh sederhana untuk memeriksa anomali berbasis kemiringan.
Mendeteksi penyimpangan antara hari data pelatihan yang berbeda dapat dilakukan dengan cara yang sama
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
CATATAN Norma L-infinity hanya akan mendeteksi kemiringan untuk fitur kategorikal. Daripada menentukan ambang batas infinity_norm , menentukan ambang batas jensen_shannon_divergence di skew_comparator akan mendeteksi kemiringan untuk fitur numerik dan kategorikal.
Menulis konektor data khusus
Untuk menghitung statistik data, TFDV menyediakan beberapa metode mudah untuk menangani data masukan dalam berbagai format (misalnya TFRecord dari tf.train.Example , CSV, dll). Jika format data Anda tidak ada dalam daftar ini, Anda perlu menulis konektor data khusus untuk membaca data masukan, dan menghubungkannya dengan API inti TFDV untuk menghitung statistik data.
API inti TFDV untuk menghitung statistik data adalah Beam PTransform yang mengambil PCollection kumpulan contoh masukan (kumpulan contoh masukan direpresentasikan sebagai Arrow RecordBatch), dan mengeluarkan PCollection yang berisi buffer protokol DatasetFeatureStatisticsList tunggal.
Setelah Anda menerapkan konektor data khusus yang mengelompokkan contoh masukan Anda di Arrow RecordBatch, Anda perlu menghubungkannya dengan tfdv.GenerateStatistics API untuk menghitung statistik data. Ambil TFRecord dari tf.train.Example misalnya. tfx_bsl menyediakan konektor data TFExampleRecord , dan di bawah ini adalah contoh cara menghubungkannya dengan tfdv.GenerateStatistics API.
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
Menghitung statistik pada potongan data
TFDV dapat dikonfigurasi untuk menghitung statistik pada potongan data. Pengirisan dapat diaktifkan dengan menyediakan fungsi pengirisan yang menggunakan Arrow RecordBatch dan menampilkan rangkaian tupel dalam bentuk (slice key, record batch) . TFDV menyediakan cara mudah untuk menghasilkan fungsi pemotongan berbasis nilai fitur yang dapat disediakan sebagai bagian dari tfdv.StatsOptions saat menghitung statistik.
Saat pemotongan diaktifkan, proto DatasetFeatureStatisticsList keluaran berisi beberapa proto DatasetFeatureStatistics , satu untuk setiap irisan. Setiap irisan diidentifikasi dengan nama unik yang ditetapkan sebagai nama kumpulan data di proto DatasetFeatureStatistics . Secara default, TFDV menghitung statistik untuk keseluruhan dataset selain irisan yang dikonfigurasi.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])