
Indikator Kewajaran dirancang untuk mendukung tim dalam mengevaluasi dan meningkatkan model untuk masalah keadilan dalam kemitraan dengan toolkit Tensorflow yang lebih luas. Alat ini saat ini aktif digunakan secara internal oleh banyak produk kami, dan kini tersedia dalam versi BETA untuk dicoba pada kasus penggunaan Anda sendiri.
Apa itu Indikator Kewajaran?
Indikator Keadilan adalah perpustakaan yang memungkinkan penghitungan metrik keadilan yang umum diidentifikasi dengan mudah untuk pengklasifikasi biner dan multikelas. Banyak alat yang ada untuk mengevaluasi masalah keadilan tidak berfungsi dengan baik pada kumpulan data dan model berskala besar. Di Google, penting bagi kami untuk memiliki alat yang dapat bekerja pada sistem dengan miliaran pengguna. Indikator Kewajaran akan memungkinkan Anda mengevaluasi berbagai ukuran kasus penggunaan.
Secara khusus, Indikator Kewajaran mencakup kemampuan untuk:
- Evaluasi distribusi kumpulan data
- Evaluasi kinerja model, yang dibagi ke dalam kelompok pengguna tertentu
- Merasa yakin dengan hasil Anda dengan interval keyakinan dan evaluasi pada berbagai ambang batas
- Selidiki lebih dalam bagian-bagian individual untuk mengeksplorasi akar permasalahan dan peluang perbaikan
Unduhan paket pip meliputi:
- Validasi Data Tensorflow (TFDV)
- Analisis Model Tensorflow (TFMA)
- Indikator Kewajaran
- Alat Bagaimana-Jika (WIT)
Menggunakan Indikator Kewajaran dengan Model Tensorflow
Data
Untuk menjalankan Indikator Kewajaran dengan TFMA, pastikan kumpulan data evaluasi diberi label sesuai fitur yang ingin Anda potong. Jika Anda tidak memiliki fitur irisan yang tepat untuk masalah keadilan Anda, Anda dapat mencari rangkaian evaluasi yang memiliki fitur tersebut, atau mempertimbangkan fitur proxy dalam rangkaian fitur Anda yang dapat menyoroti perbedaan hasil. Untuk panduan tambahan, lihat di sini .
Model
Anda dapat menggunakan kelas Tensorflow Estimator untuk membangun model Anda. Dukungan untuk model Keras akan segera hadir di TFMA. Jika Anda ingin menjalankan TFMA pada model Keras, silakan lihat bagian “Model-Agnostic TFMA” di bawah.
Setelah Estimator dilatih, Anda perlu mengekspor model tersimpan untuk tujuan evaluasi. Untuk mempelajari lebih lanjut, lihat panduan TFMA .
Mengonfigurasi Irisan
Selanjutnya, tentukan irisan yang ingin Anda evaluasi:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
Jika Anda ingin mengevaluasi irisan titik-temu (misalnya, warna dan tinggi bulu), Anda dapat mengatur hal berikut:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
Hitung Metrik Kewajaran
Tambahkan callback Indikator Kewajaran ke daftar metrics_callback . Dalam panggilan balik, Anda dapat menentukan daftar ambang batas tempat model akan dievaluasi.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
Sebelum menjalankan konfigurasi, tentukan apakah Anda ingin mengaktifkan penghitungan interval kepercayaan atau tidak. Interval kepercayaan dihitung menggunakan bootstrapping Poisson dan memerlukan penghitungan ulang pada 20 sampel.
compute_confidence_intervals = True
Jalankan alur evaluasi TFMA:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
Render Indikator Keadilan
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
Tips menggunakan Indikator Kewajaran:
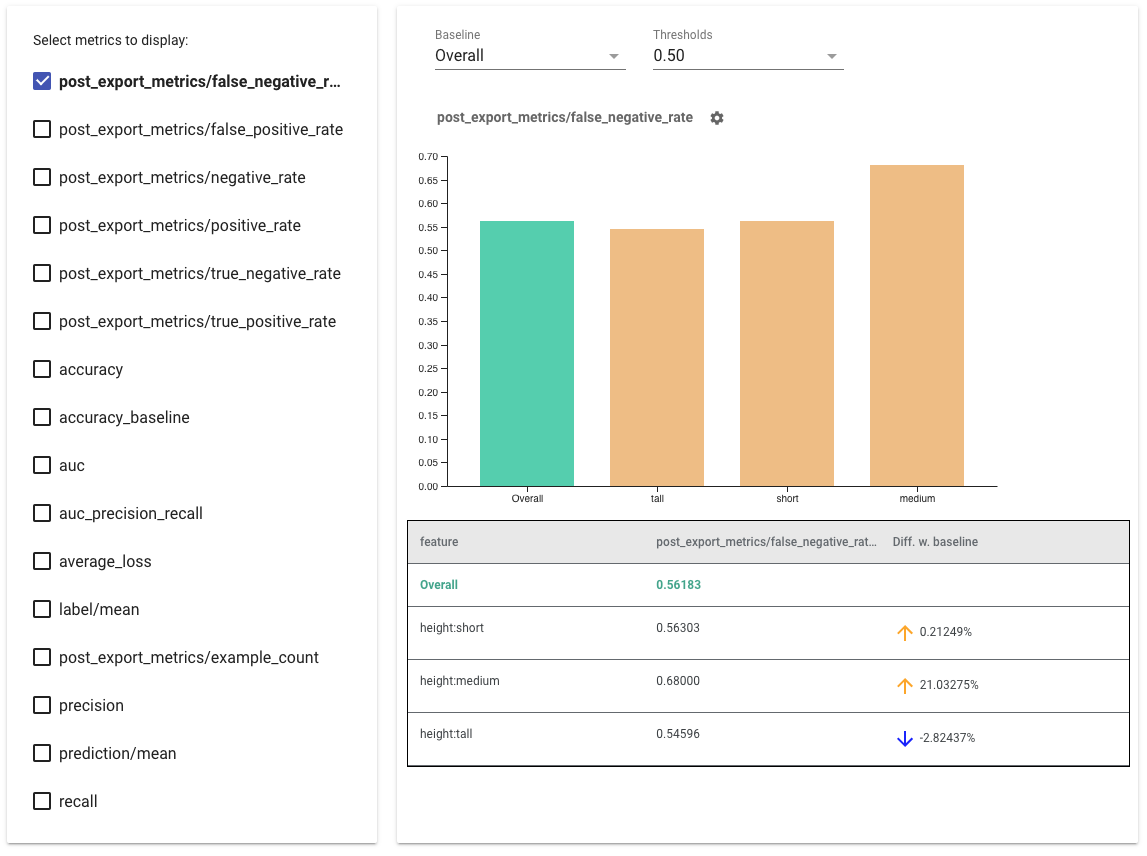
- Pilih metrik yang akan ditampilkan dengan mencentang kotak di sisi kiri. Grafik individual untuk setiap metrik akan muncul di widget secara berurutan.
- Ubah irisan garis dasar , batang pertama pada grafik, menggunakan pemilih tarik-turun. Delta akan dihitung dengan nilai dasar ini.
- Pilih ambang batas menggunakan pemilih dropdown. Anda dapat melihat beberapa ambang batas pada grafik yang sama. Ambang batas yang dipilih akan dicetak tebal, dan Anda dapat mengeklik ambang batas yang dicetak tebal untuk membatalkan pilihannya.
- Arahkan kursor ke bilah untuk melihat metrik untuk potongan tersebut.
- Identifikasi perbedaan dengan garis dasar menggunakan kolom "Diff w. baseline", yang mengidentifikasi perbedaan persentase antara potongan saat ini dan garis dasar.
- Jelajahi titik data suatu irisan secara mendalam menggunakan Alat Bagaimana-Jika . Lihat di sini sebagai contoh.
Merender Indikator Kewajaran untuk Berbagai Model
Indikator Kewajaran juga dapat digunakan untuk membandingkan model. Daripada meneruskan satu eval_result, berikan objek multi_eval_results, yang merupakan kamus yang memetakan dua nama model ke objek eval_result.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
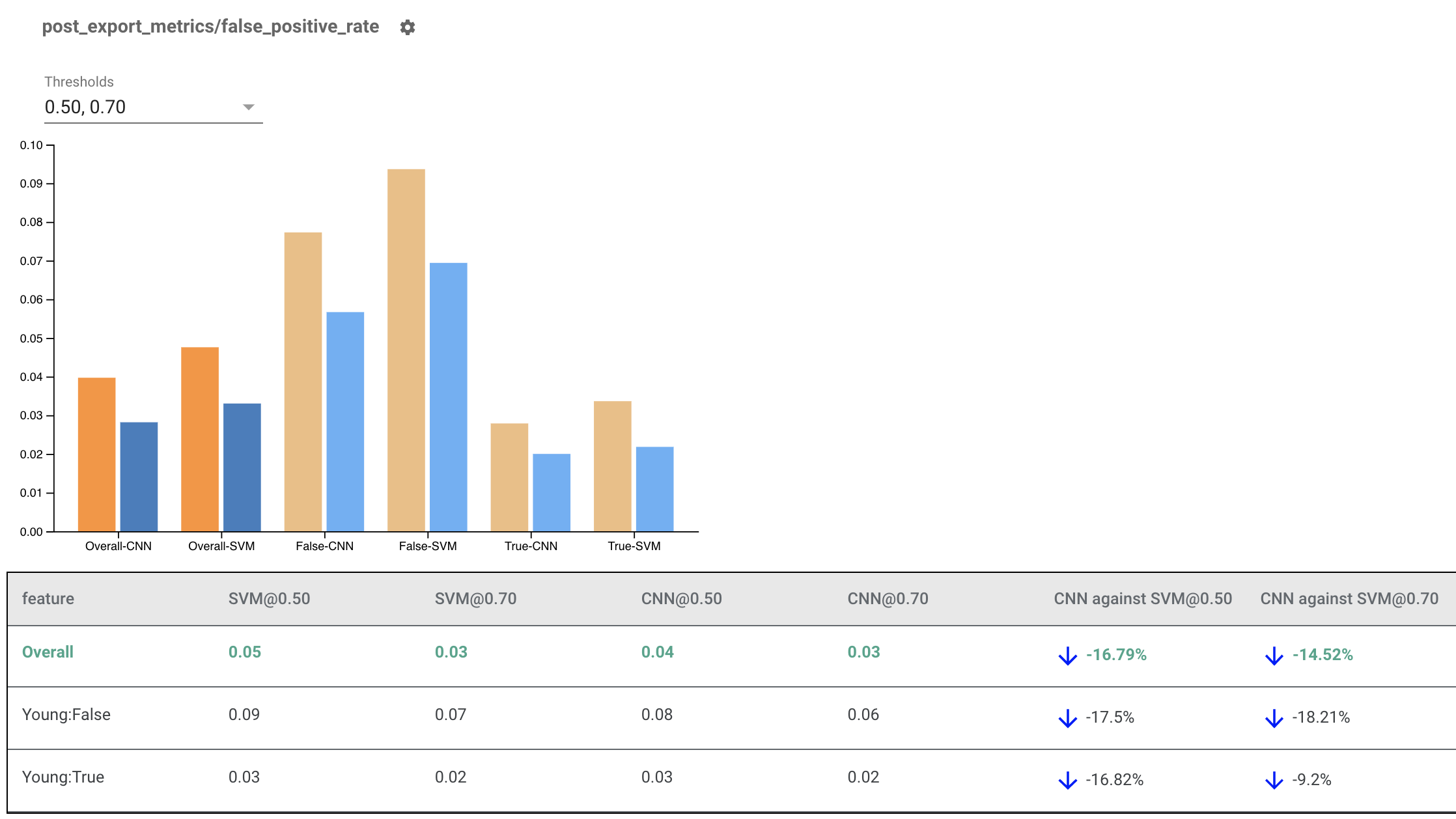
Perbandingan model dapat digunakan bersamaan dengan perbandingan ambang batas. Misalnya, Anda dapat membandingkan dua model pada dua kumpulan ambang batas untuk menemukan kombinasi optimal untuk metrik kewajaran Anda.
Menggunakan Indikator Kewajaran dengan Model non-TensorFlow
Untuk lebih mendukung klien yang memiliki model dan alur kerja berbeda, kami telah mengembangkan pustaka evaluasi yang tidak bergantung pada model yang sedang dievaluasi.
Siapa pun yang ingin mengevaluasi sistem pembelajaran mesinnya dapat menggunakan ini, terutama jika Anda memiliki model yang tidak berbasis TensorFlow. Dengan menggunakan Apache Beam Python SDK, Anda dapat membuat biner evaluasi TFMA mandiri dan kemudian menjalankannya untuk menganalisis model Anda.
Data
Langkah ini adalah untuk menyediakan kumpulan data yang Anda inginkan untuk menjalankan evaluasi. Itu harus dalam format proto tf.Example yang memiliki label, prediksi, dan fitur lain yang mungkin ingin Anda potong.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
Model
Daripada menentukan model, Anda dapat membuat konfigurasi dan ekstraktor eval agnostik model untuk mengurai dan menyediakan data yang dibutuhkan TFMA untuk menghitung metrik. Spesifikasi ModelAgnosticConfig menentukan fitur, prediksi, dan label yang akan digunakan dari contoh masukan.
Untuk melakukan ini, buat peta fitur dengan kunci yang mewakili semua fitur termasuk label dan kunci prediksi serta nilai yang mewakili tipe data fitur.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
Buat konfigurasi model agnostik menggunakan kunci label, kunci prediksi, dan peta fitur.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
Siapkan Model Agnostic Extractor
Ekstraktor digunakan untuk mengekstrak fitur, label, dan prediksi dari input menggunakan konfigurasi model agnostic. Dan jika Anda ingin mengiris data, Anda juga perlu menentukan spesifikasi kunci irisan , yang berisi informasi tentang kolom yang ingin Anda potong.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
Hitung Metrik Kewajaran
Sebagai bagian dari EvalSharedModel , Anda dapat memberikan semua metrik yang Anda inginkan untuk mengevaluasi model Anda. Metrik disediakan dalam bentuk callback metrik seperti yang ditentukan di post_export_metrics atau fairness_indicators .
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
Ini juga memerlukan construct_fn yang digunakan untuk membuat grafik tensorflow untuk melakukan evaluasi.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
Setelah semuanya siap, gunakan salah satu fungsi ExtractEvaluate atau ExtractEvaluateAndWriteResults yang disediakan oleh model_eval_lib untuk mengevaluasi model.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
Terakhir, render Indikator Kewajaran menggunakan instruksi dari bagian "Render Indikator Kewajaran" di atas.
Contoh Lainnya
Direktori contoh Indikator Kewajaran berisi beberapa contoh:
- Fairness_Indicators_Example_Colab.ipynb memberikan ringkasan Indikator Kewajaran dalam Analisis Model TensorFlow dan cara menggunakannya dengan kumpulan data nyata. Notebook ini juga membahas Validasi Data TensorFlow dan Alat Bagaimana-Jika , dua alat untuk menganalisis model TensorFlow yang dikemas dengan Indikator Kewajaran.
- Fairness_Indicators_on_TF_Hub.ipynb menunjukkan cara menggunakan Indikator Kewajaran untuk membandingkan model yang dilatih pada penyematan teks yang berbeda. Notebook ini menggunakan penyematan teks dari TensorFlow Hub , pustaka TensorFlow untuk memublikasikan, menemukan, dan menggunakan kembali komponen model.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb menunjukkan cara memvisualisasikan Indikator Kewajaran di TensorBoard.