
Индикаторы справедливости предназначены для поддержки команд в оценке и улучшении моделей обеспечения справедливости в партнерстве с более широким набором инструментов Tensorflow. В настоящее время этот инструмент активно используется во многих наших продуктах и теперь доступен в бета-версии, чтобы его можно было опробовать в своих собственных сценариях использования.
Что такое показатели справедливости?
Индикаторы справедливости — это библиотека, которая позволяет легко вычислять часто встречающиеся показатели справедливости для бинарных и многоклассовых классификаторов. Многие существующие инструменты для оценки вопросов справедливости не очень хорошо работают с крупномасштабными наборами данных и моделями. Нам в Google важно иметь инструменты, которые могут работать в системах с миллиардами пользователей. Индикаторы справедливости позволят вам оценить вариант использования любого масштаба.
В частности, Индикаторы справедливости включают в себя возможность:
- Оценить распределение наборов данных
- Оцените производительность модели по определенным группам пользователей.
- Будьте уверены в своих результатах благодаря доверительным интервалам и оценкам с несколькими пороговыми значениями.
- Погрузитесь глубже в отдельные фрагменты, чтобы изучить коренные причины и возможности для улучшения.
Загрузка пакета pip включает в себя:
- Проверка данных Tensorflow (TFDV)
- Анализ модели тензорного потока (TFMA)
- Показатели справедливости
- Инструмент «Что, если» (WIT)
Использование индикаторов справедливости с моделями Tensorflow
Данные
Чтобы запустить индикаторы справедливости с TFMA, убедитесь, что набор оценочных данных помечен для функций, по которым вы хотите разделить. Если у вас нет точных функций среза для решения ваших проблем с справедливостью, вы можете попытаться найти оценочный набор, который их поддерживает, или рассмотреть прокси-функции в вашем наборе функций, которые могут подчеркнуть различия в результатах. Дополнительные рекомендации см. здесь .
Модель
Вы можете использовать класс Tensorflow Estimator для построения своей модели. Поддержка моделей Keras скоро появится в TFMA. Если вы хотите запустить TFMA на модели Keras, см. раздел «Модельно-независимый TFMA» ниже.
После обучения вашего оценщика вам нужно будет экспортировать сохраненную модель для целей оценки. Дополнительную информацию см. в руководстве TFMA .
Настройка срезов
Затем определите срезы, которые вы хотите оценить:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
Если вы хотите оценить пересекающиеся срезы (например, цвет меха и высоту), вы можете установить следующее:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
Вычисление показателей справедливости
Добавьте обратный вызов индикаторов справедливости в список metrics_callback . В обратном вызове вы можете определить список пороговых значений, по которым будет оцениваться модель.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
Прежде чем запускать конфигурацию, определите, хотите ли вы включить вычисление доверительных интервалов. Доверительные интервалы рассчитываются с использованием метода начальной загрузки Пуассона и требуют повторного расчета для 20 выборок.
compute_confidence_intervals = True
Запустите конвейер оценки TFMA:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
Индикаторы справедливости рендеринга
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
Советы по использованию индикаторов справедливости:
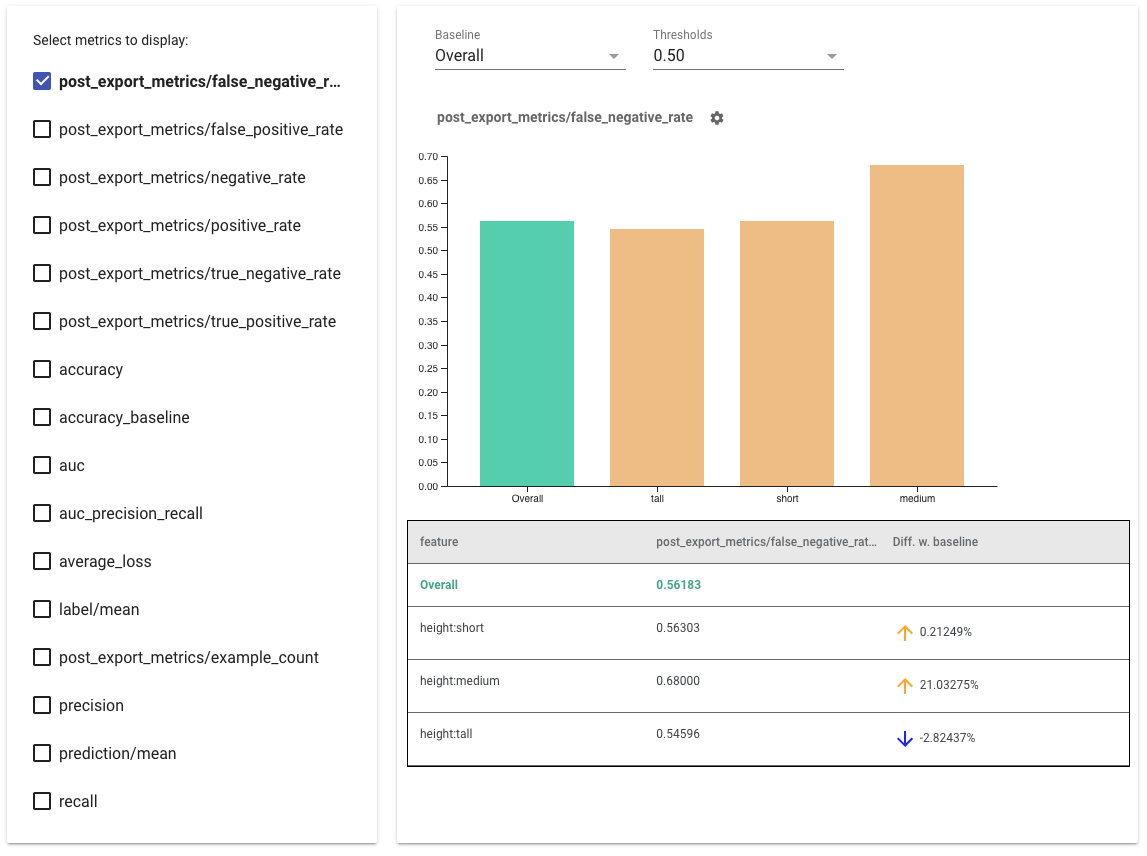
- Выберите показатели для отображения , установив флажки слева. В виджете по порядку появятся отдельные графики для каждой метрики.
- Измените базовый срез (первый столбец на графике) с помощью раскрывающегося списка. Дельты будут рассчитываться с использованием этого базового значения.
- Выберите пороговые значения, используя раскрывающийся список. Вы можете просмотреть несколько пороговых значений на одном графике. Выбранные пороговые значения будут выделены жирным шрифтом, и вы можете щелкнуть выделенный жирным шрифтом порог, чтобы отменить его выбор.
- Наведите указатель мыши на полосу , чтобы просмотреть показатели для этого фрагмента.
- Определите несоответствия с базовым уровнем, используя столбец «Разница с базовым уровнем», который определяет процентную разницу между текущим срезом и базовым уровнем.
- Подробно изучите точки данных среза с помощью инструмента «Что, если» . См. здесь пример.
Отрисовка индикаторов справедливости для нескольких моделей
Индикаторы справедливости также можно использовать для сравнения моделей. Вместо передачи одного eval_result передайте объект multi_eval_results, который представляет собой словарь, сопоставляющий два имени модели с объектами eval_result.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
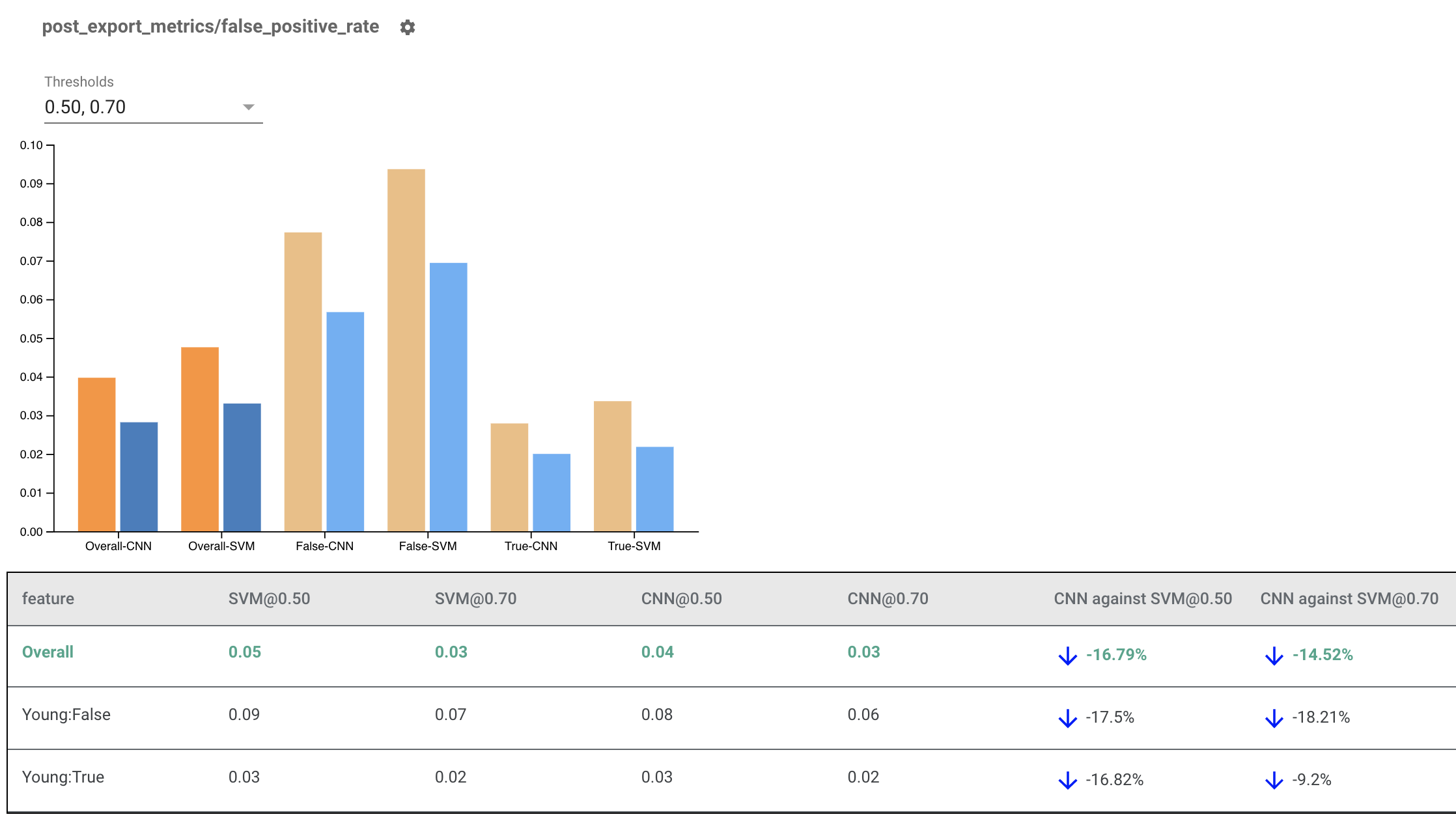
Сравнение моделей можно использовать наряду с пороговым сравнением. Например, вы можете сравнить две модели с двумя наборами пороговых значений, чтобы найти оптимальную комбинацию для ваших показателей справедливости.
Использование индикаторов справедливости с моделями, отличными от TensorFlow
Чтобы лучше поддерживать клиентов с разными моделями и рабочими процессами, мы разработали библиотеку оценки, которая не зависит от оцениваемой модели.
Любой, кто хочет оценить свою систему машинного обучения, может использовать это, особенно если у вас есть модели, не основанные на TensorFlow. Используя Apache Beam Python SDK, вы можете создать автономный двоичный файл оценки TFMA, а затем запустить его для анализа вашей модели.
Данные
На этом этапе необходимо предоставить набор данных, на котором будут проводиться оценки. Он должен быть в формате прототипа tf.Example с метками, прогнозами и другими функциями, которые вы, возможно, захотите использовать.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
Модель
Вместо указания модели вы создаете независимую от модели конфигурацию и экстрактор для анализа и предоставления данных, необходимых TFMA для вычисления показателей. Спецификация ModelAgnosticConfig определяет функции, прогнозы и метки, которые будут использоваться из входных примеров.
Для этого создайте карту объектов с ключами, представляющими все объекты, включая ключи меток и прогнозирования, а также значения, представляющие тип данных объекта.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
Создайте независимую от модели конфигурацию, используя ключи меток, ключи прогнозирования и карту объектов.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
Настройка экстрактора, не зависящего от модели
Экстрактор используется для извлечения функций, меток и прогнозов из входных данных с использованием конфигурации, не зависящей от модели. А если вы хотите разрезать свои данные, вам также необходимо определить спецификацию ключа среза , содержащую информацию о столбцах, по которым вы хотите разрезать.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
Вычисление показателей справедливости
В рамках EvalSharedModel вы можете предоставить все метрики, по которым вы хотите оценивать свою модель. Метрики предоставляются в форме обратных вызовов метрик, подобных тем, которые определены в post_export_metrics или fairness_indicators .
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
Он также принимает construct_fn , который используется для создания графа тензорного потока для выполнения оценки.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
После того, как все настроено, используйте одну из функций ExtractEvaluate или ExtractEvaluateAndWriteResults , предоставляемых model_eval_lib , для оценки модели.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
Наконец, визуализируйте индикаторы справедливости, используя инструкции из раздела «Визуализация индикаторов справедливости» выше.
Больше примеров
Каталог примеров показателей справедливости содержит несколько примеров:
- Fairness_Indicators_Example_Colab.ipynb дает обзор индикаторов справедливости в анализе модели TensorFlow и способы их использования с реальным набором данных. В этом блокноте также рассматриваются проверка данных TensorFlow и инструмент «Что, если» , два инструмента для анализа моделей TensorFlow, оснащенных индикаторами справедливости.
- Fairness_Indicators_on_TF_Hub.ipynb демонстрирует, как использовать индикаторы справедливости для сравнения моделей, обученных на различных встраиваниях текста . В этом блокноте используются встраивания текста из TensorFlow Hub , библиотеки TensorFlow, для публикации, обнаружения и повторного использования компонентов модели.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb демонстрирует, как визуализировать индикаторы справедливости в TensorBoard.