
একবার আপনার ডেটা টিএফএক্স পাইপলাইনে থাকলে, আপনি এটি বিশ্লেষণ এবং রূপান্তর করতে TFX উপাদানগুলি ব্যবহার করতে পারেন। আপনি একটি মডেল প্রশিক্ষণের আগেও আপনি এই সরঞ্জামগুলি ব্যবহার করতে পারেন।
আপনার ডেটা বিশ্লেষণ এবং রূপান্তর করার অনেক কারণ রয়েছে:
- আপনার ডেটাতে সমস্যা খুঁজে পেতে। সাধারণ সমস্যাগুলির মধ্যে রয়েছে:
- অনুপস্থিত ডেটা, যেমন খালি মান সহ বৈশিষ্ট্য।
- লেবেলগুলিকে বৈশিষ্ট্য হিসাবে বিবেচনা করা হয়, যাতে আপনার মডেল প্রশিক্ষণের সময় সঠিক উত্তরটি দেখতে পায়।
- আপনার প্রত্যাশিত পরিসরের বাইরের মান সহ বৈশিষ্ট্য।
- ডেটা অসঙ্গতি।
- ট্রান্সফার শেখা মডেলের প্রিপ্রসেসিং রয়েছে যা প্রশিক্ষণের ডেটার সাথে মেলে না।
- আরো কার্যকর বৈশিষ্ট্য সেট ইঞ্জিনিয়ার করতে. উদাহরণস্বরূপ, আপনি সনাক্ত করতে পারেন:
- বিশেষ করে তথ্যপূর্ণ বৈশিষ্ট্য.
- অপ্রয়োজনীয় বৈশিষ্ট্য।
- যে বৈশিষ্ট্যগুলি স্কেলে এত ব্যাপকভাবে পরিবর্তিত হয় যে তারা শেখার গতি কমিয়ে দিতে পারে।
- সামান্য বা কোন অনন্য ভবিষ্যদ্বাণীমূলক তথ্য সহ বৈশিষ্ট্য।
TFX টুল উভয়ই ডেটা বাগ খুঁজে পেতে সাহায্য করতে পারে, এবং বৈশিষ্ট্য প্রকৌশলে সাহায্য করতে পারে।
টেনসরফ্লো ডেটা যাচাইকরণ
ওভারভিউ
টেনসরফ্লো ডেটা যাচাইকরণ প্রশিক্ষণ এবং ডেটা পরিবেশনের ক্ষেত্রে অসামঞ্জস্যতা চিহ্নিত করে এবং ডেটা পরীক্ষা করে স্বয়ংক্রিয়ভাবে একটি স্কিমা তৈরি করতে পারে। উপাদানটি ডেটাতে বিভিন্ন শ্রেণীর অসঙ্গতি সনাক্ত করতে কনফিগার করা যেতে পারে। এটা পারে
- একটি স্কিমার সাথে ডেটা পরিসংখ্যান তুলনা করে বৈধতা পরীক্ষাগুলি সম্পাদন করুন যা ব্যবহারকারীর প্রত্যাশাগুলিকে কোডিফাই করে৷
- প্রশিক্ষণ এবং পরিবেশন ডেটার উদাহরণ তুলনা করে প্রশিক্ষণ-সার্ভিং স্কু সনাক্ত করুন।
- ডেটার একটি সিরিজ দেখে ডেটা ড্রিফ্ট সনাক্ত করুন।
আমরা এই কার্যকারিতাগুলির প্রতিটি স্বাধীনভাবে নথিভুক্ত করি:
স্কিমা ভিত্তিক উদাহরণ যাচাইকরণ
টেনসরফ্লো ডেটা যাচাইকরণ একটি স্কিমার সাথে ডেটা পরিসংখ্যান তুলনা করে ইনপুট ডেটাতে যে কোনও অসঙ্গতি সনাক্ত করে। স্কিমা বৈশিষ্ট্যগুলিকে কোডিফাই করে যা ইনপুট ডেটা সন্তুষ্ট করবে বলে আশা করা হয়, যেমন ডেটা প্রকার বা শ্রেণীগত মান, এবং ব্যবহারকারী দ্বারা পরিবর্তন বা প্রতিস্থাপন করা যেতে পারে।
TFX পাইপলাইনের প্রেক্ষাপটে Tensorflow ডেটা বৈধতা সাধারণত একাধিকবার আহ্বান করা হয়: (i) ExampleGen থেকে প্রাপ্ত প্রতিটি বিভাজনের জন্য, (ii) ট্রান্সফর্ম দ্বারা ব্যবহৃত সমস্ত প্রাক-রূপান্তরিত ডেটার জন্য এবং (iii) উৎপন্ন সমস্ত পোস্ট-ট্রান্সফর্ম ডেটার জন্য রূপান্তর। ট্রান্সফর্ম (ii-iii) এর প্রসঙ্গে বলা হলে, পরিসংখ্যান বিকল্প এবং স্কিমা-ভিত্তিক সীমাবদ্ধতা stats_options_updater_fn সংজ্ঞায়িত করে সেট করা যেতে পারে। অসংগঠিত ডেটা (যেমন পাঠ্য বৈশিষ্ট্য) যাচাই করার সময় এটি বিশেষভাবে কার্যকর। একটি উদাহরণের জন্য ব্যবহারকারী কোড দেখুন.
উন্নত স্কিমা বৈশিষ্ট্য
এই বিভাগে আরও উন্নত স্কিমা কনফিগারেশন রয়েছে যা বিশেষ সেটআপে সাহায্য করতে পারে।
স্পারস বৈশিষ্ট্য
উদাহরণগুলিতে স্পার্স বৈশিষ্ট্যগুলি এনকোডিং সাধারণত একাধিক বৈশিষ্ট্য প্রবর্তন করে যা সমস্ত উদাহরণের জন্য একই ভ্যালেন্সি থাকবে বলে আশা করা হয়। উদাহরণস্বরূপ স্পার্স বৈশিষ্ট্য:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
স্পারস বৈশিষ্ট্যের সংজ্ঞার জন্য এক বা একাধিক সূচক এবং একটি মান বৈশিষ্ট্য প্রয়োজন যা স্কিমাতে বিদ্যমান বৈশিষ্ট্যগুলিকে উল্লেখ করে। স্পষ্টভাবে বিক্ষিপ্ত বৈশিষ্ট্যগুলি সংজ্ঞায়িত করা TFDV কে সমস্ত উল্লেখিত বৈশিষ্ট্যগুলির ভ্যালেন্সিগুলি মেলে কিনা তা পরীক্ষা করতে সক্ষম করে৷
কিছু ব্যবহারের ক্ষেত্রে বৈশিষ্ট্যগুলির মধ্যে অনুরূপ ভ্যালেন্সি সীমাবদ্ধতা প্রবর্তন করা হয়, কিন্তু অগত্যা একটি বিক্ষিপ্ত বৈশিষ্ট্য এনকোড করে না। স্পার্স বৈশিষ্ট্য ব্যবহার করা আপনাকে অবরোধ মুক্ত করা উচিত, কিন্তু আদর্শ নয়।
স্কিমা পরিবেশ
ডিফল্টভাবে বৈধকরণ অনুমান করে যে একটি পাইপলাইনের সমস্ত উদাহরণ একটি একক স্কিমা মেনে চলে। কিছু ক্ষেত্রে সামান্য স্কিমা বৈচিত্র প্রবর্তন করা প্রয়োজন, উদাহরণস্বরূপ লেবেল হিসাবে ব্যবহৃত বৈশিষ্ট্যগুলি প্রশিক্ষণের সময় প্রয়োজন (এবং যাচাই করা উচিত), কিন্তু পরিবেশন করার সময় অনুপস্থিত। পরিবেশ এই ধরনের প্রয়োজনীয়তা প্রকাশ করতে ব্যবহার করা যেতে পারে, বিশেষ করে default_environment() , in_environment() , not_in_environment() ।
উদাহরণস্বরূপ, অনুমান করুন 'LABEL' নামের একটি বৈশিষ্ট্য প্রশিক্ষণের জন্য প্রয়োজন, কিন্তু পরিবেশন করা থেকে অনুপস্থিত হবে বলে আশা করা হচ্ছে। এটি দ্বারা প্রকাশ করা যেতে পারে:
- স্কিমাতে দুটি স্বতন্ত্র পরিবেশ সংজ্ঞায়িত করুন: ["পরিষেবা", "প্রশিক্ষণ"] এবং 'লেবেল' শুধুমাত্র "প্রশিক্ষণ" পরিবেশের সাথে সংযুক্ত করুন।
- পরিবেশ "ট্রেনিং" এর সাথে প্রশিক্ষণের ডেটা এবং পরিবেশ "পরিষেবা" এর সাথে পরিবেশন ডেটা সংযুক্ত করুন।
স্কিমা জেনারেশন
ইনপুট ডেটা স্কিমা টেনসরফ্লো স্কিমার উদাহরণ হিসাবে নির্দিষ্ট করা হয়েছে।
স্ক্র্যাচ থেকে ম্যানুয়ালি একটি স্কিমা তৈরি করার পরিবর্তে, একজন বিকাশকারী টেনসরফ্লো ডেটা যাচাইকরণের স্বয়ংক্রিয় স্কিমা নির্মাণের উপর নির্ভর করতে পারেন। বিশেষত, টেনসরফ্লো ডেটা যাচাইকরণ পাইপলাইনে উপলব্ধ প্রশিক্ষণ ডেটার উপর গণনা করা পরিসংখ্যানের উপর ভিত্তি করে স্বয়ংক্রিয়ভাবে একটি প্রাথমিক স্কিমা তৈরি করে। ব্যবহারকারীরা সহজভাবে এই স্বয়ংক্রিয় তৈরি স্কিমা পর্যালোচনা করতে পারে, প্রয়োজন অনুসারে এটিকে সংশোধন করতে পারে, এটিকে একটি সংস্করণ নিয়ন্ত্রণ সিস্টেমে পরীক্ষা করতে পারে এবং আরও বৈধতার জন্য এটিকে স্পষ্টভাবে পাইপলাইনে ঠেলে দিতে পারে।
TFDV স্বয়ংক্রিয়ভাবে একটি স্কিমা তৈরি করতে infer_schema() অন্তর্ভুক্ত করে। যেমন:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
এটি নিম্নলিখিত নিয়মগুলির উপর ভিত্তি করে একটি স্বয়ংক্রিয় স্কিমা প্রজন্মকে ট্রিগার করে:
যদি একটি স্কিমা ইতিমধ্যেই স্বয়ংক্রিয়ভাবে তৈরি হয়ে থাকে তবে এটি ব্যবহার করা হয়।
অন্যথায়, TensorFlow ডেটা বৈধকরণ উপলব্ধ ডেটা পরিসংখ্যান পরীক্ষা করে এবং ডেটার জন্য একটি উপযুক্ত স্কিমা গণনা করে।
দ্রষ্টব্য: স্বয়ংক্রিয়-উত্পন্ন স্কিমা সর্বোত্তম প্রচেষ্টা এবং শুধুমাত্র ডেটার মৌলিক বৈশিষ্ট্যগুলি অনুমান করার চেষ্টা করে৷ এটি প্রত্যাশিত যে ব্যবহারকারীরা প্রয়োজন অনুসারে এটি পর্যালোচনা এবং সংশোধন করবে৷
ট্রেনিং-সার্ভিং স্কু ডিটেকশন
ওভারভিউ
TensorFlow ডেটা যাচাইকরণ প্রশিক্ষণ এবং পরিবেশন ডেটার মধ্যে বিতরণ তির্যক সনাক্ত করতে পারে। ডিস্ট্রিবিউশন স্ক্যু ঘটে যখন প্রশিক্ষণ ডেটার জন্য বৈশিষ্ট্যের মানগুলির বিতরণ ডেটা পরিবেশন করা থেকে উল্লেখযোগ্যভাবে আলাদা। ডিস্ট্রিবিউশন স্কুয়ের মূল কারণগুলির মধ্যে একটি হল কাঙ্ক্ষিত কর্পাসে প্রাথমিক ডেটার অভাব কাটিয়ে উঠতে প্রশিক্ষণ ডেটা তৈরির জন্য সম্পূর্ণ আলাদা কর্পাস ব্যবহার করা। আরেকটি কারণ হল একটি ত্রুটিপূর্ণ স্যাম্পলিং মেকানিজম যা প্রশিক্ষণের জন্য শুধুমাত্র পরিবেশন করা ডেটার একটি সাবস্যাম্পল বেছে নেয়।
উদাহরণ দৃশ্যকল্প
ট্রেনিং-সার্ভিং স্কু ডিটেকশন কনফিগার করার বিষয়ে তথ্যের জন্য টেনসরফ্লো ডেটা ভ্যালিডেশন শুরু করুন গাইড দেখুন।
ড্রিফ্ট সনাক্তকরণ
ড্রিফ্ট সনাক্তকরণ ডেটার পরপর স্প্যানের মধ্যে (যেমন, স্প্যান N এবং স্প্যান N+1 এর মধ্যে), যেমন প্রশিক্ষণের বিভিন্ন দিনের ডেটার মধ্যে সমর্থিত। আমরা শ্রেণীবদ্ধ বৈশিষ্ট্যগুলির জন্য L-ইনফিনিটি দূরত্বের পরিপ্রেক্ষিতে প্রবাহ প্রকাশ করি এবং সংখ্যাসূচক বৈশিষ্ট্যগুলির জন্য আনুমানিক জেনসেন-শ্যানন বিচ্যুতি প্রকাশ করি। আপনি থ্রেশহোল্ডের দূরত্ব সেট করতে পারেন যাতে ড্রিফট গ্রহণযোগ্য থেকে বেশি হলে আপনি সতর্কতা পান। সঠিক দূরত্ব সেট করা সাধারণত একটি পুনরাবৃত্তিমূলক প্রক্রিয়া যার জন্য ডোমেন জ্ঞান এবং পরীক্ষা-নিরীক্ষার প্রয়োজন হয়।
ড্রিফ্ট সনাক্তকরণ কনফিগার করার বিষয়ে তথ্যের জন্য TensorFlow ডেটা যাচাইকরণ শুরু করুন নির্দেশিকা দেখুন।
আপনার ডেটা চেক করতে ভিজ্যুয়ালাইজেশন ব্যবহার করা
টেনসরফ্লো ডেটা ভ্যালিডেশন বৈশিষ্ট্যের মানগুলির বন্টন কল্পনা করার জন্য সরঞ্জাম সরবরাহ করে। Facets ব্যবহার করে জুপিটার নোটবুকে এই বিতরণগুলি পরীক্ষা করে আপনি ডেটার সাথে সাধারণ সমস্যাগুলি ধরতে পারেন।
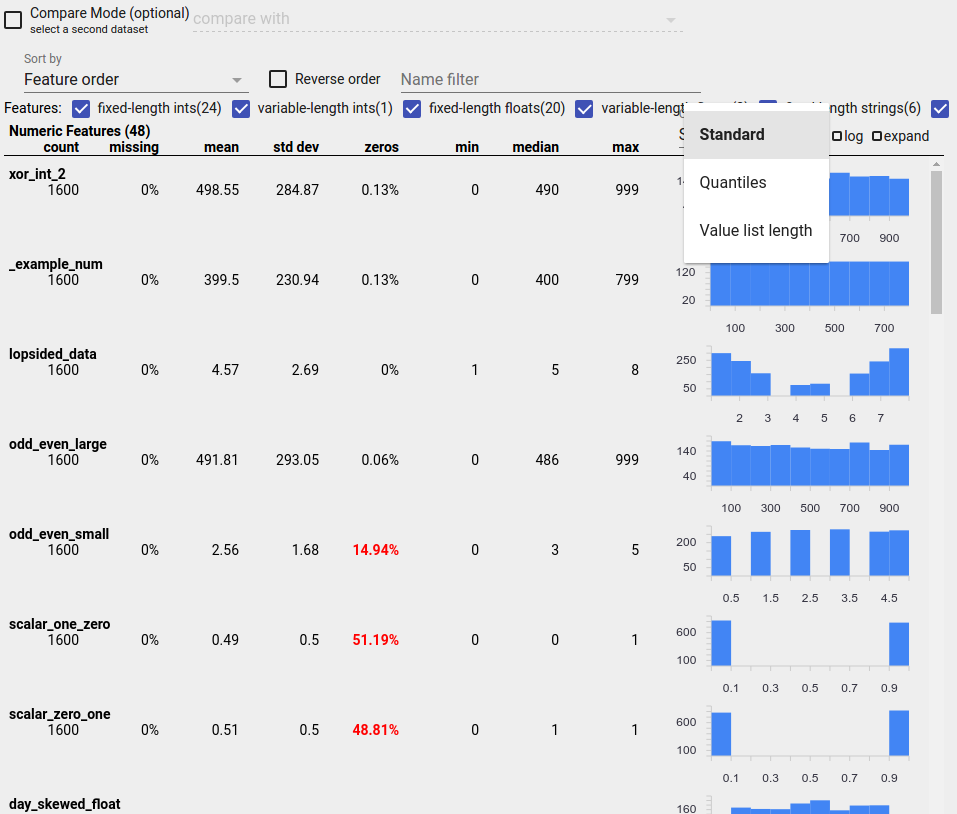
সন্দেহজনক বিতরণ সনাক্তকরণ
আপনি বৈশিষ্ট্য মানগুলির সন্দেহজনক বিতরণের জন্য একটি ফ্যাসেট ওভারভিউ প্রদর্শন ব্যবহার করে আপনার ডেটাতে সাধারণ বাগগুলি সনাক্ত করতে পারেন৷
ভারসাম্যহীন ডেটা
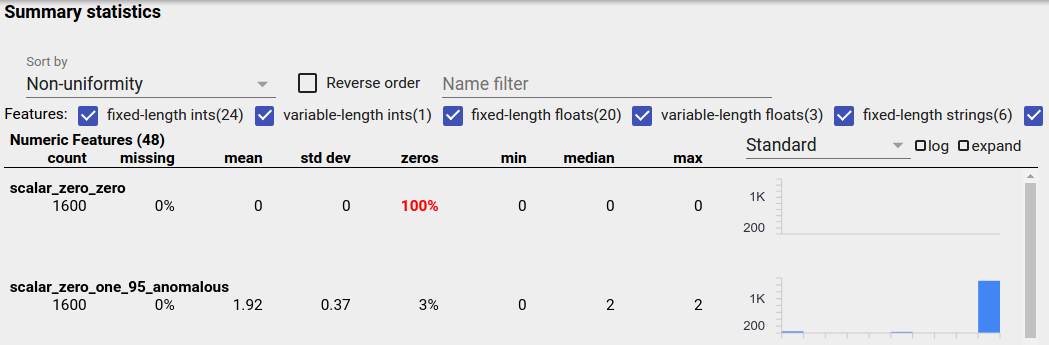
একটি ভারসাম্যহীন বৈশিষ্ট্য হল একটি বৈশিষ্ট্য যার জন্য একটি মান প্রাধান্য পায়। ভারসাম্যহীন বৈশিষ্ট্যগুলি স্বাভাবিকভাবেই ঘটতে পারে, তবে যদি একটি বৈশিষ্ট্য সবসময় একই মান থাকে তবে আপনার ডেটা বাগ থাকতে পারে। একটি ফ্যাসেট ওভারভিউতে ভারসাম্যহীন বৈশিষ্ট্য সনাক্ত করতে, "বাছাই করে" ড্রপডাউন থেকে "অ-অভিন্নতা" নির্বাচন করুন।
সর্বাধিক ভারসাম্যহীন বৈশিষ্ট্যগুলি প্রতিটি বৈশিষ্ট্য-প্রকার তালিকার শীর্ষে তালিকাভুক্ত করা হবে৷ উদাহরণস্বরূপ, নিম্নলিখিত স্ক্রিনশটটি "সাংখ্যিক বৈশিষ্ট্য" তালিকার শীর্ষে একটি বৈশিষ্ট্য দেখায় যা সমস্ত শূন্য এবং একটি দ্বিতীয় যা অত্যন্ত ভারসাম্যহীন:
অভিন্নভাবে বিতরণ করা ডেটা
একটি অভিন্নভাবে বিতরণ করা বৈশিষ্ট্য এমন একটি যার জন্য সমস্ত সম্ভাব্য মান একই ফ্রিকোয়েন্সির কাছাকাছি উপস্থিত হয়। ভারসাম্যহীন ডেটার মতো, এই বিতরণ স্বাভাবিকভাবেই ঘটতে পারে, তবে ডেটা বাগ দ্বারাও উত্পাদিত হতে পারে।
একটি ফ্যাসেট ওভারভিউতে অভিন্নভাবে বিতরণ করা বৈশিষ্ট্যগুলি সনাক্ত করতে, "সর্ট বাই" ড্রপডাউন থেকে "অভিন্নতা" চয়ন করুন এবং "বিপরীত ক্রম" চেকবক্সটি চেক করুন:
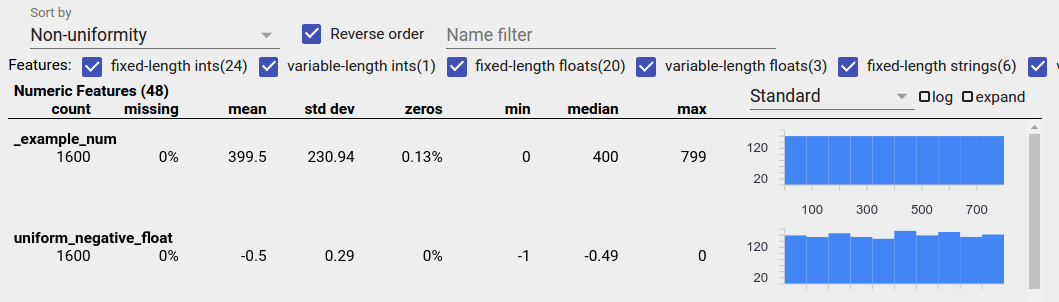
20 বা তার কম অনন্য মান থাকলে বার চার্ট ব্যবহার করে স্ট্রিং ডেটা উপস্থাপন করা হয় এবং 20টির বেশি অনন্য মান থাকলে একটি ক্রমবর্ধমান বিতরণ গ্রাফ হিসাবে। সুতরাং স্ট্রিং ডেটার জন্য, ইউনিফর্ম ডিস্ট্রিবিউশনগুলি উপরের একটির মতো ফ্ল্যাট বার গ্রাফ হিসাবে বা নীচের মতো সরল রেখা হিসাবে উপস্থিত হতে পারে:

বাগগুলি যা অভিন্নভাবে বিতরণ করা ডেটা তৈরি করতে পারে
এখানে কিছু সাধারণ বাগ রয়েছে যা একইভাবে বিতরণ করা ডেটা তৈরি করতে পারে:
তারিখের মতো নন-স্ট্রিং ডেটা টাইপগুলিকে উপস্থাপন করতে স্ট্রিং ব্যবহার করা। উদাহরণস্বরূপ, আপনার কাছে "2017-03-01-11-45-03" এর মতো উপস্থাপনা সহ একটি তারিখের বৈশিষ্ট্যের জন্য অনেকগুলি অনন্য মান থাকবে৷ অনন্য মান সমানভাবে বিতরণ করা হবে.
বৈশিষ্ট্য হিসাবে "সারি নম্বর" এর মতো সূচকগুলি সহ। এখানে আবার আপনি অনেক অনন্য মান আছে.
অনুপস্থিত ডেটা
একটি বৈশিষ্ট্য সম্পূর্ণরূপে মান অনুপস্থিত কিনা তা পরীক্ষা করতে:
- "বাছাই করে" ড্রপ-ডাউন থেকে "অ্যামাউন্ট মিসিং/শূন্য" বেছে নিন।
- "বিপরীত আদেশ" চেকবক্স চেক করুন।
- একটি বৈশিষ্ট্যের জন্য অনুপস্থিত মান সহ দৃষ্টান্তের শতাংশ দেখতে "অনুপস্থিত" কলামটি দেখুন।
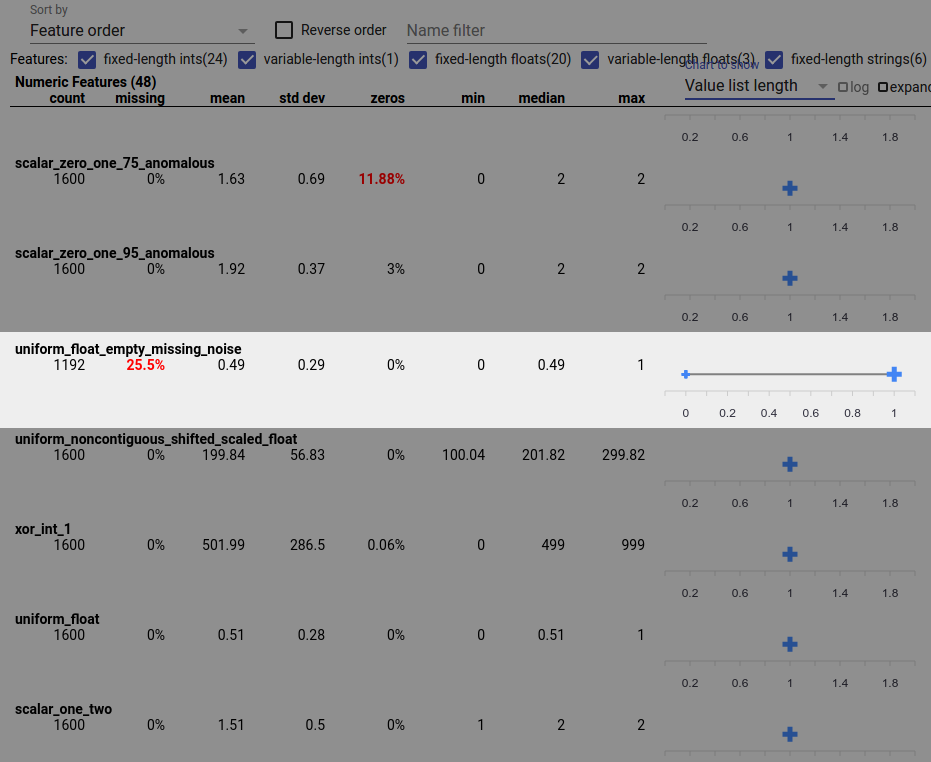
একটি ডেটা বাগ অসম্পূর্ণ বৈশিষ্ট্য মান হতে পারে। উদাহরণস্বরূপ আপনি আশা করতে পারেন যে একটি বৈশিষ্ট্যের মান তালিকায় সর্বদা তিনটি উপাদান থাকবে এবং আবিষ্কার করুন যে কখনও কখনও এটিতে শুধুমাত্র একটি থাকে। অসম্পূর্ণ মান বা অন্যান্য ক্ষেত্রে পরীক্ষা করতে যেখানে বৈশিষ্ট্য মান তালিকায় প্রত্যাশিত সংখ্যক উপাদান নেই:
ডানদিকে ড্রপ-ডাউন মেনু থেকে "দেখাতে চার্ট" থেকে "মান তালিকার দৈর্ঘ্য" বেছে নিন।
প্রতিটি বৈশিষ্ট্য সারির ডানদিকে চার্টটি দেখুন। চার্টটি বৈশিষ্ট্যটির জন্য মান তালিকার দৈর্ঘ্যের পরিসর দেখায়। উদাহরণস্বরূপ, নীচের স্ক্রিনশটে হাইলাইট করা সারিটি এমন একটি বৈশিষ্ট্য দেখায় যাতে কিছু শূন্য-দৈর্ঘ্যের মান তালিকা রয়েছে:
বৈশিষ্ট্যের মধ্যে স্কেলে বড় পার্থক্য
যদি আপনার বৈশিষ্ট্যগুলি স্কেলে ব্যাপকভাবে পরিবর্তিত হয়, তাহলে মডেলটির শিখতে অসুবিধা হতে পারে। উদাহরণস্বরূপ, যদি কিছু বৈশিষ্ট্য 0 থেকে 1 এর মধ্যে পরিবর্তিত হয় এবং অন্যগুলি 0 থেকে 1,000,000,000 এর মধ্যে পরিবর্তিত হয়, তবে আপনার স্কেলে একটি বড় পার্থক্য রয়েছে। ব্যাপকভাবে পরিবর্তিত স্কেল খুঁজতে বৈশিষ্ট্য জুড়ে "সর্বোচ্চ" এবং "মিনিট" কলাম তুলনা করুন।
এই বিস্তৃত বৈচিত্র কমাতে বৈশিষ্ট্য মান স্বাভাবিক করার বিবেচনা করুন।
অবৈধ লেবেল সহ লেবেল৷
TensorFlow এর অনুমানকারীরা লেবেল হিসাবে তারা যে ধরণের ডেটা গ্রহণ করে তার উপর সীমাবদ্ধতা রয়েছে। উদাহরণস্বরূপ, বাইনারি ক্লাসিফায়ারগুলি সাধারণত শুধুমাত্র {0, 1} লেবেলের সাথে কাজ করে।
ফ্যাসেট ওভারভিউ-এ লেবেল মানগুলি পর্যালোচনা করুন এবং নিশ্চিত করুন যে তারা অনুমানকারীদের প্রয়োজনীয়তার সাথে সঙ্গতিপূর্ণ।