
מָבוֹא
TFX היא פלטפורמת למידת מכונה בקנה מידה ייצור של גוגל (ML) המבוססת על TensorFlow. הוא מספק מסגרת תצורה וספריות משותפות לשילוב רכיבים נפוצים הדרושים להגדרה, הפעלה וניטור של מערכת למידת המכונה שלך.
TFX 1.0
אנו שמחים להכריז על זמינות ה- TFX 1.0.0 . זוהי המהדורה הראשונית לאחר בטא של TFX, המספקת ממשקי API וחפצים ציבוריים יציבים. אתה יכול להיות סמוך ובטוח שצינורות ה-TFX העתידיים שלך ימשיכו לעבוד לאחר שדרוג בטווח התאימות המוגדר ב- RFC זה.
הַתקָנָה

![]()
pip install tfx
חבילות לילה
TFX מארח גם חבילות לילה בכתובת https://pypi-nightly.tensorflow.org ב-Google Cloud. כדי להתקין את החבילה הלילית האחרונה, השתמש בפקודה הבאה:
pip install --extra-index-url https://pypi-nightly.tensorflow.org/simple --pre tfx
זה יתקין את החבילות הליליות עבור התלות העיקרית של TFX כגון TensorFlow Model Analysis (TFMA), TensorFlow Data Validation (TFDV), TensorFlow Transform (TFT), TFX Basic Shared Libraries (TFX-BSL), ML Metadata (MLMD).
לגבי TFX
TFX היא פלטפורמה לבנייה וניהול של זרימות עבודה של ML בסביבת ייצור. TFX מספק את הדברים הבאים:
ערכת כלים לבניית צינורות ML. צינורות TFX מאפשרים לך לתזמן את זרימת העבודה שלך ב-ML במספר פלטפורמות, כגון: Apache Airflow, Apache Beam ו-Kubeflow Pipelines.
קבוצה של רכיבים סטנדרטיים שאתה יכול להשתמש בהם כחלק מצינור, או כחלק מתסריט ההדרכה שלך ב-ML. רכיבי תקן TFX מספקים פונקציונליות מוכחת כדי לעזור לך להתחיל לבנות תהליך ML בקלות.
ספריות המספקות את הפונקציונליות הבסיסית עבור רבים מהרכיבים הסטנדרטיים. אתה יכול להשתמש בספריות TFX כדי להוסיף פונקציונליות זו לרכיבים המותאמים אישית שלך, או להשתמש בהם בנפרד.
TFX הוא ערכת כלים ללימוד מכונה בקנה מידה של Google המבוסס על TensorFlow. הוא מספק מסגרת תצורה וספריות משותפות לשילוב רכיבים נפוצים הדרושים להגדרה, הפעלה וניטור של מערכת למידת המכונה שלך.
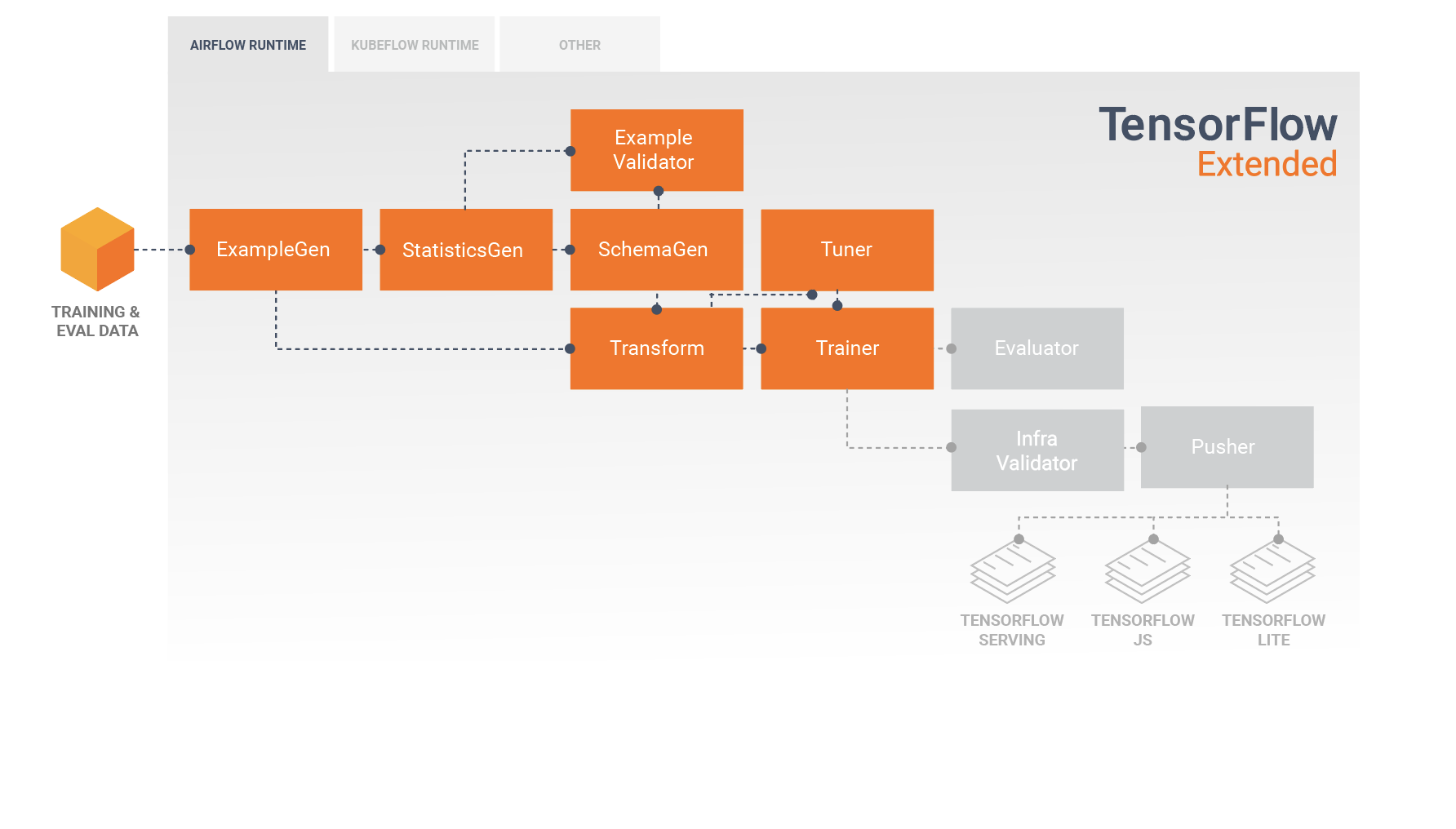
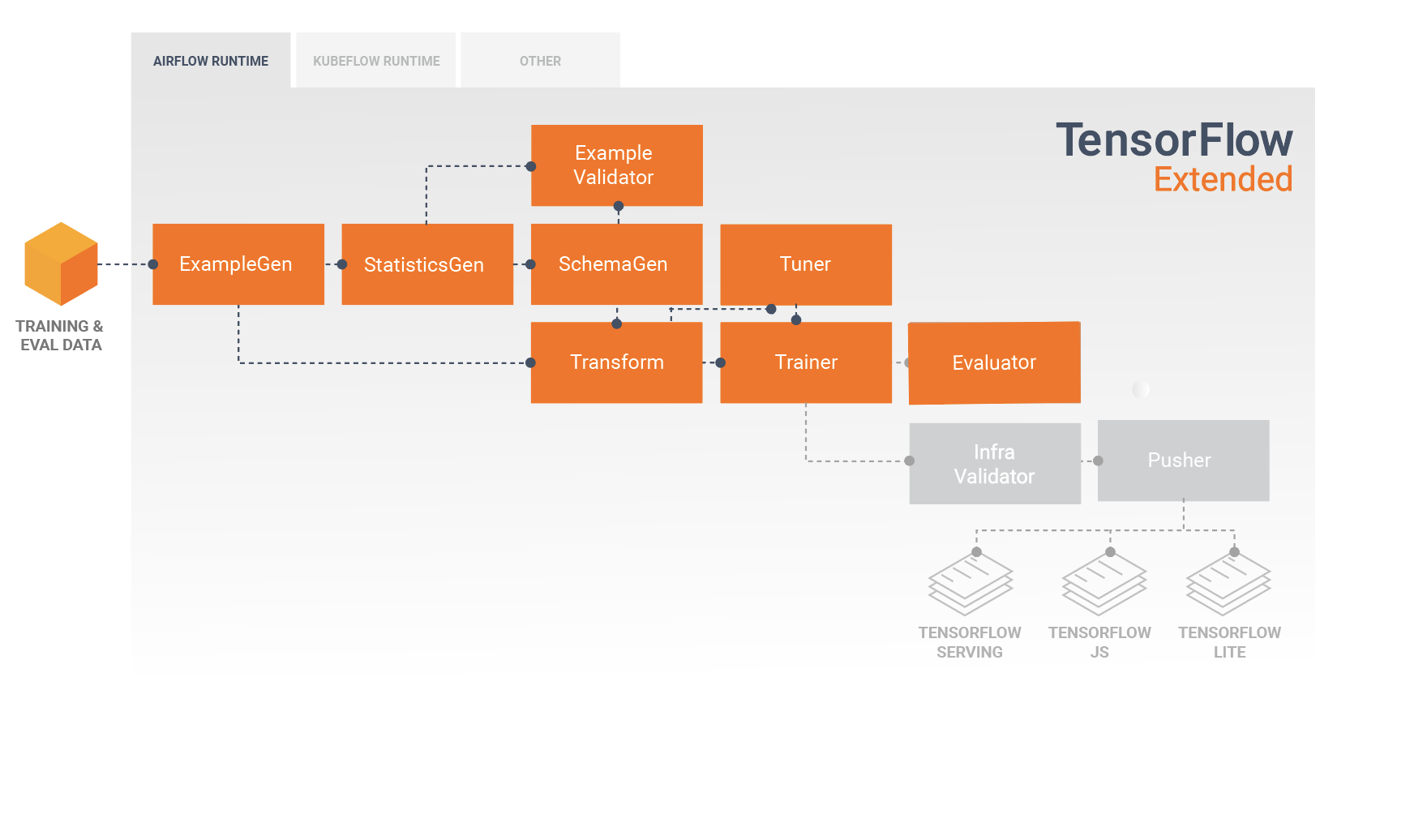
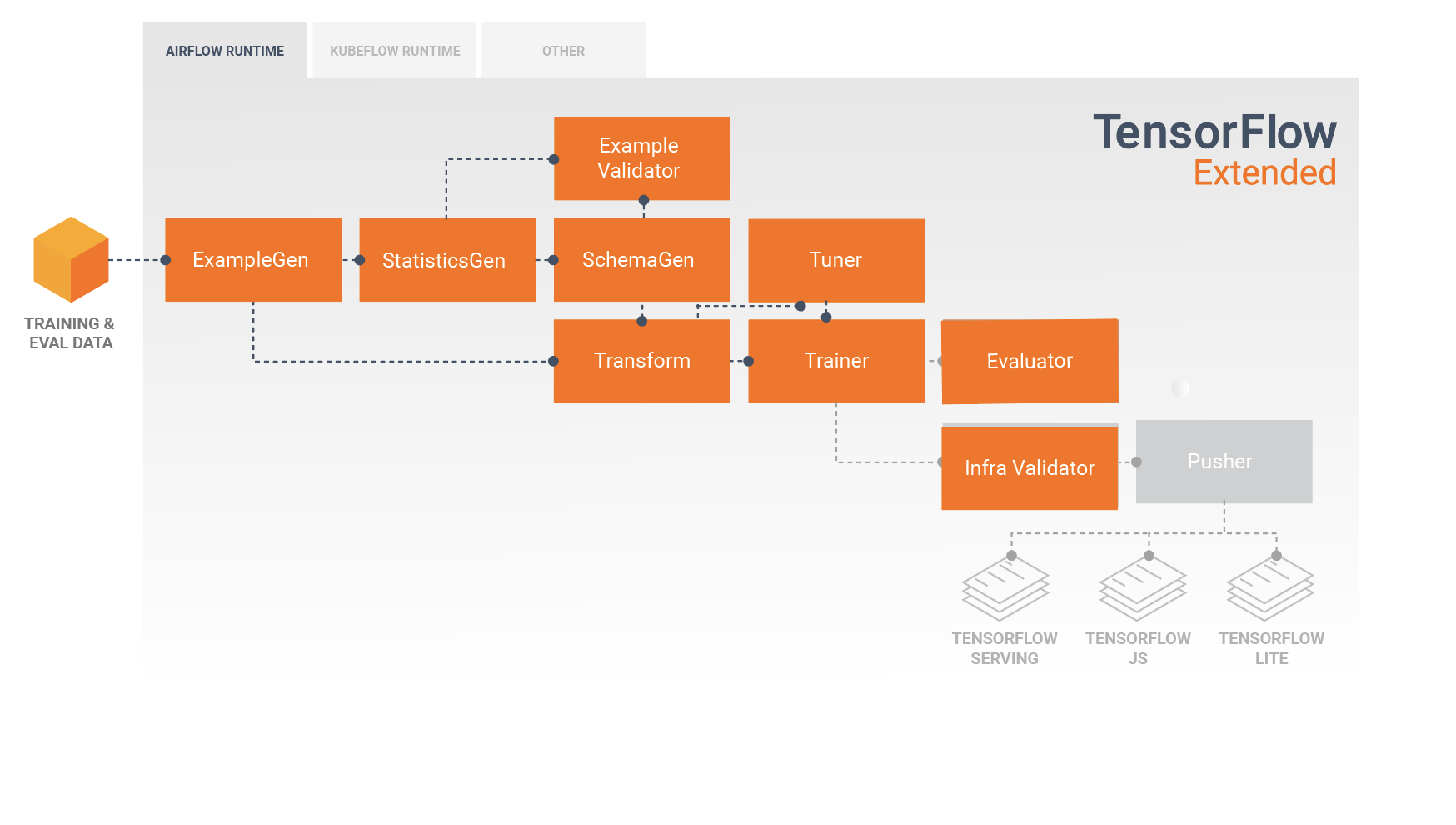
רכיבי TFX סטנדרטיים
צינור TFX הוא רצף של רכיבים המיישמים צינור ML אשר תוכנן במיוחד עבור משימות למידת מכונה ניתנות להרחבה ובעלות ביצועים גבוהים. זה כולל מודלים, הדרכה, הגשת מסקנות וניהול פריסות למטרות מקוונות, מובייל מקוריות ו-JavaScript.
צינור TFX כולל בדרך כלל את הרכיבים הבאים:
ExampleGen הוא רכיב הקלט הראשוני של צינור הקולט ומפצל את מערך הנתונים של הקלט.
StatisticsGen מחשב נתונים סטטיסטיים עבור מערך הנתונים.
SchemaGen בוחן את הסטטיסטיקה ויוצר סכימת נתונים.
ExampleValidator מחפש חריגות וערכים חסרים במערך הנתונים.
Transform מבצעת הנדסת תכונות במערך הנתונים.
מאמן מאמן את הדוגמנית.
טיונר מכוון את הפרמטרים ההיפר-פרמטרים של הדגם.
Evaluator מבצע ניתוח מעמיק של תוצאות ההדרכה ומסייע לך לאמת את המודלים המיוצאים שלך, ומבטיח שהם "טובים מספיק" כדי להידחף לייצור.
InfraValidator בודק שהמודל אכן ניתן להגשה מהתשתית ומונע דחיפה של מודל גרוע.
Pusher פורס את המודל על תשתית שירות.
BulkInferrer מבצע עיבוד אצווה על מודל עם בקשות הסקה ללא תווית.
תרשים זה ממחיש את זרימת הנתונים בין הרכיבים הללו:
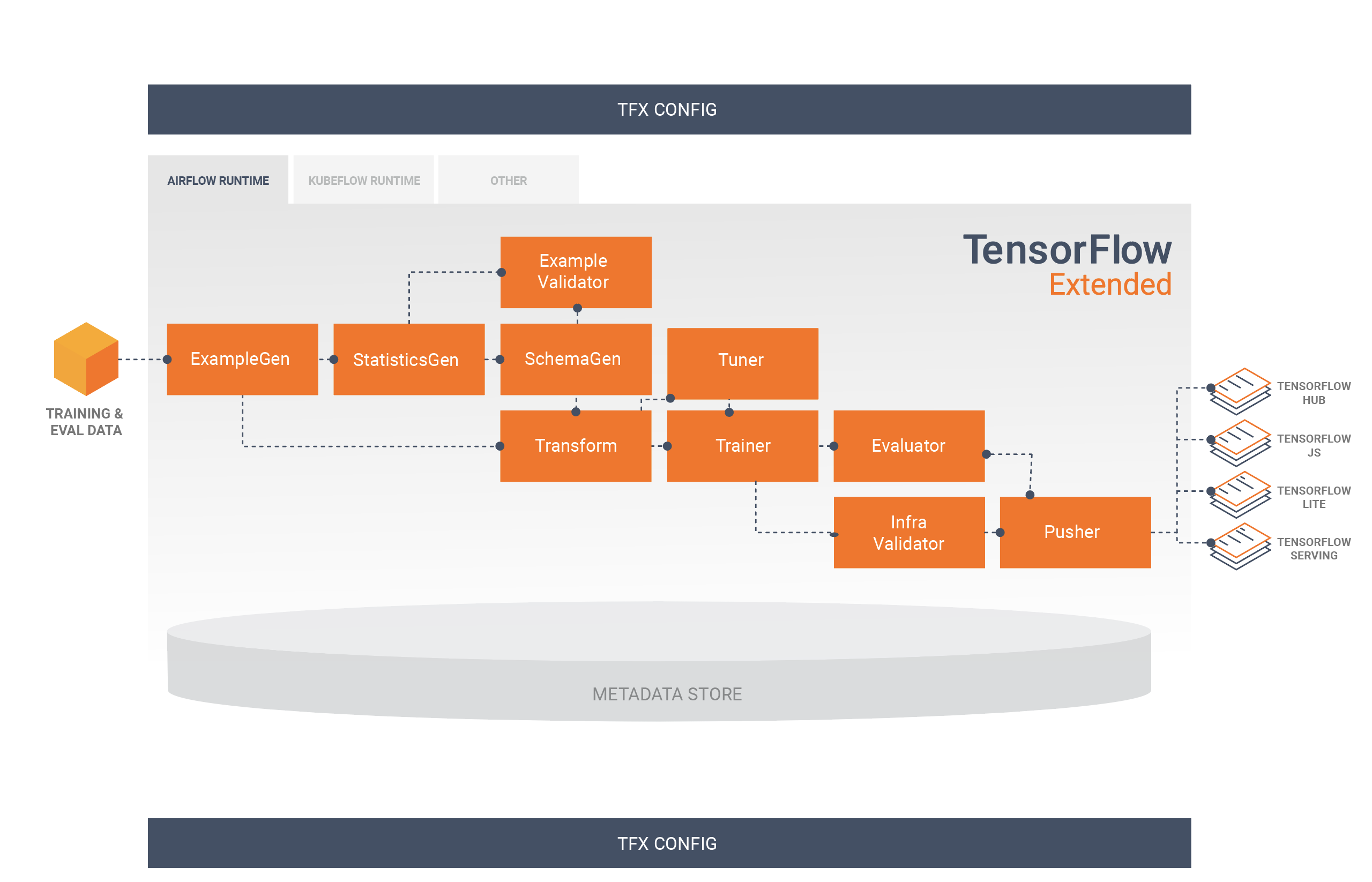
ספריות TFX
TFX כולל גם ספריות וגם רכיבי צינור. תרשים זה ממחיש את הקשרים בין ספריות TFX ורכיבי צינור:
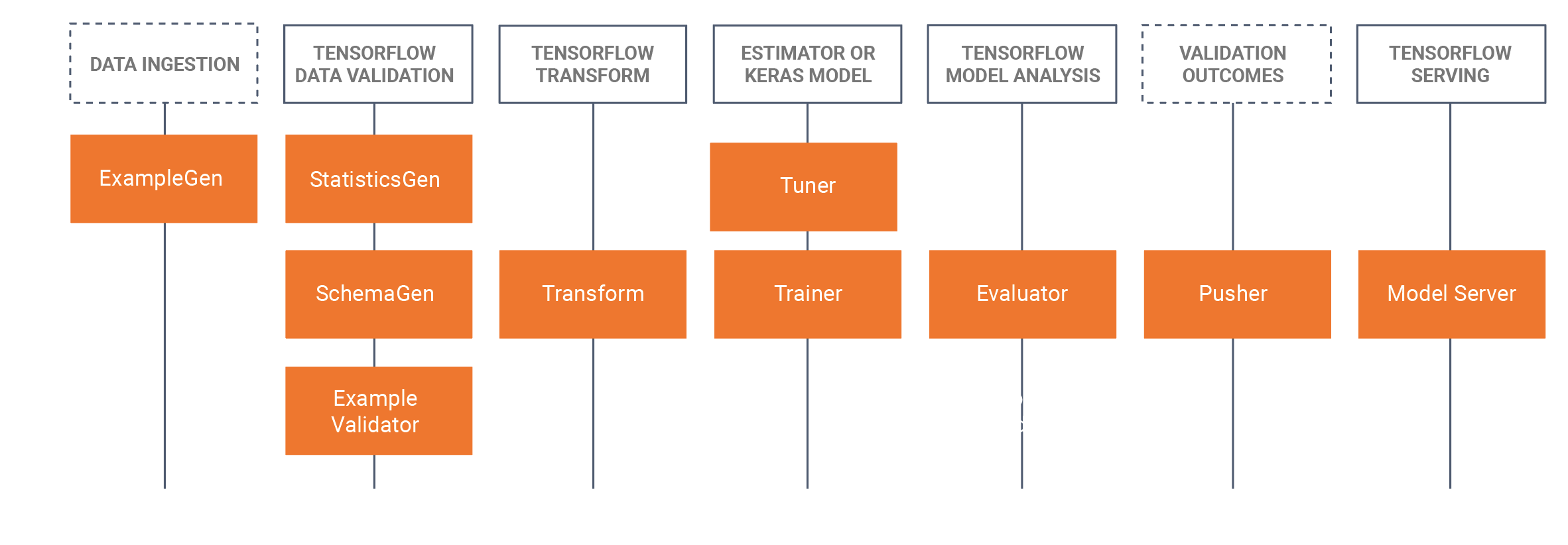
TFX מספק מספר חבילות Python שהן הספריות המשמשות ליצירת רכיבי צינור. אתה תשתמש בספריות אלה כדי ליצור את הרכיבים של הצינורות שלך כך שהקוד שלך יוכל להתמקד בהיבטים הייחודיים של הצינור שלך.
ספריות TFX כוללות:
TensorFlow Data Validation (TFDV) היא ספרייה לניתוח ואימות נתוני למידת מכונה. זה נועד להיות ניתנת להרחבה ולעבוד היטב עם TensorFlow ו-TFX. TFDV כולל:
- חישוב ניתן להרחבה של סיכום נתונים סטטיסטיים של אימון ונתוני מבחנים.
- אינטגרציה עם צופה להפצות נתונים וסטטיסטיקות, כמו גם השוואה של צמדי מערכי נתונים (Facets).
- יצירת סכימת נתונים אוטומטית לתיאור ציפיות לגבי נתונים כמו ערכים נדרשים, טווחים ואוצר מילים.
- מציג סכימה שיעזור לך לבדוק את הסכימה.
- זיהוי חריגות לזיהוי חריגות, כגון תכונות חסרות, ערכים מחוץ לטווח, או סוגי תכונות שגויים, אם להזכיר כמה.
- מציג חריגות כדי שתוכל לראות באילו תכונות יש חריגות וללמוד יותר כדי לתקן אותן.
TensorFlow Transform (TFT) היא ספרייה לעיבוד מוקדם של נתונים עם TensorFlow. TensorFlow Transform שימושי עבור נתונים הדורשים מעבר מלא, כגון:
- נרמל ערך קלט לפי ממוצע וסטיית תקן.
- המרת מחרוזות למספרים שלמים על ידי יצירת אוצר מילים על כל ערכי הקלט.
- המר צפים למספרים שלמים על ידי הקצאתם לדליים בהתבסס על התפלגות הנתונים הנצפית.
TensorFlow משמש לאימון מודלים עם TFX. הוא קולט נתוני אימון וקוד מידול ויוצר תוצאת SavedModel. זה גם משלב צינור הנדסי תכונות שנוצר על ידי TensorFlow Transform לעיבוד מקדים של נתוני קלט.
KerasTuner משמש לכוונון היפרפרמטרים לדגם.
TensorFlow Model Analysis (TFMA) היא ספרייה להערכת מודלים של TensorFlow. הוא משמש יחד עם TensorFlow ליצירת EvalSavedModel, שהופך לבסיס לניתוח שלו. זה מאפשר למשתמשים להעריך את המודלים שלהם על כמויות גדולות של נתונים בצורה מבוזרת, תוך שימוש באותם מדדים שהוגדרו במאמן שלהם. ניתן לחשב מדדים אלו על פני פרוסות נתונים שונות ולהמחיש אותם במחברות של Jupyter.
TensorFlow Metadata (TFMD) מספק ייצוגים סטנדרטיים למטא נתונים שימושיים בעת אימון מודלים של למידת מכונה עם TensorFlow. המטא-נתונים עשויים להיות מופקים ביד או אוטומטית במהלך ניתוח נתוני קלט, וניתן לצרוך אותם לצורך אימות נתונים, חקירה ושינוי. הפורמטים של סידורי מטא נתונים כוללים:
- סכימה המתארת נתונים טבלאיים (למשל, tf.Examples).
- אוסף של סטטיסטיקות סיכום על מערכי נתונים כאלה.
ML Metadata (MLMD) היא ספרייה להקלטה ואחזור מטא נתונים הקשורים לתהליכי עבודה של מפתחי ML ומדעני נתונים. לרוב המטא-נתונים משתמשים בייצוגי TFMD. MLMD מנהלת התמדה באמצעות SQL-Lite , MySQL ומאגרי נתונים דומים אחרים.
טכנולוגיות תומכות
דָרוּשׁ
- Apache Beam הוא מודל קוד פתוח ומאוחד להגדרת צינורות עיבוד מקבילים של אצווה והזרמת נתונים. TFX משתמש ב-Apache Beam כדי ליישם צינורות מקבילים לנתונים. לאחר מכן, הצינור מבוצע על ידי אחד מקצה העיבוד המבוזר הנתמכים של Beam, הכוללים את Apache Flink, Apache Spark, Google Cloud Dataflow ואחרים.
אופציונלי
מתזמרים כגון Apache Airflow ו-Kubeflow מקלים על הגדרה, הפעלה, ניטור ותחזוקה של צינור ML.
Apache Airflow היא פלטפורמה לכתיבה, תזמון וניטור של זרימות עבודה באופן תכנותי. TFX משתמש ב-Airflow כדי ליצור זרימות עבודה כגרפים א-מחזוריים מכוונים (DAGs) של משימות. מתזמן זרימת האוויר מבצע משימות על מערך עובדים תוך מעקב אחר התלות שצוינו. כלי עזר עשירים של שורת פקודה הופכים את ביצוע ניתוחים מורכבים ב-DAGs לקצרה. ממשק המשתמש העשיר מאפשר לדמיין בקלות צינורות הפועלים בייצור, לנטר את ההתקדמות ולפתור בעיות בעת הצורך. כאשר זרימות עבודה מוגדרות כקוד, הן הופכות לניתנות לתחזוקה, לגירסאות, לבדיקה ולשיתוף פעולה.
Kubeflow מוקדש להפיכת פריסות של תהליכי עבודה של למידת מכונה (ML) ב-Kubernetes פשוטה, ניידת וניתנת להרחבה. המטרה של Kubeflow היא לא ליצור מחדש שירותים אחרים, אלא לספק דרך פשוטה לפרוס מערכות קוד פתוח מהסוג הטוב ביותר עבור ML לתשתיות מגוונות. Kubeflow Pipelines מאפשרים הרכבה וביצוע של זרימות עבודה הניתנות לשחזור ב-Kubeflow, משולבות עם ניסויים וחוויות מבוססות מחברת. שירותי Kubeflow Pipelines ב-Kubernetes כוללים את חנות Metadata המתארחת, מנוע תזמור מבוסס קונטיינר, שרת מחברת וממשק משתמש כדי לעזור למשתמשים לפתח, להפעיל ולנהל צינורות ML מורכבים בקנה מידה. ה-SDK של Kubeflow Pipelines מאפשר יצירה ושיתוף של רכיבים והרכב של צינורות באופן פרוגרמטי.
ניידות ויכולת פעולה הדדית
TFX תוכנן להיות נייד למספר סביבות ומסגרות תזמור, כולל Apache Airflow , Apache Beam ו- Kubeflow . הוא גם נייד לפלטפורמות מחשוב שונות, כולל פלטפורמות מקומיות ופלטפורמות ענן כגון Google Cloud Platform (GCP) . בפרט, TFX פועלת יחד עם שירותי GCP מנוהלים שרתים, כגון Cloud AI Platform for Training and Prediction , ו- Cloud Dataflow לעיבוד נתונים מבוזר עבור מספר היבטים אחרים של מחזור החיים של ML.
דגם לעומת SavedModel
דֶגֶם
מודל הוא הפלט של תהליך האימון. זהו התיעוד המסודר של המשקולות שנלמדו במהלך תהליך האימון. ניתן להשתמש במשקלים אלה לאחר מכן כדי לחשב תחזיות עבור דוגמאות קלט חדשות. עבור TFX ו- TensorFlow, 'מודל' מתייחס לנקודות המחסום המכילות את המשקולות שנלמדו עד לאותה נקודה.
שימו לב ש'מודל' עשוי להתייחס גם להגדרה של גרף החישוב של TensorFlow (כלומר קובץ Python) המבטא כיצד תחושב חיזוי. ניתן להשתמש בשני החושים לסירוגין בהתבסס על הקשר.
SavedModel
- מהו SavedModel : סריאליזציה אוניברסלית, ניטרלית בשפה, הרמטית וניתנת לשחזור של מודל TensorFlow.
- למה זה חשוב : זה מאפשר למערכות ברמה גבוהה יותר לייצר, לשנות ולצרוך מודלים של TensorFlow באמצעות הפשטה אחת.
SavedModel הוא פורמט ההסדרה המומלץ להגשת מודל TensorFlow בייצור, או לייצוא מודל מיומן עבור אפליקציה מקורית לנייד או JavaScript. לדוגמה, כדי להפוך מודל לשירות REST לביצוע תחזיות, ניתן להרכיב את המודל כ- SavedModel ולהגיש אותו באמצעות TensorFlow Serving. ראה הגשת מודל TensorFlow למידע נוסף.
סכֵימָה
חלק מרכיבי TFX משתמשים בתיאור של נתוני הקלט שלך הנקרא סכימה . הסכימה היא מופע של schema.proto . סכימות הן סוג של חוצץ פרוטוקול , הידוע יותר כ"פרוטובוף". הסכימה יכולה לציין סוגי נתונים עבור ערכי תכונה, האם תכונה חייבת להיות נוכחת בכל הדוגמאות, טווחי ערכים מותרים ומאפיינים אחרים. אחד היתרונות של שימוש ב- TensorFlow Data Validation (TFDV) הוא שהוא יפיק סכימה אוטומטית על ידי הסקת סוגים, קטגוריות וטווחים מנתוני האימון.
להלן קטע מתוך פרוטובוף סכימה:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
הרכיבים הבאים משתמשים בסכימה:
- אימות נתונים של TensorFlow
- טרנספורמציה של TensorFlow
בצינור TFX טיפוסי TensorFlow Data Validation מייצר סכימה, הנצרכת על ידי הרכיבים האחרים.
פיתוח עם TFX
TFX מספקת פלטפורמה רבת עוצמה לכל שלב של פרויקט למידת מכונה, החל ממחקר, ניסויים ופיתוח במכונה המקומית שלך ועד לפריסה. על מנת למנוע כפילות קוד ולחסל את הפוטנציאל להטיית אימון/הגשה, מומלץ מאוד ליישם את ה-TFX צינור שלך הן להכשרת מודלים והן לפריסה של מודלים מאומנים, ולהשתמש ברכיבי טרנספורמציה הממנפים את ספריית הטרנספורמציה של TensorFlow הן להדרכה והן להסקה. על ידי כך תשתמש באותו קוד עיבוד מקדים וניתוח באופן עקבי, ותימנע מהבדלים בין נתונים המשמשים לאימון ונתונים המוזנים למודלים המאומנים שלך בייצור, כמו גם תועלת מכתיבת קוד זה פעם אחת.
חקר נתונים, ויזואליזציה וניקוי
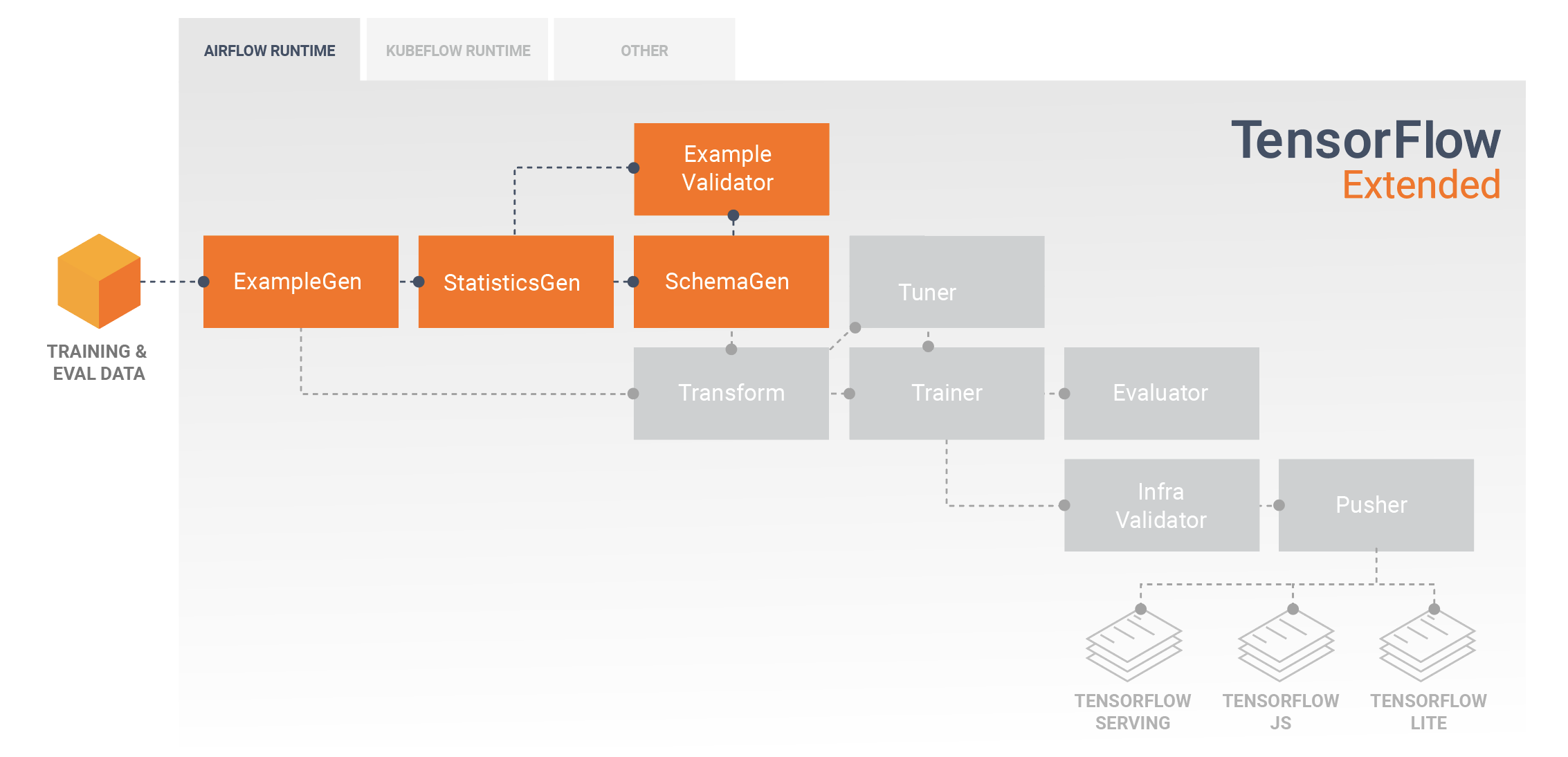
צינורות TFX מתחילים בדרך כלל ברכיב ExampleGen , שמקבל נתוני קלט ומעצב אותם כ-tf.Examples. לעתים קרובות זה נעשה לאחר שהנתונים פוצלו למערכי נתונים של הדרכה והערכה, כך שלמעשה יש שני עותקים של רכיבי ExampleGen, אחד כל אחד להדרכה והערכה. זה מלווה בדרך כלל ברכיב StatisticsGen ורכיב SchemaGen , שיבדקו את הנתונים שלך ויסיקו סכימת נתונים וסטטיסטיקה. הסכימה והסטטיסטיקה ייצרכו על ידי רכיב ExampleValidator , שיחפש חריגות, ערכים חסרים וסוגי נתונים שגויים בנתונים שלך. כל הרכיבים הללו ממנפים את היכולות של ספריית TensorFlow Data Validation .
TensorFlow Data Validation (TFDV) הוא כלי רב ערך בעת ביצוע חקירה ראשונית, הדמיה וניקוי של מערך הנתונים שלך. TFDV בוחן את הנתונים שלך ומסיק את סוגי הנתונים, הקטגוריות והטווחים, ולאחר מכן עוזר באופן אוטומטי לזהות חריגות וערכים חסרים. זה גם מספק כלי הדמיה שיכולים לעזור לך לבחון ולהבין את מערך הנתונים שלך. לאחר השלמת הצינור שלך, תוכל לקרוא מטא נתונים מ- MLMD ולהשתמש בכלי ההדמיה של TFDV במחברת Jupyter כדי לנתח את הנתונים שלך.
בעקבות ההכשרה והפריסה הראשונית של המודל, ניתן להשתמש ב-TFDV כדי לנטר נתונים חדשים מבקשות להסקת הסקה למודלים שנפרסו, ולחפש חריגות ו/או סחיפה. זה שימושי במיוחד עבור נתוני סדרות זמן המשתנים עם הזמן כתוצאה ממגמה או עונתיות, ויכול לעזור ליידע מתי יש בעיות בנתונים או כאשר יש צורך להכשיר מודלים מחדש על נתונים חדשים.
הדמיית נתונים
לאחר שהשלמת את הריצה הראשונה של הנתונים שלך דרך החלק של הצינור שלך שמשתמש ב-TFDV (בדרך כלל StatisticsGen, SchemaGen ו-ExampleValidator) אתה יכול לדמיין את התוצאות במחברת בסגנון Jupyter. עבור ריצות נוספות תוכל להשוות תוצאות אלו תוך כדי ביצוע התאמות, עד שהנתונים שלך יהיו אופטימליים עבור הדגם והיישום שלך.
תחילה תבצע שאילתה של ML Metadata (MLMD) כדי לאתר את התוצאות של ביצועים אלה של רכיבים אלה, ולאחר מכן תשתמש ב-API התמיכה בהדמיה ב-TFDV כדי ליצור את ההדמיות במחברת שלך. זה כולל tfdv.load_statistics() ו- tfdv.visualize_statistics() באמצעות הדמיה זו תוכל להבין טוב יותר את המאפיינים של מערך הנתונים שלך, ובמידת הצורך לשנות כנדרש.
פיתוח והדרכה של מודלים
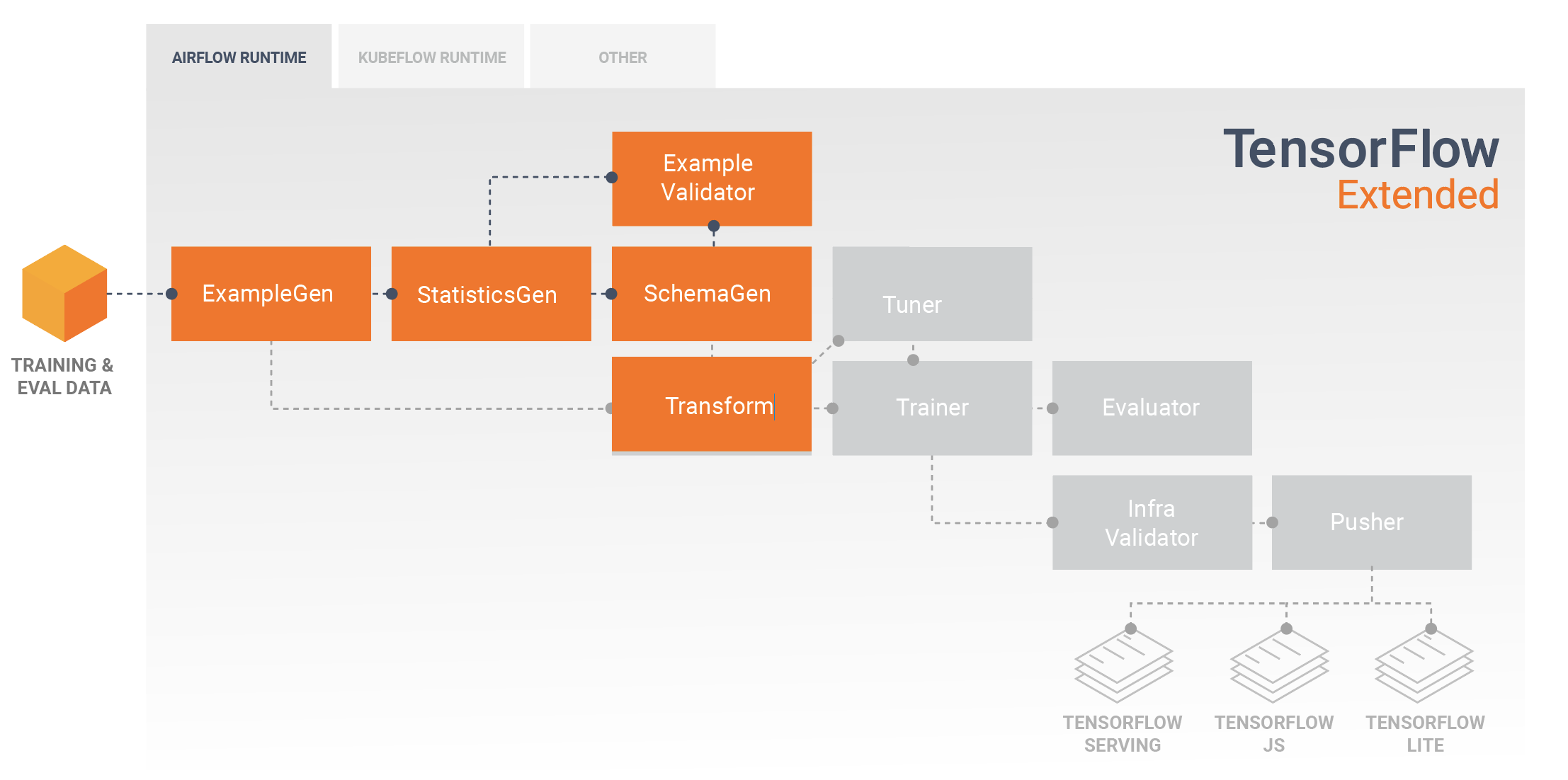
צינור TFX טיפוסי יכלול רכיב Transform , שיבצע הנדסת תכונות על ידי מינוף היכולות של ספריית TensorFlow Transform (TFT) . רכיב טרנספורמציה צורך את הסכימה שנוצרה על ידי רכיב SchemaGen, ומחיל טרנספורמציות נתונים כדי ליצור, לשלב ולהמיר את התכונות שישמשו לאימון המודל שלך. ניקוי ערכים חסרים והמרה של טיפוסים צריכים להיעשות גם ברכיב הטרנספורמציה אם קיימת אי פעם אפשרות שאלו יהיו נוכחים גם בנתונים שנשלחים לבקשות הסקה. ישנם כמה שיקולים חשובים בעת תכנון קוד TensorFlow לאימון ב-TFX.
התוצאה של רכיב טרנספורמציה היא SavedModel שייובא ויעשה בו שימוש בקוד הדוגמנות שלך ב-TensorFlow, במהלך רכיב Trainer . SavedModel זה כולל את כל הטרנספורמציות של הנדסת הנתונים שנוצרו ברכיב הטרנספורמציה, כך שהטרנספורמציות הזהות מבוצעות תוך שימוש באותו קוד בדיוק במהלך ההדרכה וההסקה. באמצעות קוד הדוגמנות, כולל SavedModel מהרכיב Transform, תוכל לצרוך את נתוני האימון וההערכה שלך ולאמן את המודל שלך.
כאשר עובדים עם מודלים מבוססי Estimator, החלק האחרון של קוד הדוגמנות שלך אמור לשמור את המודל שלך כ- SavedModel ו-EvalSavedModel. שמירה כ-EvalSavedModel מבטיחה שהמדדים המשמשים בזמן האימון זמינים גם במהלך ההערכה (שים לב שזה לא נדרש עבור מודלים מבוססי keras). שמירת EvalSavedModel מחייבת לייבא את ספריית TensorFlow Model Analysis (TFMA) לרכיב ה-Trainer שלך.
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
ניתן להוסיף רכיב טיונר אופציונלי לפני ה-Trainer כדי לכוון את הפרמטרים ההיפר (למשל, מספר השכבות) עבור הדגם. עם המודל הנתון ומרחב החיפוש של ההיפרפרמטרים, אלגוריתם הכוונון ימצא את הפרמטרים הטובים ביותר בהתבסס על המטרה.
ניתוח והבנת ביצועי המודל
לאחר פיתוח והדרכה ראשוניים של מודל, חשוב לנתח ולהבין באמת את ביצועי המודל שלך. צינור TFX טיפוסי יכלול רכיב Evaluator , הממנף את היכולות של ספריית TensorFlow Model Analysis (TFMA) , המספקת ערכת כלים חשמלית לשלב זה של פיתוח. רכיב Evaluator צורך את המודל שייצאת לעיל, ומאפשר לך לציין רשימה של tfma.SlicingSpec שבה תוכל להשתמש בעת הדמיה וניתוח של ביצועי המודל שלך. כל SlicingSpec מגדיר חלק מנתוני האימון שלך שאתה רוצה לבחון, כגון קטגוריות מסוימות עבור תכונות קטגוריות, או טווחים מסוימים עבור תכונות מספריות.
לדוגמה, זה יהיה חשוב כדי לנסות להבין את הביצועים של המודל שלך עבור פלחים שונים של הלקוחות שלך, שיכולים להיות מפולחים לפי רכישות שנתיות, נתונים גיאוגרפיים, קבוצת גיל או מין. זה יכול להיות חשוב במיוחד עבור מערכי נתונים עם זנבות ארוכים, שבהם הביצועים של קבוצה דומיננטית עשויים להסוות ביצועים לא מקובלים עבור קבוצות חשובות אך קטנות יותר. לדוגמה, המודל שלך עשוי להתפקד היטב עבור עובדים ממוצעים אך להיכשל כישלון חרוץ עבור צוות ההנהלה, וייתכן שחשוב לך לדעת זאת.
ניתוח והדמיה של מודלים
לאחר שהשלמת את הריצה הראשונה של הנתונים שלך באמצעות אימון המודל שלך והפעלת רכיב ה-Evaluator (הממנף את TFMA ) על תוצאות האימון, תוכל לדמיין את התוצאות במחברת בסגנון Jupyter. עבור ריצות נוספות תוכל להשוות תוצאות אלו תוך כדי ביצוע התאמות, עד שהתוצאות שלך יהיו אופטימליות עבור הדגם והיישום שלך.
תחילה תבצע שאילתה של ML Metadata (MLMD) כדי לאתר את התוצאות של ביצועים אלה של רכיבים אלה, ולאחר מכן תשתמש ב-API התמיכה בהדמיה ב-TFMA כדי ליצור את ההדמיות במחברת שלך. זה כולל tfma.load_eval_results ו- tfma.view.render_slicing_metrics באמצעות הדמיה זו תוכל להבין טוב יותר את המאפיינים של המודל שלך, ובמידת הצורך לשנות כנדרש.
אימות ביצועי מודל
כחלק מניתוח הביצועים של מודל, ייתכן שתרצה לאמת את הביצועים מול קו בסיס (כגון המודל המשרת כעת). אימות המודל מתבצע על ידי העברת מודל מועמד וגם מודל בסיסי לרכיב Evaluator . ה-Evaluator מחשב מדדים (למשל AUC, הפסד) הן עבור המועמד והן עבור קו הבסיס יחד עם קבוצה מתאימה של מדדי הבדל. לאחר מכן ניתן להחיל ספים ולהשתמש בהם כדי לדחוף את הדגמים שלך לייצור.
אימות שניתן להגיש דגם
לפני פריסת המודל המאומן, אולי תרצה לאמת אם המודל באמת ניתן להגשה בתשתית ההגשה. זה חשוב במיוחד בסביבות ייצור כדי להבטיח שהמודל החדש שפורסם לא מונע מהמערכת להגיש תחזיות. רכיב ה- InfraValidator יבצע פריסה קנרית של הדגם שלך בסביבת ארגז חול, ובאופן אופציונלי ישלח בקשות אמיתיות כדי לבדוק שהדגם שלך פועל כהלכה.
יעדי פריסה
לאחר שפיתחת והכשרת מודל שאתה מרוצה ממנו, הגיע הזמן לפרוס אותו ליעד פריסה אחד או יותר, שם הוא יקבל בקשות להסיק. TFX תומך בפריסה לשלושה סוגים של יעדי פריסה. ניתן לפרוס מודלים מאומנים שיצאו כ-SavedModels לכל אחד או לכל אחד מיעדי הפריסה הללו.
הסקה: TensorFlow Serving
TensorFlow Serving (TFS) היא מערכת הגשה גמישה בעלת ביצועים גבוהים עבור מודלים של למידת מכונה, המיועדת לסביבות ייצור. היא צורכת SavedModel ויקבל בקשות הסקה על פני ממשקי REST או gRPC. הוא פועל כסט של תהליכים על שרת רשת אחד או יותר, תוך שימוש באחת מכמה ארכיטקטורות מתקדמות לטיפול בסנכרון ובחישוב מבוזר. עיין בתיעוד TFS למידע נוסף על פיתוח ופריסה של פתרונות TFS.
בצנרת טיפוסית, SavedModel שעבר הכשרה ברכיב Trainer יקבל תחילה אימות אינפרא ברכיב InfraValidator . InfraValidator משיק שרת דגם TFS קנרי כדי לשרת בפועל את SavedModel. אם האימות עבר, רכיב Pusher יפרוס סוף סוף את SavedModel לתשתית ה-TFS שלך. זה כולל טיפול במספר גרסאות ועדכוני דגמים.
הסקה ביישומי Native Mobile ו-IoT: TensorFlow Lite
TensorFlow Lite היא חבילת כלים המיועדת לעזור למפתחים להשתמש בדגמי TensorFlow המאומנים שלהם ביישומי מובייל ו-IoT מקוריים. הוא צורך את אותם SavedModels כמו TensorFlow Serving, ומחיל אופטימיזציות כגון קוונטיזציה וגיזום כדי לייעל את הגודל והביצועים של המודלים המתקבלים עבור האתגרים של ריצה על מכשירים ניידים ו-IoT. עיין בתיעוד של TensorFlow Lite למידע נוסף על השימוש ב- TensorFlow Lite.
הסקה ב-JavaScript: TensorFlow JS
TensorFlow JS היא ספריית JavaScript לאימון ופריסה של מודלים של ML בדפדפן וב-Node.js. הוא צורך את אותם SavedModels כמו TensorFlow Serving ו- TensorFlow Lite, וממיר אותם לפורמט האינטרנט TensorFlow.js. עיין בתיעוד TensorFlow JS לפרטים נוספים על השימוש ב- TensorFlow JS.
יצירת צינור TFX עם זרימת אוויר
בדוק את סדנת זרימת האוויר לפרטים
יצירת צינור TFX עם Kubeflow
הגדרה
Kubeflow דורש אשכול Kubernetes כדי להפעיל את הצינורות בקנה מידה. עיין בהנחיית הפריסה של Kubeflow המנחה את האפשרויות לפריסת אשכול Kubeflow.
הגדר והפעל את צינור TFX
אנא עקוב אחר המדריך של TFX ב-Cloud AI Platform Pipeline כדי להפעיל את ה-TFX לדוגמה ב-Kubeflow. רכיבי TFX הוכנסו למכולות כדי להרכיב את צינור Kubeflow והדוגמה ממחישה את היכולת להגדיר את הצינור לקריאת מערך נתונים ציבורי גדול ולבצע שלבי הדרכה ועיבוד נתונים בקנה מידה בענן.
ממשק שורת הפקודה לפעולות צינור
TFX מספק CLI מאוחד שעוזר לבצע מגוון שלם של פעולות צינור כגון יצירה, עדכון, הפעלה, רשימה ומחיקה של צינורות על מתזמרים שונים כולל Apache Airflow, Apache Beam ו-Kubeflow. לפרטים, אנא עקוב אחר ההוראות הבאות .