
نمای کلی
خط لوله تحلیل مدل TensorFlow (TFMA) به صورت زیر نشان داده شده است:
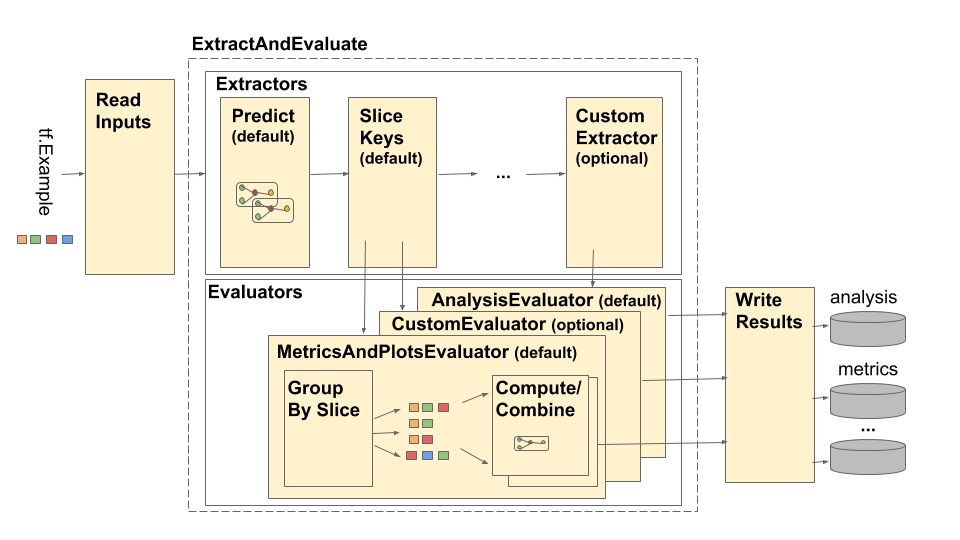
خط لوله از چهار جزء اصلی تشکیل شده است:
- ورودی ها را بخوانید
- استخراج
- ارزیابی
- نتایج را بنویسید
این مؤلفه ها از دو نوع اصلی استفاده می کنند: tfma.Extracts و tfma.evaluators.Evaluation . نوع tfma.Extracts نشان دهنده داده هایی است که در طول پردازش خط لوله استخراج می شوند و ممکن است با یک یا چند مثال برای مدل مطابقت داشته باشند. tfma.evaluators.Evaluation خروجی حاصل از ارزیابی عصاره ها در نقاط مختلف در طول فرآیند استخراج را نشان می دهد. به منظور ارائه یک API منعطف، این انواع فقط دستوراتی هستند که در آن کلیدها توسط پیاده سازی های مختلف تعریف می شوند (برای استفاده رزرو می شوند). انواع به شرح زیر تعریف می شود:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
توجه داشته باشید که tfma.Extracts هرگز مستقیماً نوشته نمیشوند، آنها همیشه باید از طریق یک ارزیاب برای تولید tfma.evaluators.Evaluation که سپس نوشته میشود، عبور کنند. همچنین توجه داشته باشید که tfma.Extracts دیکت هایی هستند که در یک beam.pvalue.PCollection ذخیره می شوند (یعنی beam.PTransform به عنوان ورودی beam.pvalue.PCollection[tfma.Extracts] در نظر گرفته می شود) در حالی که tfma.evaluators.Evaluation دیکتی است که مقادیر آن beam.pvalue.PCollection s هستند (یعنی beam.PTransform خود دیکت را به عنوان آرگومان ورودی beam.value.PCollection می گیرد). به عبارت دیگر tfma.evaluators.Evaluation در زمان ساخت خط لوله استفاده می شود، اما tfma.Extracts در زمان اجرای خط لوله استفاده می شود.
ورودی ها را بخوانید
مرحله ReadInputs از یک تبدیل تشکیل شده است که ورودی های خام (tf.train.Example، CSV، ...) را می گیرد و آنها را به عصاره تبدیل می کند. امروزه عصارهها بهعنوان بایتهای ورودی خام ذخیرهشده در tfma.INPUT_KEY نشان داده میشوند، اما عصارهها میتوانند به هر شکلی باشند که با خط لوله استخراج سازگار باشد - به این معنی که tfma.Extracts را به عنوان خروجی ایجاد میکند، و آن عصارهها با پاییندست سازگار هستند. استخراج کننده ها این به استخراج کنندگان مختلف بستگی دارد که آنچه را که نیاز دارند به وضوح مستند کنند.
استخراج
فرآیند استخراج لیستی از beam.PTransform است که به صورت سری اجرا می شوند. استخراج کننده ها tfma.Extracts را به عنوان ورودی می گیرند و tfma.Extracts را به عنوان خروجی برمی گردانند. استخراج کننده نمونه اولیه tfma.extractors.PredictExtractor است که از عصاره ورودی تولید شده توسط تبدیل ورودی های خوانده شده استفاده می کند و آن را از طریق یک مدل برای تولید عصاره های پیش بینی اجرا می کند. استخراج کننده های سفارشی شده را می توان در هر نقطه وارد کرد، مشروط بر اینکه تبدیل آنها با tfma.Extracts in و tfma.Extracts out مطابقت داشته باشد. استخراج کننده به صورت زیر تعریف می شود:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
InputExtractor
tfma.extractors.InputExtractor برای استخراج ویژگیهای خام، برچسبهای خام و وزنهای نمونه خام از رکوردهای tf.train.Example برای استفاده در برشهای متریک و محاسبات استفاده میشود. بهطور پیشفرض مقادیر به ترتیب در زیر کلیدهای استخراج features ، labels و example_weights ذخیره میشوند. برچسب های مدل تک خروجی و وزن های نمونه مستقیماً به عنوان مقادیر np.ndarray ذخیره می شوند. برچسبهای مدل چند خروجی و وزنهای نمونه بهعنوان دستورات مقادیر np.ndarray ذخیره میشوند (کلید شده با نام خروجی). اگر ارزیابی چند مدلی انجام شود، برچسبها و وزنهای نمونه بیشتر در یک دیکته دیگر (کلید شده با نام مدل) تعبیه میشوند.
پیش بینی استخراج
tfma.extractors.PredictExtractor پیش بینی های مدل را اجرا می کند و آنها را در زیر predictions کلیدی در tfma.Extracts dict ذخیره می کند. پیش بینی های مدل تک خروجی مستقیماً به عنوان مقادیر خروجی پیش بینی شده ذخیره می شوند. پیشبینیهای مدل چند خروجی بهعنوان دیکتهای از مقادیر خروجی (که با نام خروجی کلید میخورد) ذخیره میشوند. اگر ارزیابی چند مدلی انجام شود، پیشبینی بیشتر در یک دیکته دیگر (کلید شده با نام مدل) تعبیه میشود. مقدار واقعی خروجی استفاده شده به مدل بستگی دارد (مثلاً خروجی های بازگشتی برآوردگر TF به صورت دیکته در حالی که keras مقادیر np.ndarray را برمی گرداند).
SliceKeyExtractor
tfma.extractors.SliceKeyExtractor از مشخصات برش استفاده میکند تا تعیین کند کدام برشها برای هر ورودی نمونه بر اساس ویژگیهای استخراجشده اعمال میشوند و مقادیر برش متناظر را برای استفاده بعدی توسط ارزیابان به عصارهها اضافه میکند.
ارزیابی
ارزیابی فرآیند استخراج عصاره و ارزیابی آن است. در حالی که انجام ارزیابی در انتهای خط لوله استخراج معمول است، موارد استفاده ای وجود دارد که نیاز به ارزیابی زودتر در فرآیند استخراج دارد. از آنجایی که چنین ارزیاب هایی با استخراج کننده هایی مرتبط هستند که خروجی آنها باید بر اساس آنها ارزیابی شود. یک ارزیاب به صورت زیر تعریف می شود:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
توجه کنید که یک ارزیاب یک beam.PTransform است. PTtransform که tfma.Extracts به عنوان ورودی می گیرد. هیچ چیز مانع از اجرای تغییرات اضافی بر روی عصاره ها به عنوان بخشی از فرآیند ارزیابی نمی شود. برخلاف استخراجکنندهها که باید یک tfma.Extracts dict را برگردانند، هیچ محدودیتی در نوع خروجیهایی که یک ارزیاب میتواند تولید کند وجود ندارد، اگرچه اکثر ارزیابها یک دیکته را نیز برمیگردانند (مثلاً نامها و مقادیر متریک).
MetricsAndPlotsEvaluator
tfma.evaluators.MetricsAndPlotsEvaluator features ، labels و predictions را به عنوان ورودی می گیرد، آنها را از طریق tfma.slicer.FanoutSlices اجرا می کند تا آنها را بر اساس برش ها گروه بندی کند، و سپس متریک ها را انجام می دهد و محاسبات را ترسیم می کند. خروجی هایی را به شکل فرهنگ لغت متریک تولید می کند و کلیدها و مقادیر را ترسیم می کند (اینها بعداً به پروتوهای سریالی برای خروجی توسط tfma.writers.MetricsAndPlotsWriter تبدیل می شوند).
نتایج را بنویسید
مرحله WriteResults جایی است که خروجی ارزیابی روی دیسک نوشته می شود. WriteResults از نویسنده ها برای نوشتن داده ها بر اساس کلیدهای خروجی استفاده می کند. به عنوان مثال، یک tfma.evaluators.Evaluation ممکن است حاوی کلیدهایی برای metrics و plots باشد. سپس اینها با دیکشنری های متریک و نمودار به نام «متریکس» و «نقشه» مرتبط می شوند. نویسندگان نحوه نوشتن هر فایل را مشخص می کنند:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsWriter
ما یک tfma.writers.MetricsAndPlotsWriter ارائه می دهیم که معیارها و رسم دیکشنری ها را به پروتوهای سریالی تبدیل می کند و آنها را روی دیسک می نویسد.
اگر میخواهید از قالب سریالسازی متفاوتی استفاده کنید، میتوانید یک نویسنده سفارشی ایجاد کنید و به جای آن از آن استفاده کنید. از آنجایی که tfma.evaluators.Evaluation ارسال شده به نویسنده ها حاوی خروجی برای همه ارزیاب ها است، یک تبدیل کمکی tfma.writers.Write ارائه شده است که نویسندگان می توانند در پیاده سازی های ptransform خود برای انتخاب beam.PCollection مناسب استفاده کنند.PCollection s بر اساس یک کلید خروجی (برای مثال به زیر مراجعه کنید).
سفارشی سازی
روش tfma.run_model_analysis برای سفارشی کردن extractors ، evaluators و writers مورد استفاده خط لوله، استدلالهای استخراجکننده، ارزیابیکننده و نویسنده را میگیرد. اگر هیچ آرگومانی ارائه نشود، tfma.default_extractors ، tfma.default_evaluators ، و tfma.default_writers به طور پیشفرض استفاده میشوند.
استخراج کننده های سفارشی
برای ایجاد یک استخراج کننده سفارشی، یک نوع tfma.extractors.Extractor ایجاد کنید که یک beam.PTransform بپیچد. PT تبدیل tfma.Extracts به عنوان ورودی و برگرداندن tfma.Extracts به عنوان خروجی. نمونه هایی از استخراج کننده ها تحت tfma.extractors موجود هستند.
ارزیاب های سفارشی
برای ایجاد یک ارزیاب سفارشی، یک نوع tfma.evaluators.Evaluator ایجاد کنید که یک beam.PTransform بپیچد. PT تبدیل tfma.Extracts به عنوان ورودی و برگرداندن tfma.evaluators.Evaluation به عنوان خروجی. یک ارزیاب بسیار ابتدایی ممکن است tfma.Extracts ورودی را بگیرد و آنها را برای ذخیره در یک جدول خروجی دهد. این دقیقاً همان کاری است که tfma.evaluators.AnalysisTableEvaluator انجام می دهد. یک ارزیاب پیچیده تر ممکن است پردازش و تجمیع داده های اضافی را انجام دهد. به عنوان مثال tfma.evaluators.MetricsAndPlotsEvaluator را ببینید.
توجه داشته باشید که خود tfma.evaluators.MetricsAndPlotsEvaluator می تواند برای پشتیبانی از معیارهای سفارشی سفارشی شود (برای جزئیات بیشتر به معیارها مراجعه کنید).
نویسندگان سفارشی
برای ایجاد یک رایتر سفارشی، یک نوع tfma.writers.Writer ایجاد کنید که یک beam.PTransform بپیچد.PT تبدیل tfma.evaluators.Evaluation را به عنوان ورودی و برگرداندن beam.pvalue.PDone به عنوان خروجی تبدیل کنید. در زیر یک مثال اساسی از یک نویسنده برای نوشتن TFRecords حاوی معیارها است:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
ورودی های نویسنده به خروجی ارزیاب مرتبط بستگی دارد. برای مثال بالا، خروجی یک پروتوی سریالی است که توسط tfma.evaluators.MetricsAndPlotsEvaluator تولید شده است. یک نویسنده برای tfma.evaluators.AnalysisTableEvaluator مسئول نوشتن یک beam.pvalue.PCollection از tfma.Extracts است.
توجه داشته باشید که یک نویسنده از طریق کلید خروجی مورد استفاده (مثلا tfma.METRICS_KEY ، tfma.ANALYSIS_KEY و غیره) با خروجی یک ارزیاب مرتبط می شود.
گام به گام مثال
در زیر نمونهای از مراحل درگیر در خط لوله استخراج و ارزیابی است که هر دو tfma.evaluators.MetricsAndPlotsEvaluator و tfma.evaluators.AnalysisTableEvaluator استفاده میشوند:
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(اجرای_بعد:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(اجرای_بعد:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files