
Este tutorial mostra como usar o TensorFlow Transform (a biblioteca tf.Transform ) para implementar o pré-processamento de dados para aprendizado de máquina (ML). A biblioteca tf.Transform do TensorFlow permite definir transformações de dados em nível de instância e de passagem completa por meio de pipelines de pré-processamento de dados. Esses pipelines são executados de forma eficiente com Apache Beam e criam como subprodutos um gráfico TensorFlow para aplicar as mesmas transformações durante a previsão como quando o modelo é servido.
Este tutorial fornece um exemplo completo usando o Dataflow como executor para Apache Beam. Presume-se que você esteja familiarizado com o BigQuery , o Dataflow, o Vertex AI e a API TensorFlow Keras . Também pressupõe que você tenha alguma experiência no uso de Jupyter Notebooks, como o Vertex AI Workbench .
Este tutorial também pressupõe que você esteja familiarizado com os conceitos de tipos de pré-processamento, desafios e opções no Google Cloud, conforme descrito em Pré-processamento de dados para ML: opções e recomendações .
Objetivos
- Implemente o pipeline do Apache Beam usando a biblioteca
tf.Transform. - Execute o pipeline no Dataflow.
- Implemente o modelo TensorFlow usando a biblioteca
tf.Transform. - Treine e use o modelo para previsões.
Custos
Este tutorial usa os seguintes componentes faturáveis do Google Cloud:
Para estimar o custo de execução deste tutorial, supondo que você use todos os recursos durante um dia inteiro, use a calculadora de preços pré-configurada.
Antes de começar
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud .
Certifique-se de que o faturamento esteja ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto .
Ative as APIs Dataflow, Vertex AI e Notebooks. Habilite as APIs
Notebooks Jupyter para esta solução
Os seguintes notebooks Jupyter mostram o exemplo de implementação:
- O Notebook 1 cobre o pré-processamento de dados. Os detalhes são fornecidos na seção Implementando o pipeline do Apache Beam posteriormente.
- O caderno 2 cobre o treinamento do modelo. Os detalhes são fornecidos na seção Implementando o modelo do TensorFlow posteriormente.
Nas seções a seguir, você clonará esses notebooks e, em seguida, executará os notebooks para aprender como funciona o exemplo de implementação.
Iniciar uma instância de notebooks gerenciados pelo usuário
No console do Google Cloud, acesse a página Vertex AI Workbench .
Na guia Blocos de anotações gerenciados pelo usuário , clique em +Novo bloco de notas .
Selecione TensorFlow Enterprise 2.8 (com LTS) sem GPUs para o tipo de instância.
Clique em Criar .
Depois de criar o notebook, aguarde até que o proxy do JupyterLab termine a inicialização. Quando estiver pronto, Open JupyterLab será exibido ao lado do nome do notebook.
Clonar o bloco de notas
Na guia Notebooks gerenciados pelo usuário , ao lado do nome do notebook, clique em Abrir JupyterLab . A interface do JupyterLab é aberta em uma nova guia.
Se o JupyterLab exibir uma caixa de diálogo Compilação recomendada , clique em Cancelar para rejeitar a compilação sugerida.
Na guia Iniciador , clique em Terminal .
Na janela do terminal, clone o notebook:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Implementar o pipeline do Apache Beam
Esta seção e a próxima seção Executar o pipeline no Dataflow fornecem uma visão geral e o contexto do notebook 1. O notebook fornece um exemplo prático para descrever como usar a biblioteca tf.Transform para pré-processar dados. Este exemplo usa o conjunto de dados Natality, que é usado para prever o peso do bebê com base em várias entradas. Os dados são armazenados na tabela pública de natalidade do BigQuery.
Execute o Caderno 1
Na interface do JupyterLab, clique em Arquivo > Abrir do caminho e insira o seguinte caminho:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbClique em Editar > Limpar todas as saídas .
Na seção Instalar pacotes necessários , execute a primeira célula para executar o comando
pip install apache-beam.A última parte da saída é a seguinte:
Successfully installed ...Você pode ignorar erros de dependência na saída. Você não precisa reiniciar o kernel ainda.
Execute a segunda célula para executar o comando
pip install tensorflow-transform. A última parte da saída é a seguinte:Successfully installed ... Note: you may need to restart the kernel to use updated packages.Você pode ignorar erros de dependência na saída.
Clique em Kernel > Reiniciar Kernel .
Execute as células nas seções Confirmar os pacotes instalados e Criar setup.py para instalar pacotes nos contêineres do Dataflow .
Na seção Definir sinalizadores globais , ao lado de
PROJECTeBUCKET, substituayour-projectpelo ID do projeto do Cloud e execute a célula.Execute todas as células restantes até a última célula do notebook. Para obter informações sobre o que fazer em cada célula, consulte as instruções no caderno.
Visão geral do pipeline
No exemplo do notebook, o Dataflow executa o pipeline tf.Transform em escala para preparar os dados e produzir os artefatos de transformação. As seções posteriores deste documento descrevem as funções que executam cada etapa do pipeline. As etapas gerais do pipeline são as seguintes:
- Leia dados de treinamento do BigQuery.
- Analise e transforme dados de treinamento usando a biblioteca
tf.Transform. - Grave dados de treinamento transformados no Cloud Storage no formato TFRecord .
- Leia os dados de avaliação do BigQuery.
- Transforme os dados de avaliação usando o gráfico
transform_fnproduzido na etapa 2. - Grave dados de treinamento transformados no Cloud Storage no formato TFRecord.
- Grave artefatos de transformação no Cloud Storage que serão usados posteriormente para criar e exportar o modelo.
O exemplo a seguir mostra o código Python para o pipeline geral. As seções a seguir fornecem explicações e listagens de códigos para cada etapa.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
Leia dados brutos de treinamento do BigQuery
A primeira etapa é ler os dados brutos de treinamento do BigQuery usando a função read_from_bq . Esta função retorna um objeto raw_dataset extraído do BigQuery. Você passa um valor data_size e um valor de step train ou eval . A consulta de origem do BigQuery é construída usando a função get_source_query , conforme mostrado no exemplo a seguir:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
Antes de executar o pré-processamento tf.Transform , pode ser necessário executar o processamento típico baseado no Apache Beam, incluindo processamento de mapa, filtro, grupo e janela. No exemplo, o código limpa os registros lidos do BigQuery usando o método beam.Map(prep_bq_row) , onde prep_bq_row é uma função personalizada. Esta função personalizada converte o código numérico de um recurso categórico em rótulos legíveis por humanos.
Além disso, para usar a biblioteca tf.Transform para analisar e transformar o objeto raw_data extraído do BigQuery, você precisa criar um objeto raw_dataset , que é uma tupla de objetos raw_data e raw_metadata . O objeto raw_metadata é criado usando a função create_raw_metadata , como segue:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
Ao executar a célula no notebook que segue imediatamente a célula que define esse método, o conteúdo do objeto raw_metadata.schema é exibido. Inclui as seguintes colunas:
-
gestation_weeks(tipo:FLOAT) -
is_male(tipo:BYTES) -
mother_age(tipo:FLOAT) -
mother_race(tipo:BYTES) -
plurality(tipo:FLOAT) -
weight_pounds(tipo:FLOAT)
Transforme dados brutos de treinamento
Imagine que você deseja aplicar transformações típicas de pré-processamento aos recursos brutos de entrada dos dados de treinamento para prepará-los para ML. Essas transformações incluem operações de passagem completa e de nível de instância, conforme mostrado na tabela a seguir:
| Recurso de entrada | Transformação | Estatísticas necessárias | Tipo | Recurso de saída |
|---|---|---|---|---|
weight_pound | Nenhum | Nenhum | N / D | weight_pound |
mother_age | Normalizar | quer dizer, var | Passe completo | mother_age_normalized |
mother_age | Bucketização de tamanho igual | quantis | Passe completo | mother_age_bucketized |
mother_age | Calcule o log | Nenhum | Nível de instância | mother_age_log |
plurality | Indique se são bebês únicos ou múltiplos | Nenhum | Nível de instância | is_multiple |
is_multiple | Converter valores nominais em índice numérico | vocabulário | Passe completo | is_multiple_index |
gestation_weeks | Escala entre 0 e 1 | mínimo, máximo | Passe completo | gestation_weeks_scaled |
mother_race | Converter valores nominais em índice numérico | vocabulário | Passe completo | mother_race_index |
is_male | Converter valores nominais em índice numérico | vocabulário | Passe completo | is_male_index |
Essas transformações são implementadas em uma função preprocess_fn , que espera um dicionário de tensores ( input_features ) e retorna um dicionário de recursos processados ( output_features ).
O código a seguir mostra a implementação da função preprocess_fn , usando as APIs de transformação de passagem completa tf.Transform (prefixadas com tft. ) e operações em nível de instância do TensorFlow (prefixadas com tf. ):
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
A estrutura tf.Transform possui diversas outras transformações além daquelas do exemplo anterior, incluindo aquelas listadas na tabela a seguir:
| Transformação | Aplica-se a | Descrição |
|---|---|---|
scale_by_min_max | Recursos numéricos | Dimensiona uma coluna numérica no intervalo [ output_min , output_max ] |
scale_to_0_1 | Recursos numéricos | Retorna uma coluna que é a coluna de entrada dimensionada para ter intervalo [ 0 , 1 ] |
scale_to_z_score | Recursos numéricos | Retorna uma coluna padronizada com média 0 e variância 1 |
tfidf | Recursos de texto | Mapeia os termos em x para sua frequência de termo * frequência inversa do documento |
compute_and_apply_vocabulary | Recursos categóricos | Gera um vocabulário para um recurso categórico e o mapeia para um número inteiro com este vocabulário |
ngrams | Recursos de texto | Cria um SparseTensor de n-gramas |
hash_strings | Recursos categóricos | Hashes de strings em buckets |
pca | Recursos numéricos | Calcula PCA no conjunto de dados usando covariância tendenciosa |
bucketize | Recursos numéricos | Retorna uma coluna agrupada de tamanho igual (baseada em quantis), com um índice de intervalo atribuído a cada entrada |
Para aplicar as transformações implementadas na função preprocess_fn ao objeto raw_train_dataset produzido na etapa anterior do pipeline, você usa o método AnalyzeAndTransformDataset . Este método espera o objeto raw_dataset como entrada, aplica a função preprocess_fn e produz o objeto transformed_dataset e o gráfico transform_fn . O código a seguir ilustra esse processamento:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
As transformações são aplicadas nos dados brutos em duas fases: a fase de análise e a fase de transformação. A Figura 3 mais adiante neste documento mostra como o método AnalyzeAndTransformDataset é decomposto no método AnalyzeDataset e no método TransformDataset .
A fase de análise
Na fase de análise, os dados brutos de treinamento são analisados em um processo completo para calcular as estatísticas necessárias para as transformações. Isso inclui calcular a média, variância, mínimo, máximo, quantis e vocabulário. O processo de análise espera um conjunto de dados brutos (dados brutos mais metadados brutos) e produz duas saídas:
-
transform_fn: um gráfico do TensorFlow que contém as estatísticas computadas da fase de análise e a lógica de transformação (que usa as estatísticas) como operações em nível de instância. Conforme discutido posteriormente em Salvar o gráfico , o gráficotransform_fné salvo para ser anexado à função do modeloserving_fn. Isto torna possível aplicar a mesma transformação aos pontos de dados de previsão online. -
transform_metadata: um objeto que descreve o esquema esperado dos dados após a transformação.
A fase de análise é ilustrada no diagrama a seguir, figura 1:

tf.Transform . Os analisadores tf.Transform incluem min , max , sum , size , mean , var , covariance , quantiles , vocabulary e pca .
A fase de transformação
Na fase de transformação, o gráfico transform_fn produzido pela fase de análise é usado para transformar os dados brutos de treinamento em um processo em nível de instância para produzir os dados de treinamento transformados. Os dados de treinamento transformados são emparelhados com os metadados transformados (produzidos pela fase de análise) para produzir o conjunto de dados transformed_train_dataset .
A fase de transformação é ilustrada no diagrama a seguir, figura 2:

tf.Transform . Para pré-processar os recursos, você chama as transformações tensorflow_transform necessárias (importadas como tft no código) em sua implementação da função preprocess_fn . Por exemplo, quando você chama as operações tft.scale_to_z_score , a biblioteca tf.Transform traduz essa chamada de função em analisadores de média e variância, calcula as estatísticas na fase de análise e, em seguida, aplica essas estatísticas para normalizar o recurso numérico na fase de transformação. Tudo isso é feito automaticamente chamando o método AnalyzeAndTransformDataset(preprocess_fn) .
A entidade transformed_metadata.schema produzida por esta chamada inclui as seguintes colunas:
-
gestation_weeks_scaled(tipo:FLOAT) -
is_male_index(tipo:INT, is_categorical:True) -
is_multiple_index(tipo:INT, is_categorical:True) -
mother_age_bucketized(tipo:INT, is_categorical:True) -
mother_age_log(tipo:FLOAT) -
mother_age_normalized(tipo:FLOAT) -
mother_race_index(tipo:INT, is_categorical:True) -
weight_pounds(tipo:FLOAT)
Conforme explicado em Operações de pré-processamento na primeira parte desta série, a transformação de recursos converte recursos categóricos em uma representação numérica. Após a transformação, os recursos categóricos são representados por valores inteiros. Na entidade transformed_metadata.schema , o sinalizador is_categorical para colunas do tipo INT indica se a coluna representa um recurso categórico ou um recurso numérico verdadeiro.
Escreva dados de treinamento transformados
Depois que os dados de treinamento forem pré-processados com a função preprocess_fn durante as fases de análise e transformação, você poderá gravar os dados em um coletor a ser usado para treinar o modelo do TensorFlow. Quando você executa o pipeline do Apache Beam usando o Dataflow, o coletor é o Cloud Storage. Caso contrário, o coletor será o disco local. Embora você possa gravar os dados como um arquivo CSV de arquivos formatados com largura fixa, o formato de arquivo recomendado para conjuntos de dados do TensorFlow é o formato TFRecord. Este é um formato binário simples orientado a registros que consiste em mensagens de buffer de protocolo tf.train.Example .
Cada registro tf.train.Example contém um ou mais recursos. Eles são convertidos em tensores quando são alimentados no modelo para treinamento. O código a seguir grava o conjunto de dados transformado em arquivos TFRecord no local especificado:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
Ler, transformar e gravar dados de avaliação
Depois de transformar os dados de treinamento e produzir o gráfico transform_fn , você poderá usá-lo para transformar os dados de avaliação. Primeiro, você lê e limpa os dados de avaliação do BigQuery usando a função read_from_bq descrita anteriormente em Ler dados brutos de treinamento do BigQuery e passando um valor de eval para o parâmetro step . Em seguida, você usa o código a seguir para transformar o conjunto de dados de avaliação bruto ( raw_dataset ) no formato transformado esperado ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
Quando você transforma os dados de avaliação, somente as operações em nível de instância se aplicam, usando a lógica no gráfico transform_fn e as estatísticas calculadas na fase de análise nos dados de treinamento. Em outras palavras, você não analisa os dados de avaliação de maneira completa para calcular novas estatísticas, como a média e a variância para normalização de pontuação z de recursos numéricos em dados de avaliação. Em vez disso, você usa as estatísticas computadas dos dados de treinamento para transformar os dados de avaliação em nível de instância.
Portanto, você usa o método AnalyzeAndTransform no contexto de dados de treinamento para calcular as estatísticas e transformar os dados. Ao mesmo tempo, você usa o método TransformDataset no contexto de transformação de dados de avaliação para transformar apenas os dados usando as estatísticas calculadas nos dados de treinamento.
Em seguida, você grava os dados em um coletor (Cloud Storage ou disco local, dependendo do executor) no formato TFRecord para avaliar o modelo do TensorFlow durante o processo de treinamento. Para fazer isso, você usa a função write_tfrecords discutida em Gravar dados de treinamento transformados . O diagrama a seguir, figura 3, mostra como o gráfico transform_fn produzido na fase de análise dos dados de treinamento é usado para transformar os dados de avaliação.

transform_fn .Salve o gráfico
Uma etapa final no pipeline de pré-processamento tf.Transform é armazenar os artefatos, que incluem o gráfico transform_fn produzido pela fase de análise nos dados de treinamento. O código para armazenar os artefatos é mostrado na seguinte função write_transform_artefacts :
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
Esses artefatos serão usados posteriormente para treinamento de modelo e exportação para veiculação. Os seguintes artefatos também são produzidos, conforme mostrado na próxima seção:
-
saved_model.pb: representa o gráfico do TensorFlow que inclui a lógica de transformação (o gráficotransform_fn), que deve ser anexado à interface de serviço do modelo para transformar os pontos de dados brutos no formato transformado. -
variables: inclui as estatísticas calculadas durante a fase de análise dos dados de treinamento e é usada na lógica de transformação no artefatosaved_model.pb. -
assets: inclui arquivos de vocabulário, um para cada recurso categórico processado com o métodocompute_and_apply_vocabulary, para serem usados durante o serviço para converter um valor nominal bruto de entrada em um índice numérico. -
transformed_metadata: um diretório que contém o arquivoschema.jsonque descreve o esquema dos dados transformados.
Execute o pipeline no Dataflow
Depois de definir o pipeline tf.Transform , execute-o usando o Dataflow. O diagrama a seguir, figura 4, mostra o gráfico de execução do Dataflow do pipeline tf.Transform descrito no exemplo.
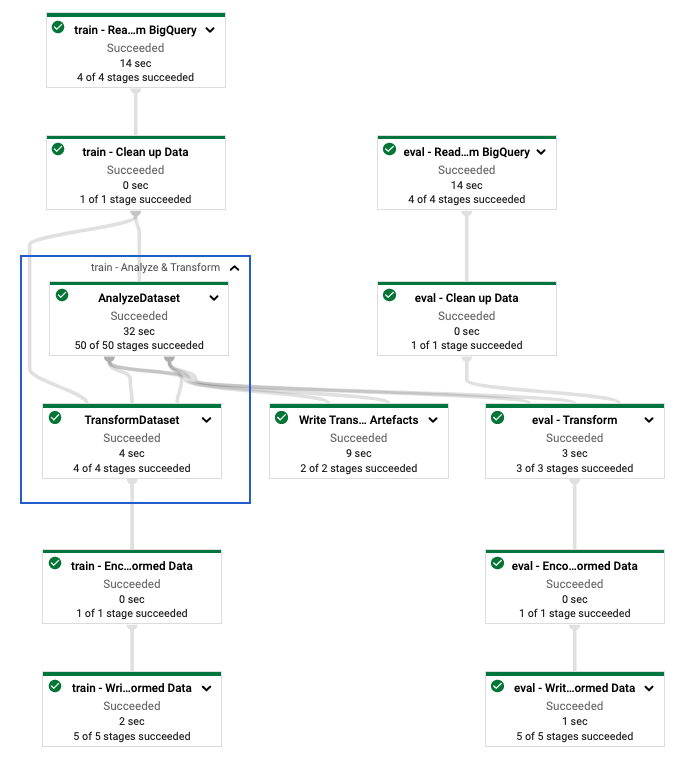
tf.Transform . Depois de executar o pipeline do Dataflow para pré-processar os dados de treinamento e avaliação, você poderá explorar os objetos produzidos no Cloud Storage executando a última célula do notebook. Os snippets de código nesta seção mostram os resultados, onde YOUR_BUCKET_NAME é o nome do seu bucket do Cloud Storage.
Os dados de treinamento e avaliação transformados no formato TFRecord são armazenados no seguinte local:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
Os artefatos de transformação são produzidos no seguinte local:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
A lista a seguir é a saída do pipeline, mostrando os objetos de dados e artefatos produzidos:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
Implementar o modelo TensorFlow
Esta seção e a próxima seção, Treinar e usar o modelo para previsões , fornecem uma visão geral e o contexto do Caderno 2. O caderno fornece um modelo de ML de exemplo para prever pesos de bebês. Neste exemplo, um modelo do TensorFlow é implementado usando a API Keras. O modelo usa os dados e artefatos produzidos pelo pipeline de pré-processamento tf.Transform explicado anteriormente.
Execute o Caderno 2
Na interface do JupyterLab, clique em Arquivo > Abrir do caminho e insira o seguinte caminho:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbClique em Editar > Limpar todas as saídas .
Na seção Instalar pacotes necessários , execute a primeira célula para executar o comando
pip install tensorflow-transform.A última parte da saída é a seguinte:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.Você pode ignorar erros de dependência na saída.
No menu Kernel , selecione Reiniciar Kernel .
Execute as células nas seções Confirmar os pacotes instalados e Criar setup.py para instalar pacotes nos contêineres do Dataflow .
Na seção Definir sinalizadores globais , ao lado de
PROJECTeBUCKET, substituayour-projectpelo ID do projeto do Cloud e execute a célula.Execute todas as células restantes até a última célula do notebook. Para obter informações sobre o que fazer em cada célula, consulte as instruções no caderno.
Visão geral da criação do modelo
As etapas para criar o modelo são as seguintes:
- Crie colunas de recursos usando as informações de esquema armazenadas no diretório
transformed_metadata. - Crie o modelo amplo e profundo com a API Keras usando as colunas de recursos como entrada para o modelo.
- Crie a função
tfrecords_input_fnpara ler e analisar os dados de treinamento e avaliação usando os artefatos de transformação. - Treine e avalie o modelo.
- Exporte o modelo treinado definindo uma função
serving_fnque possui o gráficotransform_fnanexado a ela. - Inspecione o modelo exportado usando a ferramenta
saved_model_cli. - Use o modelo exportado para previsão.
Este documento não explica como construir o modelo, portanto não discute detalhadamente como o modelo foi construído ou treinado. No entanto, as seções a seguir mostram como as informações armazenadas no diretório transform_metadata — que é produzido pelo processo tf.Transform — são usadas para criar as colunas de recursos do modelo. O documento também mostra como o gráfico transform_fn – que também é produzido pelo processo tf.Transform – é usado na função serving_fn quando o modelo é exportado para veiculação.
Use os artefatos de transformação gerados no treinamento do modelo
Ao treinar o modelo do TensorFlow, você usa os objetos train e eval transformados produzidos na etapa anterior de processamento de dados. Esses objetos são armazenados como arquivos fragmentados no formato TFRecord. As informações de esquema no diretório transformed_metadata gerado na etapa anterior podem ser úteis na análise dos dados (objetos tf.train.Example ) para alimentar o modelo para treinamento e avaliação.
Analise os dados
Como você lê arquivos no formato TFRecord para alimentar o modelo com dados de treinamento e avaliação, é necessário analisar cada objeto tf.train.Example nos arquivos para criar um dicionário de recursos (tensores). Isso garante que os recursos sejam mapeados para a camada de entrada do modelo usando as colunas de recursos, que atuam como interface de treinamento e avaliação do modelo. Para analisar os dados, use o objeto TFTransformOutput criado a partir dos artefatos gerados na etapa anterior:
Crie um objeto
TFTransformOutputa partir dos artefatos gerados e salvos na etapa de pré-processamento anterior, conforme descrito na seção Salvar o gráfico :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Extraia um objeto
feature_specdo objetoTFTransformOutput:tf_transform_output.transformed_feature_spec()Use o objeto
feature_specpara especificar os recursos contidos no objetotf.train.Examplecomo na funçãotfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
Crie as colunas de recursos
O pipeline produz as informações de esquema no diretório transformed_metadata que descreve o esquema dos dados transformados esperados pelo modelo para treinamento e avaliação. O esquema contém o nome do recurso e o tipo de dados, como este:
-
gestation_weeks_scaled(tipo:FLOAT) -
is_male_index(tipo:INT, is_categorical:True) -
is_multiple_index(tipo:INT, is_categorical:True) -
mother_age_bucketized(tipo:INT, is_categorical:True) -
mother_age_log(tipo:FLOAT) -
mother_age_normalized(tipo:FLOAT) -
mother_race_index(tipo:INT, is_categorical:True) -
weight_pounds(tipo:FLOAT)
Para ver essas informações, use os seguintes comandos:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
O código a seguir mostra como você usa o nome do recurso para criar colunas de recursos:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
O código cria uma coluna tf.feature_column.numeric_column para recursos numéricos e uma coluna tf.feature_column.categorical_column_with_identity para recursos categóricos.
Você também pode criar colunas de recursos estendidos, conforme descrito na Opção C: TensorFlow na primeira parte desta série. No exemplo usado para esta série, um novo recurso é criado, mother_race_X_mother_age_bucketized , cruzando os recursos mother_race e mother_age_bucketized usando a coluna de recurso tf.feature_column.crossed_column . A representação densa e de baixa dimensão desse recurso cruzado é criada usando a coluna de recurso tf.feature_column.embedding_column .
O diagrama a seguir, figura 5, mostra os dados transformados e como os metadados transformados são usados para definir e treinar o modelo TensorFlow:

Exporte o modelo para veicular previsão
Depois de treinar o modelo do TensorFlow com a API Keras, você exporta o modelo treinado como um objeto SavedModel, para que ele possa servir novos pontos de dados para previsão. Ao exportar o modelo, você deve definir sua interface, ou seja, o esquema de recursos de entrada esperado durante a veiculação. Este esquema de recursos de entrada é definido na função serving_fn , conforme mostrado no código a seguir:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
Durante a veiculação, o modelo espera os pontos de dados em sua forma bruta (ou seja, recursos brutos antes das transformações). Portanto, a função serving_fn recebe os recursos brutos e os armazena em um objeto features como um dicionário Python. No entanto, conforme discutido anteriormente, o modelo treinado espera os pontos de dados no esquema transformado. Para converter os recursos brutos nos objetos transformed_features esperados pela interface do modelo, aplique o gráfico transform_fn salvo ao objeto features com as seguintes etapas:
Crie o objeto
TFTransformOutputa partir dos artefatos gerados e salvos na etapa de pré-processamento anterior:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Crie um objeto
TransformFeaturesLayera partir do objetoTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()Aplique o gráfico
transform_fnusando o objetoTransformFeaturesLayer:transformed_features = model.tft_layer(features)
O diagrama a seguir, figura 6, ilustra a etapa final da exportação de um modelo para veiculação:

transform_fn anexado. Treine e use o modelo para previsões
Você pode treinar o modelo localmente executando as células do notebook. Para ver exemplos de como empacotar o código e treinar seu modelo em escala usando o Vertex AI Training, consulte os exemplos e guias no repositório GitHub de exemplos de nuvem do Google Cloud.
Ao inspecionar o objeto SavedModel exportado usando a ferramenta saved_model_cli , você verá que os elementos inputs da definição de assinatura signature_def incluem os recursos brutos, conforme mostrado no exemplo a seguir:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
As células restantes do notebook mostram como usar o modelo exportado para uma previsão local e como implantar o modelo como um microsserviço usando o Vertex AI Prediction. É importante destacar que o ponto de dados de entrada (amostra) está no esquema bruto em ambos os casos.
Limpar
Para evitar cobranças adicionais na sua conta do Google Cloud pelos recursos usados neste tutorial, exclua o projeto que contém os recursos.
Exclua o projeto
No console do Google Cloud, acesse a página Gerenciar recursos .
Na lista de projetos, selecione o projeto que deseja excluir e clique em Excluir .
Na caixa de diálogo, digite o ID do projeto e clique em Desligar para excluir o projeto.
O que vem a seguir
- Para saber mais sobre os conceitos, desafios e opções de pré-processamento de dados para aprendizado de máquina no Google Cloud, consulte o primeiro artigo desta série, Pré-processamento de dados para ML: opções e recomendações .
- Para obter mais informações sobre como implementar, empacotar e executar um pipeline tf.Transform no Dataflow, consulte o exemplo Predição de renda com conjunto de dados do censo .
- Faça a especialização do Coursera em ML com TensorFlow no Google Cloud .
- Aprenda sobre as práticas recomendadas para engenharia de ML em Regras de ML .
- Para obter mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Cloud Architecture Center .