
Descripción general
TensorFlow Model Analysis (TFMA) es una biblioteca para realizar evaluaciones de modelos.
- Para : ingenieros de aprendizaje automático o científicos de datos
- quién : quiere analizar y comprender sus modelos de TensorFlow
- es : una biblioteca independiente o un componente de una canalización TFX
- que : evalúa modelos sobre grandes cantidades de datos de forma distribuida según las mismas métricas definidas en el entrenamiento. Estas métricas se comparan en porciones de datos y se visualizan en cuadernos de Jupyter o Colab.
- a diferencia : algunas herramientas de introspección de modelos como tensorboard que ofrecen introspección de modelos
TFMA realiza sus cálculos de forma distribuida sobre grandes cantidades de datos utilizando Apache Beam . Las siguientes secciones describen cómo configurar un proceso de evaluación TFMA básico. Consulte la arquitectura para obtener más detalles sobre la implementación subyacente.
Si solo desea comenzar y comenzar, consulte nuestro cuaderno de colaboración .
Esta página también se puede ver desde tensorflow.org .
Tipos de modelos admitidos
TFMA está diseñado para admitir modelos basados en tensorflow, pero se puede ampliar fácilmente para admitir también otros marcos. Históricamente, TFMA requería la creación de un EvalSavedModel para usar TFMA, pero la última versión de TFMA admite múltiples tipos de modelos según las necesidades del usuario. Solo debería ser necesario configurar un EvalSavedModel si se utiliza un modelo basado en tf.estimator y se requieren métricas de tiempo de entrenamiento personalizadas.
Tenga en cuenta que debido a que TFMA ahora se ejecuta según el modelo de publicación, TFMA ya no evaluará automáticamente las métricas agregadas en el momento del entrenamiento. La excepción a este caso es si se utiliza un modelo de Keras, ya que Keras guarda las métricas utilizadas junto con el modelo guardado. Sin embargo, si este es un requisito estricto, el TFMA más reciente es compatible con versiones anteriores, de modo que aún se puede ejecutar un EvalSavedModel en una canalización TFMA.
La siguiente tabla resume los modelos admitidos de forma predeterminada:
| Tipo de modelo | Métricas de tiempo de entrenamiento | Métricas posteriores a la capacitación |
|---|---|---|
| TF2 (keras) | Sí* | Y |
| TF2 (genérico) | N / A | Y |
| EvalSavedModel (estimador) | Y | Y |
| Ninguno (pd.DataFrame, etc.) | N / A | Y |
- Las métricas de tiempo de entrenamiento se refieren a métricas definidas en el momento del entrenamiento y guardadas con el modelo (ya sea TFMA EvalSavedModel o el modelo guardado de Keras). Las métricas posteriores al entrenamiento se refieren a las métricas agregadas a través de
tfma.MetricConfig. - Los modelos genéricos TF2 son modelos personalizados que exportan firmas que pueden usarse para inferencia y no se basan ni en keras ni en estimadores.
Consulte las preguntas frecuentes para obtener más información sobre cómo instalar y configurar estos diferentes tipos de modelos.
Configuración
Antes de ejecutar una evaluación, se requiere una pequeña configuración. Primero, se debe definir un objeto tfma.EvalConfig que proporcione especificaciones para el modelo, las métricas y los sectores que se van a evaluar. En segundo lugar, es necesario crear un tfma.EvalSharedModel que apunte al modelo (o modelos) real que se utilizará durante la evaluación. Una vez definidos, la evaluación se realiza llamando tfma.run_model_analysis con un conjunto de datos apropiado. Para obtener más detalles, consulte la guía de configuración .
Si se ejecuta dentro de una canalización TFX, consulte la guía TFX para saber cómo configurar TFMA para que se ejecute como un componente TFX Evaluator .
Ejemplos
Evaluación de modelo único
A continuación se utiliza tfma.run_model_analysis para realizar una evaluación en un modelo de servicio. Para obtener una explicación de las diferentes configuraciones necesarias, consulte la guía de configuración .
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
Para una evaluación distribuida, construya una canalización de Apache Beam utilizando un ejecutor distribuido. En el proceso, utilice tfma.ExtractEvaluateAndWriteResults para evaluar y escribir los resultados. Los resultados se pueden cargar para visualización usando tfma.load_eval_result .
Por ejemplo:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
Validación del modelo
Para realizar la validación del modelo con un candidato y una línea de base, actualice la configuración para incluir una configuración de umbral y pase dos modelos a tfma.run_model_analysis .
Por ejemplo:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
Visualización
Los resultados de la evaluación de TFMA se pueden visualizar en un cuaderno Jupyter utilizando los componentes de interfaz incluidos en TFMA. Por ejemplo:
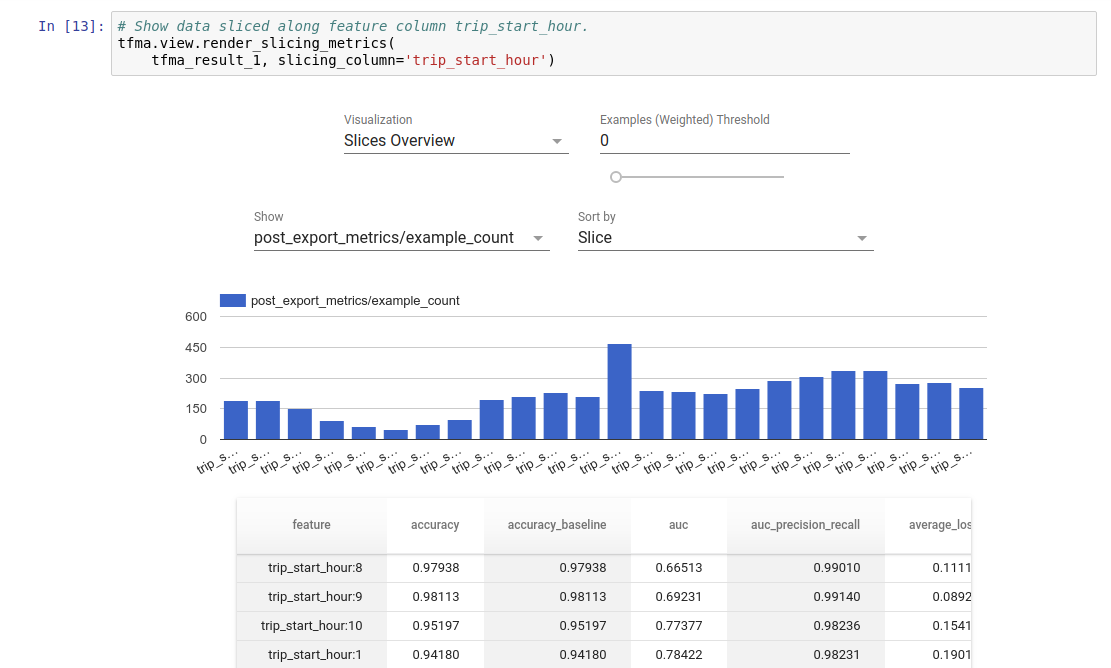 .
.