
Ringkasan
TensorFlow Model Analysis (TFMA) adalah perpustakaan untuk melakukan evaluasi model.
- Untuk : Insinyur Pembelajaran Mesin atau Ilmuwan Data
- who : ingin menganalisis dan memahami model TensorFlow mereka
- itu adalah : perpustakaan mandiri atau komponen pipa TFX
- bahwa : mengevaluasi model pada data dalam jumlah besar secara terdistribusi pada metrik yang sama yang ditentukan dalam pelatihan. Metrik ini dibandingkan pada potongan data, dan divisualisasikan dalam notebook Jupyter atau Colab.
- tidak seperti : beberapa alat introspeksi model seperti tensorboard yang menawarkan introspeksi model
TFMA melakukan penghitungannya secara terdistribusi pada data dalam jumlah besar menggunakan Apache Beam . Bagian berikut menjelaskan cara menyiapkan alur evaluasi TFMA dasar. Lihat arsitektur lebih detail tentang implementasi yang mendasarinya.
Jika Anda hanya ingin langsung terjun dan memulai, lihat buku catatan colab kami.
Halaman ini juga dapat dilihat dari tensorflow.org .
Jenis Model yang Didukung
TFMA dirancang untuk mendukung model berbasis tensorflow, namun dapat dengan mudah diperluas untuk mendukung kerangka kerja lain juga. Secara historis, TFMA memerlukan EvalSavedModel dibuat untuk menggunakan TFMA, namun versi terbaru TFMA mendukung beberapa jenis model bergantung pada kebutuhan pengguna. Menyiapkan EvalSavedModel hanya diperlukan jika model berbasis tf.estimator digunakan dan metrik waktu pelatihan khusus diperlukan.
Perhatikan bahwa karena TFMA sekarang berjalan berdasarkan model penyajian, TFMA tidak lagi secara otomatis mengevaluasi metrik yang ditambahkan pada waktu pelatihan. Pengecualian untuk kasus ini adalah jika model keras digunakan karena keras menyimpan metrik yang digunakan bersama model yang disimpan. Namun, jika ini merupakan persyaratan yang sulit, TFMA terbaru kompatibel sehingga EvalSavedModel masih dapat dijalankan dalam alur TFMA.
Tabel berikut merangkum model yang didukung secara default:
| Tipe Model | Metrik Waktu Pelatihan | Metrik Pasca Pelatihan |
|---|---|---|
| TF2 (keras) | kamu* | Y |
| TF2 (generik) | T/A | Y |
| EvalSavedModel (penaksir) | Y | Y |
| Tidak ada (pd.DataFrame, dll) | T/A | Y |
- Metrik Waktu Pelatihan mengacu pada metrik yang ditentukan pada waktu pelatihan dan disimpan dengan model (baik TFMA EvalSavedModel atau model yang disimpan dengan keras). Metrik pasca pelatihan mengacu pada metrik yang ditambahkan melalui
tfma.MetricConfig. - Model TF2 generik adalah model khusus yang mengekspor tanda tangan yang dapat digunakan untuk inferensi dan tidak didasarkan pada keras atau estimator.
Lihat FAQ untuk informasi lebih lanjut tentang cara menyiapkan dan mengonfigurasi berbagai jenis model ini.
Pengaturan
Sebelum menjalankan evaluasi, diperlukan sedikit pengaturan. Pertama, objek tfma.EvalConfig harus ditentukan yang menyediakan spesifikasi untuk model, metrik, dan irisan yang akan dievaluasi. Kedua, tfma.EvalSharedModel perlu dibuat yang menunjuk ke model (atau model) aktual yang akan digunakan selama evaluasi. Setelah ini ditentukan, evaluasi dilakukan dengan memanggil tfma.run_model_analysis dengan kumpulan data yang sesuai. Untuk lebih jelasnya, lihat panduan pengaturan .
Jika dijalankan dalam pipeline TFX, lihat panduan TFX tentang cara mengonfigurasi TFMA agar dijalankan sebagai komponen TFX Evaluator .
Contoh
Evaluasi Model Tunggal
Berikut ini penggunaan tfma.run_model_analysis untuk melakukan evaluasi pada model penyajian. Untuk penjelasan tentang berbagai pengaturan yang diperlukan, lihat panduan pengaturan .
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
Untuk evaluasi terdistribusi, buat pipeline Apache Beam menggunakan runner terdistribusi. Di dalam pipeline, gunakan tfma.ExtractEvaluateAndWriteResults untuk evaluasi dan menuliskan hasilnya. Hasilnya dapat dimuat untuk visualisasi menggunakan tfma.load_eval_result .
Misalnya:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
Validasi Model
Untuk melakukan validasi model terhadap kandidat dan baseline, perbarui konfigurasi untuk menyertakan pengaturan ambang batas dan teruskan dua model ke tfma.run_model_analysis .
Misalnya:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
Visualisasi
Hasil evaluasi TFMA dapat divisualisasikan dalam notebook Jupyter menggunakan komponen frontend yang disertakan dalam TFMA. Misalnya:
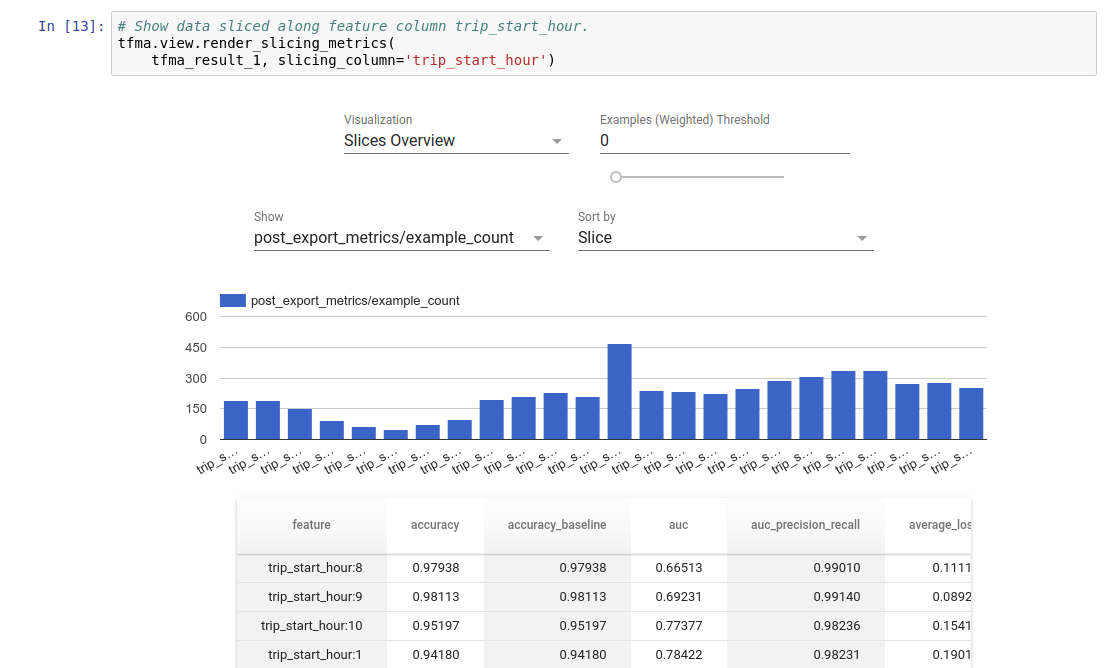 .
.