
يعتمد أداء TensorFlow Serving بشكل كبير على التطبيق الذي يعمل عليه، والبيئة التي يتم نشره فيها والبرامج الأخرى التي يشارك معها الوصول إلى موارد الأجهزة الأساسية. على هذا النحو، فإن ضبط أدائه يعتمد إلى حد ما على الحالة وهناك عدد قليل جدًا من القواعد العالمية التي تضمن تحقيق الأداء الأمثل في جميع الإعدادات. ومع ذلك، تهدف هذه الوثيقة إلى التقاط بعض المبادئ العامة وأفضل الممارسات لتشغيل خدمة TensorFlow.
يرجى استخدام دليل طلبات الاستدلال لملف التعريف مع TensorBoard لفهم السلوك الأساسي لحساب النموذج الخاص بك عند طلبات الاستدلال، واستخدام هذا الدليل لتحسين أدائه بشكل متكرر.
نصائح سريعة
- زمن الوصول للطلب الأول مرتفع جدًا؟ تمكين إحماء النموذج .
- هل أنت مهتم بزيادة استخدام الموارد أو الإنتاجية؟ تكوين الخلط
ضبط الأداء: الأهداف والمعلمات
عند ضبط أداء TensorFlow Serving، عادةً ما يكون هناك نوعان من الأهداف التي قد تكون لديك و3 مجموعات من المعلمات التي يجب تعديلها لتحسين تلك الأهداف.
أهداف
TensorFlow Serving هو نظام تقديم عبر الإنترنت للنماذج المستفادة آليًا. كما هو الحال مع العديد من أنظمة الخدمة الأخرى عبر الإنترنت، فإن هدف الأداء الأساسي الخاص بها هو زيادة الإنتاجية إلى أقصى حد مع الحفاظ على زمن الاستجابة أقل من حدود معينة . اعتمادًا على تفاصيل تطبيقك ومدى نضجه، قد تهتم بمتوسط زمن الاستجابة أكثر من زمن الوصول الخلفي ، ولكن عادةً ما تكون بعض مفاهيم زمن الوصول والإنتاجية هي المقاييس التي تحدد على أساسها أهداف الأداء. لاحظ أننا لا نناقش التوفر في هذا الدليل لأن ذلك يتعلق أكثر ببيئة النشر.
حدود
يمكننا التفكير تقريبًا في ثلاث مجموعات من المعلمات التي يحدد تكوينها الأداء الملحوظ: 1) نموذج TensorFlow 2) طلبات الاستدلال و3) الخادم (الأجهزة والثنائي).
1) نموذج TensorFlow
يحدد النموذج الحساب الذي ستجريه خدمة TensorFlow عند تلقي كل طلب وارد.
أسفل الغطاء، يستخدم TensorFlow Serving وقت تشغيل TensorFlow للقيام بالاستدلال الفعلي على طلباتك. وهذا يعني أن متوسط زمن الوصول لخدمة الطلب باستخدام TensorFlow Serving عادة ما يكون على الأقل وقت الاستدلال مباشرة باستخدام TensorFlow. هذا يعني أنه إذا كان الاستدلال على مثال واحد على جهاز معين يستغرق ثانيتين، وكان لديك هدف زمن استجابة أقل من ثانية، فأنت بحاجة إلى تحديد طلبات الاستدلال، وفهم ما تساهم به عمليات TensorFlow والرسوم البيانية الفرعية لنموذجك بشكل أكبر في زمن الاستجابة هذا ، وأعد تصميم النموذج الخاص بك مع وضع زمن الاستجابة الاستدلالي كأحد قيود التصميم في الاعتبار.
يرجى ملاحظة أنه في حين أن متوسط زمن الوصول لإجراء الاستدلال باستخدام TensorFlow Serving لا يكون عادةً أقل من استخدام TensorFlow مباشرة، حيث يتألق TensorFlow Serving في الحفاظ على زمن الاستجابة المنخفض للعديد من العملاء الذين يستعلمون عن العديد من النماذج المختلفة، كل ذلك مع استخدام الأجهزة الأساسية بكفاءة لزيادة الإنتاجية إلى أقصى حد .
2) طلبات الاستدلال
أسطح API
يحتوي TensorFlow Serving على سطحين لواجهة برمجة التطبيقات (HTTP وgRPC)، وكلاهما يطبق واجهة برمجة تطبيقات PredictionService (باستثناء خادم HTTP الذي لا يعرض نقطة نهاية MultiInference ). تم ضبط كلا سطحي واجهة برمجة التطبيقات (API) بشكل كبير ويضيفان الحد الأدنى من زمن الوصول، ولكن في الممارسة العملية، لوحظ أن سطح gRPC أكثر أداءً قليلاً.
طرق واجهة برمجة التطبيقات
بشكل عام، يُنصح باستخدام نقاط النهاية Classify وRegress لأنها تقبل tf.Example ، وهو تجريد عالي المستوى؛ ومع ذلك، في حالات نادرة للطلبات المنظمة الكبيرة (O(Mb))، قد يجد المستخدمون الأذكياء استخدام PredictRequest وترميز رسائل Protobuf الخاصة بهم مباشرة في TensorProto، وتخطي التسلسل إلى tf وإلغاء التسلسل منه. مثال على ذلك هو مصدر لزيادة طفيفة في الأداء.
حجم الدفعة
هناك طريقتان أساسيتان يمكن أن تساعدهما عملية التجميع في تحسين أدائك. يمكنك تكوين عملائك لإرسال طلبات مجمعة إلى TensorFlow Serving، أو يمكنك إرسال طلبات فردية وتكوين TensorFlow Serving للانتظار لفترة زمنية محددة مسبقًا، وإجراء الاستدلال على جميع الطلبات التي تصل في تلك الفترة دفعة واحدة. يتيح لك تكوين النوع الأخير من التجميعات الوصول إلى TensorFlow Serving بمعدل QPS مرتفع للغاية، مع السماح له بقياس موارد الحوسبة اللازمة للمواكبة بشكل فرعي. تمت مناقشة هذا بشكل أكبر في دليل التكوين وملف README المجمع .
3) الخادم (الأجهزة والثنائي)
يقوم برنامج TensorFlow Serving الثنائي بحساب دقيق إلى حد ما للأجهزة التي يعمل عليها. على هذا النحو، يجب عليك تجنب تشغيل تطبيقات أخرى كثيفة الحوسبة أو الذاكرة على نفس الجهاز، خاصة تلك التي تستخدم الموارد الديناميكية.
كما هو الحال مع العديد من أنواع أعباء العمل الأخرى، يكون TensorFlow Serving أكثر كفاءة عند نشره على أجهزة أقل وأكبر (المزيد من وحدة المعالجة المركزية وذاكرة الوصول العشوائي) (أي Deployment مع replicas أقل وفقًا لمصطلحات Kubernetes). ويرجع ذلك إلى الإمكانية الأفضل للنشر متعدد المستأجرين للاستفادة من الأجهزة وانخفاض التكاليف الثابتة (خادم RPC، ووقت تشغيل TensorFlow، وما إلى ذلك).
المسرعات
إذا كان مضيفك لديه حق الوصول إلى المسرع، فتأكد من أنك قمت بتنفيذ النموذج الخاص بك لوضع حسابات كثيفة على المسرع - يجب أن يتم ذلك تلقائيًا إذا كنت قد استخدمت واجهات برمجة التطبيقات TensorFlow عالية المستوى، ولكن إذا كنت قد أنشأت رسومًا بيانية مخصصة، أو تريد تثبيتها أجزاء معينة من الرسوم البيانية على مسرعات محددة، قد تحتاج إلى وضع رسوم بيانية فرعية معينة يدويًا على المسرعات (أي with tf.device('/device:GPU:0'): ... ).
وحدات المعالجة المركزية الحديثة
قامت وحدات المعالجة المركزية الحديثة باستمرار بتوسيع بنية مجموعة التعليمات x86 لتحسين دعم SIMD (بيانات التعليمات الفردية المتعددة) وغيرها من الميزات المهمة للحسابات الكثيفة (على سبيل المثال، الضرب والإضافة في دورة ساعة واحدة). ومع ذلك، من أجل التشغيل على أجهزة أقدم قليلاً، تم تصميم TensorFlow وTensorFlow Serving مع افتراض متواضع بأن أحدث هذه الميزات غير مدعومة من قبل وحدة المعالجة المركزية المضيفة.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
إذا رأيت إدخال السجل هذا (من المحتمل أن يكون امتدادات مختلفة عن الاثنتين المدرجتين) عند بدء تشغيل TensorFlow Serving، فهذا يعني أنه يمكنك إعادة بناء TensorFlow Serving واستهداف النظام الأساسي لمضيفك المعين والاستمتاع بأداء أفضل. يعد إنشاء خدمة TensorFlow من المصدر أمرًا سهلاً نسبيًا باستخدام Docker وتم توثيقه هنا .
التكوين الثنائي
يقدم TensorFlow Serving عددًا من مقابض التكوين التي تحكم سلوك وقت التشغيل، ويتم ضبطها في الغالب من خلال إشارات سطر الأوامر . يتم تمرير بعض هذه العناصر (أبرزها tensorflow_intra_op_parallelism و tensorflow_inter_op_parallelism ) لتكوين وقت تشغيل TensorFlow ويتم تهيئتها تلقائيًا، والتي قد يتجاوزها المستخدمون الأذكياء عن طريق إجراء العديد من التجارب والعثور على التكوين الصحيح لأعباء العمل والبيئة المحددة الخاصة بهم.
حياة طلب الاستدلال لخدمة TensorFlow
دعنا نستعرض بإيجاز حياة مثال نموذجي لطلب استدلال TensorFlow Serving لمعرفة الرحلة التي يمر بها الطلب النموذجي. على سبيل المثال، سنتعمق في طلب التنبؤ الذي يتم تلقيه بواسطة سطح واجهة برمجة التطبيقات TensorFlow Serving gRPC API 2.0.0.
دعونا نلقي نظرة أولاً على مخطط التسلسل على مستوى المكون، ثم ننتقل إلى الكود الذي ينفذ هذه السلسلة من التفاعلات.
مخطط تسلسل
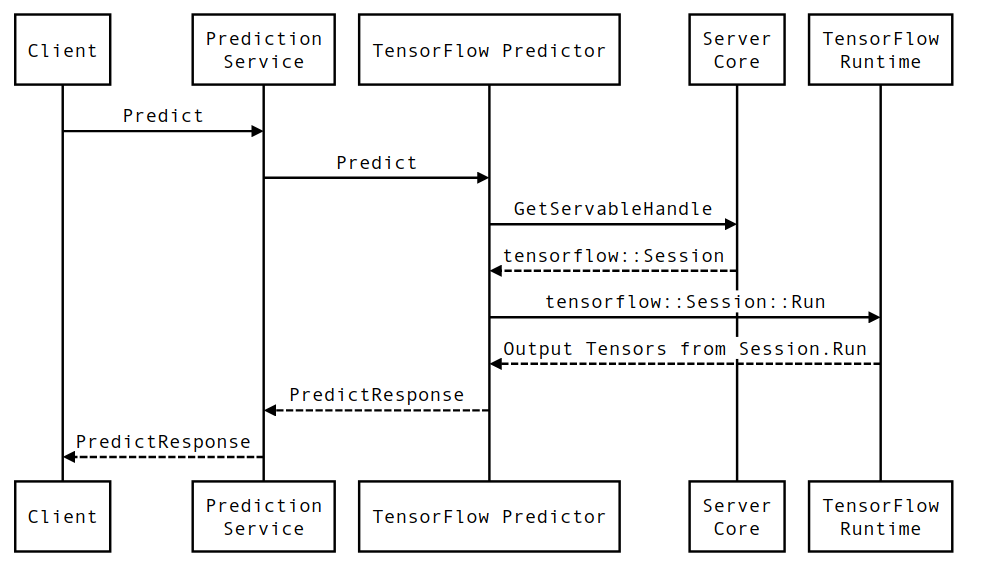
لاحظ أن العميل هو مكون مملوك للمستخدم، وخدمة التنبؤ، وServables، وServer Core مملوكة لشركة TensorFlow Serving، وTensorFlow Runtime مملوكة لشركة Core TensorFlow .
تفاصيل التسلسل
-
PredictionServiceImpl::PredictيتلقىPredictRequest - نحن نستدعي
TensorflowPredictor::Predict، وننشر الموعد النهائي للطلب من طلب gRPC (إذا تم تعيينه). - داخل
TensorflowPredictor::Predict، نقوم بالبحث عن (النموذج) القابل للخدمة الذي يبحث عنه الطلب لإجراء الاستدلال عليه، والذي نسترجع منه معلومات حول SavedModel والأهم من ذلك، مؤشر إلى كائنSessionالذي يوجد فيه الرسم البياني للنموذج (ربما جزئيًا) محمل. تم إنشاء هذا الكائن القابل للعرض والالتزام به في الذاكرة عندما تم تحميل النموذج بواسطة TensorFlow Serving. نقوم بعد ذلك باستدعاء داخلي::RunPredict لتنفيذ التنبؤ. - في
internal::RunPredict، بعد التحقق من صحة الطلب ومعالجته مسبقًا، نستخدم كائنSessionلإجراء الاستدلال باستخدام استدعاء حظر لـ Session::Run ، وعند هذه النقطة، ندخل قاعدة بيانات TensorFlow الأساسية. بعد إرجاعSession::Runوملء موتراتoutputs، نقوم بتحويل المخرجات إلىPredictionResponseونعيد النتيجة إلى مكدس الاستدعاءات.