
| |
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
本教程演示了如何使用 UCF101 动作识别数据集训练一个用于视频分类的 3D 卷积神经网络。3D CNN 使用三维过滤器来执行卷积。内核能够在三个维度上滑动,而在 2D CNN 中,它可以在两个维度上滑动。此模型基于 D. Tran 等人在 A Closer Look at Spatiotemporal Convolutions for Action Recognition(2017 年)中发表的工作。在本教程中,您将完成以下任务:
- 构建输入流水线
- 使用 Keras 函数式 API 构建具有残差连接的 3D 卷积神经网络模型
- 训练模型
- 评估和测试模型
安装
首先,安装和导入一些必要的库,包括:用于检查 ZIP 文件内容的 remotezip,用于使用进度条的 tqdm,用于处理视频文件的 OpenCV,用于执行更复杂张量运算的 einops,以及用于在 Jupyter 笔记本中嵌入数据的 tensorflow_docs。
pip install remotezip tqdm opencv-python einopsimport tqdm
import random
import pathlib
import itertools
import collections
import cv2
import einops
import numpy as np
import remotezip as rz
import seaborn as sns
import matplotlib.pyplot as plt
import tensorflow as tf
import keras
from keras import layers
2023-11-07 18:08:39.970660: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-11-07 18:08:39.970710: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-11-07 18:08:39.972243: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
加载并预处理视频数据
下面的隐藏单元定义了从 UCF-101 数据集下载数据切片并将其加载到 tf.data.Dataset 中的函数。可以在加载视频数据教程中详细了解特定的预处理步骤,此教程将更详细地介绍此代码。
def list_files_per_class(zip_url):
"""
List the files in each class of the dataset given the zip URL.
Args:
zip_url: URL from which the files can be unzipped.
Return:
files: List of files in each of the classes.
"""
files = []
with rz.RemoteZip(URL) as zip:
for zip_info in zip.infolist():
files.append(zip_info.filename)
return files
def get_class(fname):
"""
Retrieve the name of the class given a filename.
Args:
fname: Name of the file in the UCF101 dataset.
Return:
Class that the file belongs to.
"""
return fname.split('_')[-3]
def get_files_per_class(files):
"""
Retrieve the files that belong to each class.
Args:
files: List of files in the dataset.
Return:
Dictionary of class names (key) and files (values).
"""
files_for_class = collections.defaultdict(list)
for fname in files:
class_name = get_class(fname)
files_for_class[class_name].append(fname)
return files_for_class
def download_from_zip(zip_url, to_dir, file_names):
"""
Download the contents of the zip file from the zip URL.
Args:
zip_url: Zip URL containing data.
to_dir: Directory to download data to.
file_names: Names of files to download.
"""
with rz.RemoteZip(zip_url) as zip:
for fn in tqdm.tqdm(file_names):
class_name = get_class(fn)
zip.extract(fn, str(to_dir / class_name))
unzipped_file = to_dir / class_name / fn
fn = pathlib.Path(fn).parts[-1]
output_file = to_dir / class_name / fn
unzipped_file.rename(output_file,)
def split_class_lists(files_for_class, count):
"""
Returns the list of files belonging to a subset of data as well as the remainder of
files that need to be downloaded.
Args:
files_for_class: Files belonging to a particular class of data.
count: Number of files to download.
Return:
split_files: Files belonging to the subset of data.
remainder: Dictionary of the remainder of files that need to be downloaded.
"""
split_files = []
remainder = {}
for cls in files_for_class:
split_files.extend(files_for_class[cls][:count])
remainder[cls] = files_for_class[cls][count:]
return split_files, remainder
def download_ufc_101_subset(zip_url, num_classes, splits, download_dir):
"""
Download a subset of the UFC101 dataset and split them into various parts, such as
training, validation, and test.
Args:
zip_url: Zip URL containing data.
num_classes: Number of labels.
splits: Dictionary specifying the training, validation, test, etc. (key) division of data
(value is number of files per split).
download_dir: Directory to download data to.
Return:
dir: Posix path of the resulting directories containing the splits of data.
"""
files = list_files_per_class(zip_url)
for f in files:
tokens = f.split('/')
if len(tokens) <= 2:
files.remove(f) # Remove that item from the list if it does not have a filename
files_for_class = get_files_per_class(files)
classes = list(files_for_class.keys())[:num_classes]
for cls in classes:
new_files_for_class = files_for_class[cls]
random.shuffle(new_files_for_class)
files_for_class[cls] = new_files_for_class
# Only use the number of classes you want in the dictionary
files_for_class = {x: files_for_class[x] for x in list(files_for_class)[:num_classes]}
dirs = {}
for split_name, split_count in splits.items():
print(split_name, ":")
split_dir = download_dir / split_name
split_files, files_for_class = split_class_lists(files_for_class, split_count)
download_from_zip(zip_url, split_dir, split_files)
dirs[split_name] = split_dir
return dirs
def format_frames(frame, output_size):
"""
Pad and resize an image from a video.
Args:
frame: Image that needs to resized and padded.
output_size: Pixel size of the output frame image.
Return:
Formatted frame with padding of specified output size.
"""
frame = tf.image.convert_image_dtype(frame, tf.float32)
frame = tf.image.resize_with_pad(frame, *output_size)
return frame
def frames_from_video_file(video_path, n_frames, output_size = (224,224), frame_step = 15):
"""
Creates frames from each video file present for each category.
Args:
video_path: File path to the video.
n_frames: Number of frames to be created per video file.
output_size: Pixel size of the output frame image.
Return:
An NumPy array of frames in the shape of (n_frames, height, width, channels).
"""
# Read each video frame by frame
result = []
src = cv2.VideoCapture(str(video_path))
video_length = src.get(cv2.CAP_PROP_FRAME_COUNT)
need_length = 1 + (n_frames - 1) * frame_step
if need_length > video_length:
start = 0
else:
max_start = video_length - need_length
start = random.randint(0, max_start + 1)
src.set(cv2.CAP_PROP_POS_FRAMES, start)
# ret is a boolean indicating whether read was successful, frame is the image itself
ret, frame = src.read()
result.append(format_frames(frame, output_size))
for _ in range(n_frames - 1):
for _ in range(frame_step):
ret, frame = src.read()
if ret:
frame = format_frames(frame, output_size)
result.append(frame)
else:
result.append(np.zeros_like(result[0]))
src.release()
result = np.array(result)[..., [2, 1, 0]]
return result
class FrameGenerator:
def __init__(self, path, n_frames, training = False):
""" Returns a set of frames with their associated label.
Args:
path: Video file paths.
n_frames: Number of frames.
training: Boolean to determine if training dataset is being created.
"""
self.path = path
self.n_frames = n_frames
self.training = training
self.class_names = sorted(set(p.name for p in self.path.iterdir() if p.is_dir()))
self.class_ids_for_name = dict((name, idx) for idx, name in enumerate(self.class_names))
def get_files_and_class_names(self):
video_paths = list(self.path.glob('*/*.avi'))
classes = [p.parent.name for p in video_paths]
return video_paths, classes
def __call__(self):
video_paths, classes = self.get_files_and_class_names()
pairs = list(zip(video_paths, classes))
if self.training:
random.shuffle(pairs)
for path, name in pairs:
video_frames = frames_from_video_file(path, self.n_frames)
label = self.class_ids_for_name[name] # Encode labels
yield video_frames, label
URL = 'https://storage.googleapis.com/thumos14_files/UCF101_videos.zip'
download_dir = pathlib.Path('./UCF101_subset/')
subset_paths = download_ufc_101_subset(URL,
num_classes = 10,
splits = {"train": 30, "val": 10, "test": 10},
download_dir = download_dir)
train : 100%|██████████| 300/300 [00:34<00:00, 8.77it/s] val : 100%|██████████| 100/100 [00:12<00:00, 8.18it/s] test : 100%|██████████| 100/100 [00:12<00:00, 8.30it/s]
创建训练集、验证集和测试集(train_ds、val_ds 和 test_ds)。
output_signature = (tf.TensorSpec(shape = (None, None, None, 3), dtype = tf.float32),
tf.TensorSpec(shape = (), dtype = tf.int16))
train_ds = tf.data.Dataset.from_generator(FrameGenerator(subset_paths['train'], 10, training = True),
output_signature = output_signature)
# Batch the data
train_ds = train_ds.batch(8)
val_ds = tf.data.Dataset.from_generator(FrameGenerator(subset_paths['val'], 10),
output_signature = output_signature)
val_ds = val_ds.batch(8)
test_ds = tf.data.Dataset.from_generator(FrameGenerator(subset_paths['test'], 10),
output_signature = output_signature)
test_ds = test_ds.batch(8)
创建模型
以下 3D 卷积神经网络模型基于 D. Tran 等人的论文 A Closer Look at Spatiotemporal Convolutions for Action Recognition(2017 年)。这篇论文比较了数个版本的 3D ResNet。与标准 ResNet 一样,它们并非对具有维度 (height, width) 的单个图像进行运算,而是对视频体积 (time, height, width) 进行运算。解决这一问题的最明显方式是将每个 2D 卷积 (layers.Conv2D) 替换为 3D 卷积 (layers.Conv3D)。
本教程使用具有残差连接的 (2 + 1)D 卷积。(2 + 1)D 卷积允许对空间和时间维度进行分解,进而创建两个单独的步骤。这种方式的一个优势在于,将卷积因式分解为空间和时间维度有助于节省参数。
对于每个输出位置,3D 卷积将体积的 3D 补丁中的所有向量组合在一起,以在输出体积中创建一个向量。
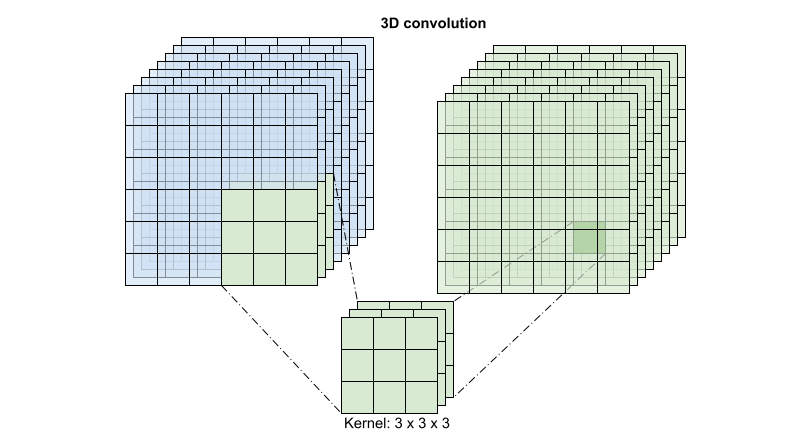
此运算需要 time * height * width * channels 个输入并产生 channels 个输出(假设输入和输出通道的数量相同。这样,内核大小为 (3 x 3 x 3) 的 3D 卷积层需要一个具有 27 * channels ** 2 个条目的权重矩阵。根据参考论文的发现,更有效且高效的方式是对卷积进行因式分解。他们提出了一个 (2+1)D 卷积来分别处理空间和时间维度,而不是用单个 3D 卷积来处理时间和空间维度。下图显示了一个 (2 + 1)D 卷积因式分解后的空间和时间卷积。
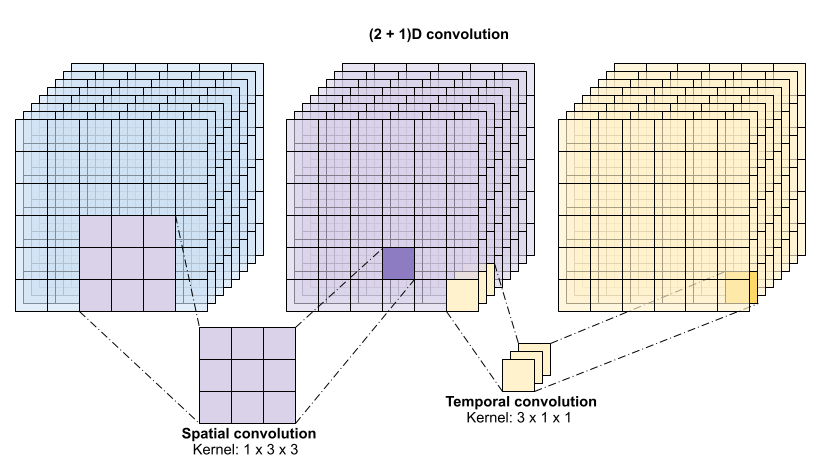
这种方式的主要优点是减少了参数数量。在 (2 + 1)D 卷积中,空间卷积接受形状为 (1, width, height) 的数据,而时间卷积接受形状为 (time, 1, 1) 的数据。例如,内核大小为 (3 x 3 x 3) 的 (2 + 1)D 卷积需要大小为 (9 * channels**2) + (3 * channels**2) 的权重矩阵,不到完整 3D 卷积的一半。本教程实现了 (2 + 1)D ResNet18,其中 ResNet 中的每个卷积都被替换为 (2+1)D 卷积。
# Define the dimensions of one frame in the set of frames created
HEIGHT = 224
WIDTH = 224
class Conv2Plus1D(keras.layers.Layer):
def __init__(self, filters, kernel_size, padding):
"""
A sequence of convolutional layers that first apply the convolution operation over the
spatial dimensions, and then the temporal dimension.
"""
super().__init__()
self.seq = keras.Sequential([
# Spatial decomposition
layers.Conv3D(filters=filters,
kernel_size=(1, kernel_size[1], kernel_size[2]),
padding=padding),
# Temporal decomposition
layers.Conv3D(filters=filters,
kernel_size=(kernel_size[0], 1, 1),
padding=padding)
])
def call(self, x):
return self.seq(x)
ResNet 模型由一系列残差块组成。一个残差块有两个分支。主分支执行计算,但难以让梯度流过。残差分支绕过主计算,大部分只是将输入添加到主分支的输出中。梯度很容易流过此分支。因此,将存在从损失函数到任何残差块的主分支的简单路径。这有助于避免梯度消失的问题。
使用以下类创建残差块的主分支。与标准 ResNet 结构相比,它使用自定义的 Conv2Plus1D 层而不是 layers.Conv2D。
class ResidualMain(keras.layers.Layer):
"""
Residual block of the model with convolution, layer normalization, and the
activation function, ReLU.
"""
def __init__(self, filters, kernel_size):
super().__init__()
self.seq = keras.Sequential([
Conv2Plus1D(filters=filters,
kernel_size=kernel_size,
padding='same'),
layers.LayerNormalization(),
layers.ReLU(),
Conv2Plus1D(filters=filters,
kernel_size=kernel_size,
padding='same'),
layers.LayerNormalization()
])
def call(self, x):
return self.seq(x)
要将残差分支添加到主分支,它需要具有相同的大小。下面的 Project 层处理分支上通道数发生变化的情况。特别是,添加了一系列密集连接层,然后添加了归一化。
class Project(keras.layers.Layer):
"""
Project certain dimensions of the tensor as the data is passed through different
sized filters and downsampled.
"""
def __init__(self, units):
super().__init__()
self.seq = keras.Sequential([
layers.Dense(units),
layers.LayerNormalization()
])
def call(self, x):
return self.seq(x)
使用 add_residual_block 在模型的各层之间引入跳跃连接。
def add_residual_block(input, filters, kernel_size):
"""
Add residual blocks to the model. If the last dimensions of the input data
and filter size does not match, project it such that last dimension matches.
"""
out = ResidualMain(filters,
kernel_size)(input)
res = input
# Using the Keras functional APIs, project the last dimension of the tensor to
# match the new filter size
if out.shape[-1] != input.shape[-1]:
res = Project(out.shape[-1])(res)
return layers.add([res, out])
必须调整视频大小才能执行数据的下采样。特别是,对视频帧进行下采样允许模型检查帧的特定部分,以检测可能特定于某个动作的模式。通过下采样,可以丢弃非必要信息。此外,调整视频大小将允许降维,从而加快模型的处理速度。
class ResizeVideo(keras.layers.Layer):
def __init__(self, height, width):
super().__init__()
self.height = height
self.width = width
self.resizing_layer = layers.Resizing(self.height, self.width)
def call(self, video):
"""
Use the einops library to resize the tensor.
Args:
video: Tensor representation of the video, in the form of a set of frames.
Return:
A downsampled size of the video according to the new height and width it should be resized to.
"""
# b stands for batch size, t stands for time, h stands for height,
# w stands for width, and c stands for the number of channels.
old_shape = einops.parse_shape(video, 'b t h w c')
images = einops.rearrange(video, 'b t h w c -> (b t) h w c')
images = self.resizing_layer(images)
videos = einops.rearrange(
images, '(b t) h w c -> b t h w c',
t = old_shape['t'])
return videos
使用 Keras 函数式 API 构建残差网络。
input_shape = (None, 10, HEIGHT, WIDTH, 3)
input = layers.Input(shape=(input_shape[1:]))
x = input
x = Conv2Plus1D(filters=16, kernel_size=(3, 7, 7), padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = ResizeVideo(HEIGHT // 2, WIDTH // 2)(x)
# Block 1
x = add_residual_block(x, 16, (3, 3, 3))
x = ResizeVideo(HEIGHT // 4, WIDTH // 4)(x)
# Block 2
x = add_residual_block(x, 32, (3, 3, 3))
x = ResizeVideo(HEIGHT // 8, WIDTH // 8)(x)
# Block 3
x = add_residual_block(x, 64, (3, 3, 3))
x = ResizeVideo(HEIGHT // 16, WIDTH // 16)(x)
# Block 4
x = add_residual_block(x, 128, (3, 3, 3))
x = layers.GlobalAveragePooling3D()(x)
x = layers.Flatten()(x)
x = layers.Dense(10)(x)
model = keras.Model(input, x)
frames, label = next(iter(train_ds))
model.build(frames)
# Visualize the model
keras.utils.plot_model(model, expand_nested=True, dpi=60, show_shapes=True)
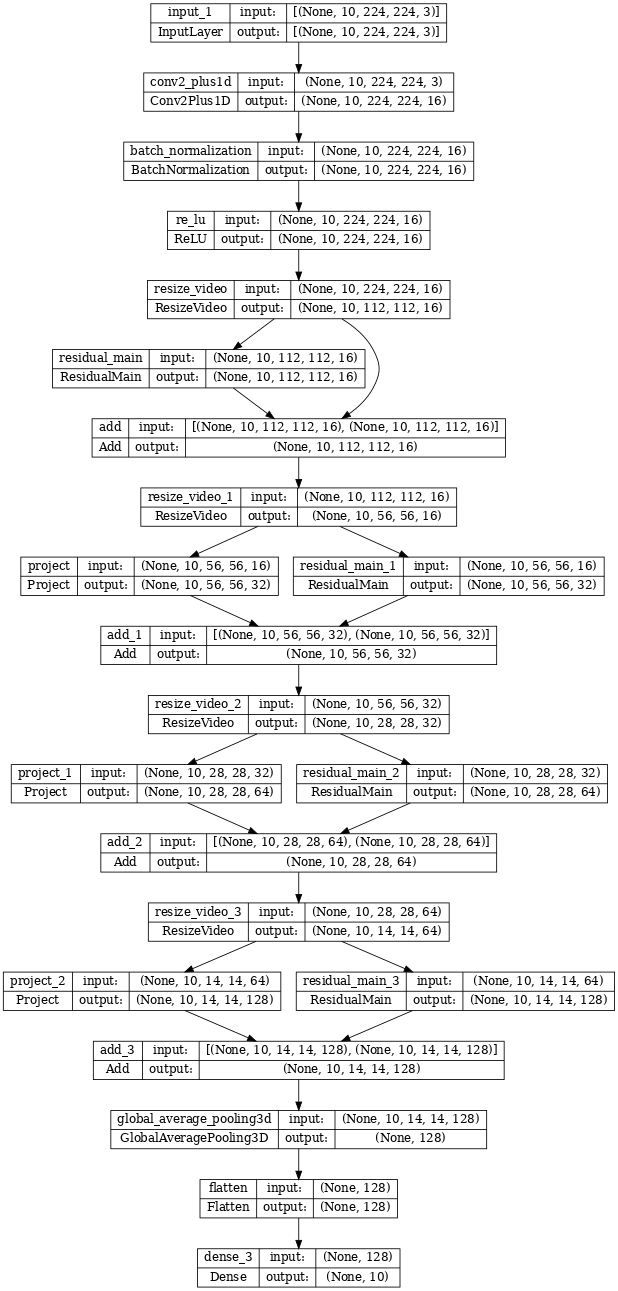
训练模型
对于本教程,选择 tf.keras.optimizers.Adam 优化器和 tf.keras.losses.SparseCategoricalCrossentropy 损失函数。使用 metrics 参数查看每个步骤中模型性能的准确率。
model.compile(loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer = keras.optimizers.Adam(learning_rate = 0.0001),
metrics = ['accuracy'])
使用 Keras Model.fit 方法将模型训练 50 个周期。
注:此示例模型在较少的数据点(300 个训练样本和 100 个验证样本)上进行训练,以保持本教程具有合理的训练时间。此外,此示例模型可能需要超过一个小时来训练。
history = model.fit(x = train_ds,
epochs = 50,
validation_data = val_ds)
Epoch 1/50 WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1699380597.517956 67756 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process. 38/38 [==============================] - 79s 2s/step - loss: 2.4852 - accuracy: 0.1167 - val_loss: 2.3667 - val_accuracy: 0.1200 Epoch 2/50 38/38 [==============================] - 57s 2s/step - loss: 2.2703 - accuracy: 0.1700 - val_loss: 2.2573 - val_accuracy: 0.1400 Epoch 3/50 38/38 [==============================] - 58s 2s/step - loss: 2.1488 - accuracy: 0.1700 - val_loss: 2.3543 - val_accuracy: 0.1600 Epoch 4/50 38/38 [==============================] - 58s 2s/step - loss: 2.0405 - accuracy: 0.1800 - val_loss: 2.4043 - val_accuracy: 0.2100 Epoch 5/50 38/38 [==============================] - 57s 2s/step - loss: 1.9244 - accuracy: 0.2867 - val_loss: 2.0895 - val_accuracy: 0.2200 Epoch 6/50 38/38 [==============================] - 57s 2s/step - loss: 1.8480 - accuracy: 0.3167 - val_loss: 1.9638 - val_accuracy: 0.2800 Epoch 7/50 38/38 [==============================] - 58s 2s/step - loss: 1.7556 - accuracy: 0.3633 - val_loss: 2.1203 - val_accuracy: 0.2400 Epoch 8/50 38/38 [==============================] - 57s 2s/step - loss: 1.6934 - accuracy: 0.3933 - val_loss: 2.0532 - val_accuracy: 0.3300 Epoch 9/50 38/38 [==============================] - 58s 2s/step - loss: 1.6195 - accuracy: 0.4633 - val_loss: 1.8839 - val_accuracy: 0.3600 Epoch 10/50 38/38 [==============================] - 58s 2s/step - loss: 1.5717 - accuracy: 0.4400 - val_loss: 1.9027 - val_accuracy: 0.2900 Epoch 11/50 38/38 [==============================] - 58s 2s/step - loss: 1.5300 - accuracy: 0.4500 - val_loss: 1.7193 - val_accuracy: 0.3800 Epoch 12/50 38/38 [==============================] - 57s 2s/step - loss: 1.5294 - accuracy: 0.4333 - val_loss: 1.4846 - val_accuracy: 0.5000 Epoch 13/50 38/38 [==============================] - 58s 2s/step - loss: 1.4340 - accuracy: 0.5033 - val_loss: 1.4433 - val_accuracy: 0.4900 Epoch 14/50 38/38 [==============================] - 57s 2s/step - loss: 1.4611 - accuracy: 0.4667 - val_loss: 1.6779 - val_accuracy: 0.3900 Epoch 15/50 38/38 [==============================] - 57s 2s/step - loss: 1.3541 - accuracy: 0.4967 - val_loss: 1.3948 - val_accuracy: 0.5000 Epoch 16/50 38/38 [==============================] - 58s 2s/step - loss: 1.2649 - accuracy: 0.5733 - val_loss: 1.3639 - val_accuracy: 0.4700 Epoch 17/50 38/38 [==============================] - 57s 2s/step - loss: 1.2876 - accuracy: 0.5267 - val_loss: 1.5137 - val_accuracy: 0.4900 Epoch 18/50 38/38 [==============================] - 58s 2s/step - loss: 1.2339 - accuracy: 0.5900 - val_loss: 1.2411 - val_accuracy: 0.5100 Epoch 19/50 38/38 [==============================] - 58s 2s/step - loss: 1.1422 - accuracy: 0.5933 - val_loss: 1.2295 - val_accuracy: 0.4700 Epoch 20/50 38/38 [==============================] - 57s 2s/step - loss: 1.0417 - accuracy: 0.6333 - val_loss: 1.2528 - val_accuracy: 0.6000 Epoch 21/50 38/38 [==============================] - 57s 2s/step - loss: 1.0779 - accuracy: 0.6333 - val_loss: 1.2432 - val_accuracy: 0.5900 Epoch 22/50 38/38 [==============================] - 57s 2s/step - loss: 1.0722 - accuracy: 0.6100 - val_loss: 1.1889 - val_accuracy: 0.5100 Epoch 23/50 38/38 [==============================] - 58s 2s/step - loss: 1.0276 - accuracy: 0.6400 - val_loss: 1.1974 - val_accuracy: 0.5700 Epoch 24/50 38/38 [==============================] - 57s 2s/step - loss: 0.9482 - accuracy: 0.6600 - val_loss: 1.1542 - val_accuracy: 0.6900 Epoch 25/50 38/38 [==============================] - 58s 2s/step - loss: 0.9073 - accuracy: 0.6867 - val_loss: 1.1290 - val_accuracy: 0.5400 Epoch 26/50 38/38 [==============================] - 58s 2s/step - loss: 0.8753 - accuracy: 0.6833 - val_loss: 0.9988 - val_accuracy: 0.6100 Epoch 27/50 38/38 [==============================] - 58s 2s/step - loss: 0.8845 - accuracy: 0.7033 - val_loss: 1.1641 - val_accuracy: 0.5500 Epoch 28/50 38/38 [==============================] - 57s 2s/step - loss: 0.9075 - accuracy: 0.6867 - val_loss: 1.0183 - val_accuracy: 0.6600 Epoch 29/50 38/38 [==============================] - 58s 2s/step - loss: 0.8817 - accuracy: 0.6667 - val_loss: 0.9545 - val_accuracy: 0.6600 Epoch 30/50 38/38 [==============================] - 57s 2s/step - loss: 0.8307 - accuracy: 0.7100 - val_loss: 1.0712 - val_accuracy: 0.6000 Epoch 31/50 38/38 [==============================] - 57s 2s/step - loss: 0.8055 - accuracy: 0.6933 - val_loss: 0.8558 - val_accuracy: 0.6800 Epoch 32/50 38/38 [==============================] - 58s 2s/step - loss: 0.7328 - accuracy: 0.7400 - val_loss: 0.9174 - val_accuracy: 0.6900 Epoch 33/50 38/38 [==============================] - 58s 2s/step - loss: 0.7281 - accuracy: 0.7500 - val_loss: 0.8336 - val_accuracy: 0.7100 Epoch 34/50 38/38 [==============================] - 58s 2s/step - loss: 0.7645 - accuracy: 0.7233 - val_loss: 0.8816 - val_accuracy: 0.7100 Epoch 35/50 38/38 [==============================] - 58s 2s/step - loss: 0.7383 - accuracy: 0.7433 - val_loss: 0.8970 - val_accuracy: 0.6900 Epoch 36/50 38/38 [==============================] - 57s 2s/step - loss: 0.7897 - accuracy: 0.7267 - val_loss: 1.2212 - val_accuracy: 0.5500 Epoch 37/50 38/38 [==============================] - 58s 2s/step - loss: 0.6962 - accuracy: 0.7600 - val_loss: 0.8390 - val_accuracy: 0.6200 Epoch 38/50 38/38 [==============================] - 57s 2s/step - loss: 0.6660 - accuracy: 0.7733 - val_loss: 0.8266 - val_accuracy: 0.7400 Epoch 39/50 38/38 [==============================] - 58s 2s/step - loss: 0.6839 - accuracy: 0.7600 - val_loss: 1.0613 - val_accuracy: 0.6500 Epoch 40/50 38/38 [==============================] - 58s 2s/step - loss: 0.6635 - accuracy: 0.7733 - val_loss: 0.8927 - val_accuracy: 0.6700 Epoch 41/50 38/38 [==============================] - 57s 2s/step - loss: 0.5997 - accuracy: 0.7933 - val_loss: 0.8795 - val_accuracy: 0.7100 Epoch 42/50 38/38 [==============================] - 57s 2s/step - loss: 0.6059 - accuracy: 0.8100 - val_loss: 0.9292 - val_accuracy: 0.6600 Epoch 43/50 38/38 [==============================] - 58s 2s/step - loss: 0.6559 - accuracy: 0.7667 - val_loss: 0.8097 - val_accuracy: 0.6900 Epoch 44/50 38/38 [==============================] - 58s 2s/step - loss: 0.5902 - accuracy: 0.8000 - val_loss: 0.8116 - val_accuracy: 0.6800 Epoch 45/50 38/38 [==============================] - 58s 2s/step - loss: 0.5465 - accuracy: 0.8300 - val_loss: 0.8406 - val_accuracy: 0.6700 Epoch 46/50 38/38 [==============================] - 58s 2s/step - loss: 0.6235 - accuracy: 0.7833 - val_loss: 1.1075 - val_accuracy: 0.6000 Epoch 47/50 38/38 [==============================] - 58s 2s/step - loss: 0.6543 - accuracy: 0.7933 - val_loss: 0.8507 - val_accuracy: 0.6900 Epoch 48/50 38/38 [==============================] - 58s 2s/step - loss: 0.4840 - accuracy: 0.8467 - val_loss: 0.7414 - val_accuracy: 0.7600 Epoch 49/50 38/38 [==============================] - 58s 2s/step - loss: 0.5513 - accuracy: 0.8167 - val_loss: 0.8569 - val_accuracy: 0.7200 Epoch 50/50 38/38 [==============================] - 58s 2s/step - loss: 0.4742 - accuracy: 0.8367 - val_loss: 0.7287 - val_accuracy: 0.7300
呈现结果
在训练集和验证集上创建损失和准确率的图表:
def plot_history(history):
"""
Plotting training and validation learning curves.
Args:
history: model history with all the metric measures
"""
fig, (ax1, ax2) = plt.subplots(2)
fig.set_size_inches(18.5, 10.5)
# Plot loss
ax1.set_title('Loss')
ax1.plot(history.history['loss'], label = 'train')
ax1.plot(history.history['val_loss'], label = 'test')
ax1.set_ylabel('Loss')
# Determine upper bound of y-axis
max_loss = max(history.history['loss'] + history.history['val_loss'])
ax1.set_ylim([0, np.ceil(max_loss)])
ax1.set_xlabel('Epoch')
ax1.legend(['Train', 'Validation'])
# Plot accuracy
ax2.set_title('Accuracy')
ax2.plot(history.history['accuracy'], label = 'train')
ax2.plot(history.history['val_accuracy'], label = 'test')
ax2.set_ylabel('Accuracy')
ax2.set_ylim([0, 1])
ax2.set_xlabel('Epoch')
ax2.legend(['Train', 'Validation'])
plt.show()
plot_history(history)

评估模型
使用 Keras Model.evaluate 获取测试数据集的损失和准确率。
注:本教程中的示例模型使用 UCF101 数据集的子集来保持合理的训练时间。通过进一步的超参数调优或更多的训练数据,可以改善准确率和损失。
model.evaluate(test_ds, return_dict = True)
13/13 [==============================] - 11s 885ms/step - loss: 0.9717 - accuracy: 0.6800
{'loss': 0.9717392921447754, 'accuracy': 0.6800000071525574}
要进一步呈现模型性能,请使用混淆矩阵。混淆矩阵允许评估分类模型的性能,而不仅仅是准确率。为了构建此多类分类问题的混淆矩阵,需要获得测试集中的实际值和预测值。
def get_actual_predicted_labels(dataset):
"""
Create a list of actual ground truth values and the predictions from the model.
Args:
dataset: An iterable data structure, such as a TensorFlow Dataset, with features and labels.
Return:
Ground truth and predicted values for a particular dataset.
"""
actual = [labels for _, labels in dataset.unbatch()]
predicted = model.predict(dataset)
actual = tf.stack(actual, axis=0)
predicted = tf.concat(predicted, axis=0)
predicted = tf.argmax(predicted, axis=1)
return actual, predicted
def plot_confusion_matrix(actual, predicted, labels, ds_type):
cm = tf.math.confusion_matrix(actual, predicted)
ax = sns.heatmap(cm, annot=True, fmt='g')
sns.set(rc={'figure.figsize':(12, 12)})
sns.set(font_scale=1.4)
ax.set_title('Confusion matrix of action recognition for ' + ds_type)
ax.set_xlabel('Predicted Action')
ax.set_ylabel('Actual Action')
plt.xticks(rotation=90)
plt.yticks(rotation=0)
ax.xaxis.set_ticklabels(labels)
ax.yaxis.set_ticklabels(labels)
labels = ['ApplyEyeMakeup', 'ApplyLipstick', 'Archery', 'BabyCrawling', 'BalanceBeam',
'BandMarching', 'BaseballPitch', 'Basketball', 'BasketballDunk', 'BenchPress']
actual, predicted = get_actual_predicted_labels(train_ds)
plot_confusion_matrix(actual, predicted, labels, 'training')
38/38 [==============================] - 36s 912ms/step

actual, predicted = get_actual_predicted_labels(test_ds)
plot_confusion_matrix(actual, predicted, labels, 'test')
13/13 [==============================] - 12s 893ms/step

另外,还可以使用混淆矩阵计算每个类的准确率和召回率值。
def calculate_classification_metrics(y_actual, y_pred, labels):
"""
Calculate the precision and recall of a classification model using the ground truth and
predicted values.
Args:
y_actual: Ground truth labels.
y_pred: Predicted labels.
labels: List of classification labels.
Return:
Precision and recall measures.
"""
cm = tf.math.confusion_matrix(y_actual, y_pred)
tp = np.diag(cm) # Diagonal represents true positives
precision = dict()
recall = dict()
for i in range(len(labels)):
col = cm[:, i]
fp = np.sum(col) - tp[i] # Sum of column minus true positive is false negative
row = cm[i, :]
fn = np.sum(row) - tp[i] # Sum of row minus true positive, is false negative
precision[labels[i]] = tp[i] / (tp[i] + fp) # Precision
recall[labels[i]] = tp[i] / (tp[i] + fn) # Recall
return precision, recall
precision, recall = calculate_classification_metrics(actual, predicted, labels) # Test dataset
precision
{'ApplyEyeMakeup': 0.5,
'ApplyLipstick': 0.5555555555555556,
'Archery': 0.6666666666666666,
'BabyCrawling': 1.0,
'BalanceBeam': 0.6,
'BandMarching': 0.7,
'BaseballPitch': 0.8,
'Basketball': 0.4444444444444444,
'BasketballDunk': 0.8333333333333334,
'BenchPress': 0.9}
recall
{'ApplyEyeMakeup': 0.2,
'ApplyLipstick': 1.0,
'Archery': 0.8,
'BabyCrawling': 0.5,
'BalanceBeam': 0.6,
'BandMarching': 0.7,
'BaseballPitch': 0.8,
'Basketball': 0.4,
'BasketballDunk': 1.0,
'BenchPress': 0.9}