
Trang này liệt kê một tập hợp các hướng dẫn và công cụ đã biết để giải quyết các vấn đề trong miền văn bản với TensorFlow Hub. Đây là nơi khởi đầu cho bất kỳ ai muốn giải quyết các vấn đề ML điển hình bằng cách sử dụng các thành phần ML được đào tạo trước thay vì bắt đầu lại từ đầu.
Phân loại
Khi chúng tôi muốn dự đoán một lớp cho một ví dụ cụ thể, chẳng hạn như tình cảm , độc tính , danh mục bài viết hoặc bất kỳ đặc điểm nào khác.

Các hướng dẫn bên dưới giải quyết cùng một nhiệm vụ từ những góc nhìn khác nhau và sử dụng các công cụ khác nhau.
máy ảnh
Phân loại văn bản bằng Keras - ví dụ về cách xây dựng trình phân loại cảm tính IMDB với Bộ dữ liệu Keras và TensorFlow.
Công cụ ước tính
Phân loại văn bản - ví dụ về cách xây dựng trình phân loại cảm tính IMDB bằng Công cụ ước tính. Chứa nhiều mẹo để cải thiện và phần so sánh mô-đun.
BERT
Dự đoán tình cảm đánh giá phim bằng BERT trên TF Hub - hiển thị cách sử dụng mô-đun BERT để phân loại. Bao gồm việc sử dụng thư viện bert để mã hóa và tiền xử lý.
Kaggle
Phân loại IMDB trên Kaggle - cho thấy cách dễ dàng tương tác với cuộc thi Kaggle từ Colab, bao gồm cả việc tải xuống dữ liệu và gửi kết quả.
| Công cụ ước tính | máy ảnh | TF2 | Bộ dữ liệu TF | BERT | API Kaggle | |
|---|---|---|---|---|---|---|
| Phân loại văn bản | ||||||
| Phân loại văn bản với Keras | ||||||
| Dự đoán tâm lý đánh giá phim bằng BERT trên TF Hub | ||||||
| Phân loại IMDB trên Kaggle |
Nhiệm vụ tiếng Bangla với phần nhúng FastText
TensorFlow Hub hiện không cung cấp mô-đun ở mọi ngôn ngữ. Hướng dẫn sau đây cho thấy cách tận dụng TensorFlow Hub để thử nghiệm nhanh và phát triển ML theo mô-đun.
Trình phân loại bài viết Bangla - trình bày cách tạo nhúng văn bản TensorFlow Hub có thể tái sử dụng và sử dụng nó để huấn luyện trình phân loại Keras cho tập dữ liệu BARD Bangla Article .
Sự tương đồng về ngữ nghĩa
Khi chúng ta muốn tìm ra những câu nào có mối tương quan với nhau trong thiết lập zero-shot (không có ví dụ huấn luyện).
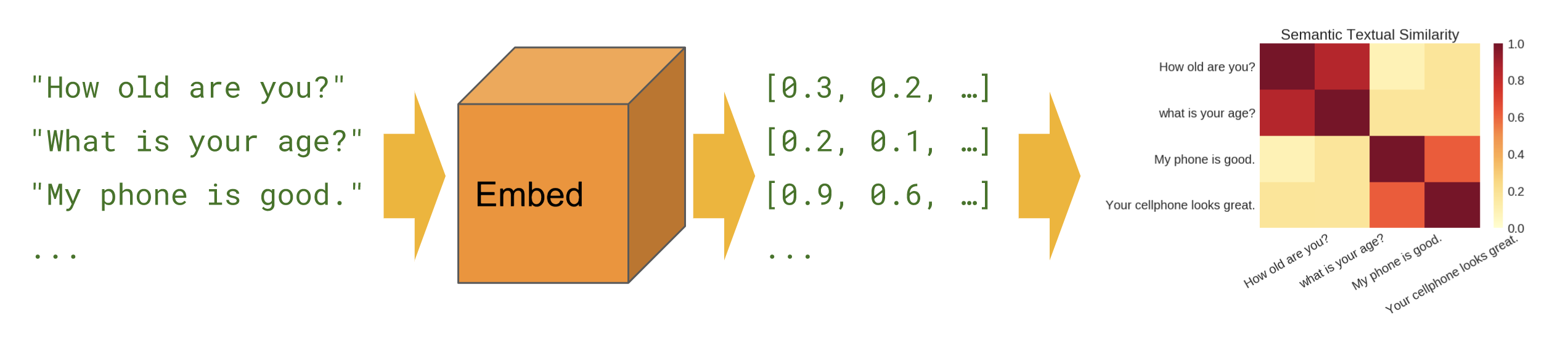
Nền tảng
Độ tương tự về ngữ nghĩa - hiển thị cách sử dụng mô-đun bộ mã hóa câu để tính toán độ tương tự của câu.
Đa ngôn ngữ
Độ tương tự ngữ nghĩa giữa các ngôn ngữ - cho thấy cách sử dụng một trong các bộ mã hóa câu đa ngôn ngữ để tính toán độ tương tự của câu giữa các ngôn ngữ.
Truy xuất ngữ nghĩa
Truy xuất ngữ nghĩa - cho biết cách sử dụng bộ mã hóa câu Q/A để lập chỉ mục một tập hợp tài liệu để truy xuất dựa trên sự tương đồng về ngữ nghĩa.
Đầu vào câu
Sự tương đồng về mặt ngữ nghĩa với Universal Encoding Lite - hiển thị cách sử dụng các mô-đun bộ mã hóa câu chấp nhận id SentencePiece trên đầu vào thay vì văn bản.
Tạo mô-đun
Thay vì chỉ sử dụng các mô-đun trên tfhub.dev , có nhiều cách để tạo các mô-đun riêng. Đây có thể là một công cụ hữu ích để mô đun hóa cơ sở mã ML tốt hơn và để chia sẻ thêm.
Gói các phần nhúng được đào tạo trước hiện có
Trình xuất mô-đun nhúng văn bản - một công cụ để gói nội dung nhúng được đào tạo trước hiện có vào một mô-đun. Hiển thị cách đưa các hoạt động xử lý trước văn bản vào mô-đun. Điều này cho phép tạo mô-đun nhúng câu từ phần nhúng mã thông báo.
Trình xuất mô-đun nhúng văn bản v2 - tương tự như trên, nhưng tương thích với TensorFlow 2 và khả năng thực thi nhanh chóng.