
Bắt đầu
TensorFlow Hub là một kho lưu trữ toàn diện các mô hình được đào tạo trước sẵn sàng để tinh chỉnh và có thể triển khai ở bất kỳ đâu. Tải xuống các mô hình được đào tạo mới nhất với lượng mã tối thiểu bằng thư viện tensorflow_hub .
Các hướng dẫn sau đây sẽ giúp bạn bắt đầu sử dụng và áp dụng các mô hình từ TF Hub cho nhu cầu của mình. Các hướng dẫn tương tác cho phép bạn sửa đổi chúng và thực thi chúng với các thay đổi của bạn. Nhấp vào nút Chạy trong Google Colab ở đầu hướng dẫn tương tác để mày mò.
Cho những người mới bắt đầu
Nếu bạn chưa quen với học máy và TensorFlow, bạn có thể bắt đầu bằng cách tìm hiểu tổng quan về cách phân loại hình ảnh và văn bản, phát hiện các đối tượng trong hình ảnh hoặc bằng cách cách điệu hình ảnh của riêng bạn như tác phẩm nghệ thuật nổi tiếng:

Phân loại hình ảnh
Xây dựng mô hình Keras bên trên bộ phân loại hình ảnh được đào tạo trước để phân biệt các loài hoa.
Phân loại văn bản với BERT
Sử dụng BERT để xây dựng mô hình Keras nhằm giải quyết nhiệm vụ phân tích tình cảm theo phân loại văn bản.Chuyển phong cách
Hãy để mạng nơ-ron vẽ lại một hình ảnh theo phong cách của Picasso, van Gogh hoặc giống như hình ảnh theo phong cách của riêng bạn.
Phát hiện đối tượng
Phát hiện các đối tượng trong hình ảnh bằng các mô hình như FasterRCNN hoặc SSD.Dành cho các nhà phát triển có kinh nghiệm
Xem các hướng dẫn nâng cao hơn để biết cách sử dụng NLP, hình ảnh, âm thanh và mô hình video từ TensorFlow Hub.
Hướng dẫn NLP
Giải quyết các nhiệm vụ NLP phổ biến với các mô hình từ TensorFlow Hub. Xem tất cả các hướng dẫn NLP có sẵn ở điều hướng bên trái.
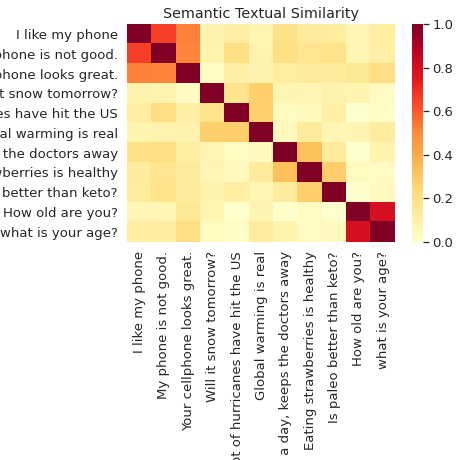
Sự giống nhau về ngữ nghĩa
Phân loại và so sánh ngữ nghĩa các câu với Bộ mã hóa câu đa năng.
BERT trên TPU
Sử dụng BERT để giải quyết các tác vụ điểm chuẩn GLUE chạy trên TPU.Bộ mã hóa câu đa ngôn ngữ Hỏi và đáp
Trả lời các câu hỏi đa ngôn ngữ từ tập dữ liệu SQuAD bằng cách sử dụng mô hình Hỏi và Đáp của bộ mã hóa câu đa ngôn ngữ.Hướng dẫn bằng hình ảnh
Khám phá cách sử dụng GAN, mô hình siêu phân giải và hơn thế nữa. Xem tất cả các hướng dẫn bằng hình ảnh có sẵn ở điều hướng bên trái.

GANS để tạo hình ảnh
Tạo khuôn mặt nhân tạo và nội suy giữa chúng bằng GAN.
giải pháp tối ưu
Nâng cao độ phân giải của hình ảnh được lấy mẫu xuống.
Phần mở rộng Hình ảnh
Điền vào phần bị che của các hình ảnh đã cho.Hướng dẫn bằng âm thanh
Khám phá các hướng dẫn sử dụng các mô hình được đào tạo cho dữ liệu âm thanh bao gồm nhận dạng cao độ và phân loại âm thanh.
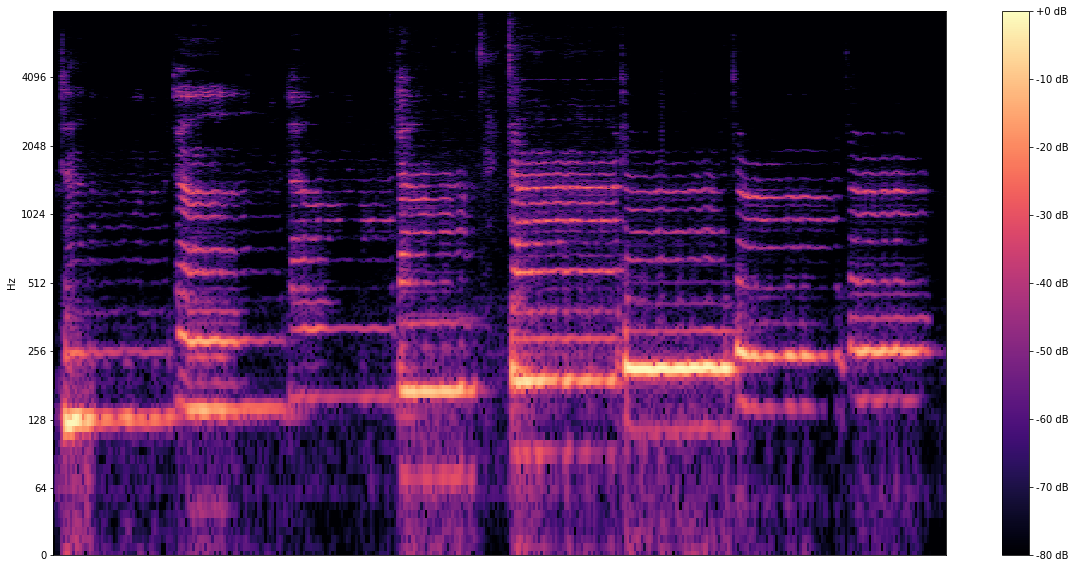
Nhận dạng quảng cáo chiêu hàng
Ghi âm chính bạn hát và phát hiện cao độ giọng nói của bạn bằng cách sử dụng mô hình SPICE.
Phân loại âm thanh
Sử dụng mô hình YAMNet để phân loại âm thanh thành 521 lớp sự kiện âm thanh từ kho dữ liệu AudioSet-YouTube.Video hướng dẫn
Hãy thử các mô hình ML được đào tạo cho dữ liệu video để nhận dạng hành động, nội suy video và hơn thế nữa.

Nhận dạng hành động
Phát hiện một trong 400 hành động trong video bằng cách sử dụng mô hình Inflated 3D ConvNet.
Nội suy video
Nội suy giữa các khung hình video bằng Inbetweening với 3D Convolutions.