
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | | |
अवलोकन
सकारात्मक या नकारात्मक रूप में इस नोटबुक का वर्गीकरण फिल्म समीक्षा समीक्षा के पाठ का उपयोग कर। यह द्विआधारी वर्गीकरण, मशीन सीखने समस्या का एक महत्वपूर्ण और व्यापक रूप से लागू तरह का एक उदाहरण है।
हम दिए गए इनपुट से ग्राफ बनाकर इस नोटबुक में ग्राफ नियमितीकरण के उपयोग को प्रदर्शित करेंगे। न्यूरल स्ट्रक्चर्ड लर्निंग (NSL) फ्रेमवर्क का उपयोग करके ग्राफ़-नियमित मॉडल बनाने के लिए सामान्य नुस्खा जब इनपुट में एक स्पष्ट ग्राफ़ नहीं होता है:
- इनपुट में प्रत्येक टेक्स्ट नमूने के लिए एम्बेडिंग बनाएं। इस तरह के रूप में पूर्व प्रशिक्षित मॉडल का उपयोग किया जा सकता है word2vec , फिरकी , बर्ट आदि
- समानता मीट्रिक जैसे 'L2' दूरी, 'कोसाइन' दूरी, आदि का उपयोग करके इन एम्बेडिंग के आधार पर एक ग्राफ़ बनाएं। ग्राफ़ में नोड्स नमूने के अनुरूप होते हैं और ग्राफ़ में किनारों के नमूने के जोड़े के बीच समानता के अनुरूप होते हैं।
- उपरोक्त संश्लेषित ग्राफ और नमूना सुविधाओं से प्रशिक्षण डेटा उत्पन्न करें। परिणामी प्रशिक्षण डेटा में मूल नोड सुविधाओं के अलावा पड़ोसी सुविधाएँ भी होंगी।
- केरस अनुक्रमिक, कार्यात्मक, या उपवर्ग एपीआई का उपयोग करके आधार मॉडल के रूप में एक तंत्रिका नेटवर्क बनाएं।
- एक नया ग्राफ केरस मॉडल बनाने के लिए एनएसएल फ्रेमवर्क द्वारा प्रदान किए गए ग्राफ रेगुलराइजेशन रैपर क्लास के साथ बेस मॉडल को लपेटें। इस नए मॉडल में अपने प्रशिक्षण उद्देश्य में नियमितीकरण अवधि के रूप में ग्राफ नियमितीकरण हानि शामिल होगी।
- केरस मॉडल को प्रशिक्षित करें और उसका मूल्यांकन करें।
आवश्यकताएं
- तंत्रिका संरचित शिक्षण पैकेज स्थापित करें।
- टेंसरफ़्लो-हब स्थापित करें।
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
निर्भरता और आयात
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
आईएमडीबी डेटासेट
IMDB डाटासेट से 50,000 फिल्म समीक्षा की पाठ होता है इंटरनेट मूवी डाटाबेस । इन्हें प्रशिक्षण के लिए 25,000 समीक्षाओं और परीक्षण के लिए 25,000 समीक्षाओं में विभाजित किया गया है। प्रशिक्षण और परीक्षण सेट संतुलित जाता है, वे सकारात्मक और नकारात्मक समीक्षा की संख्या बराबर होते हैं।
इस ट्यूटोरियल में, हम IMDB डेटासेट के प्रीप्रोसेस्ड संस्करण का उपयोग करेंगे।
प्रीप्रोसेस्ड IMDB डेटासेट डाउनलोड करें
IMDB डेटासेट TensorFlow के साथ पैक किया जाता है। इसे पहले से ही इस तरह से पूर्व-संसाधित किया गया है कि समीक्षाओं (शब्दों के अनुक्रम) को पूर्णांकों के अनुक्रम में बदल दिया गया है, जहां प्रत्येक पूर्णांक एक शब्दकोश में एक विशिष्ट शब्द का प्रतिनिधित्व करता है।
निम्नलिखित कोड IMDB डेटासेट डाउनलोड करता है (या कैश्ड कॉपी का उपयोग करता है यदि इसे पहले ही डाउनलोड किया जा चुका है):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
तर्क num_words=10000 प्रशिक्षण डेटा में शीर्ष 10,000 सबसे अक्सर होने वाली शब्द रहता है। शब्दावली के आकार को व्यवस्थित रखने के लिए दुर्लभ शब्दों को छोड़ दिया जाता है।
डेटा का अन्वेषण करें
आइए डेटा के प्रारूप को समझने के लिए कुछ समय निकालें। डेटासेट प्रीप्रोसेस्ड आता है: प्रत्येक उदाहरण फिल्म समीक्षा के शब्दों का प्रतिनिधित्व करने वाले पूर्णांकों की एक सरणी है। प्रत्येक लेबल 0 या 1 का पूर्णांक मान है, जहां 0 एक नकारात्मक समीक्षा है, और 1 एक सकारात्मक समीक्षा है।
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
समीक्षाओं के पाठ को पूर्णांक में बदल दिया गया है, जहां प्रत्येक पूर्णांक एक शब्दकोश में एक विशिष्ट शब्द का प्रतिनिधित्व करता है। यहाँ पहली समीक्षा कैसी दिखती है:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
मूवी समीक्षा अलग-अलग लंबाई की हो सकती है। नीचे दिया गया कोड पहली और दूसरी समीक्षाओं में शब्दों की संख्या दिखाता है। चूंकि तंत्रिका नेटवर्क में इनपुट समान लंबाई का होना चाहिए, इसलिए हमें इसे बाद में हल करना होगा।
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
पूर्णांकों को वापस शब्दों में बदलें
यह जानना उपयोगी हो सकता है कि पूर्णांकों को वापस संगत पाठ में कैसे परिवर्तित किया जाए। यहां, हम एक डिक्शनरी ऑब्जेक्ट को क्वेरी करने के लिए एक हेल्पर फंक्शन बनाएंगे जिसमें स्ट्रिंग मैपिंग के लिए पूर्णांक शामिल है:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
अब हम उपयोग कर सकते हैं decode_review समीक्षा करने के पहले पाठ प्रदर्शित करने समारोह:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
ग्राफ निर्माण
ग्राफ़ निर्माण में टेक्स्ट नमूनों के लिए एम्बेडिंग बनाना और फिर एम्बेडिंग की तुलना करने के लिए समानता फ़ंक्शन का उपयोग करना शामिल है।
आगे बढ़ने से पहले, हम पहले इस ट्यूटोरियल द्वारा बनाई गई कलाकृतियों को संग्रहीत करने के लिए एक निर्देशिका बनाते हैं।
mkdir -p /tmp/imdb
नमूना एम्बेडिंग बनाएं
हम pretrained फिरकी embeddings प्रयोग embeddings बनाने के लिए होगा tf.train.Example इनपुट में प्रत्येक नमूने के लिए प्रारूप। हम में जिसके परिणामस्वरूप embeddings स्टोर करेगा TFRecord एक अतिरिक्त विशेषता यह है कि प्रत्येक नमूने की आईडी का प्रतिनिधित्व करता है के साथ प्रारूप। यह महत्वपूर्ण है और हमें बाद में ग्राफ़ में संबंधित नोड्स के साथ नमूना एम्बेडिंग का मिलान करने की अनुमति देगा।
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
एक ग्राफ बनाएं
अब जब हमारे पास नमूना एम्बेडिंग हैं, तो हम उनका उपयोग एक समानता ग्राफ बनाने के लिए करेंगे, अर्थात, इस ग्राफ में नोड्स नमूनों के अनुरूप होंगे और इस ग्राफ में किनारों को नोड्स के जोड़े के बीच समानता के अनुरूप होगा।
न्यूरल स्ट्रक्चर्ड लर्निंग नमूना एम्बेडिंग के आधार पर एक ग्राफ बनाने के लिए एक ग्राफ बिल्डिंग लाइब्रेरी प्रदान करता है। यह का उपयोग करता है कोज्या समानता समानता उपाय के रूप में उन दोनों के बीच embeddings और निर्माण किनारों तुलना करने के लिए। यह हमें एक समानता सीमा निर्दिष्ट करने की भी अनुमति देता है, जिसका उपयोग अंतिम ग्राफ़ से भिन्न किनारों को त्यागने के लिए किया जा सकता है। इस उदाहरण में, समानता सीमा के रूप में 0.99 और यादृच्छिक बीज के रूप में 12345 का उपयोग करते हुए, हम एक ग्राफ के साथ समाप्त होते हैं जिसमें 429,415 द्वि-दिशात्मक किनारे होते हैं। यहाँ हम के लिए ग्राफ बिल्डर के समर्थन का उपयोग कर रहे इलाके के प्रति संवेदनशील हैशिंग (LSH) ग्राफ निर्माण में तेजी लाने के। ग्राफ बिल्डर के LSH समर्थन का उपयोग करने पर जानकारी के लिए, build_graph_from_config API दस्तावेज़।
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
प्रत्येक द्वि-दिशात्मक किनारे को आउटपुट TSV फ़ाइल में दो निर्देशित किनारों द्वारा दर्शाया जाता है, ताकि फ़ाइल में 429,415 * 2 = 858,830 कुल लाइनें हों:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
नमूना विशेषताएं
हम का उपयोग कर हमारी समस्या के लिए नमूना विशेषताएं बनाने tf.train.Example प्रारूप और उन में जारी रहती है TFRecord प्रारूप। प्रत्येक नमूने में निम्नलिखित तीन विशेषताएं शामिल होंगी:
- आईडी: नमूने के नोड आईडी।
- शब्द: एक int64 शब्द आईडी युक्त सूची।
- लेबल: समीक्षा का लक्ष्य वर्ग की पहचान करने int64 एक सिंगलटन।
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
ग्राफ पड़ोसियों के साथ प्रशिक्षण डेटा बढ़ाना
चूंकि हमारे पास नमूना विशेषताएं और संश्लेषित ग्राफ हैं, इसलिए हम तंत्रिका संरचित सीखने के लिए संवर्धित प्रशिक्षण डेटा उत्पन्न कर सकते हैं। एनएसएल ढांचा ग्राफ नियमितीकरण के लिए अंतिम प्रशिक्षण डेटा तैयार करने के लिए ग्राफ और नमूना सुविधाओं को संयोजित करने के लिए एक पुस्तकालय प्रदान करता है। परिणामी प्रशिक्षण डेटा में मूल नमूना सुविधाओं के साथ-साथ उनके संबंधित पड़ोसियों की विशेषताएं भी शामिल होंगी।
इस ट्यूटोरियल में, हम अप्रत्यक्ष किनारों पर विचार करते हैं और ग्राफ़ पड़ोसियों के साथ प्रशिक्षण डेटा बढ़ाने के लिए प्रति नमूना अधिकतम 3 पड़ोसियों का उपयोग करते हैं।
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
आधार मॉडल
अब हम ग्राफ नियमितीकरण के बिना आधार मॉडल बनाने के लिए तैयार हैं। इस मॉडल को बनाने के लिए, हम या तो एम्बेडिंग का उपयोग कर सकते हैं जिनका उपयोग ग्राफ़ बनाने में किया गया था, या हम वर्गीकरण कार्य के साथ संयुक्त रूप से नए एम्बेडिंग सीख सकते हैं। इस नोटबुक के प्रयोजन के लिए, हम बाद वाले का काम करेंगे।
सार्वत्रिक चर
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
हाइपरपैरामीटर
हम का एक उदाहरण का उपयोग करेगा HParams विभिन्न hyperparameters और स्थिरांक प्रशिक्षण और मूल्यांकन के लिए इस्तेमाल किया inclue करने के लिए। हम नीचे उनमें से प्रत्येक का संक्षेप में वर्णन करते हैं:
num_classes: - सकारात्मक और नकारात्मक वहाँ 2 वर्ग हैं।
max_seq_length: यह इस उदाहरण में प्रत्येक फिल्म समीक्षा से माना शब्दों की अधिकतम संख्या है।
vocab_size: इस शब्दावली इस उदाहरण के लिए विचार का आकार है।
distance_type: इस दूरी मीट्रिक अपने पड़ोसियों के साथ नमूना को नियमित करने के लिए प्रयोग किया जाता है।
graph_regularization_multiplier: यह नियंत्रण कुल नुकसान समारोह में ग्राफ नियमितीकरण अवधि के सापेक्ष वजन।
num_neighbors: ग्राफ नियमितीकरण के लिए इस्तेमाल किया पड़ोसियों की संख्या। इस मान से कम या ज्यादा के बराबर हो गया है
max_nbrsजब लागू, ऊपर उपयोग तर्कnsl.tools.pack_nbrs।num_fc_units: तंत्रिका नेटवर्क का पूरी तरह से जुड़ा हुआ परत में पुस्तकों की संख्या।
train_epochs: प्रशिक्षण अवधियों की संख्या।
batch_size: बैच आकार प्रशिक्षण और मूल्यांकन के लिए इस्तेमाल किया।
eval_steps: मूल्यांकन deeming से पहले की प्रक्रिया के लिए बैचों की संख्या पूरी हो चुकी है। तो करने के लिए सेट
None, परीक्षण सेट में सभी उदाहरणों मूल्यांकन किया जाता है।
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
डेटा तैयार करें
समीक्षाएं—पूर्णांकों की सरणियों—को तंत्रिका नेटवर्क में फीड किए जाने से पहले टेंसर में परिवर्तित किया जाना चाहिए। यह रूपांतरण दो तरीकों से किया जा सकता है:
की वैक्टर में सरणियों कन्वर्ट
0और1शब्द घटना, एक एक गर्म एन्कोडिंग के लिए इसी तरह का संकेत है। उदाहरण के लिए, अनुक्रम[3, 5]एक बन जाएगा10000आयामी सदिश सूचकांक को छोड़कर सभी शून्य है कि3और5, जो होते हैं। फिर, यह हमारे में पहली परत बनाने के नेटवर्क-एकDenseपरत-उस बिंदु वेक्टर डेटा चल संभाल कर सकते हैं। यह दृष्टिकोण एक की आवश्यकता होती है, स्मृति-गहन है, हालांकिnum_words * num_reviewsआकार मैट्रिक्स।वैकल्पिक रूप से, हम पैड सरणियों तो वे सभी एक ही लंबाई है, तो आकार के एक पूर्णांक टेन्सर बना सकते हैं
max_length * num_reviews। हम अपने नेटवर्क में पहली परत के रूप में इस आकार को संभालने में सक्षम एक एम्बेडिंग परत का उपयोग कर सकते हैं।
इस ट्यूटोरियल में, हम दूसरे दृष्टिकोण का उपयोग करेंगे।
चूंकि फिल्म समीक्षा एक ही लंबाई होना चाहिए, हम का उपयोग करेगा pad_sequence लंबाई मानकीकृत करने के लिए समारोह नीचे परिभाषित।
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
मॉडल बनाएं
परतों को ढेर करके एक तंत्रिका नेटवर्क बनाया जाता है - इसके लिए दो मुख्य वास्तु निर्णयों की आवश्यकता होती है:
- मॉडल में कितनी परतों का उपयोग करना है?
- कितने छिपा इकाइयों प्रत्येक परत के लिए उपयोग करने के लिए?
इस उदाहरण में, इनपुट डेटा में शब्द-सूचकांक की एक सरणी होती है। भविष्यवाणी करने के लिए लेबल या तो 0 या 1 हैं।
हम इस ट्यूटोरियल में अपने बेस मॉडल के रूप में एक द्वि-दिशात्मक LSTM का उपयोग करेंगे।
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
क्लासिफायरियर बनाने के लिए परतों को क्रमिक रूप से प्रभावी ढंग से स्टैक किया जाता है:
- पहली परत एक है
Inputपरत जो पूर्णांक एन्कोड शब्दावली लेता है। - अगले परत एक है
Embeddingपरत है, जो पूर्णांक एन्कोड शब्दावली और दिखता है ऊपर प्रत्येक शब्द सूचकांक के लिए एम्बेडिंग वेक्टर लेता है। इन वैक्टर को मॉडल ट्रेन के रूप में सीखा जाता है। वेक्टर आउटपुट सरणी में एक आयाम जोड़ते हैं। जिसके परिणामस्वरूप आयाम हैं:(batch, sequence, embedding)। - इसके बाद, एक द्विदिश LSTM परत प्रत्येक उदाहरण के लिए एक निश्चित-लंबाई आउटपुट वेक्टर लौटाती है।
- यह निश्चित लंबाई उत्पादन वेक्टर एक पूरी तरह से जुड़ा हुआ (के माध्यम से पहुंचाया जाता है
Dense64 छिपा इकाइयों के साथ) परत। - अंतिम परत एकल आउटपुट नोड के साथ घनी रूप से जुड़ी हुई है। का उपयोग करते हुए
sigmoidसक्रियण समारोह, यह मान एक संभावना है, या आत्मविश्वास का स्तर का प्रतिनिधित्व करने, 0 और 1 के बीच एक नाव है।
छिपी हुई इकाइयाँ
ऊपर मॉडल इनपुट और आउटपुट, और को छोड़कर के बीच, दो मध्यवर्ती या "छिपा" परतें हैं Embedding परत। आउटपुट (इकाइयों, नोड्स, या न्यूरॉन्स) की संख्या परत के लिए प्रतिनिधित्व स्थान का आयाम है। दूसरे शब्दों में, आंतरिक प्रतिनिधित्व सीखते समय नेटवर्क को कितनी स्वतंत्रता की अनुमति है।
यदि किसी मॉडल में अधिक छिपी हुई इकाइयाँ (एक उच्च-आयामी प्रतिनिधित्व स्थान), और/या अधिक परतें हैं, तो नेटवर्क अधिक जटिल अभ्यावेदन सीख सकता है। हालांकि, यह नेटवर्क को अधिक कम्प्यूटेशनल रूप से महंगा बनाता है और अवांछित पैटर्न सीखने का कारण बन सकता है-पैटर्न जो प्रशिक्षण डेटा पर प्रदर्शन में सुधार करते हैं लेकिन परीक्षण डेटा पर नहीं। यह overfitting कहा जाता है।
हानि समारोह और अनुकूलक
एक मॉडल को प्रशिक्षण के लिए एक हानि फ़ंक्शन और एक अनुकूलक की आवश्यकता होती है। चूंकि यह एक द्विआधारी वर्गीकरण समस्या है और एक संभावना आउटपुट मॉडल (एक अवग्रह सक्रियण के साथ एक एकल इकाई परत) है, जिसका हम उपयोग करेंगे binary_crossentropy नुकसान कार्य करते हैं।
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
एक सत्यापन सेट बनाएं
प्रशिक्षण के दौरान, हम उस डेटा पर मॉडल की सटीकता की जांच करना चाहते हैं जो उसने पहले नहीं देखा है। मूल प्रशिक्षण डेटा का एक अंश के अलावा स्थापना करके एक मान्यता समूह बनाना होगा। (अभी परीक्षण सेट का उपयोग क्यों न करें? हमारा लक्ष्य केवल प्रशिक्षण डेटा का उपयोग करके हमारे मॉडल को विकसित और ट्यून करना है, फिर हमारी सटीकता का मूल्यांकन करने के लिए केवल एक बार परीक्षण डेटा का उपयोग करें)।
इस ट्यूटोरियल में, हम प्रारंभिक प्रशिक्षण नमूनों का लगभग 10% (2500 का 10%) प्रशिक्षण के लिए लेबल किए गए डेटा के रूप में और शेष को सत्यापन डेटा के रूप में लेते हैं। चूंकि प्रारंभिक ट्रेन/परीक्षण विभाजन 50/50 (प्रत्येक में 25000 नमूने) था, अब हमारे पास प्रभावी ट्रेन/सत्यापन/परीक्षण विभाजन 5/45/50 है।
ध्यान दें कि 'train_dataset' को पहले ही बैच और फेरबदल किया जा चुका है।
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
मॉडल को प्रशिक्षित करें
मॉडल को मिनी-बैच में प्रशिक्षित करें। प्रशिक्षण के दौरान, सत्यापन सेट पर मॉडल के नुकसान और सटीकता की निगरानी करें:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
मॉडल का मूल्यांकन करें
अब, देखते हैं कि मॉडल कैसा प्रदर्शन करता है। दो मान लौटाए जाएंगे। हानि (एक संख्या जो हमारी त्रुटि का प्रतिनिधित्व करती है, कम मान बेहतर होते हैं), और सटीकता।
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
समय के साथ सटीकता/नुकसान का ग्राफ बनाएं
model.fit() की ओर से एक History उद्देश्य यह है कि सब कुछ है कि प्रशिक्षण के दौरान हुआ के साथ एक शब्दकोश में शामिल है:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
चार प्रविष्टियां हैं: प्रशिक्षण और सत्यापन के दौरान प्रत्येक मॉनिटर किए गए मीट्रिक के लिए एक। हम तुलना के लिए प्रशिक्षण और सत्यापन हानि, साथ ही प्रशिक्षण और सत्यापन सटीकता की साजिश रचने के लिए इनका उपयोग कर सकते हैं:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
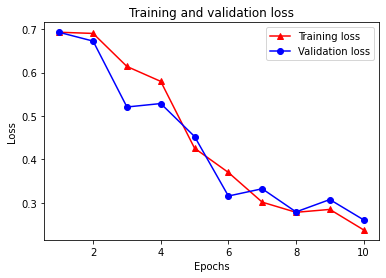
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
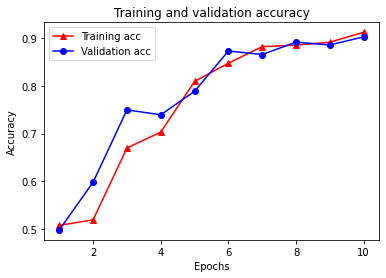
सूचना प्रशिक्षण नुकसान प्रत्येक युग और प्रत्येक युग के साथ प्रशिक्षण सटीकता वृद्धि के साथ कम हो जाती है। ग्रेडिएंट डिसेंट ऑप्टिमाइज़ेशन का उपयोग करते समय यह अपेक्षित है - इसे हर पुनरावृत्ति पर वांछित मात्रा को कम करना चाहिए।
ग्राफ नियमितीकरण
अब हम ऊपर बनाए गए बेस मॉडल का उपयोग करके ग्राफ नियमितीकरण का प्रयास करने के लिए तैयार हैं। हम का उपयोग करेगा GraphRegularization आवरण तंत्रिका संरचित सीखने ढांचे आधार (द्वि-LSTM) मॉडल रैप करने के लिए ग्राफ नियमितीकरण शामिल करने के लिए द्वारा प्रदान की कक्षा। ग्राफ-नियमित मॉडल के प्रशिक्षण और मूल्यांकन के बाकी चरण बेस मॉडल के समान हैं।
ग्राफ-नियमित मॉडल बनाएं
ग्राफ नियमितीकरण के वृद्धिशील लाभ का आकलन करने के लिए, हम एक नया आधार मॉडल उदाहरण बनाएंगे। इसका कारण यह है है model पहले से ही कुछ पुनरावृत्तियों के लिए प्रशिक्षित किया गया है, और इस प्रशिक्षित मॉडल पुन: उपयोग एक ग्राफ-नियमित मॉडल बनाने के लिए के लिए एक निष्पक्ष तुलना नहीं होगा model ।
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
मॉडल को प्रशिक्षित करें
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
मॉडल का मूल्यांकन करें
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
समय के साथ सटीकता/नुकसान का ग्राफ बनाएं
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
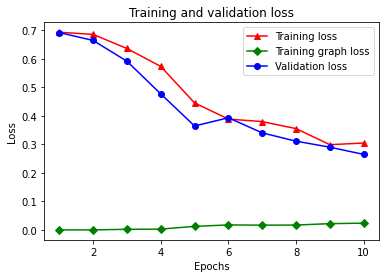
शब्दकोश में कुल पाँच प्रविष्टियाँ हैं: प्रशिक्षण हानि, प्रशिक्षण सटीकता, प्रशिक्षण ग्राफ़ हानि, सत्यापन हानि और सत्यापन सटीकता। हम तुलना के लिए उन सभी को एक साथ प्लॉट कर सकते हैं। ध्यान दें कि ग्राफ हानि की गणना केवल प्रशिक्षण के दौरान की जाती है।
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
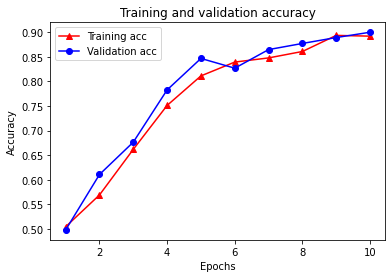
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
अर्ध-पर्यवेक्षित सीखने की शक्ति
अर्ध-पर्यवेक्षित शिक्षण और अधिक विशेष रूप से, इस ट्यूटोरियल के संदर्भ में ग्राफ नियमितीकरण, प्रशिक्षण डेटा की मात्रा कम होने पर वास्तव में शक्तिशाली हो सकता है। प्रशिक्षण डेटा की कमी की भरपाई प्रशिक्षण नमूनों में समानता का लाभ उठाकर की जाती है, जो पारंपरिक पर्यवेक्षित शिक्षण में संभव नहीं है।
हम जो प्रशिक्षण, मान्यता, और परीक्षण नमूने शामिल नमूनों की कुल संख्या के लिए नमूने के प्रशिक्षण के अनुपात के रूप में पर्यवेक्षण अनुपात को परिभाषित। इस नोटबुक में, हमने आधार मॉडल के साथ-साथ ग्राफ़-नियमित मॉडल दोनों के प्रशिक्षण के लिए 0.05 (अर्थात, लेबल किए गए डेटा का 5%) के पर्यवेक्षण अनुपात का उपयोग किया है। हम नीचे सेल में मॉडल सटीकता पर पर्यवेक्षण अनुपात के प्रभाव का वर्णन करते हैं।
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
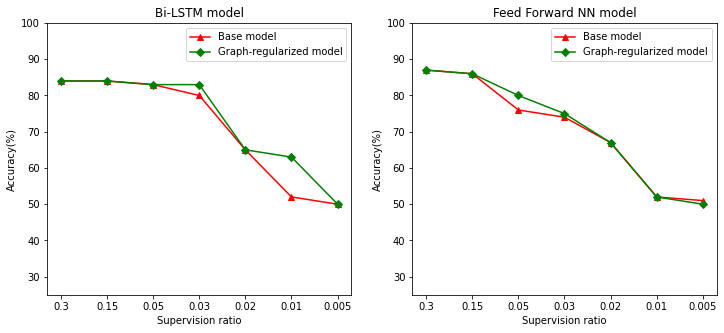
यह देखा जा सकता है कि जैसे-जैसे पर्यवेक्षण अनुपात घटता है, मॉडल सटीकता भी कम होती जाती है। यह आधार मॉडल और ग्राफ़-नियमित मॉडल दोनों के लिए सही है, चाहे इस्तेमाल किए गए मॉडल आर्किटेक्चर पर ध्यान दिए बिना। हालांकि, ध्यान दें कि ग्राफ़-नियमित मॉडल दोनों आर्किटेक्चर के लिए बेस मॉडल से बेहतर प्रदर्शन करता है। विशेष रूप से, द्वि-LSTM मॉडल, के लिए जब पर्यवेक्षण अनुपात 0.01 है, ग्राफ-नियमित मॉडल की सटीकता ~ 20% बेस मॉडल की तुलना में अधिक है। यह मुख्य रूप से ग्राफ-नियमित मॉडल के लिए अर्ध-पर्यवेक्षित सीखने के कारण है, जहां प्रशिक्षण नमूनों के बीच संरचनात्मक समानता का उपयोग स्वयं प्रशिक्षण नमूनों के अलावा किया जाता है।
निष्कर्ष
हमने न्यूरल स्ट्रक्चर्ड लर्निंग (NSL) फ्रेमवर्क का उपयोग करके ग्राफ नियमितीकरण के उपयोग का प्रदर्शन किया है, तब भी जब इनपुट में स्पष्ट ग्राफ नहीं होता है। हमने IMDB मूवी समीक्षाओं के सेंटीमेंट वर्गीकरण के कार्य पर विचार किया, जिसके लिए हमने समीक्षा एम्बेडिंग के आधार पर एक समानता ग्राफ़ को संश्लेषित किया। हम उपयोगकर्ताओं को अलग-अलग हाइपरपैरामीटर, पर्यवेक्षण की मात्रा और विभिन्न मॉडल आर्किटेक्चर का उपयोग करके आगे प्रयोग करने के लिए प्रोत्साहित करते हैं।