| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этой записной книжке демонстрируется использование инструментов приблизительного вывода TFP для включения (негауссовской) модели наблюдения при подгонке и прогнозировании с помощью моделей структурных временных рядов (STS). В этом примере мы будем использовать модель наблюдения Пуассона для работы с дискретными данными подсчета.
import time
import matplotlib.pyplot as plt
import numpy as np
import tensorflow.compat.v2 as tf
import tensorflow_probability as tfp
from tensorflow_probability import bijectors as tfb
from tensorflow_probability import distributions as tfd
tf.enable_v2_behavior()
Синтетические данные
Сначала мы сгенерируем некоторые синтетические данные подсчета:
num_timesteps = 30
observed_counts = np.round(3 + np.random.lognormal(np.log(np.linspace(
num_timesteps, 5, num=num_timesteps)), 0.20, size=num_timesteps))
observed_counts = observed_counts.astype(np.float32)
plt.plot(observed_counts)
[<matplotlib.lines.Line2D at 0x7f940ae958d0>]
Модель
Мы укажем простую модель со случайно блуждающим линейным трендом:
def build_model(approximate_unconstrained_rates):
trend = tfp.sts.LocalLinearTrend(
observed_time_series=approximate_unconstrained_rates)
return tfp.sts.Sum([trend],
observed_time_series=approximate_unconstrained_rates)
Вместо того, чтобы работать с наблюдаемыми временными рядами, эта модель будет работать с рядом параметров скорости Пуассона, которые управляют наблюдениями.
Поскольку коэффициенты Пуассона должны быть положительными, мы будем использовать биектор, чтобы преобразовать модель STS с действительным знаком в распределение по положительным значениям. Softplus преобразование \(y = \log(1 + \exp(x))\) является естественным выбором, так как она близка к линейной для положительных значений, но и другие варианты , таких как Exp (который превращает нормальное блуждание в логнормальное блуждание) также возможны.
positive_bijector = tfb.Softplus() # Or tfb.Exp()
# Approximate the unconstrained Poisson rate just to set heuristic priors.
# We could avoid this by passing explicit priors on all model params.
approximate_unconstrained_rates = positive_bijector.inverse(
tf.convert_to_tensor(observed_counts) + 0.01)
sts_model = build_model(approximate_unconstrained_rates)
Чтобы использовать приблизительный вывод для негауссовской модели наблюдения, мы закодируем модель STS как TFP JointDistribution. Случайными величинами в этом совместном распределении являются параметры модели STS, временные ряды латентных скоростей Пуассона и наблюдаемые подсчеты.
def sts_with_poisson_likelihood_model():
# Encode the parameters of the STS model as random variables.
param_vals = []
for param in sts_model.parameters:
param_val = yield param.prior
param_vals.append(param_val)
# Use the STS model to encode the log- (or inverse-softplus)
# rate of a Poisson.
unconstrained_rate = yield sts_model.make_state_space_model(
num_timesteps, param_vals)
rate = positive_bijector.forward(unconstrained_rate[..., 0])
observed_counts = yield tfd.Poisson(rate, name='observed_counts')
model = tfd.JointDistributionCoroutineAutoBatched(sts_with_poisson_likelihood_model)
Подготовка к выводу
Мы хотим вывести ненаблюдаемые количества в модели, учитывая наблюдаемые подсчеты. Во-первых, мы обуславливаем общую плотность журнала наблюдаемыми подсчетами.
pinned_model = model.experimental_pin(observed_counts=observed_counts)
Нам также понадобится ограничивающий биектор, чтобы гарантировать, что вывод соблюдает ограничения на параметры модели STS (например, масштабы должны быть положительными).
constraining_bijector = pinned_model.experimental_default_event_space_bijector()
Вывод с помощью HMC
Мы будем использовать HMC (в частности, NUTS) для выборки из сустава апостериорно по параметрам модели и латентным показателям.
Это будет значительно медленнее, чем подгонка стандартной модели STS с помощью HMC, поскольку в дополнение к параметрам модели (относительно небольшому количеству) мы также должны вывести весь ряд скоростей Пуассона. Итак, мы пробежим относительно небольшое количество шагов; для приложений, где критично качество вывода, может иметь смысл увеличить эти значения или запустить несколько цепочек.
Конфигурация семплера
# Allow external control of sampling to reduce test runtimes.
num_results = 500 # @param { isTemplate: true}
num_results = int(num_results)
num_burnin_steps = 100 # @param { isTemplate: true}
num_burnin_steps = int(num_burnin_steps)
Сначала мы указываем пробник, а затем использовать sample_chain для запуска ядра , что выборки для образцов продукции.
sampler = tfp.mcmc.TransformedTransitionKernel(
tfp.mcmc.NoUTurnSampler(
target_log_prob_fn=pinned_model.unnormalized_log_prob,
step_size=0.1),
bijector=constraining_bijector)
adaptive_sampler = tfp.mcmc.DualAveragingStepSizeAdaptation(
inner_kernel=sampler,
num_adaptation_steps=int(0.8 * num_burnin_steps),
target_accept_prob=0.75)
initial_state = constraining_bijector.forward(
type(pinned_model.event_shape)(
*(tf.random.normal(part_shape)
for part_shape in constraining_bijector.inverse_event_shape(
pinned_model.event_shape))))
# Speed up sampling by tracing with `tf.function`.
@tf.function(autograph=False, jit_compile=True)
def do_sampling():
return tfp.mcmc.sample_chain(
kernel=adaptive_sampler,
current_state=initial_state,
num_results=num_results,
num_burnin_steps=num_burnin_steps,
trace_fn=None)
t0 = time.time()
samples = do_sampling()
t1 = time.time()
print("Inference ran in {:.2f}s.".format(t1-t0))
Inference ran in 24.83s.
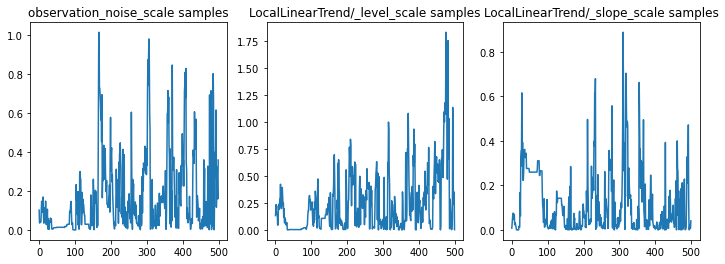
Мы можем проверить правильность вывода, изучив трассировки параметров. В этом случае они, кажется, изучили несколько объяснений данных, что хорошо, хотя было бы полезно больше выборок, чтобы судить, насколько хорошо смешивается цепочка.
f = plt.figure(figsize=(12, 4))
for i, param in enumerate(sts_model.parameters):
ax = f.add_subplot(1, len(sts_model.parameters), i + 1)
ax.plot(samples[i])
ax.set_title("{} samples".format(param.name))
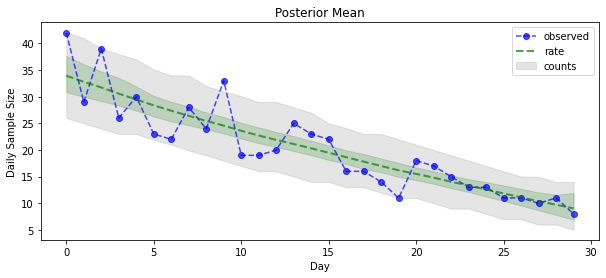
Теперь о выигрыше: давайте посмотрим на апостериорные коэффициенты Пуассона! Мы также построим 80-процентный прогностический интервал по наблюдаемым подсчетам и сможем проверить, что этот интервал содержит около 80% подсчетов, которые мы действительно наблюдали.
param_samples = samples[:-1]
unconstrained_rate_samples = samples[-1][..., 0]
rate_samples = positive_bijector.forward(unconstrained_rate_samples)
plt.figure(figsize=(10, 4))
mean_lower, mean_upper = np.percentile(rate_samples, [10, 90], axis=0)
pred_lower, pred_upper = np.percentile(np.random.poisson(rate_samples),
[10, 90], axis=0)
_ = plt.plot(observed_counts, color="blue", ls='--', marker='o', label='observed', alpha=0.7)
_ = plt.plot(np.mean(rate_samples, axis=0), label='rate', color="green", ls='dashed', lw=2, alpha=0.7)
_ = plt.fill_between(np.arange(0, 30), mean_lower, mean_upper, color='green', alpha=0.2)
_ = plt.fill_between(np.arange(0, 30), pred_lower, pred_upper, color='grey', label='counts', alpha=0.2)
plt.xlabel("Day")
plt.ylabel("Daily Sample Size")
plt.title("Posterior Mean")
plt.legend()
<matplotlib.legend.Legend at 0x7f93ffd35550>
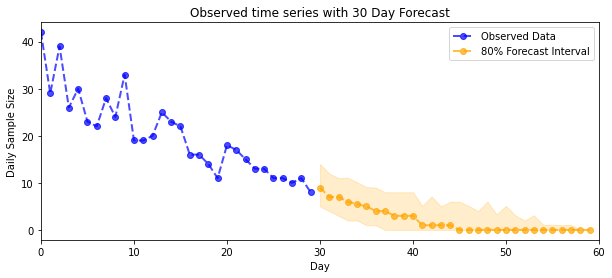
Прогнозирование
Чтобы спрогнозировать наблюдаемые количества, мы будем использовать стандартные инструменты STS для построения распределения прогноза по скрытым показателям (опять же, в неограниченном пространстве, поскольку STS предназначен для моделирования реальных данных), а затем пропустим выборочные прогнозы через наблюдение Пуассона. модель:
def sample_forecasted_counts(sts_model, posterior_latent_rates,
posterior_params, num_steps_forecast,
num_sampled_forecasts):
# Forecast the future latent unconstrained rates, given the inferred latent
# unconstrained rates and parameters.
unconstrained_rates_forecast_dist = tfp.sts.forecast(sts_model,
observed_time_series=unconstrained_rate_samples,
parameter_samples=posterior_params,
num_steps_forecast=num_steps_forecast)
# Transform the forecast to positive-valued Poisson rates.
rates_forecast_dist = tfd.TransformedDistribution(
unconstrained_rates_forecast_dist,
positive_bijector)
# Sample from the forecast model following the chain rule:
# P(counts) = P(counts | latent_rates)P(latent_rates)
sampled_latent_rates = rates_forecast_dist.sample(num_sampled_forecasts)
sampled_forecast_counts = tfd.Poisson(rate=sampled_latent_rates).sample()
return sampled_forecast_counts, sampled_latent_rates
forecast_samples, rate_samples = sample_forecasted_counts(
sts_model,
posterior_latent_rates=unconstrained_rate_samples,
posterior_params=param_samples,
# Days to forecast:
num_steps_forecast=30,
num_sampled_forecasts=100)
forecast_samples = np.squeeze(forecast_samples)
def plot_forecast_helper(data, forecast_samples, CI=90):
"""Plot the observed time series alongside the forecast."""
plt.figure(figsize=(10, 4))
forecast_median = np.median(forecast_samples, axis=0)
num_steps = len(data)
num_steps_forecast = forecast_median.shape[-1]
plt.plot(np.arange(num_steps), data, lw=2, color='blue', linestyle='--', marker='o',
label='Observed Data', alpha=0.7)
forecast_steps = np.arange(num_steps, num_steps+num_steps_forecast)
CI_interval = [(100 - CI)/2, 100 - (100 - CI)/2]
lower, upper = np.percentile(forecast_samples, CI_interval, axis=0)
plt.plot(forecast_steps, forecast_median, lw=2, ls='--', marker='o', color='orange',
label=str(CI) + '% Forecast Interval', alpha=0.7)
plt.fill_between(forecast_steps,
lower,
upper, color='orange', alpha=0.2)
plt.xlim([0, num_steps+num_steps_forecast])
ymin, ymax = min(np.min(forecast_samples), np.min(data)), max(np.max(forecast_samples), np.max(data))
yrange = ymax-ymin
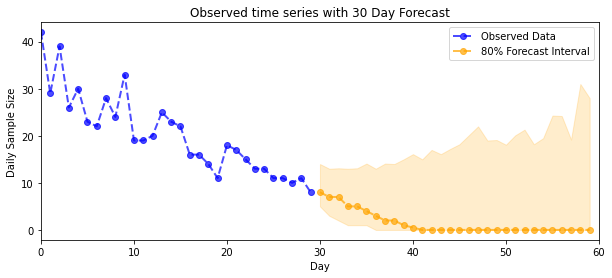
plt.title("{}".format('Observed time series with ' + str(num_steps_forecast) + ' Day Forecast'))
plt.xlabel('Day')
plt.ylabel('Daily Sample Size')
plt.legend()
plot_forecast_helper(observed_counts, forecast_samples, CI=80)
VI вывод
Вариационное умозаключение может быть проблематичным , когда выводя полную временную ряд, как и наших приблизительных подсчеты (в отличие от всего параметров временного ряда, как в стандартных моделях STS). Стандартное предположение о том, что переменные имеют независимые апостериорные значения, совершенно неверно, поскольку каждый временной шаг коррелирует со своими соседями, что может привести к недооценке неопределенности. По этой причине HMC может быть лучшим выбором для приблизительного вывода по полному временному ряду. Тем не менее, VI может быть немного быстрее и может быть полезен для прототипирования модели или в случаях, когда эмпирически можно показать, что его производительность «достаточно хороша».
Чтобы подогнать нашу модель к VI, мы просто строим и оптимизируем суррогатную апостериорную вероятность:
surrogate_posterior = tfp.experimental.vi.build_factored_surrogate_posterior(
event_shape=pinned_model.event_shape,
bijector=constraining_bijector)
# Allow external control of optimization to reduce test runtimes.
num_variational_steps = 1000 # @param { isTemplate: true}
num_variational_steps = int(num_variational_steps)
t0 = time.time()
losses = tfp.vi.fit_surrogate_posterior(pinned_model.unnormalized_log_prob,
surrogate_posterior,
optimizer=tf.optimizers.Adam(0.1),
num_steps=num_variational_steps)
t1 = time.time()
print("Inference ran in {:.2f}s.".format(t1-t0))
Inference ran in 11.37s.
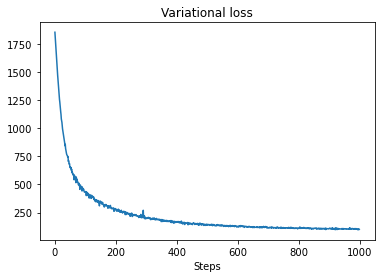
plt.plot(losses)
plt.title("Variational loss")
_ = plt.xlabel("Steps")
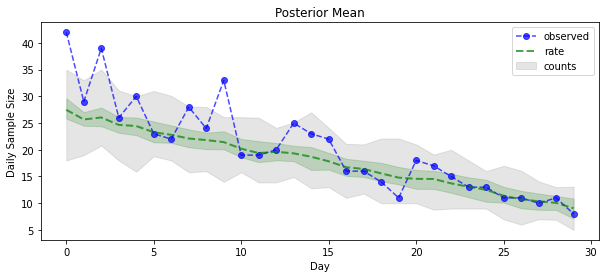
posterior_samples = surrogate_posterior.sample(50)
param_samples = posterior_samples[:-1]
unconstrained_rate_samples = posterior_samples[-1][..., 0]
rate_samples = positive_bijector.forward(unconstrained_rate_samples)
plt.figure(figsize=(10, 4))
mean_lower, mean_upper = np.percentile(rate_samples, [10, 90], axis=0)
pred_lower, pred_upper = np.percentile(
np.random.poisson(rate_samples), [10, 90], axis=0)
_ = plt.plot(observed_counts, color='blue', ls='--', marker='o',
label='observed', alpha=0.7)
_ = plt.plot(np.mean(rate_samples, axis=0), label='rate', color='green',
ls='dashed', lw=2, alpha=0.7)
_ = plt.fill_between(
np.arange(0, 30), mean_lower, mean_upper, color='green', alpha=0.2)
_ = plt.fill_between(np.arange(0, 30), pred_lower, pred_upper, color='grey',
label='counts', alpha=0.2)
plt.xlabel('Day')
plt.ylabel('Daily Sample Size')
plt.title('Posterior Mean')
plt.legend()
<matplotlib.legend.Legend at 0x7f93ff4735c0>
forecast_samples, rate_samples = sample_forecasted_counts(
sts_model,
posterior_latent_rates=unconstrained_rate_samples,
posterior_params=param_samples,
# Days to forecast:
num_steps_forecast=30,
num_sampled_forecasts=100)
forecast_samples = np.squeeze(forecast_samples)
plot_forecast_helper(observed_counts, forecast_samples, CI=80)