
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
अवलोकन
मशीन लर्निंग एल्गोरिदम आमतौर पर कम्प्यूटेशनल रूप से महंगे होते हैं। इस प्रकार यह सुनिश्चित करने के लिए कि आप अपने मॉडल का सबसे अनुकूलित संस्करण चला रहे हैं, अपने मशीन लर्निंग एप्लिकेशन के प्रदर्शन को मापना महत्वपूर्ण है। अपने TensorFlow कोड के निष्पादन को प्रोफाइल करने के लिए TensorFlow Profiler का उपयोग करें।
सेट अप
from datetime import datetime
from packaging import version
import os
TensorFlow प्रोफाइलर TensorFlow और TensorBoard (के नवीनतम संस्करण की आवश्यकता है >=2.2 )।
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
पुष्टि करें कि TensorFlow GPU तक पहुंच सकता है।
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
TensorBoard कॉलबैक के साथ एक छवि वर्गीकरण मॉडल को प्रशिक्षित करें
इस ट्यूटोरियल में, आप प्रदर्शन प्रोफ़ाइल में वर्गीकृत छवियों के लिए एक मॉडल के प्रशिक्षण के द्वारा प्राप्त की पर कब्जा कर TensorFlow प्रोफाइलर की क्षमताओं का पता लगाने MNIST डाटासेट ।
प्रशिक्षण डेटा आयात करने के लिए TensorFlow डेटासेट का उपयोग करें और इसे प्रशिक्षण और परीक्षण सेट में विभाजित करें।
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
0 और 1 के बीच होने वाले पिक्सेल मानों को सामान्य करके प्रशिक्षण और परीक्षण डेटा को प्रीप्रोसेस करें।
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
केरस का उपयोग करके छवि वर्गीकरण मॉडल बनाएं।
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
प्रदर्शन प्रोफाइल को कैप्चर करने के लिए एक TensorBoard कॉलबैक बनाएं और मॉडल को प्रशिक्षित करते समय इसे कॉल करें।
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
मॉडल प्रशिक्षण प्रदर्शन को प्रोफाइल करने के लिए TensorFlow Profiler का उपयोग करें
TensorFlow Profiler TensorBoard के भीतर एम्बेडेड है। Colab मैजिक का उपयोग करके TensorBoard लोड करें और इसे लॉन्च करें। प्रोफ़ाइल टैब पर नेविगेट करके प्रदर्शन प्रोफाइल देखें।
# Load the TensorBoard notebook extension.
%load_ext tensorboard
इस मॉडल के लिए प्रदर्शन प्रोफ़ाइल नीचे दी गई छवि के समान है।
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
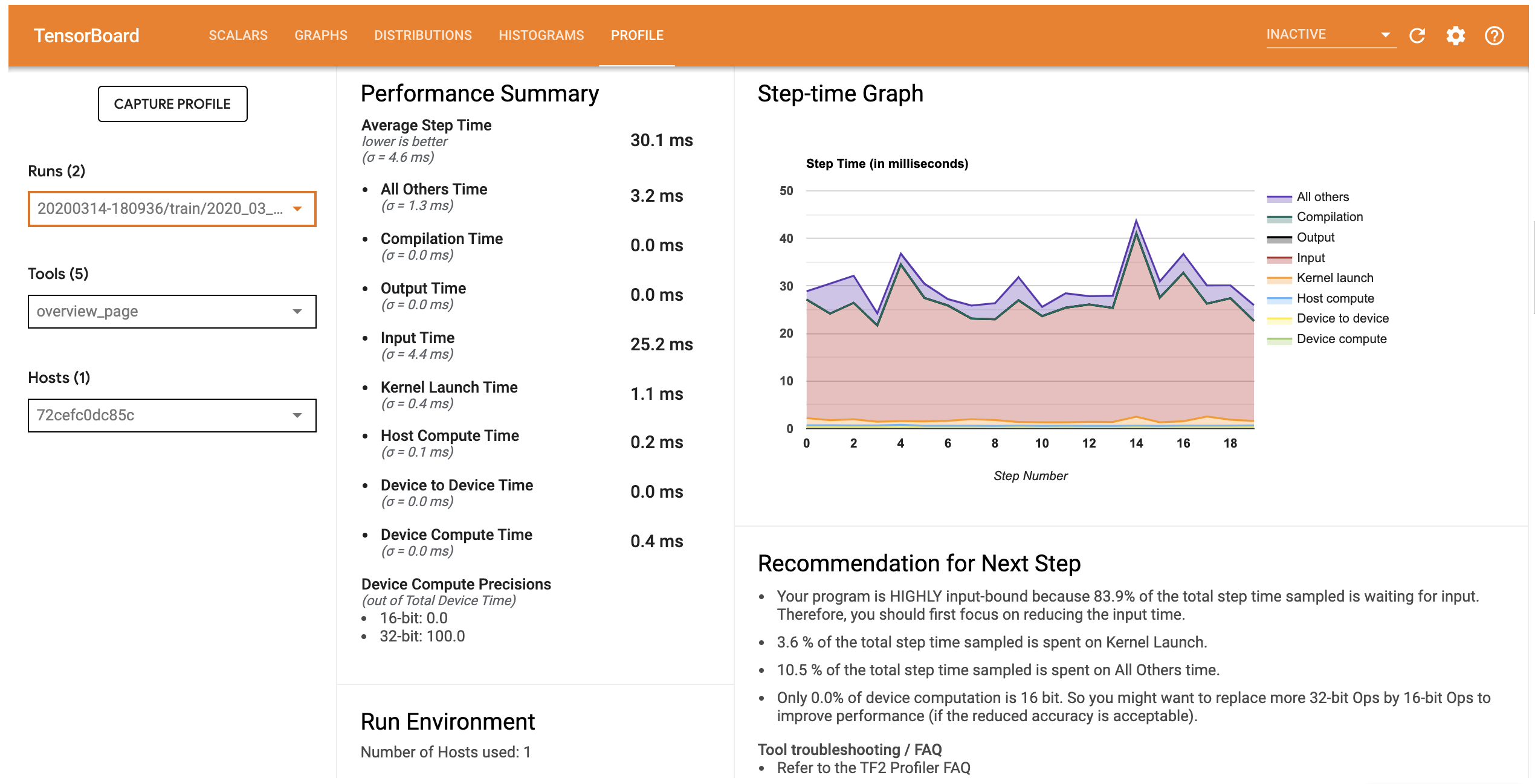
प्रोफ़ाइल टैब ओवरव्यू पृष्ठ जो आप से पता चलता है अपने मॉडल के प्रदर्शन का एक उच्च-स्तरीय सारांश खोलता है। स्टेप-टाइम ग्राफ को दाईं ओर देखते हुए, आप देख सकते हैं कि मॉडल अत्यधिक इनपुट बाउंड है (यानी, यह डेटा इनपुट पाईपलाइन में बहुत समय बिताता है)। अवलोकन पृष्ठ आपको संभावित अगले चरणों के बारे में सुझाव भी देता है जिनका पालन करके आप अपने मॉडल के प्रदर्शन को अनुकूलित कर सकते हैं।
यह समझने के लिए जहां प्रदर्शन टोंटी इनपुट पाइपलाइन में होता है उपकरण बाईं तरफ ड्रॉपडाउन से ट्रेस व्यूअर चुनें। ट्रेस व्यूअर आपको प्रोफाइलिंग अवधि के दौरान सीपीयू और जीपीयू पर हुई विभिन्न घटनाओं की एक समयरेखा दिखाता है।
ट्रेस व्यूअर लंबवत अक्ष पर एकाधिक ईवेंट समूह दिखाता है। प्रत्येक ईवेंट समूह में कई क्षैतिज ट्रैक होते हैं, जो ट्रेस ईवेंट से भरे होते हैं। ट्रैक एक थ्रेड या GPU स्ट्रीम पर निष्पादित ईवेंट के लिए एक ईवेंट टाइमलाइन है। अलग-अलग इवेंट टाइमलाइन ट्रैक पर रंगीन, आयताकार ब्लॉक होते हैं। समय बाएं से दाएं चलता है। कीबोर्ड शॉर्टकट का उपयोग करके ट्रेस घटनाओं नेविगेट W (ज़ूम), S (ज़ूम आउट), A (स्क्रॉल छोड़ दिया), और D (स्क्रॉल दाएं)।
एक आयत एक ट्रेस घटना का प्रतिनिधित्व करता है। चल टूल बार में माउस कर्सर आइकन का चयन करें (या कीबोर्ड शॉर्टकट का उपयोग करें 1 ) और ट्रेस घटना क्लिक करें यह विश्लेषण करने के लिए। यह घटना के बारे में जानकारी प्रदर्शित करेगा, जैसे कि इसका प्रारंभ समय और अवधि।
क्लिक करने के अलावा, आप ट्रेस ईवेंट के समूह का चयन करने के लिए माउस को खींच सकते हैं। यह आपको उस क्षेत्र की सभी घटनाओं की एक सूची के साथ एक घटना सारांश देगा। का प्रयोग करें M चयनित घटनाओं की समय अवधि को मापने के लिए कुंजी।
ट्रेस इवेंट यहां से एकत्र किए जाते हैं:
- सीपीयू सीपीयू घटनाओं नामित एक घटना समूह के तहत प्रदर्शित किया जाता है
/host:CPU। प्रत्येक ट्रैक CPU पर एक थ्रेड का प्रतिनिधित्व करता है। CPU ईवेंट में इनपुट पाइपलाइन ईवेंट, GPU ऑपरेशन (op) शेड्यूलिंग ईवेंट, CPU op निष्पादन ईवेंट आदि शामिल हैं। - GPU: GPU घटनाओं लगाया जाता घटना समूहों के तहत प्रदर्शित किया जाता है
/device:GPU:। प्रत्येक ईवेंट समूह GPU पर एक स्ट्रीम का प्रतिनिधित्व करता है।
डीबग प्रदर्शन बाधाएं
अपनी इनपुट पाइपलाइन में प्रदर्शन बाधाओं का पता लगाने के लिए ट्रेस व्यूअर का उपयोग करें। नीचे दी गई छवि प्रदर्शन प्रोफ़ाइल का एक स्नैपशॉट है।
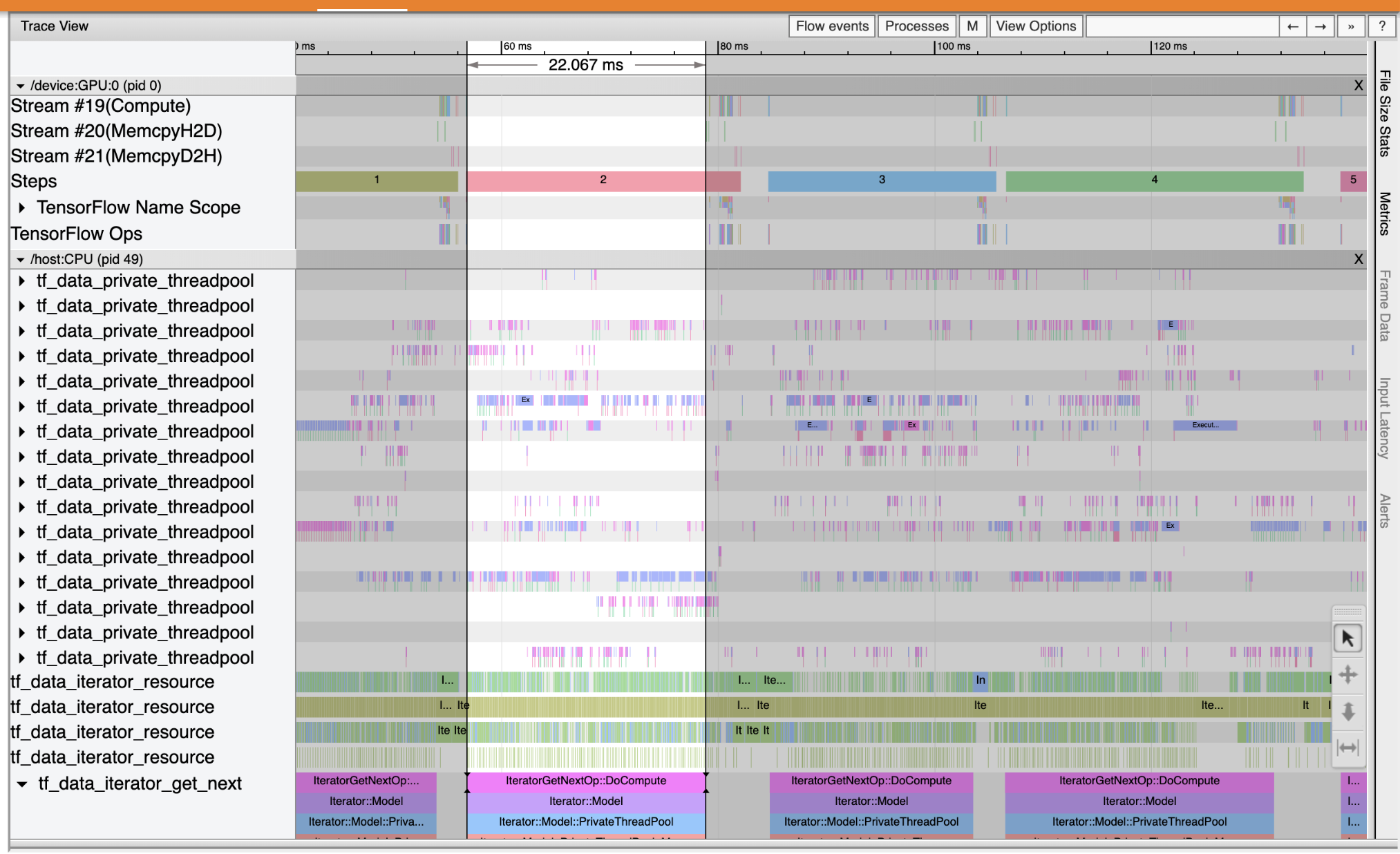
घटना निशान को देखते हुए, आप देख सकते हैं कि GPU निष्क्रिय है, जबकि tf_data_iterator_get_next सेशन CPU पर चल रहा है। यह ऑप इनपुट डेटा को संसाधित करने और प्रशिक्षण के लिए GPU को भेजने के लिए जिम्मेदार है। सामान्य नियम के रूप में, डिवाइस (GPU/TPU) को हमेशा सक्रिय रखना एक अच्छा विचार है।
का प्रयोग करें tf.data इनपुट पाइपलाइन अनुकूलन करने के लिए एपीआई। इस मामले में, आइए प्रशिक्षण डेटासेट को कैश करें और डेटा को प्रीफ़ेच करें ताकि यह सुनिश्चित हो सके कि GPU को संसाधित करने के लिए डेटा हमेशा उपलब्ध है। देखें यहाँ का उपयोग कर के बारे में अधिक जानकारी के लिए tf.data अपने इनपुट पाइपलाइनों अनुकूलन करने के लिए।
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
मॉडल को फिर से प्रशिक्षित करें और पहले से कॉलबैक का पुन: उपयोग करके प्रदर्शन प्रोफ़ाइल कैप्चर करें।
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
पुनः प्रारंभ TensorBoard और अद्यतन इनपुट पाइप लाइन के लिए प्रदर्शन प्रोफ़ाइल निरीक्षण करने के लिए प्रोफ़ाइल टैब खोलें।
अनुकूलित इनपुट पाइपलाइन वाले मॉडल के लिए प्रदर्शन प्रोफ़ाइल नीचे की छवि के समान है।
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
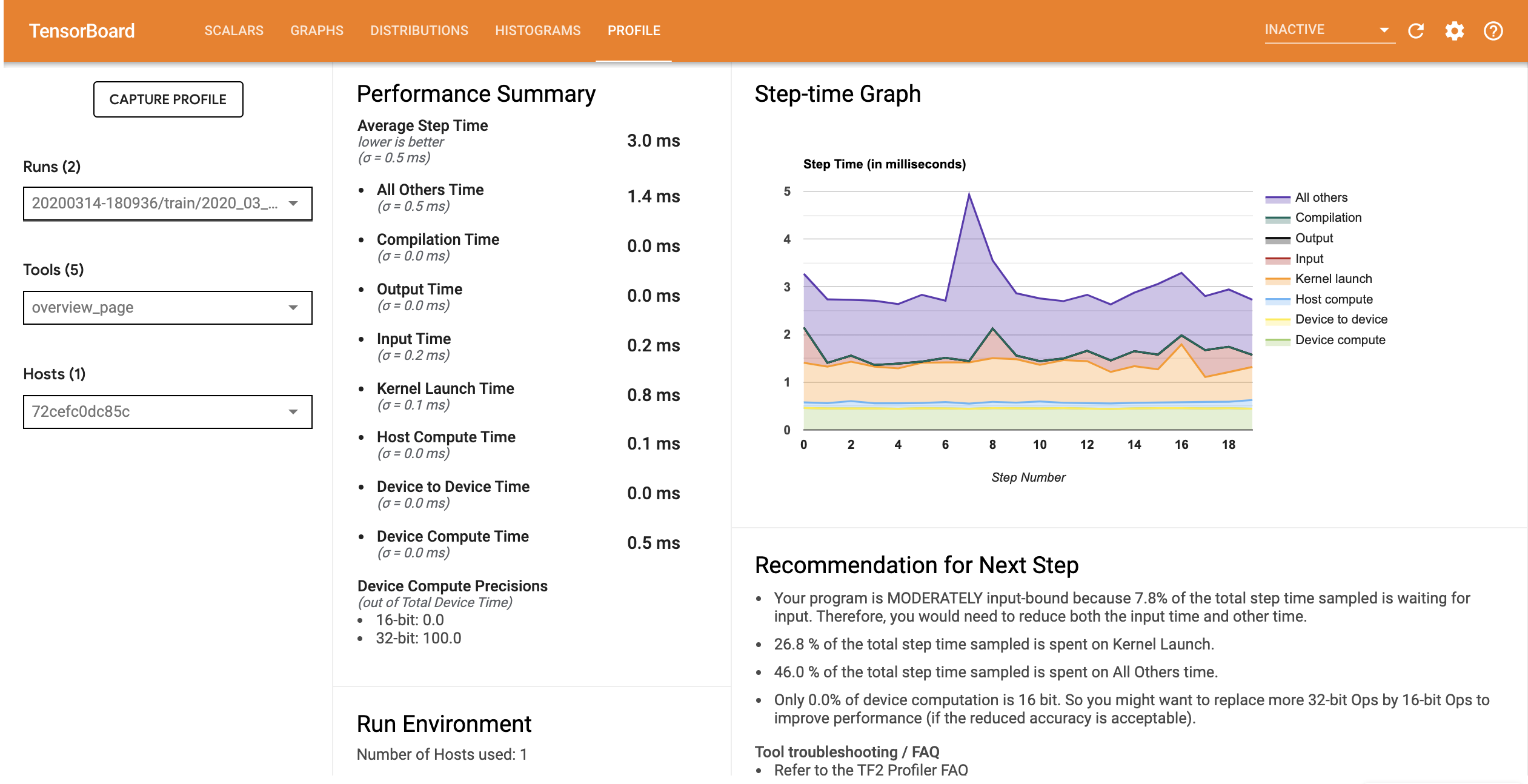
अवलोकन पृष्ठ से, आप देख सकते हैं कि औसत चरण समय कम हो गया है क्योंकि इनपुट चरण समय है। स्टेप-टाइम ग्राफ यह भी इंगित करता है कि मॉडल अब अत्यधिक इनपुट बाध्य नहीं है। अनुकूलित इनपुट पाइपलाइन के साथ ट्रेस इवेंट की जांच करने के लिए ट्रेस व्यूअर खोलें।
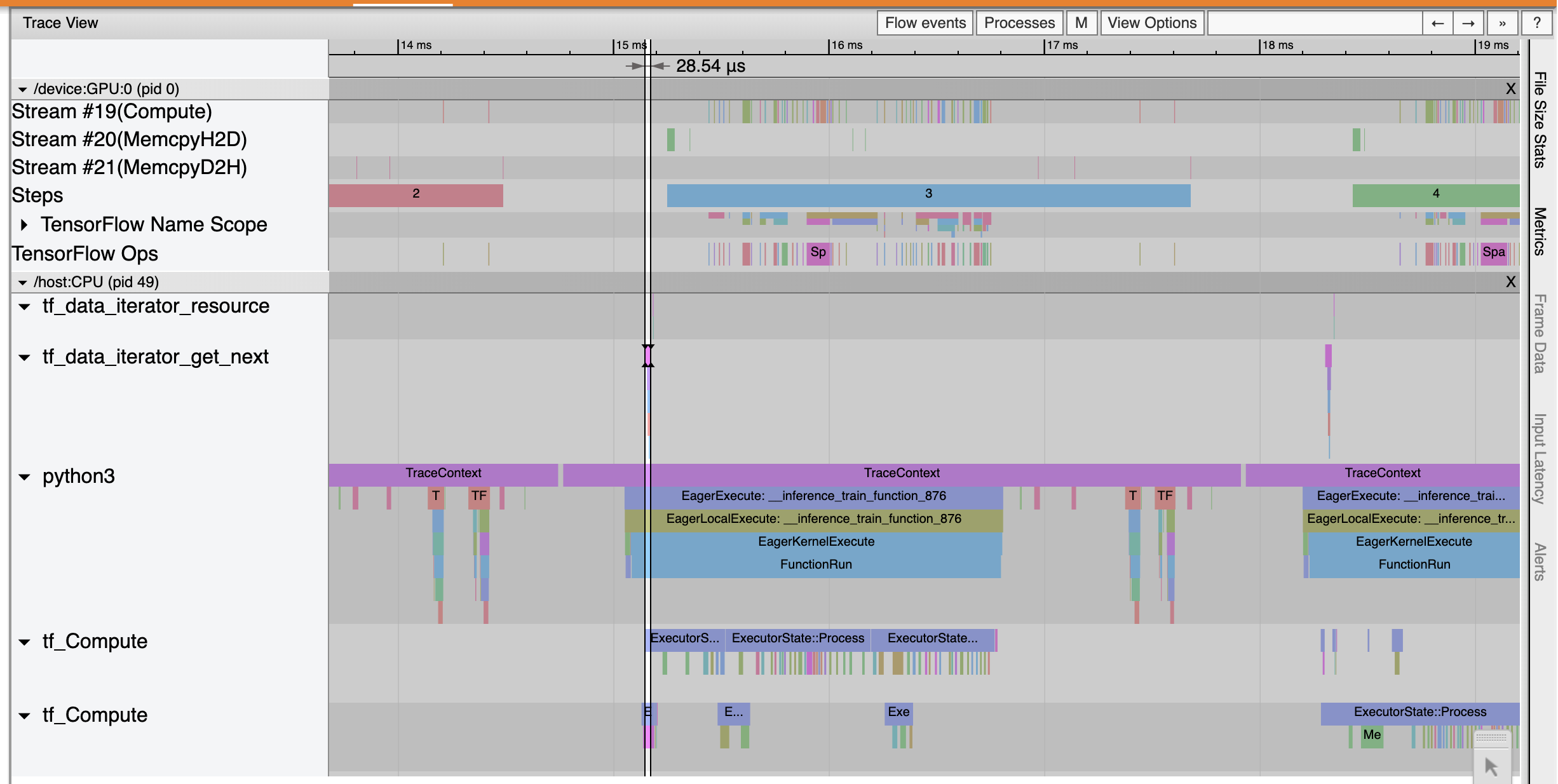
ट्रेस दर्शक शो कि tf_data_iterator_get_next सेशन बहुत तेजी से निष्पादित करता है। इसलिए GPU को प्रशिक्षण करने के लिए डेटा की एक स्थिर धारा मिलती है और मॉडल प्रशिक्षण के माध्यम से बेहतर उपयोग प्राप्त होता है।
सारांश
मॉडल प्रशिक्षण प्रदर्शन को प्रोफाइल और डीबग करने के लिए TensorFlow Profiler का उपयोग करें। पढ़ें प्रोफाइलर गाइड और घड़ी TF 2 में प्रदर्शन की रूपरेखा TensorFlow प्रोफाइलर के बारे में अधिक जानने के लिए TensorFlow देव शिखर सम्मेलन 2020 से बात करते हैं।