
Chỉ số Công bằng được thiết kế để hỗ trợ các nhóm đánh giá và cải thiện các mô hình giải quyết các mối quan ngại về tính công bằng khi hợp tác với bộ công cụ Tensorflow rộng hơn. Công cụ này hiện đang được nhiều sản phẩm của chúng tôi sử dụng tích cực trong nội bộ và hiện có sẵn ở phiên bản BETA để dùng thử cho các trường hợp sử dụng của riêng bạn.
Chỉ số Công bằng là gì?
Chỉ số công bằng là một thư viện cho phép tính toán dễ dàng các số liệu công bằng thường được xác định cho các bộ phân loại nhị phân và đa lớp. Nhiều công cụ hiện có để đánh giá mối quan tâm về tính công bằng không hoạt động tốt trên các bộ dữ liệu và mô hình quy mô lớn. Tại Google, điều quan trọng là chúng tôi phải có những công cụ có thể hoạt động trên các hệ thống có hàng tỷ người dùng. Chỉ số công bằng sẽ cho phép bạn đánh giá trên mọi quy mô trường hợp sử dụng.
Đặc biệt, Chỉ số Công bằng bao gồm khả năng:
- Đánh giá sự phân bố của các tập dữ liệu
- Đánh giá hiệu suất của mô hình, được chia thành các nhóm người dùng được xác định
- Cảm thấy tự tin về kết quả của mình với khoảng tin cậy và đánh giá ở nhiều ngưỡng
- Đi sâu vào từng phần riêng lẻ để khám phá nguyên nhân gốc rễ và cơ hội cải tiến
Tải xuống gói pip bao gồm:
- Xác thực dữ liệu Tensorflow (TFDV)
- Phân tích mô hình dòng chảy (TFMA)
- Chỉ số công bằng
- Công cụ Điều gì xảy ra nếu (WIT)
Sử dụng các chỉ báo công bằng với mô hình Tensorflow
dữ liệu
Để chạy Chỉ báo công bằng với TFMA, hãy đảm bảo tập dữ liệu đánh giá được gắn nhãn cho các tính năng mà bạn muốn phân tích. Nếu bạn không có các tính năng lát cắt chính xác cho mối quan tâm về tính công bằng của mình, bạn có thể khám phá việc cố gắng tìm một bộ đánh giá có chức năng đó hoặc xem xét các tính năng proxy trong bộ tính năng của bạn có thể làm nổi bật sự khác biệt về kết quả. Để được hướng dẫn thêm, xem tại đây .
Người mẫu
Bạn có thể sử dụng lớp Công cụ ước tính Tensorflow để xây dựng mô hình của mình. Hỗ trợ cho các mẫu Keras sẽ sớm có trên TFMA. Nếu bạn muốn chạy TFMA trên mô hình Keras, vui lòng xem phần “TFMA bất khả tri về mô hình” bên dưới.
Sau khi Công cụ ước tính của bạn được đào tạo, bạn sẽ cần xuất mô hình đã lưu cho mục đích đánh giá. Để tìm hiểu thêm, hãy xem hướng dẫn TFMA .
Cấu hình các lát cắt
Tiếp theo, xác định các phần bạn muốn đánh giá:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
Nếu bạn muốn đánh giá các lát cắt giao nhau (ví dụ: cả màu lông và chiều cao), bạn có thể đặt như sau:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
Tính toán số liệu công bằng
Thêm lệnh gọi lại Chỉ báo công bằng vào danh sách metrics_callback . Trong lệnh gọi lại, bạn có thể xác định danh sách các ngưỡng mà mô hình sẽ được đánh giá.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
Trước khi chạy cấu hình, hãy xác định xem bạn có muốn bật tính toán khoảng tin cậy hay không. Khoảng tin cậy được tính toán bằng cách sử dụng Poisson bootstrapping và yêu cầu tính toán lại trên 20 mẫu.
compute_confidence_intervals = True
Chạy quy trình đánh giá TFMA:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
Hiển thị các chỉ số công bằng
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
Mẹo sử dụng Chỉ báo Công bằng:
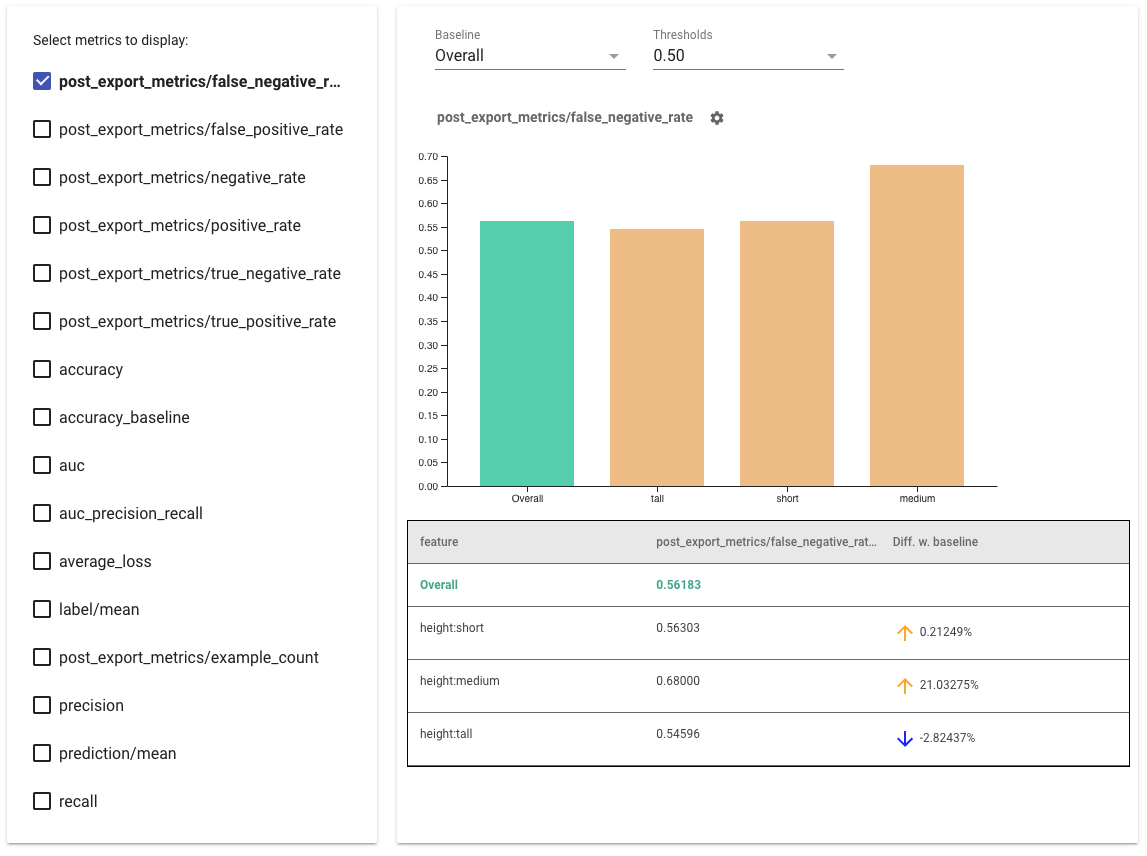
- Chọn số liệu để hiển thị bằng cách chọn các hộp ở phía bên trái. Các biểu đồ riêng lẻ cho từng số liệu sẽ xuất hiện trong tiện ích theo thứ tự.
- Thay đổi lát đường cơ sở , thanh đầu tiên trên biểu đồ, bằng cách sử dụng bộ chọn thả xuống. Deltas sẽ được tính toán với giá trị cơ bản này.
- Chọn ngưỡng bằng bộ chọn thả xuống. Bạn có thể xem nhiều ngưỡng trên cùng một biểu đồ. Các ngưỡng đã chọn sẽ được in đậm và bạn có thể nhấp vào ngưỡng được in đậm để bỏ chọn.
- Di chuột qua một thanh để xem số liệu cho phần đó.
- Xác định sự khác biệt với đường cơ sở bằng cách sử dụng cột "Khác biệt với đường cơ sở", xác định chênh lệch phần trăm giữa lát cắt hiện tại và đường cơ sở.
- Khám phá sâu các điểm dữ liệu của một lát cắt bằng cách sử dụng Công cụ What-If . Xem ở đây để biết ví dụ.
Hiển thị các chỉ số công bằng cho nhiều mô hình
Các chỉ số công bằng cũng có thể được sử dụng để so sánh các mô hình. Thay vì truyền vào một eval_result duy nhất, hãy truyền vào một đối tượng multi_eval_results, đây là một từ điển ánh xạ hai tên mô hình tới các đối tượng eval_result.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
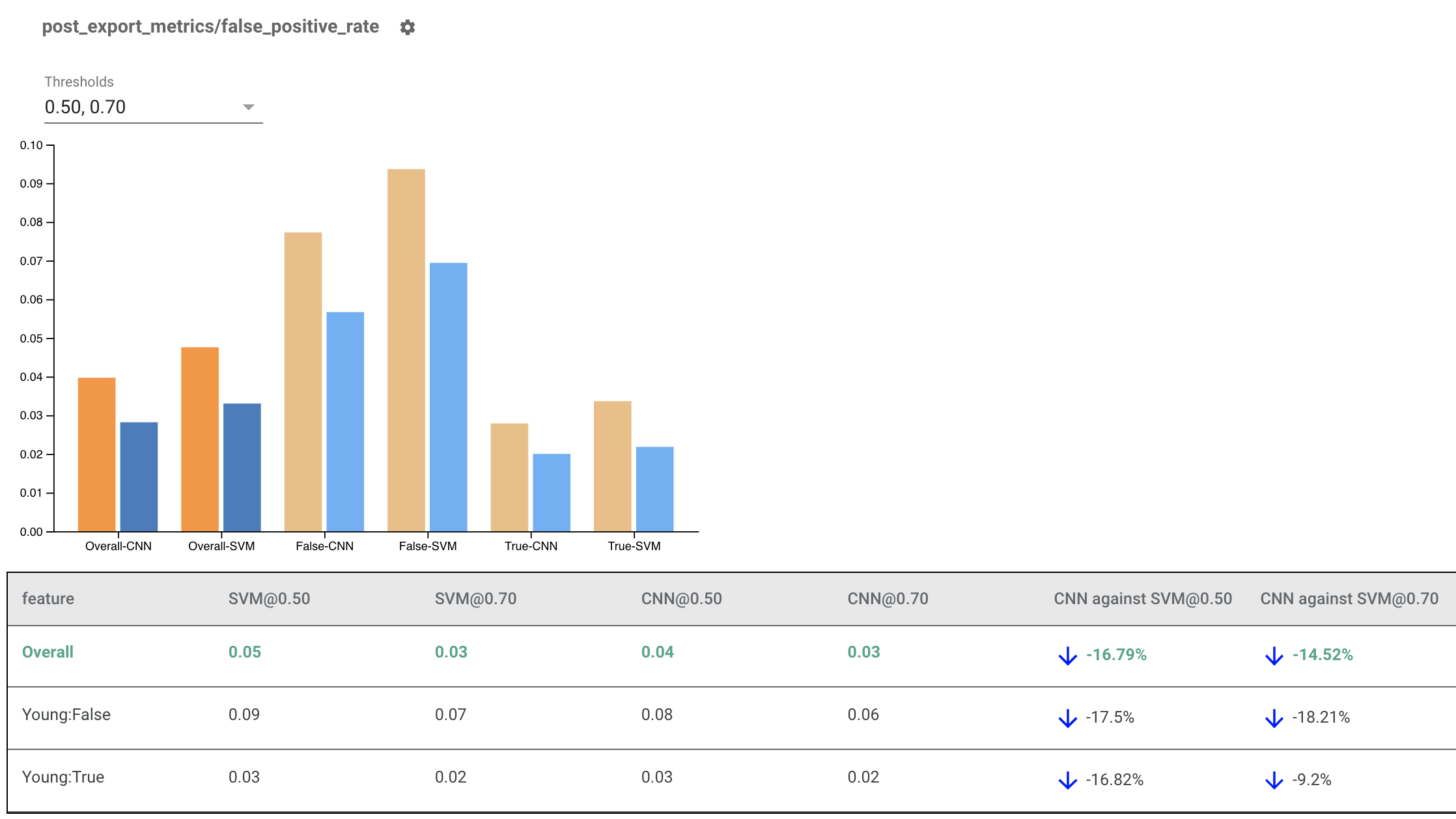
So sánh mô hình có thể được sử dụng cùng với so sánh ngưỡng. Ví dụ: bạn có thể so sánh hai mô hình ở hai bộ ngưỡng để tìm ra sự kết hợp tối ưu cho số liệu công bằng của mình.
Sử dụng Chỉ báo Công bằng với các Mô hình không phải TensorFlow
Để hỗ trợ tốt hơn cho những khách hàng có mô hình và quy trình công việc khác nhau, chúng tôi đã phát triển một thư viện đánh giá không phụ thuộc vào mô hình đang được đánh giá.
Bất kỳ ai muốn đánh giá hệ thống máy học của họ đều có thể sử dụng hệ thống này, đặc biệt nếu bạn có các mô hình không dựa trên TensorFlow. Bằng cách sử dụng Apache Beam Python SDK, bạn có thể tạo tệp nhị phân đánh giá TFMA độc lập rồi chạy tệp đó để phân tích mô hình của mình.
dữ liệu
Bước này nhằm cung cấp tập dữ liệu mà bạn muốn chạy đánh giá. Nó phải ở định dạng tf.Example proto có nhãn, dự đoán và các tính năng khác mà bạn có thể muốn sử dụng.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
Người mẫu
Thay vì chỉ định một mô hình, bạn tạo một cấu hình và trình trích xuất eval bất khả tri của mô hình để phân tích cú pháp và cung cấp dữ liệu mà TFMA cần để tính toán các số liệu. Thông số ModelAgnosticConfig xác định các tính năng, dự đoán và nhãn sẽ được sử dụng từ các ví dụ đầu vào.
Để làm điều này, hãy tạo bản đồ đối tượng với các khóa đại diện cho tất cả các đối tượng bao gồm nhãn và khóa dự đoán cũng như các giá trị đại diện cho loại dữ liệu của đối tượng địa lý.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
Tạo cấu hình bất khả tri của mô hình bằng cách sử dụng khóa nhãn, khóa dự đoán và bản đồ tính năng.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
Thiết lập Trình trích xuất bất khả tri mô hình
Trình trích xuất được sử dụng để trích xuất các tính năng, nhãn và dự đoán từ đầu vào bằng cách sử dụng cấu hình bất khả tri của mô hình. Và nếu bạn muốn cắt dữ liệu của mình, bạn cũng cần xác định thông số khóa lát , chứa thông tin về các cột bạn muốn cắt.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
Tính toán số liệu công bằng
Là một phần của EvalSharedModel , bạn có thể cung cấp tất cả các số liệu mà bạn muốn đánh giá mô hình của mình. Số liệu được cung cấp dưới dạng lệnh gọi lại số liệu giống như số liệu được xác định trong post_export_metrics hoặc fairness_indicators .
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
Nó cũng sử dụng một construct_fn được sử dụng để tạo biểu đồ tensorflow nhằm thực hiện đánh giá.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
Sau khi mọi thứ đã được thiết lập, hãy sử dụng một trong các hàm ExtractEvaluate hoặc ExtractEvaluateAndWriteResults do model_eval_lib cung cấp để đánh giá mô hình.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
Cuối cùng, hiển thị Chỉ báo Công bằng bằng cách sử dụng hướng dẫn từ phần "Kết xuất Chỉ báo Công bằng" ở trên.
Thêm ví dụ
Thư mục ví dụ về Chỉ số Công bằng chứa một số ví dụ:
- Fairness_Indicators_Example_Colab.ipynb cung cấp thông tin tổng quan về Chỉ báo công bằng trong Phân tích mô hình TensorFlow và cách sử dụng nó với tập dữ liệu thực. Sổ ghi chép này cũng đề cập đến Xác thực dữ liệu TensorFlow và Công cụ What-If , hai công cụ để phân tích các mô hình TensorFlow được đóng gói cùng với Chỉ báo công bằng.
- Fairness_Indicators_on_TF_Hub.ipynb trình bày cách sử dụng Chỉ báo công bằng để so sánh các mô hình được đào tạo về các phần nhúng văn bản khác nhau. Sổ ghi chép này sử dụng nội dung nhúng văn bản từ TensorFlow Hub , thư viện của TensorFlow để xuất bản, khám phá và sử dụng lại các thành phần mô hình.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb trình bày cách trực quan hóa các Chỉ báo Công bằng trong TensorBoard.