
TensorFlow সার্ভিং স্থাপন করার পরে এবং আপনার ক্লায়েন্টের কাছ থেকে অনুরোধ জারি করার পরে, আপনি লক্ষ্য করতে পারেন যে অনুরোধগুলি আপনার প্রত্যাশার চেয়ে বেশি সময় নেয়, অথবা আপনি যে থ্রুপুটটি পছন্দ করতেন তা অর্জন করতে পারছেন না।
এই নির্দেশিকায়, আমরা TensorBoard এর প্রোফাইলার ব্যবহার করব, যা আপনি ইতিমধ্যেই প্রোফাইল মডেল প্রশিক্ষণে ব্যবহার করতে পারেন, আমাদের ডিবাগ করতে এবং অনুমান কার্যক্ষমতা উন্নত করতে সাহায্য করার জন্য অনুমান অনুরোধগুলি ট্রেস করতে।
আপনার মডেল, অনুরোধ এবং TensorFlow পরিবেশন দৃষ্টান্ত অপ্টিমাইজ করতে পারফরম্যান্স গাইডে নির্দেশিত সেরা অনুশীলনের সাথে আপনার এই গাইডটি ব্যবহার করা উচিত।
ওভারভিউ
উচ্চ স্তরে, আমরা TensorFlow Serving-এর gRPC সার্ভারে TensorBoard-এর প্রোফাইলিং টুল নির্দেশ করব। যখন আমরা টেনসরফ্লো সার্ভিং-এ একটি অনুমান অনুরোধ পাঠাই, তখন আমরা একই সাথে টেনসরবোর্ড UI ব্যবহার করব যাতে এই অনুরোধের চিহ্নগুলি ক্যাপচার করতে বলা হয়। পর্দার আড়ালে, TensorBoard টেনসরফ্লো সার্ভিং-এর সাথে জিআরপিসি-তে কথা বলবে এবং অনুমান অনুরোধের জীবনকালের একটি বিশদ ট্রেস প্রদান করতে বলবে। TensorBoard তারপর প্রতিটি কম্পিউট ডিভাইসে প্রতিটি থ্রেডের কার্যকলাপকে কল্পনা করবে ( profiler::TraceMe এর সাথে সংহত করা কোড) টেনসরবোর্ড UI-তে আমাদের ব্যবহারের জন্য অনুরোধের জীবনকালের সময়কালে।
পূর্বশর্ত
-
Tensorflow>=2.0.0 - টেনসরবোর্ড (টিএফ যদি
pipমাধ্যমে ইনস্টল করা হয় তবে ইনস্টল করা উচিত) - ডকার (যা আমরা টিএফ সার্ভিং>=2.1.0 ছবি ডাউনলোড এবং চালানোর জন্য ব্যবহার করব)
TensorFlow সার্ভিং সহ মডেল স্থাপন করুন
এই উদাহরণের জন্য, আমরা ডকার ব্যবহার করব, টেনসরফ্লো সার্ভিং স্থাপনের প্রস্তাবিত উপায়, একটি খেলনা মডেল হোস্ট করতে যা টেনসরফ্লো সার্ভিং গিথুব রিপোজিটরিতে পাওয়া f(x) = x / 2 + 2 গণনা করে।
TensorFlow সার্ভিং উৎস ডাউনলোড করুন।
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
ডকারের মাধ্যমে টেনসরফ্লো সার্ভিং চালু করুন এবং হাফ_প্লাস_টু মডেলটি স্থাপন করুন।
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
অন্য টার্মিনালে, মডেলটি সঠিকভাবে স্থাপন করা হয়েছে তা নিশ্চিত করতে মডেলটিকে জিজ্ঞাসা করুন
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
TensorBoard এর প্রোফাইলার সেট আপ করুন
অন্য টার্মিনালে, আপনার মেশিনে TensorBoard টুল চালু করুন, অনুমান ট্রেস ইভেন্টগুলি সংরক্ষণ করার জন্য একটি ডিরেক্টরি প্রদান করে:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
TensorBoard UI দেখতে http://localhost:6006/-এ নেভিগেট করুন। প্রোফাইল ট্যাবে নেভিগেট করতে উপরে ড্রপ-ডাউন মেনু ব্যবহার করুন। ক্যাপচার প্রোফাইলে ক্লিক করুন এবং Tensorflow Serving-এর gRPC সার্ভারের ঠিকানা প্রদান করুন।
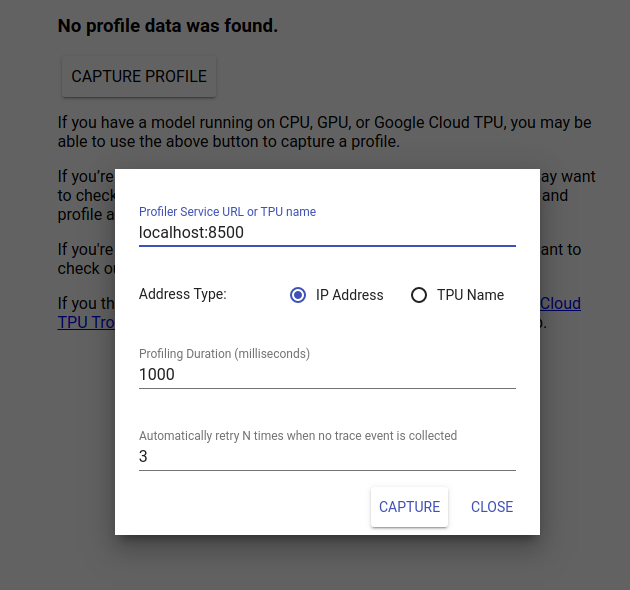
যত তাড়াতাড়ি আপনি "ক্যাপচার" চাপবেন, TensorBoard মডেল সার্ভারে প্রোফাইল অনুরোধ পাঠাতে শুরু করবে। উপরের কথোপকথনে, আপনি প্রতিটি অনুরোধের জন্য সময়সীমা এবং কোনো ট্রেস ইভেন্ট সংগ্রহ না করলে টেনসরবোর্ড কতবার পুনরায় চেষ্টা করবে উভয়ই সেট করতে পারেন। আপনি যদি একটি ব্যয়বহুল মডেল প্রোফাইলিং করেন, তাহলে অনুমান অনুরোধ সম্পূর্ণ হওয়ার আগে প্রোফাইল অনুরোধের সময় শেষ না হয় তা নিশ্চিত করার জন্য আপনি সময়সীমা বাড়াতে চাইতে পারেন।
একটি অনুমান অনুরোধ পাঠান এবং প্রোফাইল করুন
TensorBoard UI-তে ক্যাপচার টিপুন এবং তার পরে দ্রুত TF সার্ভিং-এ একটি অনুমান অনুরোধ পাঠান।
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
আপনি একটি "সফলভাবে প্রোফাইল ক্যাপচার করুন৷ অনুগ্রহ করে রিফ্রেশ করুন৷" টোস্ট পর্দার নীচে প্রদর্শিত হবে. এর মানে হল TensorBoard TensorFlow Serving থেকে ট্রেস ইভেন্টগুলি পুনরুদ্ধার করতে সক্ষম হয়েছে এবং সেগুলি আপনার logdir সেভ করেছে। প্রোফাইলারের ট্রেস ভিউয়ারের সাথে অনুমান অনুরোধটি কল্পনা করতে পৃষ্ঠাটি রিফ্রেশ করুন, যেমনটি পরবর্তী বিভাগে দেখা গেছে।
অনুমান অনুরোধ ট্রেস বিশ্লেষণ

আপনি এখন সহজেই দেখতে পারেন আপনার অনুমান অনুরোধের ফলে কী গণনা হচ্ছে। সঠিক শুরুর সময় এবং প্রাচীরের সময়কালের মতো আরও তথ্য পেতে আপনি যেকোনো আয়তক্ষেত্রে (ট্রেস ইভেন্ট) জুম করে ক্লিক করতে পারেন।
একটি উচ্চ-স্তরে, আমরা টেনসরফ্লো রানটাইমের সাথে সম্পর্কিত দুটি থ্রেড এবং একটি তৃতীয়টি REST সার্ভারের অন্তর্গত, HTTP অনুরোধ গ্রহণ করা এবং একটি টেনসরফ্লো সেশন তৈরি করা দেখতে পাই।
SessionRun এর ভিতরে কি হয় তা দেখতে আমরা জুম ইন করতে পারি।

দ্বিতীয় থ্রেডে, আমরা একটি প্রাথমিক এক্সিকিউটরস্টেট::প্রসেস কল দেখতে পাচ্ছি যেখানে কোনও টেনসরফ্লো অপস চালানো হয় না তবে প্রাথমিক পদক্ষেপগুলি কার্যকর করা হয়।
প্রথম থ্রেডে, আমরা প্রথম ভেরিয়েবলটি পড়ার কল দেখতে পাচ্ছি, এবং দ্বিতীয় ভেরিয়েবলটিও উপলব্ধ হলে, গুণটি কার্যকর করে এবং ক্রমানুসারে কার্নেল যোগ করে। অবশেষে, এক্সিকিউটর ইঙ্গিত দেয় যে এর গণনা DoneCallback কল করে করা হয়েছে এবং সেশন বন্ধ করা যেতে পারে।
পরবর্তী পদক্ষেপ
যদিও এটি একটি সাধারণ উদাহরণ, আপনি আরও জটিল মডেলগুলি প্রোফাইল করতে একই প্রক্রিয়া ব্যবহার করতে পারেন, যা আপনাকে আপনার মডেল আর্কিটেকচারের কর্মক্ষমতা উন্নত করতে ধীরগতির অপস বা বাধাগুলি সনাক্ত করতে দেয়।
অনুমান কর্মক্ষমতা অপ্টিমাইজ করার বিষয়ে আরও জানতে টেনসরবোর্ডের প্রোফাইলার এবং টেনসরফ্লো সার্ভিং পারফরম্যান্স গাইডের বৈশিষ্ট্যগুলির আরও সম্পূর্ণ টিউটোরিয়ালের জন্য অনুগ্রহ করে টেনসরবোর্ড প্রোফাইলার গাইড দেখুন।