
Sau khi triển khai Dịch vụ TensorFlow và đưa ra yêu cầu từ khách hàng, bạn có thể nhận thấy rằng các yêu cầu mất nhiều thời gian hơn dự kiến hoặc bạn không đạt được thông lượng mong muốn.
Trong hướng dẫn này, chúng tôi sẽ sử dụng Profiler của TensorBoard mà bạn có thể đã sử dụng để lập hồ sơ đào tạo mô hình , để theo dõi các yêu cầu suy luận nhằm giúp chúng tôi gỡ lỗi và cải thiện hiệu suất suy luận.
Bạn nên sử dụng hướng dẫn này kết hợp với các phương pháp hay nhất được nêu trong Hướng dẫn hiệu suất để tối ưu hóa mô hình, yêu cầu và phiên bản Cung cấp TensorFlow của bạn.
Tổng quan
Ở cấp độ cao hơn, chúng tôi sẽ trỏ công cụ Hồ sơ của TensorBoard tới máy chủ gRPC của TensorFlow Serve. Khi gửi yêu cầu suy luận tới Tensorflow Serve, chúng tôi cũng sẽ đồng thời sử dụng TensorBoard UI để yêu cầu nó ghi lại dấu vết của yêu cầu này. Đằng sau hậu trường, TensorBoard sẽ nói chuyện với TensorFlow Phục vụ qua gRPC và yêu cầu nó cung cấp dấu vết chi tiết về thời gian tồn tại của yêu cầu suy luận. Sau đó, TensorBoard sẽ trực quan hóa hoạt động của mọi luồng trên mọi thiết bị điện toán (mã chạy được tích hợp với profiler::TraceMe ) trong suốt thời gian tồn tại của yêu cầu trên giao diện người dùng TensorBoard để chúng tôi sử dụng.
Điều kiện tiên quyết
-
Tensorflow>=2.0.0 - TensorBoard (nên được cài đặt nếu TF được cài đặt qua
pip) - Docker (mà chúng tôi sẽ sử dụng để tải xuống và chạy phân phối TF>=2.1.0 hình ảnh)
Triển khai mô hình với TensorFlow Serve
Trong ví dụ này, chúng tôi sẽ sử dụng Docker, cách được đề xuất để triển khai Dịch vụ Tensorflow, để lưu trữ mô hình đồ chơi tính toán f(x) = x / 2 + 2 được tìm thấy trong kho lưu trữ Tensorflow Serve Github .
Tải xuống nguồn cung cấp TensorFlow.
git clone https://github.com/tensorflow/serving /tmp/serving
cd /tmp/serving
Khởi chạy Dịch vụ TensorFlow qua Docker và triển khai mô hình Half_plus_two.
docker pull tensorflow/serving
MODELS_DIR="$(pwd)/tensorflow_serving/servables/tensorflow/testdata"
docker run -it --rm -p 8500:8500 -p 8501:8501 \
-v $MODELS_DIR/saved_model_half_plus_two_cpu:/models/half_plus_two \
-v /tmp/tensorboard:/tmp/tensorboard \
-e MODEL_NAME=half_plus_two \
tensorflow/serving
Trong một thiết bị đầu cuối khác, truy vấn mô hình để đảm bảo mô hình được triển khai chính xác
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
Thiết lập Profiler của TensorBoard
Trong một thiết bị đầu cuối khác, khởi chạy công cụ TensorBoard trên máy của bạn, cung cấp một thư mục để lưu các sự kiện theo dõi suy luận vào:
mkdir -p /tmp/tensorboard
tensorboard --logdir /tmp/tensorboard --port 6006
Điều hướng đến http://localhost:6006/ để xem giao diện người dùng TensorBoard. Sử dụng menu thả xuống ở trên cùng để điều hướng đến tab Hồ sơ. Nhấp vào Capture Profile và cung cấp địa chỉ máy chủ gRPC của Tensorflow Serve.
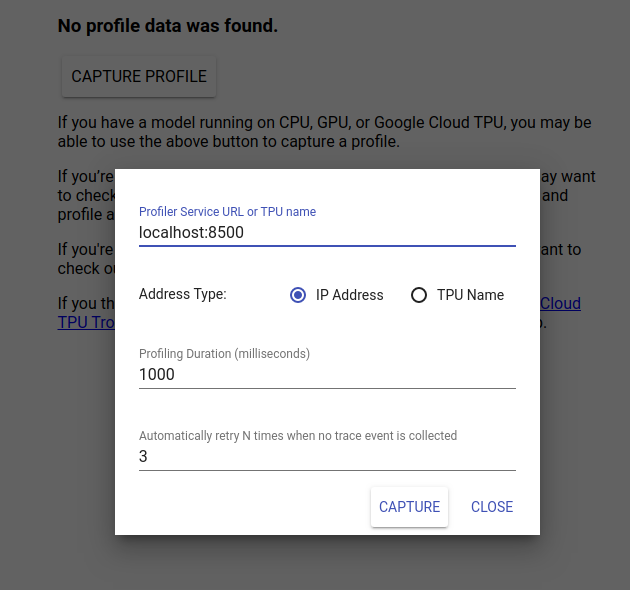
Ngay sau khi bạn nhấn "Chụp", TensorBoard sẽ bắt đầu gửi yêu cầu hồ sơ đến máy chủ mô hình. Trong hộp thoại ở trên, bạn có thể đặt cả thời hạn cho mỗi yêu cầu và tổng số lần Tensorboard sẽ thử lại nếu không thu thập được sự kiện theo dõi nào. Nếu bạn đang lập hồ sơ cho một mô hình đắt tiền, bạn có thể muốn tăng thời hạn để đảm bảo yêu cầu hồ sơ không hết thời gian trước khi yêu cầu suy luận hoàn tất.
Gửi và lập hồ sơ yêu cầu suy luận
Nhấn Capture trên giao diện người dùng TensorBoard và nhanh chóng gửi yêu cầu suy luận tới TF Serve.
curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST \
http://localhost:8501/v1/models/half_plus_two:predict
Bạn sẽ thấy thông báo "Chụp hồ sơ thành công. Vui lòng làm mới." bánh mì nướng xuất hiện ở cuối màn hình. Điều này có nghĩa là TensorBoard có thể truy xuất các sự kiện theo dõi từ TensorFlow Serve và lưu chúng vào logdir của bạn. Làm mới trang để trực quan hóa yêu cầu suy luận bằng Trình xem dấu vết của Trình hồ sơ, như được thấy trong phần tiếp theo.
Phân tích dấu vết yêu cầu suy luận

Bây giờ bạn có thể dễ dàng xem quá trình tính toán nào đang diễn ra do yêu cầu suy luận của bạn. Bạn có thể phóng to và nhấp vào bất kỳ hình chữ nhật nào (theo dõi sự kiện) để biết thêm thông tin như thời gian bắt đầu chính xác và thời lượng của bức tường.
Ở cấp độ cao, chúng tôi thấy hai luồng thuộc thời gian chạy TensorFlow và luồng thứ ba thuộc về máy chủ REST, xử lý việc nhận yêu cầu HTTP và tạo Phiên TensorFlow.
Chúng ta có thể phóng to để xem điều gì xảy ra bên trong SessionRun.

Trong luồng thứ hai, chúng ta thấy lệnh gọi ExecutorState::Process ban đầu trong đó không có hoạt động TensorFlow nào chạy nhưng các bước khởi tạo được thực thi.
Trong luồng đầu tiên, chúng ta thấy lệnh gọi để đọc biến đầu tiên và khi biến thứ hai cũng có sẵn, hãy thực hiện phép nhân và thêm hạt nhân theo trình tự. Cuối cùng, Executor báo hiệu rằng việc tính toán của nó đã được thực hiện bằng cách gọi DoneCallback và Session có thể được đóng lại.
Các bước tiếp theo
Mặc dù đây là một ví dụ đơn giản nhưng bạn có thể sử dụng quy trình tương tự để lập cấu hình các mô hình phức tạp hơn nhiều, cho phép bạn xác định các hoạt động chậm hoặc tắc nghẽn trong kiến trúc mô hình của mình để cải thiện hiệu suất của nó.
Vui lòng tham khảo Hướng dẫn về Trình biên dịch TensorBoard để có hướng dẫn đầy đủ hơn về các tính năng của Trình biên dịch TensorBoard và Hướng dẫn hiệu suất cung cấp TensorFlow để tìm hiểu thêm về cách tối ưu hóa hiệu suất suy luận.