
مثال على مكون رئيسي في TensorFlow Extended
 عرض المصدر على جيثب
عرض المصدر على جيثبيوضح مثال دفتر ملاحظات colab هذا كيف يمكن استخدام التحقق من صحة بيانات TensorFlow (TFDV) لفحص مجموعة البيانات الخاصة بك وتصورها. يتضمن ذلك النظر في الإحصائيات الوصفية ، واستنتاج المخطط ، والتحقق من الأخطاء وإصلاحها وإصلاحها ، والتحقق من الانحراف والانحراف في مجموعة البيانات الخاصة بنا. من المهم أن تفهم خصائص مجموعة البيانات الخاصة بك ، بما في ذلك كيف يمكن أن تتغير بمرور الوقت في خط أنابيب الإنتاج. من المهم أيضًا البحث عن الحالات الشاذة في بياناتك ، ومقارنة مجموعات بيانات التدريب والتقييم والعرض للتأكد من أنها متسقة.
سنستخدم بيانات من مجموعة بيانات رحلات سيارات الأجرة الصادرة عن مدينة شيكاغو.
اقرأ المزيد حول مجموعة البيانات في Google BigQuery . استكشف مجموعة البيانات الكاملة في BigQuery UI .
الأعمدة في مجموعة البيانات هي:
| pickup_community_area | أجرة | رحلة_الشهر |
| رحلة_بدء_ساعة | رحلة_البدء_اليوم | trip_start_timestamp |
| pickup_latitude | pickup_longitude | dropoff_latitude |
| dropoff_longitude | رحلة_مايلز | pickup_census_tract |
| dropoff_census_tract | نوع الدفع | شركة |
| رحلة_ثواني | منطقة_المجتمع | نصائح |
تثبيت واستيراد الحزم
قم بتثبيت حزم التحقق من صحة بيانات TensorFlow.
ترقية النقطة
لتجنب ترقية Pip في نظام عند التشغيل محليًا ، تحقق للتأكد من أننا نعمل في Colab. يمكن بالطبع ترقية الأنظمة المحلية بشكل منفصل.
try:
import colab
!pip install --upgrade pip
except:
pass
تثبيت حزم التحقق من صحة البيانات
قم بتثبيت حزم وتبعيات التحقق من صحة بيانات TensorFlow ، والتي تستغرق بضع دقائق. قد ترى تحذيرات وأخطاء تتعلق بإصدارات التبعية غير المتوافقة ، والتي ستحلها في القسم التالي.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
استيراد TensorFlow وإعادة تحميل الحزم المحدثة
تعمل الخطوة السابقة على تحديث الحزم الافتراضية في بيئة Gooogle Colab ، لذلك يجب إعادة تحميل موارد الحزمة لحل التبعيات الجديدة.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
تحقق من إصدارات TensorFlow والتحقق من صحة البيانات قبل المتابعة.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
قم بتحميل مجموعة البيانات
سنقوم بتنزيل مجموعة البيانات الخاصة بنا من Google Cloud Storage.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
حساب وتصور الإحصاءات
سنستخدم أولاً tfdv.generate_statistics_from_csv لحساب إحصائيات بيانات التدريب الخاصة بنا. (تجاهل التحذيرات السريعة)
يمكن أن يحسب TFDV الإحصائيات الوصفية التي توفر نظرة عامة سريعة على البيانات من حيث الميزات الموجودة وأشكال توزيعات قيمتها.
داخليًا ، يستخدم TFDV إطار عمل المعالجة المتوازي للبيانات الخاص بـ Apache Beam لتوسيع نطاق حساب الإحصائيات على مجموعات البيانات الكبيرة. بالنسبة للتطبيقات التي ترغب في الاندماج بشكل أعمق مع TFDV (على سبيل المثال ، إرفاق إنشاء الإحصائيات في نهاية خط أنابيب توليد البيانات) ، تعرض API أيضًا Beam PT Transform لتوليد الإحصائيات.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
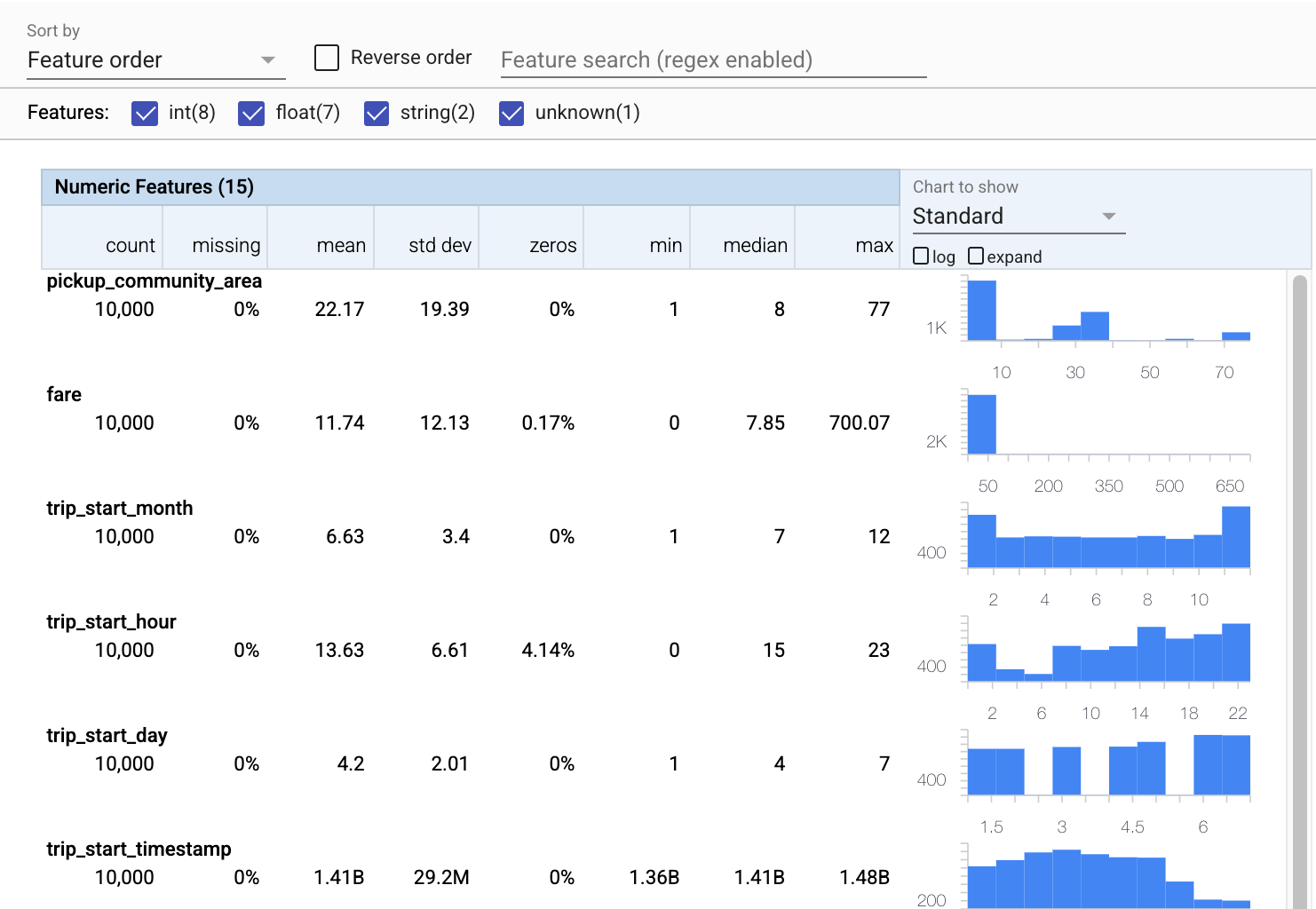
الآن دعنا نستخدم tfdv.visualize_statistics ، الذي يستخدم Facets لإنشاء تصور موجز لبيانات التدريب الخاصة بنا:
- لاحظ أن الميزات الرقمية والميزات القطعية يتم تصورها بشكل منفصل ، وأنه يتم عرض المخططات التي توضح توزيعات كل ميزة.
- لاحظ أن الميزات ذات القيم المفقودة أو الصفرية تعرض نسبة مئوية باللون الأحمر كمؤشر مرئي قد تكون هناك مشكلات مع أمثلة في تلك الميزات. النسبة المئوية هي النسبة المئوية للأمثلة التي تحتوي على قيم مفقودة أو صفرية لهذه الميزة.
- لاحظ أنه لا توجد أمثلة ذات قيم لـ
pickup_census_tract. هذه فرصة لتقليل الأبعاد! - حاول النقر فوق "توسيع" فوق الرسوم البيانية لتغيير العرض
- حاول التمرير فوق الأشرطة في المخططات لعرض نطاقات وأعداد المجموعات
- حاول التبديل بين المقياسين اللوغاريتمي والخطي ، ولاحظ كيف يكشف مقياس السجل عن مزيد من التفاصيل حول ميزة
payment_typeالفئوية - حاول تحديد "الكميات" من قائمة "مخطط العرض" ، ومرر الماوس فوق العلامات لإظهار النسب المئوية
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
استنتج مخططًا
الآن دعنا نستخدم tfdv.infer_schema لإنشاء مخطط لبياناتنا. يحدد المخطط قيود البيانات ذات الصلة بـ ML. تتضمن قيود المثال نوع البيانات لكل معلم ، سواء كانت رقمية أو فئوية ، أو تكرار تواجدها في البيانات. بالنسبة إلى الميزات الفئوية ، يحدد المخطط أيضًا النطاق - قائمة القيم المقبولة. نظرًا لأن كتابة مخطط ما يمكن أن تكون مهمة شاقة ، خاصة بالنسبة لمجموعات البيانات التي تحتوي على الكثير من الميزات ، فإن TFDV يوفر طريقة لإنشاء نسخة أولية من المخطط بناءً على الإحصائيات الوصفية.
يعد الحصول على المخطط الصحيح أمرًا مهمًا لأن بقية خط أنابيب الإنتاج الخاص بنا سيعتمد على المخطط الذي ينشئه TFDV ليكون صحيحًا. يوفر المخطط أيضًا وثائق للبيانات ، وبالتالي يكون مفيدًا عندما يعمل مطورو مختلفون على نفس البيانات. دعنا نستخدم tfdv.display_schema لعرض المخطط المستنتج حتى نتمكن من مراجعته.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
تحقق من بيانات التقييم بحثًا عن الأخطاء
حتى الآن كنا نبحث فقط في بيانات التدريب. من المهم أن تتوافق بيانات التقييم الخاصة بنا مع بيانات التدريب الخاصة بنا ، بما في ذلك أنها تستخدم نفس المخطط. من المهم أيضًا أن تتضمن بيانات التقييم أمثلة على نفس نطاقات القيم تقريبًا لميزاتنا العددية مثل بيانات التدريب لدينا ، بحيث تكون تغطيتنا لسطح الخسارة أثناء التقييم هي نفسها تقريبًا أثناء التدريب. وينطبق الشيء نفسه على السمات الفئوية. خلافًا لذلك ، قد تكون لدينا مشكلات تدريبية لم يتم تحديدها أثناء التقييم ، لأننا لم نقم بتقييم جزء من سطح خسارتنا.
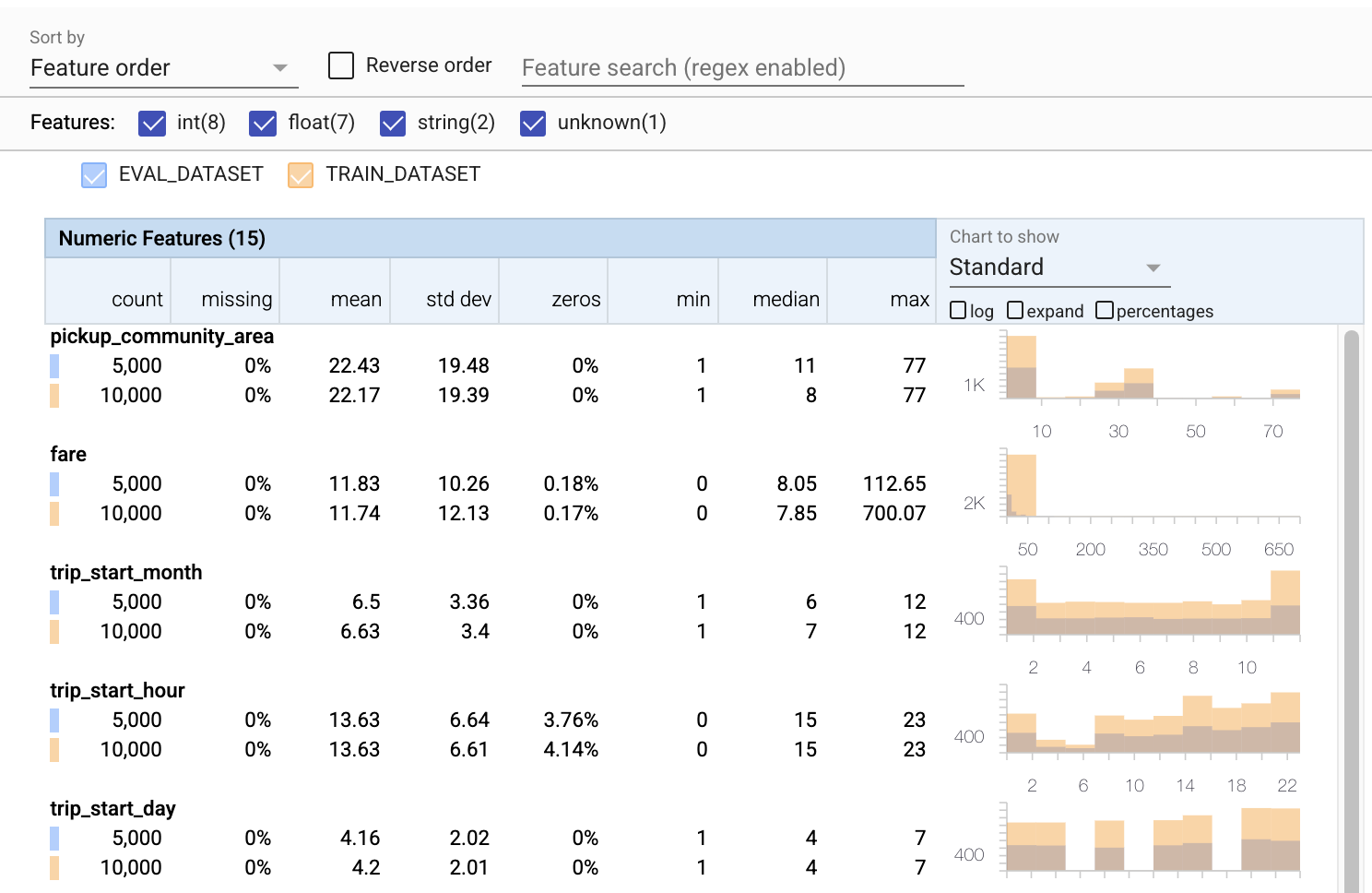
- لاحظ أن كل ميزة تتضمن الآن إحصاءات لكل من مجموعات بيانات التدريب والتقييم.
- لاحظ أن المخططات تحتوي الآن على مجموعات بيانات التدريب والتقييم متراكبة ، مما يسهل مقارنتها.
- لاحظ أن المخططات تتضمن الآن طريقة عرض النسب المئوية ، والتي يمكن دمجها مع السجل أو المقاييس الخطية الافتراضية.
- لاحظ أن متوسط ومتوسط
trip_milesيختلفان في التدريب عن مجموعات بيانات التقييم. هل سيسبب ذلك مشاكل؟ - واو ، تختلف
tipsالقصوى للتدريب عن مجموعات بيانات التقييم. هل سيسبب ذلك مشاكل؟ - انقر فوق توسيع في مخطط الميزات الرقمية ، وحدد مقياس السجل. راجع خاصية
trip_secondsالفرق في هل سيفوت التقييم أجزاء من سطح الخسارة؟
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
تحقق من وجود أخطاء في التقييم
هل تتطابق مجموعة بيانات التقييم الخاصة بنا مع المخطط من مجموعة بيانات التدريب الخاصة بنا؟ هذا مهم بشكل خاص للميزات الفئوية ، حيث نريد تحديد نطاق القيم المقبولة.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
إصلاح الانحرافات التقييمية في المخطط
وجه الفتاة! يبدو أن لدينا بعض القيم الجديدة company في بيانات التقييم الخاصة بنا ، والتي لم تكن موجودة في بيانات التدريب الخاصة بنا. لدينا أيضًا قيمة جديدة لـ payment_type . يجب اعتبار هذه حالات شاذة ، لكن ما نقرر فعله حيالها يعتمد على معرفتنا بمجال البيانات. إذا كان الانحراف يشير حقًا إلى خطأ في البيانات ، فيجب إصلاح البيانات الأساسية. خلافًا لذلك ، يمكننا ببساطة تحديث المخطط لتضمين القيم في مجموعة بيانات Eval.
ما لم نغير مجموعة بيانات التقييم الخاصة بنا ، لا يمكننا إصلاح كل شيء ، ولكن يمكننا إصلاح الأشياء في المخطط التي نقبلها بسهولة. يتضمن ذلك استرخاء وجهة نظرنا بشأن ما هو وما هو ليس شذوذًا لميزات معينة ، بالإضافة إلى تحديث مخططنا ليشمل القيم المفقودة للميزات الفئوية. لقد مكننا TFDV من اكتشاف ما نحتاج إلى إصلاحه.
دعونا نجري هذه الإصلاحات الآن ، ثم نراجعها مرة أخرى.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
مهلا ، انظر إلى ذلك! لقد تحققنا من أن بيانات التدريب والتقييم متسقة الآن! شكرا TFDV؛)
بيئات المخطط
قمنا أيضًا بتقسيم مجموعة بيانات "العرض" لهذا المثال ، لذلك يجب علينا التحقق من ذلك أيضًا. بشكل افتراضي ، يجب أن تستخدم جميع مجموعات البيانات في خط الأنابيب نفس المخطط ، ولكن غالبًا ما تكون هناك استثناءات. على سبيل المثال ، في التعلم الخاضع للإشراف ، نحتاج إلى تضمين تسميات في مجموعة البيانات الخاصة بنا ، ولكن عندما نقدم نموذجًا للاستدلال ، فلن يتم تضمين التسميات. في بعض الحالات ، من الضروري إدخال اختلافات طفيفة في المخطط.
يمكن استخدام البيئات للتعبير عن مثل هذه المتطلبات. على وجه الخصوص ، يمكن ربط الميزات في المخطط مع مجموعة من البيئات التي تستخدم البيئة default_environment ، in_environment ، وليس not_in_environment .
على سبيل المثال ، في مجموعة البيانات هذه ، يتم تضمين ميزة tips كتسمية للتدريب ، ولكنها مفقودة في بيانات العرض. بدون تحديد البيئة ، سيظهر على أنه شذوذ.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
سنتعامل مع ميزة tips أدناه. لدينا أيضًا قيمة INT في ثوان رحلتنا ، حيث توقع مخططنا نسبة FLOAT. من خلال جعلنا ندرك هذا الاختلاف ، يساعد TFDV في الكشف عن التناقضات في طريقة إنشاء البيانات للتدريب والخدمة. من السهل جدًا ألا تكون على دراية بمشكلات من هذا القبيل حتى يتضرر أداء النموذج ، وأحيانًا يكون ذلك كارثيًا. قد تكون أو لا تكون مشكلة كبيرة ، ولكن على أي حال يجب أن يكون هذا سببًا لمزيد من التحقيق.
في هذه الحالة ، يمكننا تحويل قيم INT بأمان إلى FLOAT ، لذلك نريد إخبار TFDV باستخدام مخططنا لاستنتاج النوع. لنفعل ذلك الآن.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
الآن لدينا فقط ميزة tips (وهي التسمية الخاصة بنا) تظهر كشذوذ ("تم إسقاط العمود"). بالطبع لا نتوقع وجود تسميات في بيانات الخدمة الخاصة بنا ، لذلك دعونا نخبر TFDV أن يتجاهل ذلك.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
تحقق من وجود انحراف وانحراف
بالإضافة إلى التحقق مما إذا كانت مجموعة البيانات تتوافق مع التوقعات المحددة في المخطط ، يوفر TFDV أيضًا وظائف لاكتشاف الانجراف والانحراف. يقوم TFDV بإجراء هذا الفحص من خلال مقارنة إحصائيات مجموعات البيانات المختلفة بناءً على مقارنات الانحراف / الانحراف المحددة في المخطط.
المغزى
يتم دعم اكتشاف الانجراف للميزات الفئوية وبين فترات متتالية من البيانات (على سبيل المثال ، بين الامتداد N والامتداد N + 1) ، مثل بين أيام مختلفة من بيانات التدريب. نحن نعبر عن الانجراف من حيث المسافة L-infinity ، ويمكنك تعيين مسافة العتبة بحيث تتلقى تحذيرات عندما يكون الانجراف أعلى من المقبول. عادةً ما يكون تحديد المسافة الصحيحة عملية تكرارية تتطلب معرفة المجال والتجريب.
انحراف
يمكن أن يكتشف TFDV ثلاثة أنواع مختلفة من الانحراف في بياناتك - انحراف المخطط ، وانحراف الميزات ، وانحراف التوزيع.
انحراف المخطط
يحدث انحراف المخطط عندما لا تتوافق بيانات التدريب والخدمة مع نفس المخطط. من المتوقع أن تلتزم بيانات التدريب والخدمة بنفس المخطط. يجب تحديد أي انحرافات متوقعة بين الاثنين (مثل وجود ميزة التسمية فقط في بيانات التدريب ولكن ليس في الخدمة) من خلال حقل البيئات في المخطط.
ميزة الانحراف
يحدث انحراف الميزة عندما تختلف قيم الميزة التي يتدرب عليها النموذج عن قيم الميزة التي يراها في وقت العرض. على سبيل المثال ، يمكن أن يحدث هذا عندما:
- يتم تعديل مصدر البيانات الذي يوفر بعض قيم الميزة بين التدريب ووقت الخدمة
- هناك منطق مختلف لتوليد الميزات بين التدريب والخدمة. على سبيل المثال ، إذا قمت بتطبيق بعض التحويل فقط في واحد من مسارين من الكود.
انحراف التوزيع
يحدث انحراف التوزيع عندما يختلف توزيع مجموعة بيانات التدريب اختلافًا كبيرًا عن توزيع مجموعة بيانات العرض. أحد الأسباب الرئيسية لانحراف التوزيع هو استخدام كود مختلف أو مصادر بيانات مختلفة لإنشاء مجموعة بيانات التدريب. سبب آخر هو آلية أخذ العينات الخاطئة التي تختار عينة فرعية غير تمثيلية من بيانات الخدمة للتدريب عليها.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
في هذا المثال ، نرى بعض الانحراف ، لكنه أقل بكثير من الحد الذي حددناه.
قم بتجميد المخطط
الآن وقد تمت مراجعة مخطط قاعدة البيانات وتنظيمه ، سنقوم بتخزينه في ملف ليعكس حالته "المجمدة".
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
متى تستخدم TFDV
من السهل التفكير في TFDV على أنه ينطبق فقط على بداية خط تدريبك ، كما فعلنا هنا ، ولكن في الحقيقة له العديد من الاستخدامات. إليك المزيد:
- التحقق من صحة البيانات الجديدة للاستدلال للتأكد من أننا لم نبدأ فجأة في تلقي الميزات السيئة
- التحقق من صحة البيانات الجديدة للاستدلال للتأكد من أن نموذجنا قد تدرب على هذا الجزء من سطح القرار
- التحقق من صحة بياناتنا بعد أن قمنا بتحويلها وأجرينا هندسة الميزات (ربما باستخدام TensorFlow Transform ) للتأكد من أننا لم نفعل شيئًا خاطئًا