
Hướng dẫn này chỉ cho bạn cách sử dụng TensorFlow Transform (thư viện tf.Transform ) để triển khai quá trình tiền xử lý dữ liệu cho máy học (ML). Thư viện tf.Transform dành cho TensorFlow cho phép bạn xác định cả chuyển đổi dữ liệu ở cấp phiên bản và cấp độ đầy đủ thông qua quy trình tiền xử lý dữ liệu. Các quy trình này được thực thi một cách hiệu quả bằng Apache Beam và chúng tạo ra dưới dạng sản phẩm phụ là biểu đồ TensorFlow để áp dụng các phép biến đổi tương tự trong quá trình dự đoán cũng như khi mô hình được phân phối.
Hướng dẫn này cung cấp ví dụ toàn diện về cách sử dụng Dataflow làm trình chạy cho Apache Beam. Nó giả định rằng bạn đã quen thuộc với BigQuery , Dataflow, Vertex AI và API TensorFlow Keras . Nó cũng giả định rằng bạn có một số kinh nghiệm sử dụng Notebook Jupyter, chẳng hạn như với Vertex AI Workbench .
Hướng dẫn này cũng giả định rằng bạn đã quen với các khái niệm về loại tiền xử lý, thách thức và tùy chọn trên Google Cloud, như được mô tả trong Tiền xử lý dữ liệu cho ML: tùy chọn và đề xuất .
Mục tiêu
- Triển khai đường dẫn Apache Beam bằng thư viện
tf.Transform. - Chạy quy trình trong Dataflow.
- Triển khai mô hình TensorFlow bằng thư viện
tf.Transform. - Đào tạo và sử dụng mô hình để dự đoán.
Chi phí
Hướng dẫn này sử dụng các thành phần có thể tính phí sau đây của Google Cloud:
Để ước tính chi phí chạy hướng dẫn này, giả sử bạn sử dụng mọi tài nguyên trong cả ngày, hãy sử dụng công cụ tính giá được cấu hình sẵn .
Trước khi bạn bắt đầu
Trong bảng điều khiển Google Cloud, trên trang chọn dự án, hãy chọn hoặc tạo dự án Google Cloud .
Đảm bảo rằng tính năng thanh toán được bật cho dự án Đám mây của bạn. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên dự án hay không .
Kích hoạt API Dataflow, Vertex AI và Notebooks. Kích hoạt các API
Sổ ghi chép Jupyter cho giải pháp này
Các sổ ghi chép Jupyter sau đây hiển thị ví dụ triển khai:
- Notebook 1 đề cập đến việc tiền xử lý dữ liệu. Thông tin chi tiết được cung cấp trong phần Triển khai đường dẫn Apache Beam sau này.
- Notebook 2 bao gồm đào tạo mô hình. Thông tin chi tiết được cung cấp trong phần Triển khai mô hình TensorFlow sau.
Trong các phần sau, bạn sao chép các sổ ghi chép này rồi thực thi các sổ ghi chép này để tìm hiểu cách hoạt động của ví dụ triển khai.
Khởi chạy phiên bản sổ ghi chép do người dùng quản lý
Trong bảng điều khiển Google Cloud, hãy truy cập trang Vertex AI Workbench .
Trên tab Sổ tay do người dùng quản lý , nhấp vào +Sổ tay mới .
Chọn TensorFlow Enterprise 2.8 (có LTS) không có GPU cho loại phiên bản.
Nhấp vào Tạo .
Sau khi bạn tạo sổ ghi chép, hãy đợi proxy tới JupyterLab hoàn tất quá trình khởi tạo. Khi sẵn sàng, Open JupyterLab sẽ hiển thị bên cạnh tên sổ ghi chép.
Sao chép sổ ghi chép
Trên tab Sổ ghi chép do người dùng quản lý , bên cạnh tên sổ ghi chép, hãy nhấp vào Mở JupyterLab . Giao diện JupyterLab mở trong tab mới.
Nếu JupyterLab hiển thị hộp thoại Đề xuất bản dựng , hãy nhấp vào Hủy để từ chối bản dựng được đề xuất.
Trên tab Trình khởi chạy , nhấp vào Terminal .
Trong cửa sổ terminal, sao chép sổ ghi chép:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Triển khai quy trình Apache Beam
Phần này và phần tiếp theo Chạy quy trình trong Dataflow cung cấp tổng quan và ngữ cảnh cho Notebook 1. Sổ ghi chép này cung cấp ví dụ thực tế để mô tả cách sử dụng thư viện tf.Transform để xử lý trước dữ liệu. Ví dụ này sử dụng tập dữ liệu Natality, được dùng để dự đoán cân nặng của trẻ dựa trên nhiều thông tin đầu vào khác nhau. Dữ liệu được lưu trữ trong bảng ngày sinh công khai trong BigQuery.
Chạy Notebook 1
Trong giao diện JupyterLab, nhấp vào Tệp > Mở từ đường dẫn , sau đó nhập đường dẫn sau:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbNhấp vào Chỉnh sửa > Xóa tất cả kết quả đầu ra .
Trong phần Cài đặt các gói cần thiết , thực thi ô đầu tiên để chạy lệnh
pip install apache-beam.Phần cuối cùng của đầu ra là như sau:
Successfully installed ...Bạn có thể bỏ qua các lỗi phụ thuộc ở đầu ra. Bạn chưa cần phải khởi động lại kernel.
Thực thi ô thứ hai để chạy lệnh
pip install tensorflow-transform. Phần cuối cùng của đầu ra là như sau:Successfully installed ... Note: you may need to restart the kernel to use updated packages.Bạn có thể bỏ qua các lỗi phụ thuộc ở đầu ra.
Nhấp chuột Hạt nhân > Khởi động lại hạt nhân .
Thực thi các ô trong phần Xác nhận các gói đã cài đặt và Tạo setup.py để cài đặt các gói vào phần vùng chứa Dataflow .
Trong phần Đặt cờ chung , bên cạnh
PROJECTvàBUCKET, thay thếyour-projectbằng ID dự án Đám mây của bạn, sau đó thực thi ô.Thực hiện tất cả các ô còn lại cho đến ô cuối cùng trong sổ ghi chép. Để biết thông tin về những việc cần làm trong mỗi ô, hãy xem hướng dẫn trong sổ tay.
Tổng quan về đường ống
Trong ví dụ về sổ ghi chép, Dataflow chạy quy trình tf.Transform trên quy mô lớn để chuẩn bị dữ liệu và tạo ra các tạo phẩm chuyển đổi. Các phần sau trong tài liệu này mô tả các chức năng thực hiện từng bước trong quy trình. Các bước tổng thể của đường ống như sau:
- Đọc dữ liệu đào tạo từ BigQuery.
- Phân tích và chuyển đổi dữ liệu đào tạo bằng thư viện
tf.Transform. - Ghi dữ liệu đào tạo đã chuyển đổi vào Cloud Storage ở định dạng TFRecord .
- Đọc dữ liệu đánh giá từ BigQuery.
- Chuyển đổi dữ liệu đánh giá bằng biểu đồ
transform_fnđược tạo ở bước 2. - Ghi dữ liệu đào tạo đã chuyển đổi vào Cloud Storage ở định dạng TFRecord.
- Viết các tạo phẩm chuyển đổi vào Cloud Storage để sử dụng sau này để tạo và xuất mô hình.
Ví dụ sau đây hiển thị mã Python cho quy trình tổng thể. Các phần tiếp theo cung cấp giải thích và danh sách mã cho từng bước.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
Đọc dữ liệu đào tạo thô từ BigQuery
Bước đầu tiên là đọc dữ liệu đào tạo thô từ BigQuery bằng hàm read_from_bq . Hàm này trả về một đối tượng raw_dataset được trích xuất từ BigQuery. Bạn chuyển giá trị data_size và chuyển giá trị step của train hoặc eval . Truy vấn nguồn BigQuery được xây dựng bằng hàm get_source_query , như trong ví dụ sau:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
Trước khi thực hiện quá trình xử lý trước tf.Transform , bạn có thể cần thực hiện quá trình xử lý dựa trên Tia Apache điển hình, bao gồm xử lý Bản đồ, Bộ lọc, Nhóm và Cửa sổ. Trong ví dụ này, mã sẽ xóa các bản ghi được đọc từ BigQuery bằng phương thức beam.Map(prep_bq_row) , trong đó prep_bq_row là một hàm tùy chỉnh. Hàm tùy chỉnh này chuyển đổi mã số cho một tính năng phân loại thành các nhãn mà con người có thể đọc được.
Ngoài ra, để sử dụng thư viện tf.Transform nhằm phân tích và chuyển đổi đối tượng raw_data được trích xuất từ BigQuery, bạn cần tạo đối tượng raw_dataset , là một bộ gồm các đối tượng raw_data và raw_metadata . Đối tượng raw_metadata được tạo bằng hàm create_raw_metadata như sau:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
Khi bạn thực thi ô trong sổ ghi chép ngay sau ô xác định phương thức này, nội dung của đối tượng raw_metadata.schema sẽ được hiển thị. Nó bao gồm các cột sau:
-
gestation_weeks(loại:FLOAT) -
is_male(loại:BYTES) -
mother_age(loại:FLOAT) -
mother_race(loại:BYTES) -
plurality(loại:FLOAT) -
weight_pounds(loại:FLOAT)
Chuyển đổi dữ liệu đào tạo thô
Hãy tưởng tượng rằng bạn muốn áp dụng các phép biến đổi tiền xử lý điển hình cho các tính năng thô đầu vào của dữ liệu huấn luyện để chuẩn bị cho ML. Những chuyển đổi này bao gồm cả hoạt động cấp độ đầy đủ và cấp độ phiên bản, như được hiển thị trong bảng sau:
| Tính năng đầu vào | Chuyển đổi | Số liệu thống kê cần thiết | Kiểu | Tính năng đầu ra |
|---|---|---|---|---|
weight_pound | Không có | Không có | NA | weight_pound |
mother_age | Bình thường hóa | nghĩa là, var | Toàn bộ | mother_age_normalized |
mother_age | Phân loại kích thước bằng nhau | lượng tử | Toàn bộ | mother_age_bucketized |
mother_age | Tính nhật ký | Không có | Cấp độ phiên bản | mother_age_log |
plurality | Cho biết đó là một con hay nhiều con | Không có | Cấp độ phiên bản | is_multiple |
is_multiple | Chuyển đổi giá trị danh nghĩa thành chỉ số số | từ ngữ | Toàn bộ | is_multiple_index |
gestation_weeks | Thang đo từ 0 đến 1 | tối thiểu, tối đa | Toàn bộ | gestation_weeks_scaled |
mother_race | Chuyển đổi giá trị danh nghĩa thành chỉ số số | từ ngữ | Toàn bộ | mother_race_index |
is_male | Chuyển đổi giá trị danh nghĩa thành chỉ số số | từ ngữ | Toàn bộ | is_male_index |
Các phép biến đổi này được triển khai trong hàm preprocess_fn , hàm này yêu cầu một từ điển các tensor ( input_features ) và trả về một từ điển các tính năng được xử lý ( output_features ).
Đoạn mã sau đây cho thấy cách triển khai hàm preprocess_fn , sử dụng các API chuyển đổi toàn phần tf.Transform (có tiền tố là tft. ) và các thao tác cấp phiên bản TensorFlow (có tiền tố là tf. ):
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
Khung tf.Transform có một số phép biến đổi khác ngoài những biến đổi trong ví dụ trước, bao gồm những biến đổi được liệt kê trong bảng sau:
| Chuyển đổi | Áp dụng cho | Sự miêu tả |
|---|---|---|
scale_by_min_max | Tính năng số | Chia tỷ lệ một cột số thành phạm vi [ output_min , output_max ] |
scale_to_0_1 | Tính năng số | Trả về một cột là cột đầu vào được chia tỷ lệ để có phạm vi [ 0 , 1 ] |
scale_to_z_score | Tính năng số | Trả về một cột được chuẩn hóa với giá trị trung bình là 0 và phương sai là 1 |
tfidf | Tính năng văn bản | Ánh xạ các số hạng trong x với tần suất số hạng của chúng * tần số tài liệu nghịch đảo |
compute_and_apply_vocabulary | Tính năng phân loại | Tạo từ vựng cho một tính năng phân loại và ánh xạ nó tới một số nguyên với từ vựng này |
ngrams | Tính năng văn bản | Tạo một SparseTensor của n-gram |
hash_strings | Tính năng phân loại | Băm chuỗi vào nhóm |
pca | Tính năng số | Tính toán PCA trên tập dữ liệu bằng cách sử dụng hiệp phương sai sai lệch |
bucketize | Tính năng số | Trả về một cột được nhóm có kích thước bằng nhau (dựa trên lượng tử), với chỉ mục nhóm được gán cho mỗi đầu vào |
Để áp dụng các phép biến đổi được triển khai trong hàm preprocess_fn cho đối tượng raw_train_dataset được tạo ở bước trước của quy trình, bạn sử dụng phương thức AnalyzeAndTransformDataset . Phương thức này yêu cầu đối tượng raw_dataset làm đầu vào, áp dụng hàm preprocess_fn và tạo ra đối tượng transformed_dataset và biểu đồ transform_fn . Đoạn mã sau minh họa quá trình xử lý này:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
Các phép biến đổi được áp dụng trên dữ liệu thô theo hai giai đoạn: giai đoạn phân tích và giai đoạn biến đổi. Hình 3 ở phần sau của tài liệu này cho thấy cách phân tách phương thức AnalyzeAndTransformDataset thành phương thức AnalyzeDataset và phương thức TransformDataset .
Giai đoạn phân tích
Trong giai đoạn phân tích, dữ liệu huấn luyện thô được phân tích theo quy trình toàn diện để tính toán số liệu thống kê cần thiết cho các chuyển đổi. Điều này bao gồm tính toán giá trị trung bình, phương sai, tối thiểu, tối đa, lượng tử và từ vựng. Quá trình phân tích yêu cầu một tập dữ liệu thô (dữ liệu thô cộng với siêu dữ liệu thô) và nó tạo ra hai kết quả đầu ra:
-
transform_fn: biểu đồ TensorFlow chứa số liệu thống kê được tính toán từ giai đoạn phân tích và logic chuyển đổi (sử dụng số liệu thống kê) làm hoạt động cấp phiên bản. Như đã thảo luận sau trong Lưu biểu đồ , biểu đồtransform_fnđược lưu để gắn vào hàmserving_fnmô hình_fn. Điều này giúp có thể áp dụng phép biến đổi tương tự cho các điểm dữ liệu dự đoán trực tuyến. -
transform_metadata: đối tượng mô tả lược đồ dự kiến của dữ liệu sau khi chuyển đổi.
Giai đoạn phân tích được minh họa trong sơ đồ sau, hình 1:

tf.Transform . Các máy phân tích tf.Transform bao gồm min , max , sum , size , mean , var , covariance , quantiles , vocabulary và pca .
Giai đoạn biến đổi
Trong giai đoạn chuyển đổi, biểu đồ transform_fn do giai đoạn phân tích tạo ra được sử dụng để chuyển đổi dữ liệu huấn luyện thô trong quy trình cấp phiên bản nhằm tạo ra dữ liệu huấn luyện đã chuyển đổi. Dữ liệu huấn luyện đã chuyển đổi được ghép nối với siêu dữ liệu đã chuyển đổi (được tạo bởi giai đoạn phân tích) để tạo ra tập dữ liệu transformed_train_dataset .
Giai đoạn biến đổi được minh họa trong sơ đồ sau, hình 2:

tf.Transform . Để xử lý trước các tính năng, bạn gọi các phép biến đổi tensorflow_transform cần thiết (được nhập dưới dạng tft trong mã) khi triển khai hàm preprocess_fn . Ví dụ: khi bạn gọi các phép toán tft.scale_to_z_score , thư viện tf.Transform sẽ chuyển lệnh gọi hàm này thành bộ phân tích phương sai và giá trị trung bình, tính toán các số liệu thống kê trong giai đoạn phân tích, sau đó áp dụng các số liệu thống kê này để chuẩn hóa tính năng số trong giai đoạn biến đổi. Tất cả điều này được thực hiện tự động bằng cách gọi phương thức AnalyzeAndTransformDataset(preprocess_fn) .
Thực thể transformed_metadata.schema được tạo bởi lệnh gọi này bao gồm các cột sau:
-
gestation_weeks_scaled(loại:FLOAT) -
is_male_index(loại:INT, is_categorical:True) -
is_multiple_index(loại:INT, is_categorical:True) -
mother_age_bucketized(loại:INT, is_categorical:True) -
mother_age_log(loại:FLOAT) -
mother_age_normalized(loại:FLOAT) -
mother_race_index(loại:INT, is_categorical:True) -
weight_pounds(loại:FLOAT)
Như đã giải thích trong các hoạt động Tiền xử lý ở phần đầu tiên của loạt bài này, việc chuyển đổi tính năng chuyển đổi các tính năng phân loại thành biểu diễn số. Sau khi chuyển đổi, các đặc điểm phân loại được biểu diễn bằng các giá trị nguyên. Trong thực thể transformed_metadata.schema , cờ is_categorical cho các cột loại INT cho biết cột đó đại diện cho một đối tượng phân loại hay một đối tượng số thực sự.
Viết dữ liệu đào tạo được chuyển đổi
Sau khi dữ liệu huấn luyện được xử lý trước bằng hàm preprocess_fn thông qua các giai đoạn phân tích và biến đổi, bạn có thể ghi dữ liệu vào một bồn chứa để sử dụng cho việc huấn luyện mô hình TensorFlow. Khi bạn thực thi quy trình Apache Beam bằng Dataflow, phần chính là Cloud Storage. Nếu không, bồn rửa là đĩa cục bộ. Mặc dù bạn có thể ghi dữ liệu dưới dạng tệp CSV gồm các tệp có định dạng có chiều rộng cố định, định dạng tệp được đề xuất cho bộ dữ liệu TensorFlow là định dạng TFRecord. Đây là định dạng nhị phân hướng bản ghi đơn giản bao gồm các thông báo bộ đệm giao thức tf.train.Example .
Mỗi bản ghi tf.train.Example chứa một hoặc nhiều tính năng. Chúng được chuyển đổi thành tensor khi chúng được đưa vào mô hình để huấn luyện. Đoạn mã sau ghi tập dữ liệu đã chuyển đổi vào tệp TFRecord ở vị trí đã chỉ định:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
Đọc, chuyển đổi và ghi dữ liệu đánh giá
Sau khi chuyển đổi dữ liệu huấn luyện và tạo biểu đồ transform_fn , bạn có thể sử dụng nó để chuyển đổi dữ liệu đánh giá. Trước tiên, bạn đọc và xóa dữ liệu đánh giá khỏi BigQuery bằng hàm read_from_bq được mô tả trước đó trong phần Đọc dữ liệu đào tạo thô từ BigQuery và chuyển giá trị eval cho tham số step . Sau đó, bạn sử dụng mã sau để chuyển đổi tập dữ liệu đánh giá thô ( raw_dataset ) sang định dạng được chuyển đổi dự kiến ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
Khi bạn chuyển đổi dữ liệu đánh giá, chỉ các thao tác cấp phiên bản mới được áp dụng, sử dụng cả logic trong biểu đồ transform_fn và số liệu thống kê được tính toán từ giai đoạn phân tích trong dữ liệu huấn luyện. Nói cách khác, bạn không phân tích dữ liệu đánh giá theo kiểu toàn diện để tính toán số liệu thống kê mới, như giá trị trung bình và phương sai để chuẩn hóa điểm z của các đặc điểm số trong dữ liệu đánh giá. Thay vào đó, bạn sử dụng số liệu thống kê được tính toán từ dữ liệu huấn luyện để chuyển đổi dữ liệu đánh giá theo kiểu cấp độ phiên bản.
Do đó, bạn sử dụng phương pháp AnalyzeAndTransform trong bối cảnh dữ liệu huấn luyện để tính toán số liệu thống kê và chuyển đổi dữ liệu. Đồng thời, bạn sử dụng phương thức TransformDataset trong bối cảnh chuyển đổi dữ liệu đánh giá để chỉ chuyển đổi dữ liệu bằng cách sử dụng số liệu thống kê được tính toán trên dữ liệu huấn luyện.
Sau đó, bạn ghi dữ liệu vào ổ lưu trữ (Bộ lưu trữ đám mây hoặc đĩa cục bộ, tùy thuộc vào trình chạy) ở định dạng TFRecord để đánh giá mô hình TensorFlow trong quá trình đào tạo. Để thực hiện việc này, bạn sử dụng hàm write_tfrecords được thảo luận trong phần Ghi dữ liệu huấn luyện được chuyển đổi . Sơ đồ sau đây, hình 3, cho thấy cách sử dụng biểu đồ transform_fn được tạo trong giai đoạn phân tích của dữ liệu huấn luyện để chuyển đổi dữ liệu đánh giá.

transform_fn .Lưu biểu đồ
Bước cuối cùng trong quy trình tiền xử lý tf.Transform là lưu trữ các thành phần lạ, bao gồm biểu đồ transform_fn được tạo ra bởi giai đoạn phân tích trên dữ liệu huấn luyện. Mã để lưu trữ các tạo phẩm được hiển thị trong hàm write_transform_artefacts sau:
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
Những hiện vật này sau này sẽ được sử dụng để đào tạo mô hình và xuất khẩu để phục vụ. Các hiện vật sau đây cũng được tạo ra, như được trình bày trong phần tiếp theo:
-
saved_model.pb: biểu thị biểu đồ TensorFlow bao gồm logic chuyển đổi (biểu đồtransform_fn), được gắn vào giao diện phục vụ mô hình để chuyển đổi các điểm dữ liệu thô sang định dạng được chuyển đổi. -
variables: bao gồm số liệu thống kê được tính toán trong giai đoạn phân tích của dữ liệu huấn luyện và được sử dụng trong logic chuyển đổi trong tạo phẩmsaved_model.pb. -
assets: bao gồm các tệp từ vựng, một tệp cho mỗi tính năng phân loại được xử lý bằng phương thứccompute_and_apply_vocabulary, được sử dụng trong quá trình cung cấp để chuyển đổi giá trị danh nghĩa thô đầu vào thành chỉ mục số. -
transformed_metadata: thư mục chứa tệp lượcschema.jsonmô tả lược đồ của dữ liệu được chuyển đổi.
Chạy quy trình trong Dataflow
Sau khi xác định đường dẫn tf.Transform , bạn chạy đường dẫn bằng Dataflow. Sơ đồ sau đây, hình 4, hiển thị biểu đồ thực thi Dataflow của đường dẫn tf.Transform được mô tả trong ví dụ.
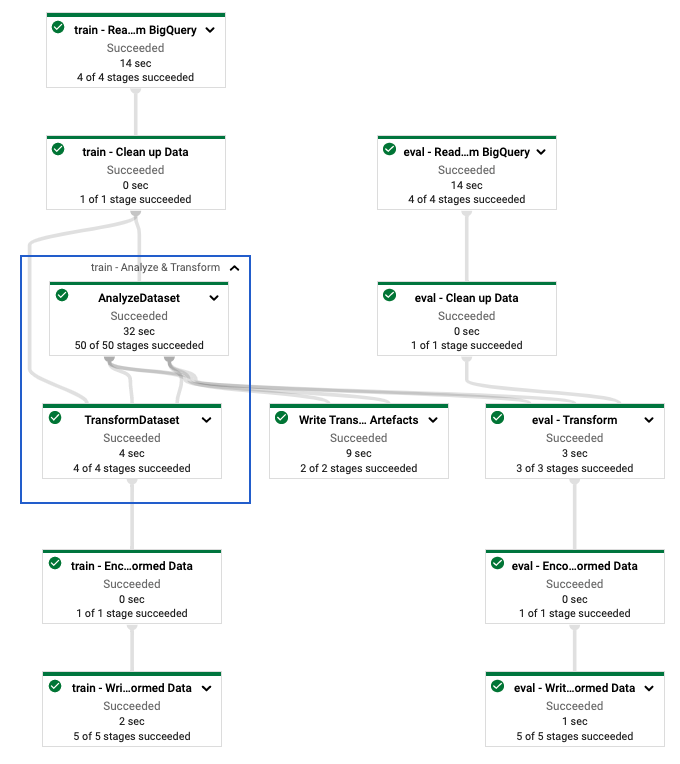
tf.Transform . Sau khi thực thi quy trình Dataflow để xử lý trước dữ liệu đào tạo và đánh giá, bạn có thể khám phá các đối tượng được tạo trong Cloud Storage bằng cách thực thi ô cuối cùng trong sổ ghi chép. Các đoạn mã trong phần này hiển thị kết quả, trong đó YOUR_BUCKET_NAME là tên bộ chứa Cloud Storage của bạn.
Dữ liệu đánh giá và đào tạo đã chuyển đổi ở định dạng TFRecord được lưu trữ tại vị trí sau:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
Các tạo phẩm biến đổi được tạo ra tại vị trí sau:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
Danh sách sau đây là đầu ra của quy trình, hiển thị các đối tượng và thành phần dữ liệu được tạo ra:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
Triển khai mô hình TensorFlow
Phần này và phần tiếp theo, Đào tạo và sử dụng mô hình để dự đoán , cung cấp thông tin tổng quan và bối cảnh cho Notebook 2. Sổ tay này cung cấp một mô hình ML mẫu để dự đoán cân nặng của trẻ. Trong ví dụ này, mô hình TensorFlow được triển khai bằng API Keras. Mô hình này sử dụng dữ liệu và tạo phẩm được tạo ra bởi quy trình tiền xử lý tf.Transform được giải thích trước đó.
Chạy Notebook 2
Trong giao diện JupyterLab, nhấp vào Tệp > Mở từ đường dẫn , sau đó nhập đường dẫn sau:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbNhấp vào Chỉnh sửa > Xóa tất cả kết quả đầu ra .
Trong phần Cài đặt các gói cần thiết , thực thi ô đầu tiên để chạy lệnh
pip install tensorflow-transform.Phần cuối cùng của đầu ra là như sau:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.Bạn có thể bỏ qua các lỗi phụ thuộc ở đầu ra.
Trong menu Kernel , chọn Khởi động lại Kernel .
Thực thi các ô trong phần Xác nhận các gói đã cài đặt và Tạo setup.py để cài đặt các gói vào phần vùng chứa Dataflow .
Trong phần Đặt cờ chung , bên cạnh
PROJECTvàBUCKET, thay thếyour-projectbằng ID dự án Đám mây của bạn, sau đó thực thi ô.Thực hiện tất cả các ô còn lại cho đến ô cuối cùng trong sổ ghi chép. Để biết thông tin về những việc cần làm trong mỗi ô, hãy xem hướng dẫn trong sổ tay.
Tổng quan về việc tạo mô hình
Các bước tạo mô hình như sau:
- Tạo các cột tính năng bằng cách sử dụng thông tin lược đồ được lưu trữ trong thư mục
transformed_metadata. - Tạo mô hình rộng và sâu bằng API Keras bằng cách sử dụng các cột tính năng làm đầu vào cho mô hình.
- Tạo hàm
tfrecords_input_fnđể đọc và phân tích dữ liệu huấn luyện và đánh giá bằng cách sử dụng các tạo phẩm biến đổi. - Huấn luyện và đánh giá mô hình.
- Xuất mô hình đã đào tạo bằng cách xác định hàm
serving_fncó biểu đồtransform_fnđược đính kèm. - Kiểm tra mô hình đã xuất bằng công cụ
saved_model_cli. - Sử dụng mô hình đã xuất để dự đoán.
Tài liệu này không giải thích cách xây dựng mô hình nên không thảo luận chi tiết về cách xây dựng hoặc huấn luyện mô hình. Tuy nhiên, các phần sau đây cho biết cách sử dụng thông tin được lưu trữ trong thư mục transform_metadata —được tạo bởi quy trình tf.Transform —để tạo các cột tính năng của mô hình. Tài liệu này cũng cho thấy cách sử dụng biểu đồ transform_fn —cũng được tạo bởi quá trình tf.Transform —trong hàm serving_fn khi mô hình được xuất để phân phối.
Sử dụng các tạo phẩm biến đổi được tạo trong đào tạo mô hình
Khi huấn luyện mô hình TensorFlow, bạn sử dụng các đối tượng train và eval đã được chuyển đổi được tạo ở bước xử lý dữ liệu trước đó. Các đối tượng này được lưu trữ dưới dạng tệp phân đoạn ở định dạng TFRecord. Thông tin lược đồ trong thư mục transformed_metadata được tạo ở bước trước có thể hữu ích trong việc phân tích dữ liệu ( các đối tượng tf.train.Example ) để đưa vào mô hình nhằm đào tạo và đánh giá.
Phân tích dữ liệu
Vì bạn đọc các tệp ở định dạng TFRecord để cung cấp dữ liệu huấn luyện và đánh giá cho mô hình, nên bạn cần phân tích từng đối tượng tf.train.Example trong các tệp để tạo từ điển các tính năng (tensor). Điều này đảm bảo rằng các tính năng được ánh xạ tới lớp đầu vào của mô hình bằng cách sử dụng các cột tính năng, đóng vai trò là giao diện đánh giá và đào tạo mô hình. Để phân tích dữ liệu, bạn sử dụng đối tượng TFTransformOutput được tạo từ các tạo phẩm được tạo ở bước trước:
Tạo một đối tượng
TFTransformOutputtừ các tạo phẩm được tạo và lưu trong bước tiền xử lý trước đó, như được mô tả trong phần Lưu biểu đồ :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Trích xuất một đối tượng
feature_spectừ đối tượngTFTransformOutput:tf_transform_output.transformed_feature_spec()Sử dụng đối tượng
feature_specđể chỉ định các tính năng có trong đối tượngtf.train.Examplenhư trong hàmtfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
Tạo các cột tính năng
Quy trình tạo ra thông tin lược đồ trong thư mục transformed_metadata mô tả lược đồ của dữ liệu đã chuyển đổi mà mô hình mong đợi để đào tạo và đánh giá. Lược đồ chứa tên tính năng và kiểu dữ liệu, chẳng hạn như sau:
-
gestation_weeks_scaled(loại:FLOAT) -
is_male_index(loại:INT, is_categorical:True) -
is_multiple_index(loại:INT, is_categorical:True) -
mother_age_bucketized(loại:INT, is_categorical:True) -
mother_age_log(loại:FLOAT) -
mother_age_normalized(loại:FLOAT) -
mother_race_index(loại:INT, is_categorical:True) -
weight_pounds(loại:FLOAT)
Để xem thông tin này, sử dụng các lệnh sau:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
Đoạn mã sau cho biết cách bạn sử dụng tên tính năng để tạo các cột tính năng:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
Mã tạo cột tf.feature_column.numeric_column cho các đối tượng số và cột tf.feature_column.categorical_column_with_identity cho các đối tượng địa lý được phân loại.
Bạn cũng có thể tạo các cột tính năng mở rộng, như được mô tả trong Tùy chọn C: TensorFlow trong phần đầu tiên của loạt bài này. Trong ví dụ được sử dụng cho loạt bài này, một tính năng mới được tạo, mother_race_X_mother_age_bucketized , bằng cách vượt qua các tính năng mother_race và mother_age_bucketized bằng cách sử dụng cột tính năng tf.feature_column.crossed_column . Sự thể hiện dày đặc, có chiều thấp của đối tượng địa lý chéo này được tạo bằng cách sử dụng cột đối tượng địa lý tf.feature_column.embedding_column .
Sơ đồ sau, hình 5, hiển thị dữ liệu đã chuyển đổi và cách sử dụng siêu dữ liệu đã chuyển đổi để xác định và huấn luyện mô hình TensorFlow:

Xuất mô hình để phục vụ dự đoán
Sau khi huấn luyện mô hình TensorFlow bằng API Keras, bạn xuất mô hình đã huấn luyện dưới dạng đối tượng SavingModel để mô hình có thể cung cấp các điểm dữ liệu mới cho dự đoán. Khi xuất mô hình, bạn phải xác định giao diện của nó—tức là lược đồ các tính năng đầu vào được mong đợi trong quá trình cung cấp. Lược đồ tính năng đầu vào này được xác định trong hàm serving_fn , như minh họa trong đoạn mã sau:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
Trong quá trình phân phối, mô hình mong đợi các điểm dữ liệu ở dạng thô (nghĩa là các tính năng thô trước khi chuyển đổi). Do đó, hàm serving_fn nhận các tính năng thô và lưu trữ chúng trong đối tượng features dưới dạng từ điển Python. Tuy nhiên, như đã thảo luận trước đó, mô hình được đào tạo mong đợi các điểm dữ liệu trong lược đồ được chuyển đổi. Để chuyển đổi các tính năng thô thành các đối tượng transformed_features mà giao diện mô hình mong đợi, bạn áp dụng biểu đồ transform_fn đã lưu cho đối tượng features bằng các bước sau:
Tạo đối tượng
TFTransformOutputtừ các tạo phẩm được tạo và lưu ở bước tiền xử lý trước đó:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Tạo một đối tượng
TransformFeaturesLayertừ đối tượngTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()Áp dụng biểu đồ
transform_fnbằng đối tượngTransformFeaturesLayer:transformed_features = model.tft_layer(features)
Sơ đồ sau, hình 6, minh họa bước cuối cùng của việc xuất mô hình để phục vụ:

transform_fn được đính kèm. Đào tạo và sử dụng mô hình để dự đoán
Bạn có thể huấn luyện mô hình cục bộ bằng cách thực thi các ô của sổ ghi chép. Để biết ví dụ về cách đóng gói mã và huấn luyện mô hình của bạn trên quy mô lớn bằng Vertex AI Training, hãy xem các mẫu và hướng dẫn trong kho lưu trữ GitHub của Google Cloud cloudml-samples .
Khi bạn kiểm tra đối tượng SavingModel đã xuất bằng công cụ saved_model_cli , bạn sẽ thấy rằng các phần tử inputs của định nghĩa chữ ký signature_def bao gồm các tính năng thô, như trong ví dụ sau:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
Các ô còn lại của sổ ghi chép cho bạn biết cách sử dụng mô hình đã xuất cho dự đoán cục bộ và cách triển khai mô hình dưới dạng vi dịch vụ bằng cách sử dụng Vertex AI Prediction. Điều quan trọng cần nhấn mạnh là điểm dữ liệu đầu vào (mẫu) đều nằm trong lược đồ thô trong cả hai trường hợp.
Dọn dẹp
Để tránh phát sinh thêm phí cho tài khoản Google Cloud của bạn đối với các tài nguyên được sử dụng trong hướng dẫn này, hãy xóa dự án chứa các tài nguyên đó.
Xóa dự án
Trong bảng điều khiển Google Cloud, hãy truy cập trang Quản lý tài nguyên .
Trong danh sách dự án, chọn dự án bạn muốn xóa rồi bấm Xóa .
Trong hộp thoại, nhập ID dự án rồi bấm Tắt máy để xóa dự án.
Tiếp theo là gì
- Để tìm hiểu về các khái niệm, thách thức và tùy chọn xử lý trước dữ liệu cho machine learning trên Google Cloud, hãy xem bài viết đầu tiên trong loạt bài này, Xử lý trước dữ liệu cho ML: tùy chọn và đề xuất .
- Để biết thêm thông tin về cách triển khai, đóng gói và chạy quy trình tf.Transform trên Dataflow, hãy xem mẫu Dự đoán thu nhập bằng Bộ dữ liệu điều tra dân số .
- Tham gia chuyên ngành Coursera về ML với TensorFlow trên Google Cloud .
- Tìm hiểu về các phương pháp hay nhất cho kỹ thuật ML trong Quy tắc ML .
- Để biết thêm kiến trúc tham khảo, sơ đồ và cách thực hành tốt nhất, hãy khám phá Trung tâm Kiến trúc Đám mây .