
| |
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
|
本教程将向您展示如何使用自定义训练循环训练机器学习模型,以按物种对企鹅进行分类。在此笔记本中,您将使用 TensorFlow 完成以下任务:
- 导入数据集
- 构建简单的线性模型
- 训练模型
- 评估模型的有效性
- 使用训练的模型进行预测
TensorFlow 编程
本教程将演示以下 TensorFlow 编程任务:
- 使用 TensorFlow Datasets API 导入数据
- 使用 Keras API 构建模型和层
企鹅分类问题
设想您是一名鸟类学家,正在寻找一种能够对您发现的每只企鹅进行分类的自动化方法。机器学习提供了许多对企鹅进行统计分类的算法。例如,复杂的机器学习程序可以根据照片对企鹅进行分类。您在本教程中构建的模型会略微简单一些。它将根据企鹅的体重、鳍状肢长度和喙(特别是嘴峰长度和宽度测量值)对企鹅进行分类。
企鹅共有 18 个种类,但在本教程中,您将仅尝试对以下三种进行分类:
- 帽带企鹅
- 金图企鹅
- 阿德利企鹅
 |
| 图 1. 帽带、金图和阿德利企鹅(作者 @allison_horst,CC BY-SA 2.0)。 |
幸运的是,有一支研究团队已经创建并共享了一个含 334 只企鹅的数据集,其中包含体重、鳍状肢长度、喙测量及其他数据。该数据集也可方便地用作企鹅 TensorFlow 数据集。
安装
为企鹅数据集安装 tfds-nightly 软件包。tfds-nightly 软件包是 TensorFlow Datasets (TFDS) 的每日构建版。有关 TFDS 的更多信息,请参阅 TensorFlow Datasets 概述。
pip install -q tfds-nightly然后,从 Colab 菜单中选择 Runtime > Restart Runtime 以重新启动 Colab 运行时。
请务必首先重新启动运行时,然后再继续本教程的其余步骤。
导入 TensorFlow 和其他所需 Python 模块。
import os
import tensorflow as tf
import tensorflow_datasets as tfds
import matplotlib.pyplot as plt
print("TensorFlow version: {}".format(tf.__version__))
print("TensorFlow Datasets version: ",tfds.__version__)
导入数据集
默认的 penguins/processed TensorFlow 数据集经清理、归一化并已准备就绪,可用于构建模型。在下载经处理的数据之前,请首先预览一个简化版本以熟悉原始企鹅调查数据。
预览数据
使用 TensorFlow Datasets tdfs.load 方法下载企鹅数据集的简化版本 (penguins/simple)。该数据集中有 344 条数据记录。将前五条记录提取到 DataFrame 对象中,以检查此数据集中的样本值:
ds_preview, info = tfds.load('penguins/simple', split='train', with_info=True)
df = tfds.as_dataframe(ds_preview.take(5), info)
print(df)
print(info.features)
带编号的行是数据记录,每行一个样本,其中:
在数据集中,企鹅物种标签以数字表示,以便于在您所构建的模型中使用。这些数字对应于以下企鹅物种:
0:阿德利企鹅1:帽带企鹅2:金图企鹅
依此顺序创建一个包含企鹅物种名称的列表。您将使用此列表来解释分类模型的输出:
class_names = ['Adélie', 'Chinstrap', 'Gentoo']
有关特征和标签的更多信息,请参阅机器学习速成课程的“ML 术语”部分。
下载预处理数据集
现在,使用 tfds.load 方法下载预处理的企鹅数据集 (penguins/processed),该方法会返回 tf.data.Dataset 对象的列表。请注意,penguins/processed 数据集不具备自己的测试集,因此请使用 80:20 拆分法将完整数据集分割成训练集和测试集。稍后您将使用测试数据集来验证您的模型。
ds_split, info = tfds.load("penguins/processed", split=['train[:20%]', 'train[20%:]'], as_supervised=True, with_info=True)
ds_test = ds_split[0]
ds_train = ds_split[1]
assert isinstance(ds_test, tf.data.Dataset)
print(info.features)
df_test = tfds.as_dataframe(ds_test.take(5), info)
print("Test dataset sample: ")
print(df_test)
df_train = tfds.as_dataframe(ds_train.take(5), info)
print("Train dataset sample: ")
print(df_train)
ds_train_batch = ds_train.batch(32)
请注意,此版本的数据集已通过将数据减少到四个归一化特征和一个物种标签的方式进行了处理。在这种格式下,数据无需进一步处理即可快速用于训练模型。
features, labels = next(iter(ds_train_batch))
print(features)
print(labels)
您可以通过从批次中绘制一些特征来呈现一些聚类:
plt.scatter(features[:,0],
features[:,2],
c=labels,
cmap='viridis')
plt.xlabel("Body Mass")
plt.ylabel("Culmen Length")
plt.show()
构建简单的线性模型
为何要使用模型?
模型是特征与标签之间的关系。对于企鹅分类问题,模型定义了体重、鳍状肢和嘴峰测量值与预测的企鹅物种之间的关系。一些简单的模型可以用几行代数来描述,但复杂的机器学习模型具有大量难以概括的参数。
您能在不使用机器学习的情况下确定这四种特征与企鹅种类之间的关系吗?也就是说,您能使用传统的编程技术(例如,大量条件语句)来创建模型吗?也许可以,前提是您对数据集分析了足够长的时间,能够确定特定种类体重与嘴峰测量值之间的关系。但对于更加复杂的数据集,这种方法就会变得非常困难甚至不可能。好的机器学习方法能够为您确定模型。如果您将足够多的代表性样本馈送到正确的机器学习模型类型,程序将为您找出关系。
选择模型
我们需要选择要训练的模型种类。模型有许多类型,挑选一个好的模型需要经验。本教程使用神经网络来解决企鹅分类问题。神经网络可以找出特征与标签之间的复杂关系。它是一种高度结构化的计算图,分为一个或多个隐藏层。每个隐藏层由一个或多个神经元组成。神经网络有几种类别,此程序使用密集或全连接神经网络:一个层中的神经元从前一个层中的每一个神经元接收输入连接。例如,图 2 展示了一个密集神经网络,它由一个输入层、两个隐藏层和一个输出层组成。
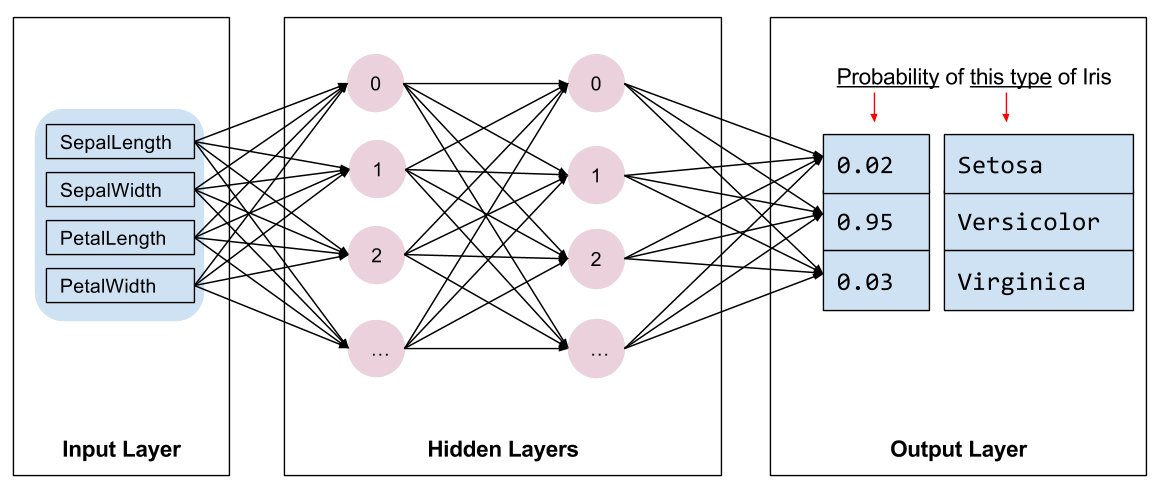 |
| 图 2. 包含特征、隐藏层和预测的神经网络 {nbsp} |
对图 2 中的模型进行训练并向其馈送无标签样本后,它会产生三个预测值:这只企鹅是给定企鹅物种的可能性。这种预测称为推断。对于此示例,输出预测值的总和为 1.0。在图 2 中,此预测可以分解为:阿德利为 0.02、帽带为 0.95,金图为 0.03。这意味着模型预测(以 95% 的概率)表明无标签样本企鹅为帽带企鹅。
使用 Keras 创建模型
TensorFlow tf.keras API 是创建模型和层的首选方式。通过该 API,您可以轻松地构建模型并进行实验,而将所有部分连接在一起的复杂工作则由 Keras 处理。
tf.keras.Sequential 模型是层的线性堆栈。它的构造函数采用层实例列表,本例采用了两个 tf.keras.layers.Dense 层,每层具有 10 个节点,输出层具有 3 个节点,用以表示您的标签预测。第一层的 input_shape 参数对应于数据集中的特征数量,是必需参数:
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation=tf.nn.relu),
tf.keras.layers.Dense(3)
])
激活函数可决定层中每个节点的输出形式。 这些非线性关系很重要,如果没有它们,模型将等同于单个层。激活函数有很多种,但隐藏层通常使用 ReLU。
隐藏层和神经元的理想数量取决于问题和数据集。与机器学习的多个方面一样,选择最佳的神经网络形状需要一定的知识水平和实验基础。一般来说,增加隐藏层和神经元的数量通常会产生更强大的模型,而这需要更多数据才能有效地进行训练。
使用模型
我们快速了解一下此模型如何处理一批特征:
predictions = model(features)
predictions[:5]
在此示例中,每个样本针对每个类别返回一个 logit。
要将这些对数转换为每个类别的概率,请使用 softmax 函数:
tf.nn.softmax(predictions[:5])
跨类采用 tf.math.argmax 能够得到预测的类索引。但是,模型尚未经过训练,因此这些并不是好的预测:
print("Prediction: {}".format(tf.math.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
训练模型
训练 是一个机器学习阶段,在此阶段中,模型会逐渐得到优化,也就是说,模型会了解数据集。目标是充分了解训练数据集的结构,以便对未见过的数据进行预测。如果您从训练数据集中获得了过多的信息,预测便会仅适用于模型见过的数据,但是无法泛化。此问题被称之为过拟合—就好比将答案死记硬背下来,而不去理解问题的解决方式。
企鹅分类问题是监督式机器学习的一个示例:模型通过包含标签的样本进行训练。在非监督式机器学习中,样本不包含标签。模型通常会在特征之间寻找模式。
定义损失和梯度函数
训练和评估阶段都需要计算模型的损失。它可以衡量模型的预测值与期望标签之间的偏差,换句话说,衡量模型的性能有多差。我们希望最小化(或优化)这个值。
您的模型将使用 tf.keras.losses.SparseCategoricalCrossentropy 函数计算其损失,该函数接受模型的类概率预测值和预期标签,然后返回样本中的平均损失。
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
# training=training is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
y_ = model(x, training=training)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
使用 tf.GradientTape 的前后关系来计算梯度以优化你的模型:
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets, training=True)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
创建优化器
优化器会将计算出的梯度应用于模型参数,以最小化 loss 函数。您可以将损失函数视为曲面(见图 3),我们希望通过四处移动找到它的最低点。梯度指向最陡峭的上升方向,因此我们将朝相反方向下坡。我们将通过迭代计算每个批次的损失和梯度在训练期间调整模型。模型将逐渐找到权重和偏差的最佳组合,以最大程度减小损失。损失越小,模型的预测越好。
 |
| 图 3. 3D 空间中随时间呈现的优化算法。(来源:Stanford CS231n 类,MIT 许可,图像来源:Alec Radford) |
TensorFlow 有许多可用于训练的优化算法。在本教程中,您将使用 tf.keras.optimizers.SGD,它可以实现随机梯度下降法 (SGD)。learning_rate 参数设置每次迭代(向下行走)的步长。这是一个超参数,您通常需要调整此参数以获得更好的结果。
以 0.01 的学习率(即每次训练迭代中与梯度相乘的标量值)实例化优化器:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
然后使用此对象计算单个优化步骤:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels, training=True).numpy()))
训练循环
一切准备就绪后,就可以开始训练模型了!训练循环会将数据集样本馈送到模型中,以帮助模型做出更好的预测。以下代码块可设置这些训练步骤:
- 迭代每个周期。通过一次数据集即为一个周期。
- 在一个周期中,遍历训练
Dataset中的每个样本,并获取样本的特征(x)和标签(y)。 - 根据样本的特征进行预测,并比较预测结果和标签。衡量预测结果的不准确性,并使用所得的值计算模型的损失和梯度。
- 使用
optimizer更新模型的参数。 - 跟踪一些统计信息以进行可视化。
- 对每个周期重复执行以上步骤。
num_epochs 变量是循环遍历数据集集合的次数。在下方代码中,num_epochs 设置为 201,这意味着此训练循环将运行 201 次。与直觉相反的是,将模型训练更长时间并不能保证得到更好的模型。num_epochs 是一个可以调节的超参数。选择正确的数字通常需要经验和实验:
## Note: Rerunning this cell uses the same model parameters
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in ds_train_batch:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg.update_state(loss_value) # Add current batch loss
# Compare predicted label to actual label
# training=True is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
epoch_accuracy.update_state(y, model(x, training=True))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
或者,您可以使用内置的 Keras Model.fit(ds_train_batch) 方法来训练您的模型。
可视化损失函数随时间推移而变化的情况
虽然打印出模型的训练进度会很有帮助,但您也可以使用 TensorBoard 来呈现进度 – 它是一种与 TensorFlow 一起打包的呈现和指标工具。对于这个简单的示例,您将使用 matplotlib 模块创建基本图表。
解释这些图表需要一些经验,但一般而言,您会希望看到损失下降而准确率上升:
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
评估模型的效果
现在已经对模型进行了训练,您可以获得一些有关其性能的统计信息。
评估 指的是确定模型做出预测的效果。要确定模型在企鹅分类方面的效果,请将一些测量值传递给模型,并要求模型预测它们所代表的企鹅物种。然后,将模型的预测结果与实际标签进行比较。例如,如果模型对一半输入样本的物种预测正确,则准确率 为 0.5。图 4 显示的是一个效果更好一些的模型,该模型做出 5 次预测,其中有 4 次正确,准确率为 80%:
| 样本特征 | 标签 | 模型预测 | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| 图 4. 一个准确率为 80% 的企鹅分类器。 | |||||
设置测试集
评估模型与训练模型相似。最大的区别在于,样本来自一个单独的测试集,而不是训练集。为了公正地评估模型的效果,用于评估模型的样本务必与用于训练模型的样本不同。
企鹅数据集不具备单独的测试数据集,因此在上方的“下载数据集”部分中,您已将原始数据集拆分为测试数据集和训练数据集。使用 ds_test_batch 数据集进行评估。
根据测试数据集评估模型
与训练阶段不同,模型仅评估单个周期的测试数据。以下代码会对测试集中的每个样本进行迭代,并将模型的预测与实际标签进行比较。这是为了衡量模型在整个测试集上的准确率:
test_accuracy = tf.keras.metrics.Accuracy()
ds_test_batch = ds_test.batch(10)
for (x, y) in ds_test_batch:
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
logits = model(x, training=False)
prediction = tf.math.argmax(logits, axis=1, output_type=tf.int64)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
您还可以使用 model.evaluate(ds_test, return_dict=True) Keras 函数来基于您的测试数据集获取准确率信息。
例如,通过检查最后一个批次,您可以观察到模型预测通常正确。
tf.stack([y,prediction],axis=1)
使用经过训练的模型进行预测
您已经训练了一个模型,并证明了该模型在对企鹅物种进行分类方面做的不错(但不完美)。现在,我们使用训练后的模型对无标签样本(即包含特征但不包含标签的样本)进行一些预测。
在现实生活中,无标签样本可能来自许多不同的源(包括应用、CSV 文件和数据馈送)。在本教程中,手动提供三个无标签样本来预测它们的标签。回顾一下标签编号与命名表示之间的映射关系:
0:阿德利企鹅1:帽带企鹅2:金图企鹅
predict_dataset = tf.convert_to_tensor([
[0.3, 0.8, 0.4, 0.5,],
[0.4, 0.1, 0.8, 0.5,],
[0.7, 0.9, 0.8, 0.4]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
class_idx = tf.math.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))