| |
 在 GitHub 上查看源代码 在 GitHub 上查看源代码
|
警告:不建议将 Estimator 用于新代码。Estimator 运行
v1.Session风格的代码,此类代码更加难以正确编写,并且可能会出现意外行为,尤其是与 TF 2 代码结合使用时。Estimator 确实在我们的兼容性保证范围内,但除了安全漏洞之外不会得到任何修复。请参阅迁移指南以了解详情。
概述
本端到端演示使用 tf.estimator API 来训练逻辑回归模型。该模型通常用作其他更复杂算法的基线。
注:Keras 逻辑回归示例已提供,并推荐在本教程中使用。
安装
pip install sklearnimport os
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import clear_output
from six.moves import urllib
加载 Titanic 数据集
使用 Titanic 数据集的目的是在给定诸如性别、年龄、阶级等特征的情况下预测乘客能否生存(相当病态)。
import tensorflow.compat.v2.feature_column as fc
import tensorflow as tf
2023-11-07 19:03:25.335707: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-11-07 19:03:25.335752: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-11-07 19:03:25.337250: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
# Load dataset.
dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')
dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
探索数据
该数据集包含以下特征
dftrain.head()
dftrain.describe()
训练和评估集中分别有 627 个和 264 个样本。
dftrain.shape[0], dfeval.shape[0]
(627, 264)
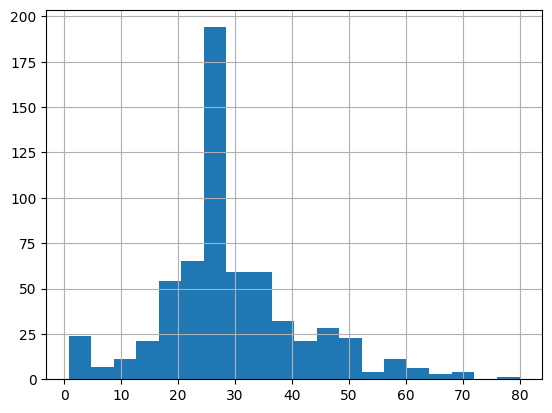
大部分乘客的年龄为 20 多岁和 30 多岁。
dftrain.age.hist(bins=20)
<Axes: >
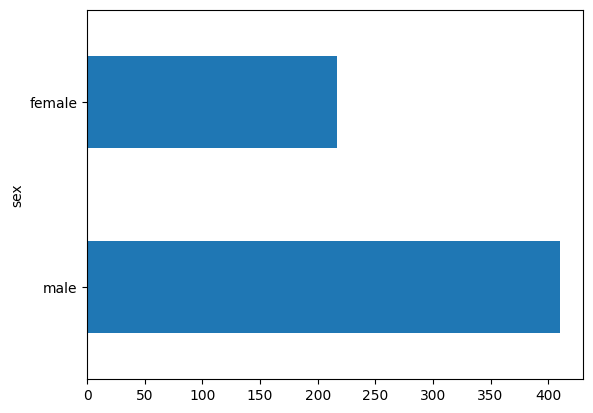
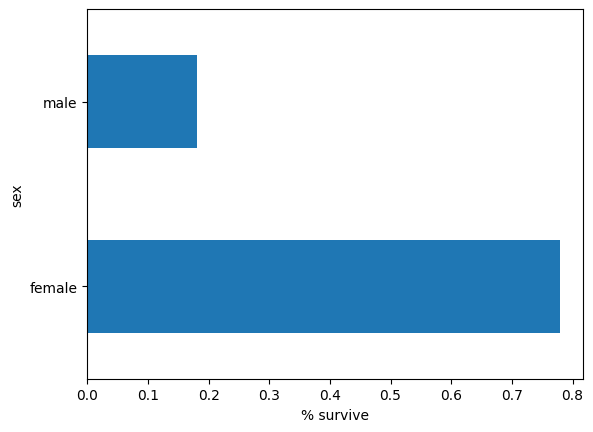
男性乘客人数大约是女性乘客人数的两倍。
dftrain.sex.value_counts().plot(kind='barh')
<Axes: ylabel='sex'>
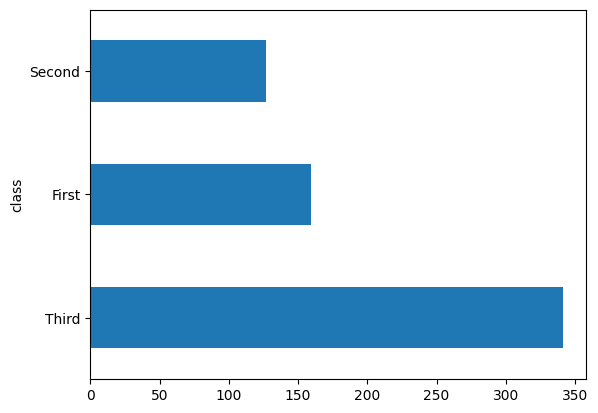
大多数乘客位于“三等”舱。
dftrain['class'].value_counts().plot(kind='barh')
<Axes: ylabel='class'>
与男性相比,女性的幸存机率要高得多。这显然是模型的预测性特征。
pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')
Text(0.5, 0, '% survive')
模型的特征工程
警告:不推荐为新代码使用本教程中介绍的 tf.feature_columns 模块。Keras 预处理层介绍了此功能,有关迁移说明,请参阅迁移特征列指南。tf.feature_columns 模块旨在与 TF1 Estimators 结合使用。它不在我们的兼容性保证范围内,除了安全漏洞修正外,不会获得其他修正。
Estimator 使用名为特征列的系统来描述模型应如何解释每个原始输入特征。需要为 Estimator 提供数字输入向量, 特征列描述了模型应如何转换各个特征。
选择和制作一组正确的特征列是学习高效模型的关键。特征列可以是原始特征 dict(基础特征列)中的一项原始输入,也可以是使用一个或多个基础列定义的转换创建的任何新列(派生特征列)。
线性 Estimator 同时使用数字和分类特征。特征列可与所有 TensorFlow Estimator 配合使用,其目的是定义用于建模的特征。此外,它们还提供了一些特征工程功能,例如独热编码、归一化和分桶。
基础特征列
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
vocabulary = dftrain[feature_name].unique()
feature_columns.append(tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
feature_columns.append(tf.feature_column.numeric_column(feature_name, dtype=tf.float32))
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_417481/567449645.py:8: categorical_column_with_vocabulary_list (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version. Instructions for updating: Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model. WARNING:tensorflow:From /tmpfs/tmp/ipykernel_417481/567449645.py:11: numeric_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version. Instructions for updating: Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
input_function 指定如何将数据转换为流式馈送输入流水线的 tf.data.Dataset。tf.data.Dataset 支持多种来源,例如数据帧、csv 格式文件等。
def make_input_fn(data_df, label_df, num_epochs=10, shuffle=True, batch_size=32):
def input_function():
ds = tf.data.Dataset.from_tensor_slices((dict(data_df), label_df))
if shuffle:
ds = ds.shuffle(1000)
ds = ds.batch(batch_size).repeat(num_epochs)
return ds
return input_function
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, num_epochs=1, shuffle=False)
您可以检查数据集:
ds = make_input_fn(dftrain, y_train, batch_size=10)()
for feature_batch, label_batch in ds.take(1):
print('Some feature keys:', list(feature_batch.keys()))
print()
print('A batch of class:', feature_batch['class'].numpy())
print()
print('A batch of Labels:', label_batch.numpy())
Some feature keys: ['sex', 'age', 'n_siblings_spouses', 'parch', 'fare', 'class', 'deck', 'embark_town', 'alone'] A batch of class: [b'First' b'Third' b'Second' b'First' b'First' b'First' b'Third' b'Third' b'First' b'First'] A batch of Labels: [0 0 0 0 0 1 0 0 1 1]
您还可以使用 tf.keras.layers.DenseFeatures 层来检查特定特征列的结果:
age_column = feature_columns[7]
tf.keras.layers.DenseFeatures([age_column])(feature_batch).numpy()
array([[33. ],
[40.5],
[28. ],
[28. ],
[58. ],
[35. ],
[20. ],
[29. ],
[35. ],
[15. ]], dtype=float32)
DenseFeatures 仅接受密集张量,要检查分类列,您需要先将其转换为指示列:
gender_column = feature_columns[0]
tf.keras.layers.DenseFeatures([tf.feature_column.indicator_column(gender_column)])(feature_batch).numpy()
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_417481/1523458592.py:2: indicator_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
array([[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.]], dtype=float32)
将所有基础特征添加到模型后,让我们开始训练模型。训练模型仅为使用 tf.estimator API 的单个命令:
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.75757575, 'accuracy_baseline': 0.625, 'auc': 0.83177227, 'auc_precision_recall': 0.78038675, 'average_loss': 0.49872923, 'label/mean': 0.375, 'loss': 0.4950045, 'precision': 0.65217394, 'prediction/mean': 0.43766224, 'recall': 0.75757575, 'global_step': 200}
派生特征列
现在,您已达到 75% 的准确率。单独使用每个基本特征列可能不足以解释数据。例如,年龄和标签之间的相关性可能因性别不同而不同。因此,如果您只学习了 gender="Male" 和 gender="Female" 的单个模型权重,则将无法捕获每个年龄-性别组合(例如区分 gender="Male" 和 age="30" 以及 gender="Male" 和 age="40")。
要了解不同特征组合之间的区别,您可以向模型添加交叉特征列(也可以在添加交叉列之前对年龄列进行分桶):
age_x_gender = tf.feature_column.crossed_column(['age', 'sex'], hash_bucket_size=100)
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_417481/476100734.py:1: crossed_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.keras.layers.experimental.preprocessing.HashedCrossing` instead for feature crossing when preprocessing data to train a Keras model.
将组合特征添加到模型后,让我们再次训练模型:
derived_feature_columns = [age_x_gender]
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns+derived_feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7537879, 'accuracy_baseline': 0.625, 'auc': 0.8417202, 'auc_precision_recall': 0.7868179, 'average_loss': 0.5083105, 'label/mean': 0.375, 'loss': 0.5034677, 'precision': 0.64166665, 'prediction/mean': 0.4752579, 'recall': 0.7777778, 'global_step': 200}
现在,准确率已达 77.6%,与仅使用基础特征进行训练相比略高。您可以尝试使用更多特征和转换,看看能否进一步提高准确率!
现在,您可以使用训练模型对评估集内的乘客进行预测。TensorFlow 模型进行了优化,能够每次以一批或一组样本的方式进行预测。之前,eval_input_fn 是使用整个评估集定义的。
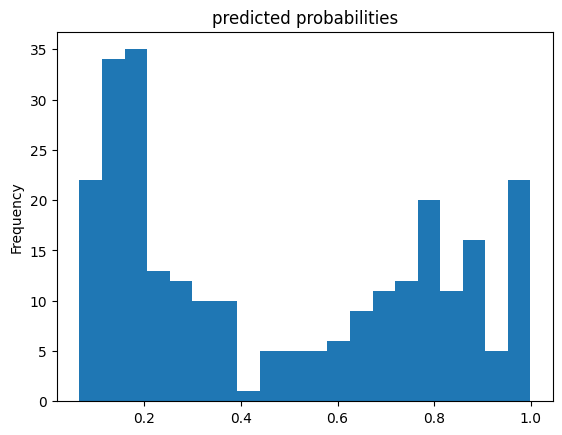
pred_dicts = list(linear_est.predict(eval_input_fn))
probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])
probs.plot(kind='hist', bins=20, title='predicted probabilities')
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_estimator/python/estimator/head/base_head.py:786: ClassificationOutput.__init__ (from tensorflow.python.saved_model.model_utils.export_output) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_estimator/python/estimator/head/binary_class_head.py:561: RegressionOutput.__init__ (from tensorflow.python.saved_model.model_utils.export_output) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_estimator/python/estimator/head/binary_class_head.py:563: PredictOutput.__init__ (from tensorflow.python.saved_model.model_utils.export_output) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmpfs/tmp/tmp7bs6960t/model.ckpt-200
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
<Axes: title={'center': 'predicted probabilities'}, ylabel='Frequency'>
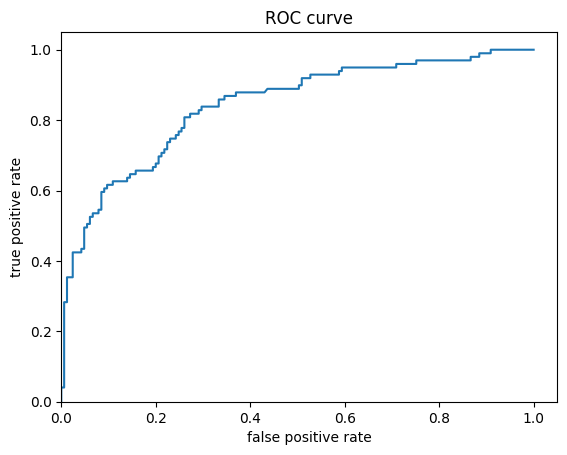
最后,查看结果的受试者工作特征 (ROC),这将使我们能够在真正例率与假正例率之间更好地加以权衡。
from sklearn.metrics import roc_curve
from matplotlib import pyplot as plt
fpr, tpr, _ = roc_curve(y_eval, probs)
plt.plot(fpr, tpr)
plt.title('ROC curve')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.xlim(0,)
plt.ylim(0,)
(0.0, 1.05)