
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce bloc-notes illustre la traduction d'image à image non appariée à l'aide de GAN conditionnels, comme décrit dans Traduction d'image à image non appariée à l'aide de réseaux contradictoires cohérents avec le cycle , également connu sous le nom de CycleGAN. L'article propose une méthode qui peut capturer les caractéristiques d'un domaine d'image et déterminer comment ces caractéristiques pourraient être traduites dans un autre domaine d'image, le tout en l'absence d'exemples de formation appariés.
Ce bloc-notes suppose que vous êtes familiarisé avec Pix2Pix, que vous pouvez découvrir dans le didacticiel Pix2Pix . Le code pour CycleGAN est similaire, la principale différence est une fonction de perte supplémentaire et l'utilisation de données d'entraînement non appariées.
CycleGAN utilise une perte de cohérence de cycle pour permettre la formation sans avoir besoin de données appariées. En d'autres termes, il peut traduire d'un domaine à un autre sans mappage un à un entre le domaine source et le domaine cible.
Cela ouvre la possibilité d'effectuer de nombreuses tâches intéressantes telles que l'amélioration de photos, la colorisation d'images, le transfert de style, etc. Tout ce dont vous avez besoin est l'ensemble de données source et cible (qui est simplement un répertoire d'images).


Configurer le pipeline d'entrée
Installez le package tensorflow_examples qui permet d'importer le générateur et le discriminateur.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
Pipeline d'entrée
Ce didacticiel entraîne un modèle à traduire des images de chevaux en images de zèbres. Vous pouvez trouver cet ensemble de données et d'autres similaires ici .
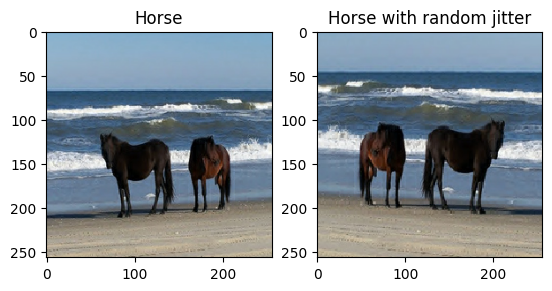
Comme mentionné dans l' article , appliquez une gigue et une mise en miroir aléatoires à l'ensemble de données d'apprentissage. Ce sont quelques-unes des techniques d'augmentation d'image qui évitent le surajustement.
Ceci est similaire à ce qui a été fait dans pix2pix
- En jittering aléatoire, l'image est redimensionnée à
286 x 286puis recadrée de manière aléatoire à256 x 256. - En mode miroir aléatoire, l'image est retournée horizontalement de manière aléatoire, c'est-à-dire de gauche à droite.
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2022-01-26 02:38:15.762422: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2022-01-26 02:38:19.927846: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf83e0050>
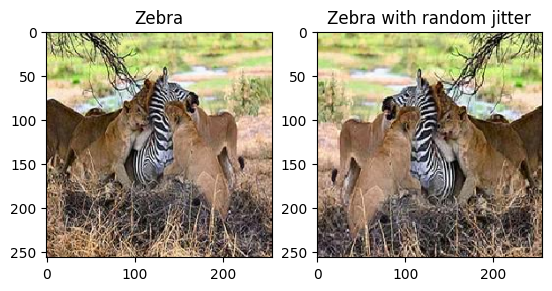
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf8139490>
Importez et réutilisez les modèles Pix2Pix
Importez le générateur et le discriminateur utilisés dans Pix2Pix via le package tensorflow_examples installé.
L'architecture du modèle utilisée dans ce tutoriel est très similaire à celle utilisée dans pix2pix . Certaines des différences sont :
- Cyclegan utilise la normalisation d'instance au lieu de la normalisation par lots .
- L' article CycleGAN utilise un générateur basé sur
resnetmodifié. Ce tutoriel utilise un générateurunetmodifié pour plus de simplicité.
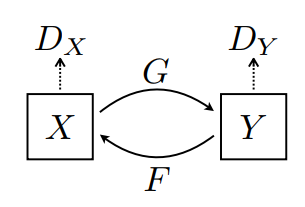
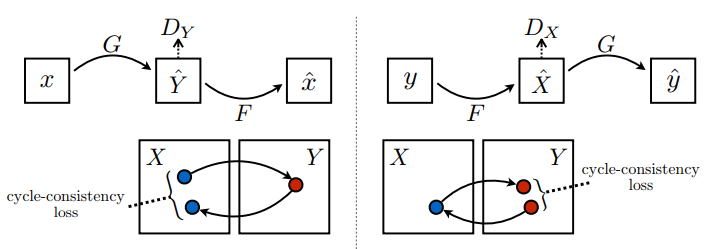
Il y a 2 générateurs (G et F) et 2 discriminateurs (X et Y) en cours de formation ici.
- Le générateur
Gapprend à transformer l'imageXen imageY. \((G: X -> Y)\) - Le générateur
Fapprend à transformer l'imageYen imageX. \((F: Y -> X)\) - Le discriminateur
D_Xapprend à faire la différence entre l'imageXet l'image généréeX(F(Y)). - Le discriminateur
D_Yapprend à différencier l'imageYde l'image généréeY(G(X)).
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
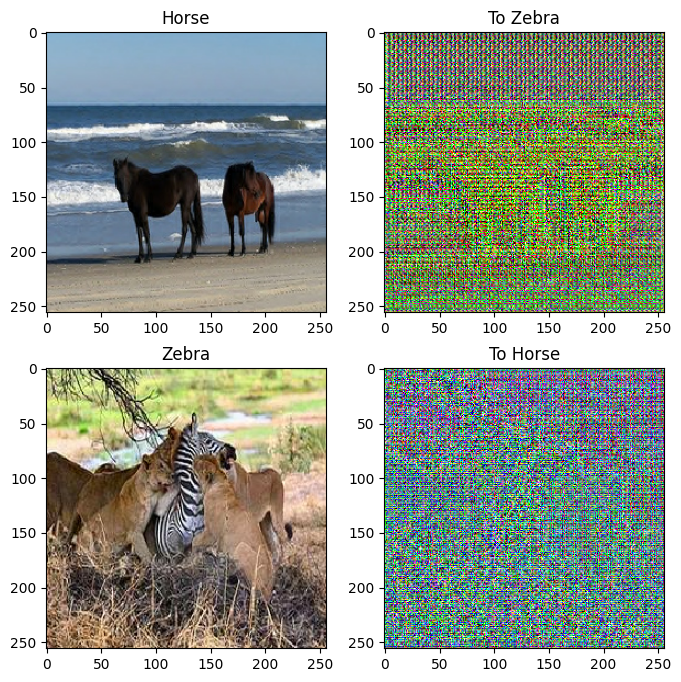
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()
Fonctions de perte
Dans CycleGAN, il n'y a pas de données appariées sur lesquelles s'entraîner, il n'y a donc aucune garantie que l'entrée x et la paire cible y soient significatives pendant l'entraînement. Ainsi, afin de faire en sorte que le réseau apprenne le mappage correct, les auteurs proposent la perte de cohérence de cycle.
La perte du discriminateur et la perte du générateur sont similaires à celles utilisées dans pix2pix .
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
La cohérence du cycle signifie que le résultat doit être proche de l'entrée d'origine. Par exemple, si l'on traduit une phrase de l'anglais vers le français, puis la retraduit du français vers l'anglais, la phrase résultante doit être la même que la phrase originale.
Dans la perte de cohérence du cycle,
- L'image \(X\) est transmise via le générateur \(G\) qui produit l'image générée \(\hat{Y}\).
- L'image générée \(\hat{Y}\) est transmise via le générateur \(F\) qui produit l'image \(\hat{X}\).
- L'erreur absolue moyenne est calculée entre \(X\) et \(\hat{X}\).
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
Comme indiqué ci-dessus, le générateur \(G\) est responsable de la traduction de l'image \(X\) en image \(Y\). La perte d'identité indique que, si vous fournissez l'image \(Y\) au générateur \(G\), cela devrait donner l'image réelle \(Y\) ou quelque chose de proche de l'image \(Y\).
Si vous exécutez le modèle zèbre à cheval sur un cheval ou le modèle cheval à zèbre sur un zèbre, cela ne devrait pas beaucoup modifier l'image puisque l'image contient déjà la classe cible.
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
Initialiser les optimiseurs pour tous les générateurs et les discriminateurs.
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
Points de contrôle
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
Entraînement
EPOCHS = 40
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Même si la boucle de formation semble compliquée, elle se compose de quatre étapes de base :
- Obtenez les prédictions.
- Calculez la perte.
- Calculez les gradients en utilisant la rétropropagation.
- Appliquez les dégradés à l'optimiseur.
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 40 at ./checkpoints/train/ckpt-8 Time taken for epoch 40 is 166.64579939842224 sec
Générer à l'aide d'un jeu de données de test
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





Prochaines étapes
Ce tutoriel a montré comment implémenter CycleGAN à partir du générateur et du discriminateur implémentés dans le tutoriel Pix2Pix . À l'étape suivante, vous pouvez essayer d'utiliser un ensemble de données différent de TensorFlow Datasets .
Vous pouvez également vous entraîner sur un plus grand nombre d'époques pour améliorer les résultats, ou vous pouvez implémenter le générateur ResNet modifié utilisé dans l' article au lieu du générateur U-Net utilisé ici.