
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este notebook demonstra a conversão de imagem para imagem não pareada usando GANs condicionais, conforme descrito em Tradução de imagem para imagem não pareada usando redes adversárias consistentes com ciclo , também conhecidas como CycleGAN. O artigo propõe um método que pode capturar as características de um domínio de imagem e descobrir como essas características podem ser traduzidas em outro domínio de imagem, tudo na ausência de exemplos de treinamento pareados.
Este notebook pressupõe que você esteja familiarizado com o Pix2Pix, sobre o qual você pode aprender no tutorial do Pix2Pix . O código para CycleGAN é semelhante, a principal diferença é uma função de perda adicional e o uso de dados de treinamento não pareados.
CycleGAN usa uma perda de consistência de ciclo para permitir o treinamento sem a necessidade de dados pareados. Em outras palavras, ele pode traduzir de um domínio para outro sem um mapeamento um-para-um entre o domínio de origem e de destino.
Isso abre a possibilidade de fazer muitas tarefas interessantes, como aprimoramento de fotos, colorização de imagens, transferência de estilo, etc. Tudo que você precisa é o conjunto de dados de origem e destino (que é simplesmente um diretório de imagens).


Configurar o pipeline de entrada
Instale o pacote tensorflow_examples que permite a importação do gerador e do discriminador.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
Pipeline de entrada
Este tutorial treina um modelo para traduzir de imagens de cavalos para imagens de zebras. Você pode encontrar este conjunto de dados e outros semelhantes aqui .
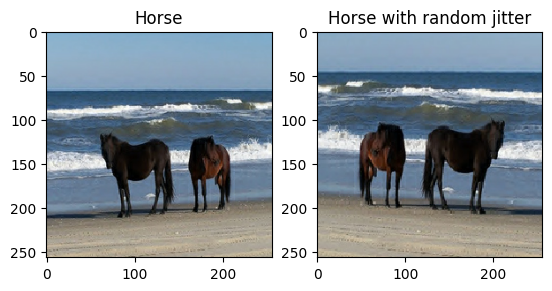
Conforme mencionado no artigo , aplique jitter e espelhamento aleatórios ao conjunto de dados de treinamento. Estas são algumas das técnicas de aumento de imagem que evitam o overfitting.
Isso é semelhante ao que foi feito no pix2pix
- Em jittering aleatório, a imagem é redimensionada para
286 x 286e depois cortada aleatoriamente para256 x 256. - No espelhamento aleatório, a imagem é invertida horizontalmente, ou seja, da esquerda para a direita.
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2022-01-26 02:38:15.762422: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2022-01-26 02:38:19.927846: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf83e0050>
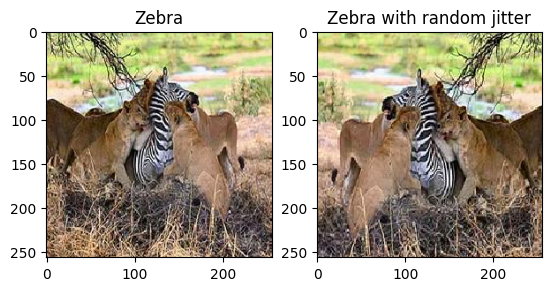
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf8139490>
Importe e reutilize os modelos Pix2Pix
Importe o gerador e o discriminador usados no Pix2Pix por meio do pacote tensorflow_examples instalado.
A arquitetura do modelo usado neste tutorial é muito semelhante ao que foi usado no pix2pix . Algumas das diferenças são:
- Cyclegan usa normalização de instância em vez de normalização em lote .
- O papel CycleGAN usa um gerador baseado
resnetmodificado. Este tutorial está usando um gerador deunetmodificado para simplificar.
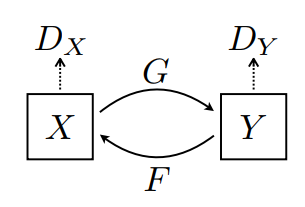
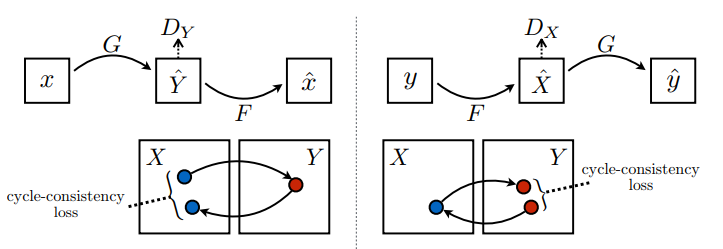
Existem 2 geradores (G e F) e 2 discriminadores (X e Y) sendo treinados aqui.
- O gerador
Gaprende a transformar a imagemXna imagemY. \((G: X -> Y)\) - O gerador
Faprende a transformar a imagemYna imagemX\((F: Y -> X)\) - O discriminador
D_Xaprende a diferenciar entre a imagemXe a imagem geradaX(F(Y)). - O discriminador
D_Yaprende a diferenciar entre a imagemYe a imagem geradaY(G(X)).
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
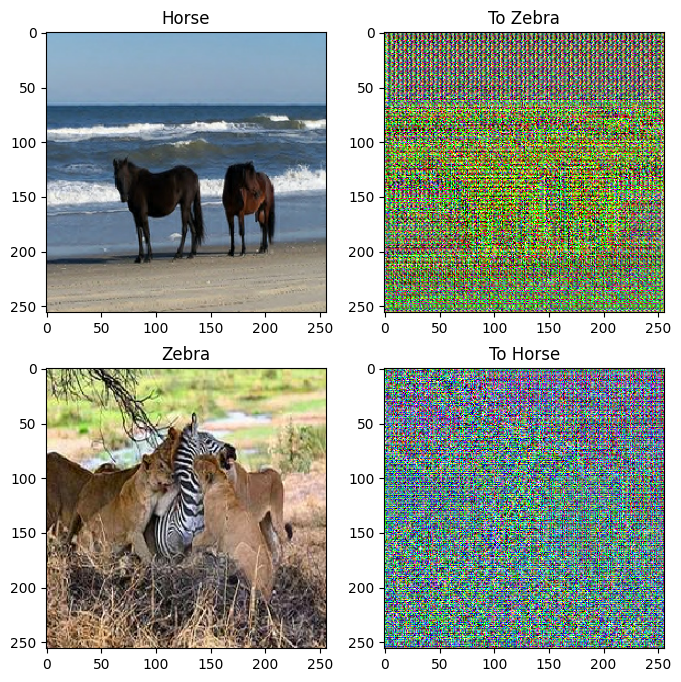
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()
Funções de perda
No CycleGAN, não há dados pareados para treinar, portanto, não há garantia de que a entrada x e o par de destino y sejam significativos durante o treinamento. Assim, para garantir que a rede aprenda o mapeamento correto, os autores propõem a perda de consistência do ciclo.
A perda do discriminador e a perda do gerador são semelhantes às usadas no pix2pix .
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
A consistência do ciclo significa que o resultado deve estar próximo da entrada original. Por exemplo, se alguém traduz uma frase do inglês para o francês e depois a traduz de volta do francês para o inglês, a frase resultante deve ser a mesma que a frase original.
Na perda de consistência do ciclo,
- A imagem \(X\) é passada através do gerador \(G\) que produz a imagem gerada \(\hat{Y}\).
- A imagem gerada \(\hat{Y}\) é passada através do gerador \(F\) que produz a imagem ciclada \(\hat{X}\).
- O erro absoluto médio é calculado entre \(X\) e \(\hat{X}\).
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
Como mostrado acima, o gerador \(G\) é responsável por traduzir a imagem \(X\) para a imagem \(Y\). A perda de identidade diz que, se você alimentar a imagem \(Y\) no gerador \(G\), ela deverá produzir a imagem real \(Y\) ou algo próximo da imagem \(Y\).
Se você executar o modelo de zebra para cavalo em um cavalo ou o modelo de cavalo para zebra em uma zebra, ele não deve modificar muito a imagem, pois a imagem já contém a classe de destino.
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
Inicialize os otimizadores para todos os geradores e discriminadores.
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
Pontos de verificação
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
Treinamento
EPOCHS = 40
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Embora o loop de treinamento pareça complicado, ele consiste em quatro etapas básicas:
- Obtenha as previsões.
- Calcule a perda.
- Calcule os gradientes usando retropropagação.
- Aplique os gradientes ao otimizador.
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 40 at ./checkpoints/train/ckpt-8 Time taken for epoch 40 is 166.64579939842224 sec
Gerar usando o conjunto de dados de teste
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





Próximos passos
Este tutorial mostrou como implementar CycleGAN a partir do gerador e discriminador implementados no tutorial Pix2Pix . Como próxima etapa, você pode tentar usar um conjunto de dados diferente do TensorFlow Datasets .
Você também pode treinar para um número maior de épocas para melhorar os resultados ou implementar o gerador ResNet modificado usado no artigo em vez do gerador U-Net usado aqui.