
| | |  Afficher sur GitHub Afficher sur GitHub | | |
Ce didacticiel utilise l'apprentissage en profondeur pour composer une image dans le style d'une autre image (n'avez-vous jamais rêvé de pouvoir peindre comme Picasso ou Van Gogh ?). Ceci est connu sous le nom de transfert de style neuronal et la technique est décrite dans A Neural Algorithm of Artistic Style (Gatys et al.).
Pour une application simple du transfert de style, consultez ce didacticiel pour en savoir plus sur l'utilisation du modèle de stylisation d'image arbitraire pré -entraîné de TensorFlow Hub ou sur l'utilisation d'un modèle de transfert de style avec TensorFlow Lite .
Le transfert de style neuronal est une technique d'optimisation utilisée pour prendre deux images - une image de contenu et une image de référence de style (telle qu'une œuvre d'un peintre célèbre) - et les mélanger afin que l'image de sortie ressemble à l'image de contenu, mais "peinte". dans le style de l'image de référence de style.
Ceci est mis en œuvre en optimisant l'image de sortie pour qu'elle corresponde aux statistiques de contenu de l'image de contenu et aux statistiques de style de l'image de référence de style. Ces statistiques sont extraites des images à l'aide d'un réseau convolutif.
Prenons par exemple une image de ce chien et de la Composition 7 de Wassily Kandinsky :

Labrador jaune regardant , de Wikimedia Commons par Elf . Licence CC BY-SA 3.0
{kind=link}

Maintenant, à quoi cela ressemblerait-il si Kandinsky décidait de peindre l'image de ce chien exclusivement avec ce style ? Quelque chose comme ça?

Installer
Importer et configurer des modules
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
Téléchargez des images et choisissez une image de style et une image de contenu :
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
Visualiser l'entrée
Définissez une fonction pour charger une image et limiter sa dimension maximale à 512 pixels.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
Créez une fonction simple pour afficher une image :
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

Transfert de style rapide avec TF-Hub
Ce didacticiel illustre l'algorithme de transfert de style original, qui optimise le contenu de l'image dans un style particulier. Avant d'entrer dans les détails, voyons comment le modèle TensorFlow Hub procède :
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
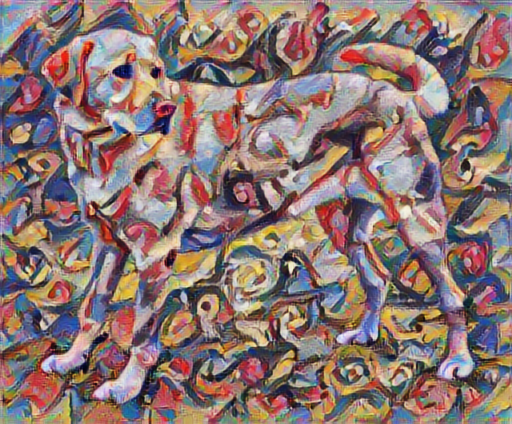
Définir les représentations de contenu et de style
Utilisez les couches intermédiaires du modèle pour obtenir les représentations de contenu et de style de l'image. À partir de la couche d'entrée du réseau, les premières activations de couche représentent des fonctionnalités de bas niveau telles que les bords et les textures. Au fur et à mesure que vous parcourez le réseau, les dernières couches représentent des fonctionnalités de niveau supérieur, des parties d'objet telles que des roues ou des yeux . Dans ce cas, vous utilisez l'architecture réseau VGG19, un réseau de classification d'images pré-entraîné. Ces couches intermédiaires sont nécessaires pour définir la représentation du contenu et du style à partir des images. Pour une image d'entrée, essayez de faire correspondre les représentations de cible de style et de contenu correspondantes au niveau de ces couches intermédiaires.
Chargez un VGG19 et testez-le sur notre image pour vous assurer qu'il est utilisé correctement :
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
Chargez maintenant un VGG19 sans la tête de classification et listez les noms des couches
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
Choisissez des couches intermédiaires du réseau pour représenter le style et le contenu de l'image :
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
Couches intermédiaires pour le style et le contenu
Alors pourquoi ces sorties intermédiaires au sein de notre réseau de classification d'images pré-entraîné nous permettent-elles de définir des représentations de style et de contenu ?
À un niveau élevé, pour qu'un réseau puisse effectuer une classification d'images (ce à quoi ce réseau a été formé), il doit comprendre l'image. Cela nécessite de prendre l'image brute comme pixels d'entrée et de construire une représentation interne qui convertit les pixels de l'image brute en une compréhension complexe des caractéristiques présentes dans l'image.
C'est aussi une raison pour laquelle les réseaux de neurones convolutifs sont capables de bien généraliser : ils sont capables de capturer les invariances et de définir des caractéristiques au sein de classes (par exemple chats contre chiens) qui sont agnostiques au bruit de fond et autres nuisances. Ainsi, quelque part entre l'endroit où l'image brute est introduite dans le modèle et l'étiquette de classification de sortie, le modèle sert d'extracteur de caractéristiques complexes. En accédant aux couches intermédiaires du modèle, vous pouvez décrire le contenu et le style des images d'entrée.
Construire le modèle
Les réseaux dans tf.keras.applications sont conçus pour que vous puissiez facilement extraire les valeurs de la couche intermédiaire à l'aide de l'API fonctionnelle Keras.
Pour définir un modèle à l'aide de l'API fonctionnelle, spécifiez les entrées et les sorties :
model = Model(inputs, outputs)
Cette fonction suivante crée un modèle VGG19 qui renvoie une liste de sorties de couche intermédiaire :
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
Et pour créer le modèle :
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
Calculer le style
Le contenu d'une image est représenté par les valeurs des cartes de caractéristiques intermédiaires.
Il s'avère que le style d'une image peut être décrit par les moyens et les corrélations entre les différentes cartes de caractéristiques. Calculez une matrice Gram qui inclut ces informations en prenant le produit externe du vecteur de caractéristiques avec lui-même à chaque emplacement et en faisant la moyenne de ce produit externe sur tous les emplacements. Cette matrice de Gram peut être calculée pour une couche particulière comme suit :
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
Cela peut être implémenté de manière concise à l'aide de la fonction tf.linalg.einsum :
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
Extraire le style et le contenu
Créez un modèle qui renvoie les tenseurs de style et de contenu.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
Lorsqu'il est appelé sur une image, ce modèle renvoie la matrice gram (style) des style_layers et le contenu des content_layers :
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
Exécuter une descente en pente
Avec cet extracteur de style et de contenu, vous pouvez désormais implémenter l'algorithme de transfert de style. Pour ce faire, calculez l'erreur quadratique moyenne de la sortie de votre image par rapport à chaque cible, puis prenez la somme pondérée de ces pertes.
Définissez vos valeurs cibles de style et de contenu :
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
Définissez une tf.Variable pour contenir l'image à optimiser. Pour rendre cela rapide, initialisez-le avec l'image de contenu (la tf.Variable doit avoir la même forme que l'image de contenu) :
image = tf.Variable(content_image)
Puisqu'il s'agit d'une image flottante, définissez une fonction pour conserver les valeurs de pixel entre 0 et 1 :
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
Créez un optimiseur. Le document recommande LBFGS, mais Adam fonctionne bien aussi :
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
Pour optimiser cela, utilisez une combinaison pondérée des deux pertes pour obtenir la perte totale :
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
Utilisez tf.GradientTape pour mettre à jour l'image.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Exécutez maintenant quelques étapes pour tester :
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

Puisque cela fonctionne, effectuez une optimisation plus longue :
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
Perte de variation totale
Un inconvénient de cette implémentation de base est qu'elle produit beaucoup d'artefacts à haute fréquence. Diminuez-les en utilisant un terme de régularisation explicite sur les composantes haute fréquence de l'image. En transfert de style, on l'appelle souvent la perte de variation totale :
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
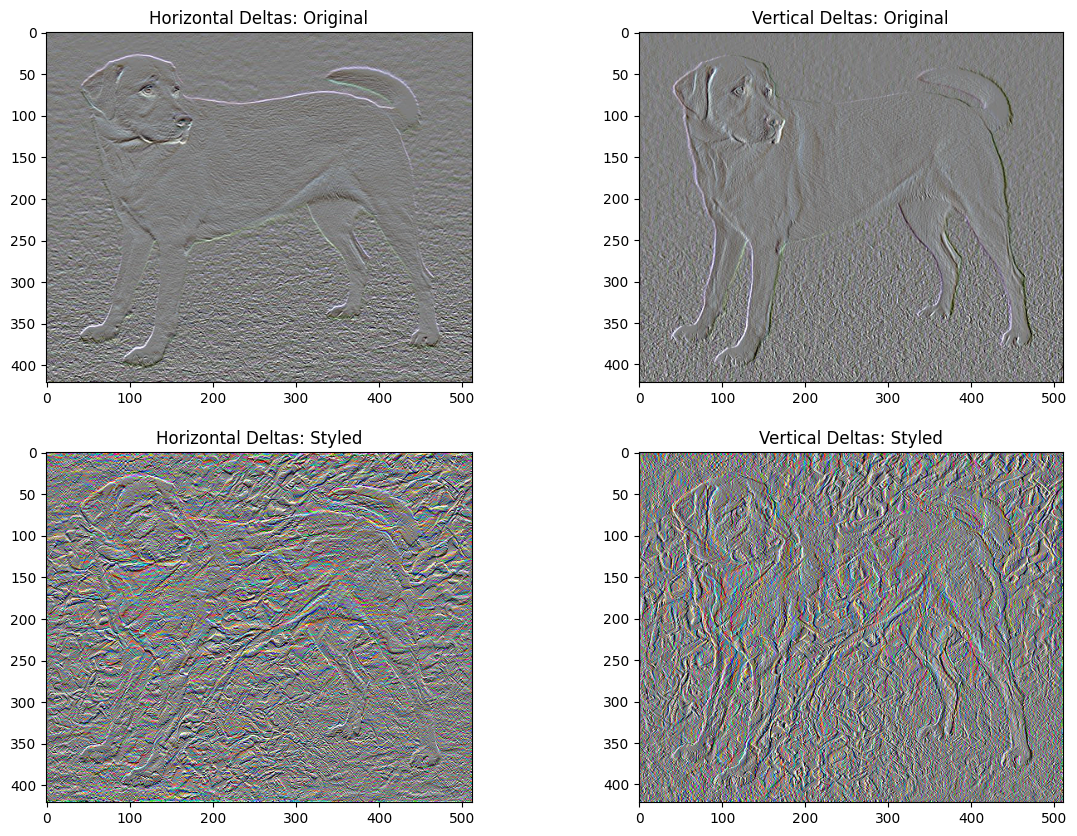
Cela montre comment les composants haute fréquence ont augmenté.
De plus, ce composant haute fréquence est essentiellement un détecteur de bord. Vous pouvez obtenir une sortie similaire du détecteur de bord Sobel, par exemple :
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
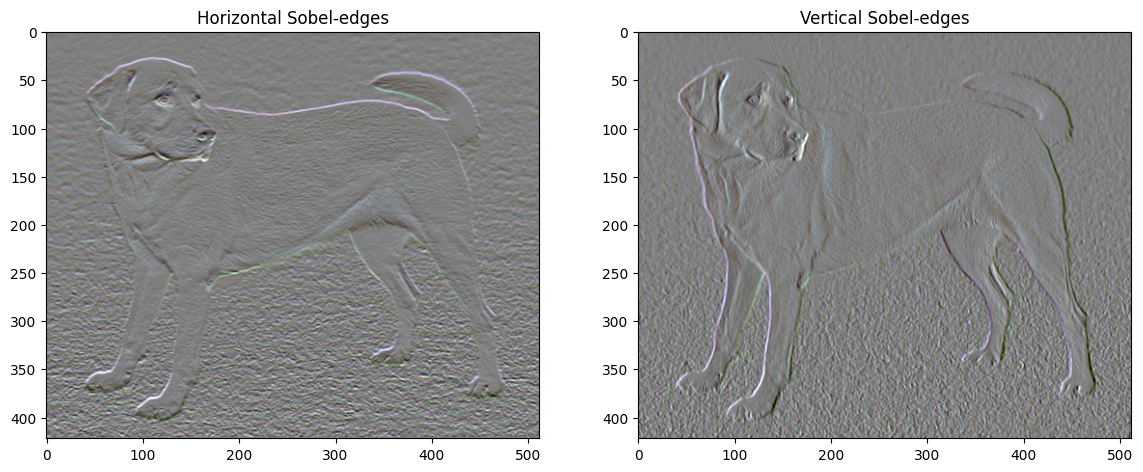
La perte de régularisation qui y est associée est la somme des carrés des valeurs :
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
Cela a démontré ce qu'il fait. Mais il n'est pas nécessaire de l'implémenter vous-même, TensorFlow inclut une implémentation standard :
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
Relancer l'optimisation
Choisissez une pondération pour le total_variation_loss :
total_variation_weight=30
Maintenant, incluez-le dans la fonction train_step :
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Réinitialisez la variable d'optimisation :
image = tf.Variable(content_image)
Et exécutez l'optimisation :
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
Enfin, enregistrez le résultat :
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
Apprendre encore plus
Ce didacticiel illustre l'algorithme de transfert de style d'origine. Pour une application simple du transfert de style, consultez ce didacticiel pour en savoir plus sur l'utilisation du modèle de transfert de style d'image arbitraire de TensorFlow Hub .