
| |
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码 |
|
本教程演示了从存储在磁盘上的纯文本文件开始的文本分类。您将训练一个二元分类器对 IMDB 数据集执行情感分析。在笔记本的最后,有一个练习供您尝试,您将在其中训练一个多类分类器来预测 Stack Overflow 上编程问题的标签。
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
2023-11-08 00:06:16.980388: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-11-08 00:06:16.980452: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-11-08 00:06:16.982190: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
print(tf.__version__)
2.15.0-rc1
情感分析
此笔记本训练了一个情感分析模型,利用评论文本将电影评论分类为正面或负面评价。这是一个二元(或二类)分类示例,也是一个重要且应用广泛的机器学习问题。
您将使用 Large Movie Review Dataset,其中包含 Internet Movie Database 中的 50,000 条电影评论文本 。我们将这些评论分为两组,其中 25,000 条用于训练,另外 25,000 条用于测试。训练集和测试集是均衡的,也就是说其中包含相等数量的正面评价和负面评价。
下载并探索 IMDB 数据集
我们下载并提取数据集,然后浏览一下目录结构。
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84125825/84125825 [==============================] - 19s 0us/step
os.listdir(dataset_dir)
['imdb.vocab', 'imdbEr.txt', 'README', 'test', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_unsup.txt', 'unsupBow.feat', 'urls_neg.txt', 'neg', 'urls_pos.txt', 'labeledBow.feat', 'unsup', 'pos']
aclImdb/train/pos 和 aclImdb/train/neg 目录包含许多文本文件,每个文件都是一条电影评论。我们来看看其中的一条评论。
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
加载数据集
接下来,您将从磁盘加载数据并将其准备为适合训练的格式。为此,您将使用有用的 text_dataset_from_directory 实用工具,它期望的目录结构如下所示。
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
要准备用于二元分类的数据集,磁盘上需要有两个文件夹,分别对应于 class_a 和 class_b。这些将是正面和负面的电影评论,可以在 aclImdb/train/pos 和 aclImdb/train/neg 中找到。由于 IMDB 数据集包含其他文件夹,因此您需要在使用此实用工具之前将其移除。
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
接下来,您将使用 text_dataset_from_directory 实用工具创建带标签的 tf.data.Dataset。tf.data 是一组强大的数据处理工具。
运行机器学习实验时,最佳做法是将数据集拆成三份:训练、验证 和 测试。
IMDB 数据集已经分成训练集和测试集,但缺少验证集。我们来通过下面的 validation_split 参数,使用 80:20 拆分训练数据来创建验证集。
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
如上所示,训练文件夹中有 25,000 个样本,您将使用其中的 80%(或 20,000 个)进行训练。稍后您将看到,您可以通过将数据集直接传递给 model.fit 来训练模型。如果您不熟悉 tf.data,还可以遍历数据集并打印出一些样本,如下所示。
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
请注意,评论包含原始文本(带有标点符号和偶尔出现的 HTML 代码,如 <br/>)。我们将在以下部分展示如何处理这些问题。
标签为 0 或 1。要查看它们与正面和负面电影评论的对应关系,可以查看数据集上的 class_names 属性。
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
接下来,您将创建验证数据集和测试数据集。您将使用训练集中剩余的 5,000 条评论进行验证。
注:使用 validation_split 和 subset 参数时,请确保要么指定随机种子,要么传递 shuffle=False,这样验证拆分和训练拆分就不会重叠。
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
准备用于训练的数据集
接下来,您将使用有用的 tf.keras.layers.TextVectorization 层对数据进行标准化、词例化和向量化。
标准化是指对文本进行预处理,通常是移除标点符号或 HTML 元素以简化数据集。词例化是指将字符串分割成词例(例如,通过空格将句子分割成单个单词)。向量化是指将词例转换为数字,以便将它们输入神经网络。所有这些任务都可以通过这个层完成。
正如您在上面看到的,评论包含各种 HTML 代码,例如 <br />。TextVectorization 层(默认情况下会将文本转换为小写并去除标点符号,但不会去除 HTML)中的默认标准化程序不会移除这些代码。您将编写一个自定义标准化函数来移除 HTML。
注:为了防止训练-测试偏差(也称为训练-应用偏差),在训练和测试时间对数据进行相同的预处理非常重要。为此,可以将 TextVectorization 层直接包含在模型中,如本教程后面所示。
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
接下来,您将创建一个 TextVectorization 层。您将使用该层对我们的数据进行标准化、词例化和向量化。您将 output_mode 设置为 int 以便为每个词例创建唯一的整数索引。
请注意,您使用的是默认拆分函数,以及您在上面定义的自定义标准化函数。您还将为模型定义一些常量,例如显式的最大 sequence_length,这会使层将序列填充或截断为精确的 sequence_length 值。
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
接下来,您将调用 adapt 以使预处理层的状态适合数据集。这会使模型构建字符串到整数的索引。
注:在调用时请务必仅使用您的训练数据(使用测试集会泄漏信息)。
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
我们来创建一个函数来查看使用该层预处理一些数据的结果。
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
正如您在上面看到的,每个词例都被一个整数替换了。您可以通过在该层上调用 .get_vocabulary() 来查找每个整数对应的词例(字符串)。
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
差不多可以训练您的模型了。作为最后的预处理步骤,将之前创建的 TextVectorization 层应用于训练数据集、验证数据集和测试数据集。
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
配置数据集以提高性能
以下是加载数据时应该使用的两种重要方法,以确保 I/O 不会阻塞。
从磁盘加载后,.cache() 会将数据保存在内存中。这将确保数据集在训练模型时不会成为瓶颈。如果您的数据集太大而无法放入内存,也可以使用此方法创建高性能的磁盘缓存,这比许多小文件的读取效率更高。
prefetch() 会在训练时将数据预处理和模型执行重叠。
您可以在数据性能指南中深入了解这两种方法,以及如何将数据缓存到磁盘。
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
创建模型
是时候创建您的神经网络了:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d ( (None, 16) 0
GlobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160033 (625.13 KB)
Trainable params: 160033 (625.13 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
层按顺序堆叠以构建分类器:
- 第一个层是
Embedding层。此层采用整数编码的评论,并查找每个单词索引的嵌入向量。这些向量是通过模型训练学习到的。向量向输出数组增加了一个维度。得到的维度为:(batch, sequence, embedding)。要详细了解嵌入向量,请参阅单词嵌入向量教程。 - 接下来,
GlobalAveragePooling1D将通过对序列维度求平均值来为每个样本返回一个定长输出向量。这允许模型以尽可能最简单的方式处理变长输入。 - 该定长输出向量通过一个有 16 个隐层单元的全连接(
Dense)层传输。 - 最后一层与单个输出结点密集连接。使用
Sigmoid激活函数,其函数值为介于 0 与 1 之间的浮点数,表示概率或置信度。
损失函数与优化器
一个模型需要损失函数和优化器来进行训练。由于这是一个二分类问题且模型输出概率值(一个使用 sigmoid 激活函数的单一单元层),我们将使用 binary_crossentropy 损失函数。
这不是损失函数的唯一选择,例如,您可以选择 mean_squared_error 。但是,一般来说 binary_crossentropy 更适合处理概率——它能够度量概率分布之间的“距离”,或者在我们的示例中,指的是度量 ground-truth 分布与预测值之间的“距离”。
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
训练模型
以 512 个样本的 mini-batch 大小迭代 40 个 epoch 来训练模型。这是指对 x_train 和 y_train 张量中所有样本的的 40 次迭代。在训练过程中,监测来自验证集的 10,000 个样本上的损失值(loss)和准确率(accuracy):
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1699402032.417606 600522 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process. 625/625 [==============================] - 48s 73ms/step - loss: 0.6668 - binary_accuracy: 0.6913 - val_loss: 0.6190 - val_binary_accuracy: 0.7690 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5520 - binary_accuracy: 0.7976 - val_loss: 0.5009 - val_binary_accuracy: 0.8206 Epoch 3/10 625/625 [==============================] - 2s 4ms/step - loss: 0.4463 - binary_accuracy: 0.8432 - val_loss: 0.4213 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 4ms/step - loss: 0.3789 - binary_accuracy: 0.8654 - val_loss: 0.3744 - val_binary_accuracy: 0.8616 Epoch 5/10 625/625 [==============================] - 2s 4ms/step - loss: 0.3358 - binary_accuracy: 0.8783 - val_loss: 0.3458 - val_binary_accuracy: 0.8662 Epoch 6/10 625/625 [==============================] - 2s 4ms/step - loss: 0.3062 - binary_accuracy: 0.8885 - val_loss: 0.3267 - val_binary_accuracy: 0.8714 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2819 - binary_accuracy: 0.8975 - val_loss: 0.3132 - val_binary_accuracy: 0.8724 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2632 - binary_accuracy: 0.9040 - val_loss: 0.3038 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2464 - binary_accuracy: 0.9093 - val_loss: 0.2971 - val_binary_accuracy: 0.8786 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2329 - binary_accuracy: 0.9156 - val_loss: 0.2926 - val_binary_accuracy: 0.8782
评估模型
我们来看一下模型的性能如何。将返回两个值。损失值(loss)(一个表示误差的数字,值越低越好)与准确率(accuracy)。
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3107 - binary_accuracy: 0.8732 Loss: 0.310722291469574 Accuracy: 0.8731600046157837
这种十分朴素的方法得到了约 87% 的准确率(accuracy)。若采用更好的方法,模型的准确率应当接近 95%。
创建准确率和损失随时间变化的图表
model.fit() 会返回包含一个字典的 History 对象。该字典包含训练过程中产生的所有信息:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
其中有四个条目:每个条目代表训练和验证过程中的一项监测指标。您可以使用这些指标来绘制用于比较的训练损失和验证损失图表,以及训练准确率和验证准确率图表:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
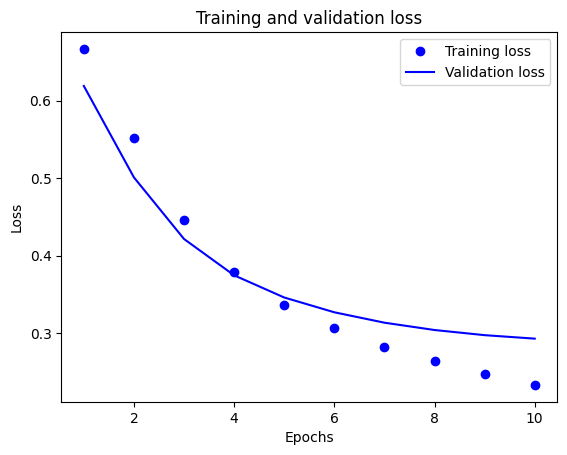
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
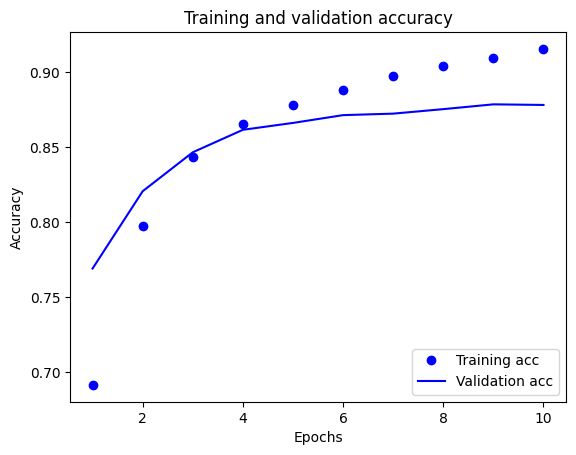
在该图表中,虚线代表训练损失和准确率,实线代表验证损失和准确率。
请注意,训练损失会逐周期下降,而训练准确率则逐周期上升。使用梯度下降优化时,这是预期结果,它应该在每次迭代中最大限度减少所需的数量。
但是,对于验证损失和准确率来说则不然——它们似乎会在训练转确率之前达到顶点。这是过拟合的一个例子:模型在训练数据上的表现要好于在之前从未见过的数据上的表现。经过这一点之后,模型会过度优化和学习特定于训练数据的表示,但无法泛化到测试数据。
对于这种特殊情况,您可以通过在验证准确率不再增加时直接停止训练来防止过度拟合。一种方式是使用 tf.keras.callbacks.EarlyStopping 回调。
导出模型
在上面的代码中,您在向模型馈送文本之前对数据集应用了 TextVectorization。 如果您想让模型能够处理原始字符串(例如,为了简化部署),您可以在模型中包含 TextVectorization 层。为此,您可以使用刚刚训练的权重创建一个新模型。
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3107 - accuracy: 0.8732 0.8731600046157837
使用新数据进行推断
要获得对新样本的预测,只需调用 model.predict() 即可。
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
1/1 [==============================] - 0s 177ms/step
array([[0.5980279 ],
[0.41937438],
[0.33809566]], dtype=float32)
将文本预处理逻辑包含在模型中后,您可以导出用于生产的模型,从而简化部署并降低训练/测试偏差的可能性。
在选择应用 TextVectorization 层的位置时,需要注意性能差异。在模型之外使用它可以让您在 GPU 上训练时进行异步 CPU 处理和数据缓冲。因此,如果您在 GPU 上训练模型,您应该在开发模型时使用此选项以获得最佳性能,然后在准备好部署时进行切换,在模型中包含 TextVectorization 层。
请参阅此教程,详细了解如何保存模型。
练习:对 Stack Overflow 问题进行多类分类
本教程展示了如何在 IMDB 数据集上从头开始训练二元分类器。作为练习,您可以修改此笔记本以训练多类分类器来预测 Stack Overflow 上的编程问题的标签。
我们已经准备好了一个数据集供您使用,其中包含了几千个发布在 Stack Overflow 上的编程问题(例如,"How can sort a dictionary by value in Python?")。每一个问题都只有一个标签(Python、CSharp、JavaScript 或 Java)。您的任务是将问题作为输入,并预测适当的标签,在本例中为 Python。
您将使用的数据集包含从 BigQuery 上更大的公共 Stack Overflow 数据集提取的数千个问题,其中包含超过 1700 万个帖子。
下载数据集后,您会发现它与您之前使用的 IMDB 数据集具有相似的目录结构:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
注:为了增加分类问题的难度,编程问题中出现的 Python、CSharp、JavaScript 或 Java 等词已被替换为 blank(因为许多问题都包含它们所涉及的语言)。
要完成此练习,您应该对此笔记本进行以下修改以使用 Stack Overflow 数据集:
在笔记本顶部,将下载 IMDB 数据集的代码更新为下载前面准备好的 Stack Overflow 数据集的代码。由于 Stack Overflow 数据集具有类似的目录结构,因此您不需要进行太多修改。
将模型的最后一层修改为
Dense(4),因为现在有四个输出类。编译模型时,将损失更改为
tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)。当每个类的标签是整数(在本例中,它们可以是 0、1、2 或 3)时,这是用于多类分类问题的正确损失函数。 此外,将指标更改为metrics=['accuracy'],因为这是一个多类分类问题(tf.metrics.BinaryAccuracy仅用于二元分类器 )。在绘制随时间变化的准确率时,请将
binary_accuracy和val_binary_accuracy分别更改为accuracy和val_accuracy。完成这些更改后,就可以训练多类分类器了。
了解更多信息
本教程从头开始介绍了文本分类。要详细了解一般的文本分类工作流程,请查看 Google Developers 提供的文本分类指南。
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.