
|
|
|
 View source on GitHub View source on GitHub
|
|
Esta Guia entrena un modelo de red neuronal para clasificar imagenes de ropa como, tennis y camisetas. No hay problema sino entiende todos los detalles; es un repaso rapido de un programa completo de Tensorflow con los detalles explicados a medida que avanza.
Esta Guia usa tf.keras, un API de alto nivel para construir y entrenar modelos en Tensorflow.
# TensorFlow y tf.keras
import tensorflow as tf
from tensorflow import keras
# Librerias de ayuda
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.3.0
Importar el set de datos de moda de MNIST
Esta guia usa el set de datos de Fashion MNIST que contiene mas de 70,000 imagenes en 10 categorias. Las imagenes muestran articulos individuales de ropa a una resolucion baja (28 por 28 pixeles) como se ve aca:
|
|
|
Figure 1. Fashion-MNIST samples (by Zalando, MIT License). |
Moda MNIST esta construida como un reemplazo para el set de datos clasico MNIST casi siempre utilizado como el "Hola Mundo" de programas de aprendizaje automatico (ML) para computo de vision. El set de datos de MNIST contiene imagenes de digitos escrito a mano (0, 1, 2, etc.) en un formato identico al de los articulos de ropa que va a utilizar aca.
Esta guia utiliza Moda MNIST para variedad y por que es un poco mas retador que la regular MNIST. Ambos set de datos son relativamente pequenos y son usados para verificar que el algoritmo funciona como debe.
Aca, 60,000 imagenes son usadas para entrenar la red neuronal y 10,000 imagenes son usadas para evaluar que tan exacto aprendia la red a clasificar imagenes. Pueden acceder al set de moda de MNIST directamente desde TensorFlow. Para importar y cargar el set de datos de MNIST directamente de TensorFlow:
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 1s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
link textAl cargar el set de datos retorna cuatro arreglos en NumPy:
- El arreglo
train_imagesytrain_labelsson los arreglos que training set—el modelo de datos usa para aprender. - el modelo es probado contra los arreglos test set, el
test_images, ytest_labels.
Las imagenes son 28x28 arreglos de NumPy, con valores de pixel que varian de 0 a 255. Los labels son un arreglo de integros, que van del 0 al 9. Estos corresponden a la class de ropa que la imagen representa.
| Label | Class |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
Cada imagen es mapeada a una unica etiqueta. Ya que los Class names no estan incluidoen el dataset, almacenelo aca para usarlos luego cuando se visualicen las imagenes:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Explore el set de datos
Explore el formato de el set de datos antes de entrenar el modelo. Lo siguiente muestra que hay 60,000 imagenes en el set de entrenamiento, con cada imagen representada por pixeles de 28x28:
train_images.shape
(60000, 28, 28)
Asimismo, hay 60,000 etiquetas en el set de entrenamiento:
len(train_labels)
60000
Cada etiqueta es un integro entre 0 y 9:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
Hay 10,000 imagenes en el set de pruebas. Otra vez, cada imagen es representada como pixeles de 28x28:
test_images.shape
(10000, 28, 28)
Y el set de pruebas contiene 10,000 etiquetas de imagen:
len(test_labels)
10000
Pre-procese el set de datos
El set de datos debe ser pre-procesada antes de entrenar la red. Si usted inspecciona la primera imagen en el set de entrenamiento, va a encontrar que los valores de los pixeles estan entre 0 y 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
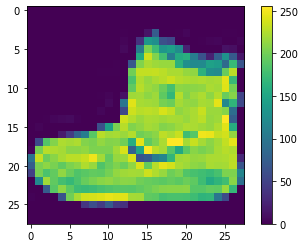
Escale estos valores en un rango de 0 a 1 antes de alimentarlos al modelo de la red neuronal. Para hacero, divida los valores por 255. Es importante que el training set y el testing set se pre-procesen de la misma forma:
train_images = train_images / 255.0
test_images = test_images / 255.0
Para verificar que el set de datos esta en el formato adecuado y que estan listos para construir y entrenar la red, vamos a desplegar las primeras 25 imagenes de el training set y despleguemos el nombre de cada clase debajo de cada imagen.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

Construir el Modelo
Construir la red neuronal requiere configurar las capas del modelo y luego compilar el modelo.
Configurar las Capas
Los bloques de construccion basicos de una red neuronal son las capas o layers. Las capas extraen representaciones de el set de datos que se les alimentan. Con suerte, estas representaciones son considerables para el problema que estamos solucionando.
La mayoria de aprendizaje profundo consiste de unir capas sencillas.
La mayoria de las capas como tf.keras.layers.Dense, tienen parametros que son aprendidos durante el entrenamiento.
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
La primera capa de esta red, tf.keras.layers.Flatten,
transforma el formato de las imagenes de un arreglo bi-dimensional (de 28 por 28 pixeles) a un arreglo uni dimensional (de 28*28 pixeles = 784 pixeles). Observe esta capa como una capa no apilada de filas de pixeles en la misma imagen y alineandolo. Esta capa no tiene parametros que aprender; solo reformatea el set de datos.
Despues de que los pixeles estan "aplanados", la secuencia consiste de dos capastf.keras.layers.Dense. Estas estan densamente conectadas, o completamente conectadas. La primera capa Dense tiene 128 nodos (o neuronas). La segunda (y ultima) capa es una capa de 10 nodos softmax que devuelve un arreglo de 10 probabilidades que suman a 1. Cada nodo contiene una calificacion que indica la probabilidad que la actual imagen pertenece a una de las 10 clases.
Compile el modelo
Antes de que el modelo este listo para entrenar , se necesitan algunas configuraciones mas. Estas son agregadas durante el paso de compilacion del modelo:
- Loss function —Esto mide que tan exacto es el modelo durante el entrenamiento. Quiere minimizar esta funcion para dirigir el modelo en la direccion adecuada.
- Optimizer — Esto es como el modelo se actualiza basado en el set de datos que ve y la funcion de perdida.
- Metrics — Se usan para monitorear los pasos de entrenamiento y de pruebas. El siguiente ejemplo usa accuracy (exactitud) , la fraccion de la imagenes que son correctamente clasificadas.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Entrenar el Modelo
Entrenar el modelo de red neuronal requiere de los siguientes pasos:
- Entregue los datos de entrenamiento al modelo. En este ejemplo , el set de datos de entrenamiento estan en los arreglos
train_imagesytrain_labels. - el modelo aprende a asociar imagenes y etiquetas.
- Usted le pregunta al modelo que haga predicciones sobre un set de datos que se encuentran en el ejemplo,incluido en el arreglo
test_images. Verifique que las predicciones sean iguales a las etiquetas de el arreglotest_labels.
Para comenzar a entrenar, llame el metodo model.fit, es llamado asi por que fit (ajusta) el modelo a el set de datos de entrenamiento:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 3s 1ms/step - loss: 0.5003 - accuracy: 0.8241 Epoch 2/10 1875/1875 [==============================] - 3s 1ms/step - loss: 0.3747 - accuracy: 0.8661 Epoch 3/10 1875/1875 [==============================] - 3s 1ms/step - loss: 0.3359 - accuracy: 0.8776 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3106 - accuracy: 0.8859 Epoch 5/10 1875/1875 [==============================] - 3s 1ms/step - loss: 0.2940 - accuracy: 0.8912 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2797 - accuracy: 0.8967 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2685 - accuracy: 0.9010 Epoch 8/10 1875/1875 [==============================] - 3s 1ms/step - loss: 0.2586 - accuracy: 0.9030 Epoch 9/10 1875/1875 [==============================] - 3s 1ms/step - loss: 0.2468 - accuracy: 0.9074 Epoch 10/10 1875/1875 [==============================] - 3s 1ms/step - loss: 0.2386 - accuracy: 0.9106 <tensorflow.python.keras.callbacks.History at 0x7f5516a46588>
A medida que el modelo entrena, la perdida y la exactitud son desplegadas. Este modelo alcanza una exactitud de 0.88 (o 88%) sobre el set de datos de entrenamiento.
Evaluar Exactitud
Siguente, compare como el rendimiento del modelo sobre el set de datos:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 0s - loss: 0.3350 - accuracy: 0.8840 Test accuracy: 0.8840000033378601
Resulta que la exactitud sobre el set de datos es un poco menor que la exactitud sobre el set de entrenamiento. Esta diferencia entre el entrenamiento y el test se debe a overfitting (sobre ajuste). Sobre ajuste sucede cuando un modelo de aprendizaje de maquina (ML) tiene un rendimiento peor sobre un set de datos nuevo, que nunca antes ha visto comparado con el de entrenamiento.
Hacer predicciones
Con el modelo entrenado usted puede usarlo para hacer predicciones sobre imagenes.
predictions = model.predict(test_images)
Aca, el modelo ha predecido la etiqueta para cada imagen en el set de datos de test (prueba). Miremos la primera prediccion:
predictions[0]
array([8.98017061e-06, 1.05824974e-07, 1.47653412e-09, 6.39178294e-11,
6.63487398e-08, 1.56312122e-03, 3.97483973e-07, 6.77545443e-02,
8.32966691e-08, 9.30672705e-01], dtype=float32)
una prediccion es un arreglo de 10 numeros. Estos representan el nivel de "confianza" del modelo sobre las imagenes de cada uno de los 10 articulos de moda/ropa. Ustedes pueden revisar cual tiene el nivel mas alto de confianza:
np.argmax(predictions[0])
9
Entonces,el modelo tiene mayor confianza que esta imagen es un bota de tobillo "ankle boot" o class_names[9]. Examinando las etiquetas de test o de pruebas muestra que esta clasificaion es correcta:
test_labels[0]
9
Grafique esto para poder ver todo el set de la prediccion de las 10 clases.
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
Miremos la imagen [0], sus predicciones y el arreglo de predicciones. Las etiquetas de prediccion correctas estan en azul y las incorrectas estan en rojo. El numero entrega el porcentaje (sobre 100) para la etiqueta predecida.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()

i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()

Vamos a graficar multiples imagenes con sus predicciones. Notese que el modelo puede estar equivocado aun cuando tiene mucha confianza.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

Finalmente, usamos el modelo entrenado para hacer una prediccion sobre una unica imagen.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
Los modelos de tf.keras son optimizados sobre batch o bloques,
o coleciones de ejemplos por vez.
De acuerdo a esto, aunque use una unica imagen toca agregarla a una lista:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
Ahora prediga la etiqueta correcta para esta imagen:
predictions_single = model.predict(img)
print(predictions_single)
[[2.7196244e-05 2.3026301e-14 9.9943405e-01 3.2361061e-10 3.3726924e-04 6.5815242e-11 2.0145018e-04 1.0427863e-13 4.7570725e-10 5.1079822e-15]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)

model.predict retorna una lista de listas para cada imagen dentro del batch o bloque de datos. Tome la prediccion para nuestra unica imagen dentro del batch o bloque:
np.argmax(predictions_single[0])
2
Y el modelo predice una etiqueta de 2.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.