
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu eğitimde bazı istemci parametreleri sunucuda toplanan asla kısmen lokal federe öğrenmeyi, araştırır. Bu, kullanıcıya özel parametrelere sahip modeller (örn. matris çarpanlara ayırma modelleri) ve iletişimle sınırlı ayarlarda eğitim için kullanışlıdır. Biz tanıtılan kavramların üzerine inşa Image Sınıflandırma için Federe Öğrenme öğretici; Bu eğitimde, biz üst düzey API'leri tanıtmak tff.learning federe eğitim ve değerlendirme için.
Biz kısmen yerel federe öğrenmeyi motive başlamak matris çarpanlara ayırma . Biz Federe İmar (açıklamak kağıt , blog yazısı ), ölçekte kısmen yerel federe öğrenme için pratik bir algoritma. MovieLens 1M veri setini hazırlıyoruz, kısmen yerel bir model oluşturuyoruz ve onu eğitiyor ve değerlendiriyoruz.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
Arka plan: Matris Çarpanlara Ayırma
Matris faktörizasyonu öneriler öğrenme ve kullanıcı etkileşimlerine dayalı öğeler için beyanda gömmek için bir tarihsel popüler tekniği olmuştur. Kurallı örnek olduğu yerde, sinema öneri \(n\) kullanıcıları ve \(m\) filmler ve kullanıcıların bazı filmler yapmıştır. Bir kullanıcı verildiğinde, kullanıcının izlemediği filmlere ilişkin puanlarını tahmin etmek için bu kullanıcının puan geçmişini ve benzer kullanıcıların puanlarını kullanırız. Derecelendirmeleri tahmin edebilen bir modelimiz varsa, kullanıcılara beğenecekleri yeni filmler önermek kolaydır.
Bu görev için, bir şekilde kullanıcıların derecelendirmeleri temsil etmek yararlıdır \(n \times m\) matris \(R\):

Kullanıcılar genellikle veri kümesindeki filmlerin yalnızca küçük bir kısmını gördüğünden, bu matris genellikle seyrektir. Matris çarpanlara çıkışı, iki matris olup: bir \(n \times k\) matris \(U\) temsil \(k\)her kullanıcı için boyutlu kullanıcı katıştırmalarını ve bir \(m \times k\) matris \(I\) temsil \(k\)her madde için boyutlu et katıştırmalarını. En basit eğitim amacı kullanıcı ve madde tespitlerinin nokta ürünü gözlenen değerlendirmesi belirtisi olduğu sağlamaktır \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
Bu, ilgili kullanıcı ve öğe yerleştirmelerinin nokta çarpımını alarak, gözlemlenen derecelendirmeler ile tahmin edilen derecelendirmeler arasındaki ortalama kare hatasının en aza indirilmesine eşdeğerdir. Bu yorumlamak için başka bir yol bu olmasını sağlar ki \(R \approx UI^T\) bilinen değerlendirmesi için, dolayısıyla "matris çarpanlara ayırma". Bu kafa karıştırıcıysa, endişelenmeyin – öğreticinin geri kalanı için matris çarpanlarına ayırmanın ayrıntılarını bilmemize gerek kalmayacak.
MovieLens Verilerini Keşfetme
En yükleyerek başlayalım MovieLens 1M 3706 filmler 6040 kullanıcılardan 1000209 film değerlendirmesi oluşur verileri.
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
Derecelendirme ve film verilerini içeren birkaç Panda DataFrame'i yükleyip keşfedelim.
ratings_df, movies_df = load_movielens_data()
Her derecelendirme örneğinin 1-5 arasında bir derecelendirmeye, karşılık gelen bir Kullanıcı Kimliğine, karşılık gelen bir Film Kimliğine ve bir zaman damgasına sahip olduğunu görebiliriz.
ratings_df.head()
Her filmin bir başlığı ve potansiyel olarak birden fazla türü vardır.
movies_df.head()
Veri kümesinin temel istatistiklerini anlamak her zaman iyi bir fikirdir:
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
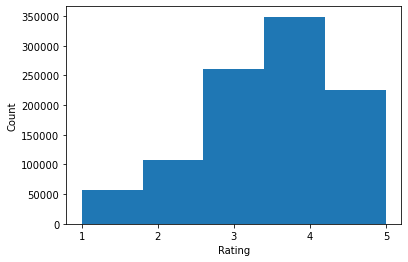
Average rating: 3.581564453029317 Median rating: 4.0
En popüler film türlerini de çizebiliriz.
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
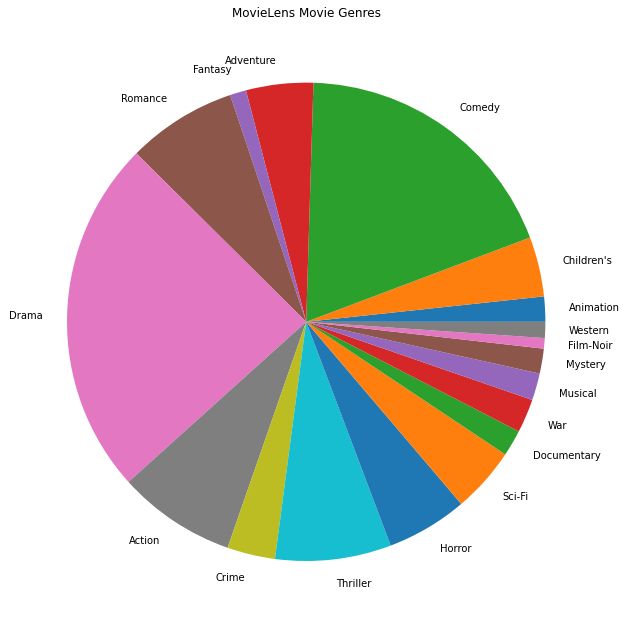
Bu veriler doğal olarak farklı kullanıcıların derecelendirmelerine bölünmüştür, bu nedenle istemciler arasında verilerde bir miktar heterojenlik olmasını bekleriz. Aşağıda, farklı kullanıcılar için en yaygın olarak derecelendirilen film türlerini gösteriyoruz. Kullanıcılar arasında önemli farklılıklar gözlemleyebiliriz.
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
MovieLens Verilerini Ön İşleme
Şimdi listesi olarak MovieLens veri kümesini hazırlayacağız tf.data.Dataset s TFF ile kullanılmak üzere her bir kullanıcının verilerini temsil eden.
İki işlevi uyguluyoruz:
-
create_tf_datasets: bizim derecelendirme DataFrame alır ve kullanıcı bölünmüş bir listesini üretirtf.data.Datasets. -
split_tf_datasets: val / test setleri eğitim sırasında görünmeyen kullanıcılardan sadece derecelendirme içerirler bu yüzden, veri setleri ve kullanıcı tarafından tren / val / test içine böler onları bir listesini alır. Görünmeyen kullanıcılar kullanıcı katıştırmalarını olmadığı için Tipik standart merkezi matris çarpanlarına içinde biz aslında, val / test setleri görülen kullanıcı arasında gerçekleşecek aşımı derecelendirme içermesi böylece bölün. Bizim durumumuzda, FL'de matris çarpanlarına ayırmayı etkinleştirmek için kullandığımız yaklaşımın, görünmeyen kullanıcılar için kullanıcı yerleştirmelerini hızla yeniden yapılandırmayı da sağladığını daha sonra göreceğiz.
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
Hızlı bir kontrol olarak, bir grup eğitim verisi yazdırabiliriz. Her bir örneğin, "x" tuşu altında bir MovieID ve "y" tuşu altında bir derecelendirme içerdiğini görebiliriz. Her kullanıcı yalnızca kendi verilerini gördüğü için Kullanıcı Kimliğine ihtiyacımız olmayacağını unutmayın.
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
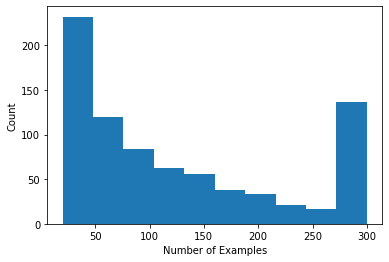
Kullanıcı başına derecelendirme sayısını gösteren bir histogram çizebiliriz.
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
Artık verileri yüklediğimize ve araştırdığımıza göre, matris çarpanlarına ayırmanın birleşik öğrenmeye nasıl getirileceğini tartışacağız. Yol boyunca, kısmen yerel federe öğrenmeyi motive edeceğiz.
Matris Çarpanlaştırmayı FL'ye Getirme
Matris çarpanlara ayırma geleneksel olarak merkezi ayarlarda kullanılsa da, özellikle birleşik öğrenmeyle ilgilidir: kullanıcı derecelendirmeleri ayrı istemci cihazlarda yaşayabilir ve verileri merkezileştirmeden kullanıcılar ve öğeler için yerleştirmeleri ve önerileri öğrenmek isteyebiliriz. Her kullanıcının karşılık gelen bir kullanıcı yerleştirmesi olduğundan, her istemcinin kendi kullanıcı yerleştirmelerini depolaması doğaldır - bu, tüm kullanıcı yerleştirmelerini depolayan merkezi bir sunucudan çok daha iyi ölçeklenir.
FL'ye matris çarpanlarına ayırma önerisi şu şekildedir:
- Sunucu depolar ve madde matrisi gönderir \(I\) örneklenmiş müşterilerine her turda
- Müşteriler madde matrisi güncellemek ve kişisel kullanıcı gömme \(U_u\) yukarıdaki amaç üzerinde SGD kullanarak
- Güncellemeler \(I\) sunucu kopyasını güncellenmesi, sunucu üzerinde toplanır \(I\) sonraki turda
Bu yaklaşım, bazı istemci parametreleri sunucu tarafından toplanan asla -yani kısmen yerel. Bu yaklaşım çekici olsa da, istemcilerin turlar boyunca durumu, yani kullanıcı yerleştirmelerini korumasını gerektirir. Durum bilgisi olan federe algoritmalar, cihazlar arası FL ayarları için daha az uygundur: bu ayarlarda popülasyon boyutu genellikle her tura katılan istemci sayısından çok daha fazladır ve bir istemci eğitim süreci sırasında genellikle en fazla bir kez katılır. Müşteriler seyrek numune zaman başlatılmamış olabilir durumuna dayanarak yanı sıra, durum bilgisi algoritmalar bağlı durum alma eski çapraz cihaz ayarları performans düşmesine neden olabilir. Önemli olarak, matris çarpanlara ayırma ayarında, durum bilgisi olan bir algoritma, tüm görünmeyen istemcilerin eğitilmiş kullanıcı yerleştirmelerini kaçırmasına neden olur ve büyük ölçekli eğitimde, kullanıcıların çoğunluğu görülmeyebilir. Cihazlar arası FL durum bilgisi algoritmaları için motivasyon daha fazla bilgi için, bakınız , Wang et al. 2021 Sn. 3.1.1 ve Reddi vd. 2020 Sek. 5.1 .
Federal Yeniden ( ve ark. 2021 Singhal ) yukarıda sözü edilen yaklaşım bir bilgisi olmayan bir alternatiftir. Ana fikir, kullanıcı yerleştirmelerini turlar arasında depolamak yerine, müşterilerin gerektiğinde kullanıcı yerleştirmelerini yeniden oluşturmasıdır. FedRecon matris çarpanlarına ayırmaya uygulandığında eğitim şu şekilde ilerler:
- Sunucu depolar ve madde matrisi gönderir \(I\) örneklenmiş müşterilerine her turda
- Her müşteri donar \(I\) ve kullanıcı gömme trenler \(U_u\) SGD bir veya daha fazla aşamasını kullanarak (yeniden)
- Her müşteri donar \(U_u\) ve trenler \(I\) SGD bir veya daha fazla aşamasını kullanarak
- Güncellemeler \(I\) sunucu kopyasını güncellenmesi, kullanıcı arasında toplanır \(I\) sonraki turda
Bu yaklaşım, istemcilerin turlar arasında durumu korumasını gerektirmez. Yazarlar ayrıca makalede, bu yöntemin, görünmeyen müşteriler için kullanıcı yerleştirmelerinin hızlı bir şekilde yeniden oluşturulmasına yol açtığını (Kısım 4.2, Şekil 3 ve Tablo 1), eğitime katılmayan müşterilerin çoğunluğunun eğitimli bir modele sahip olmasına izin verdiğini gösteriyor. , bu istemciler için önerileri etkinleştirme. Federe Yeniden görün tarihinde AI Blog post daha önemli sonuçlar için.
Modelin Tanımlanması
Daha sonra, istemci cihazlarda eğitilecek yerel matris çarpanlara ayırma modelini tanımlayacağız. Bu model tam öğe matris içerecektir \(I\) ve tek bir kullanıcı gömme \(U_u\) istemci için \(u\). İstemcilerin tam kullanıcı matris saklamak gerek olmayacak Not \(U\).
Aşağıdakileri tanımlayacağız:
-
UserEmbedding: Tek temsil basit Keras tabakanum_latent_factorsboyutlu kullanıcı gömme. -
get_matrix_factorization_model: döner bir bir fonksiyonutff.learning.reconstruction.Modeltabakalar genel olarak sunucu üzerinde toplanır ve hangi tabakalar yerel kaldığı içeren model mantığı, ihtiva etmektedir. Federe Yeniden Yapılanma eğitim sürecini başlatmak için bu ek bilgiye ihtiyacımız var. Burada üretmektff.learning.reconstruction.Modelkullanarak bir Keras modelindentff.learning.reconstruction.from_keras_model. Benzertff.learning.Model, biz de özel uygulayabilirtff.learning.reconstruction.Modelsınıf arabirimini uygulayarak.
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
Federe Ortalaması için arayüzüne biçime benzer, Federe Yeniden Yapılanma arayüz bekliyor model_fn hiçbir argüman döndürdüğü bir ile tff.learning.reconstruction.Model .
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
Gelecek tanımlayacağız loss_fn ve metrics_fn , loss_fn modeli eğitmek için kullanılacak bir Keras kaybı dönen no-argüman fonksiyonudur ve metrics_fn değerlendirme için Keras ölçümlerin listesini dönen no-argüman fonksiyonudur. Bunlar, eğitim ve değerlendirme hesaplamalarını oluşturmak için gereklidir.
Yukarıda belirtildiği gibi kayıp olarak Ortalama Kare Hatasını kullanacağız. Değerlendirme için derecelendirme doğruluğunu kullanacağız (modelin tahmin edilen nokta çarpımı en yakın tam sayıya yuvarlandığında, etiket derecelendirmesiyle ne sıklıkla eşleşir?).
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
Eğitim ve Değerlendirme
Artık eğitim sürecini tanımlamak için ihtiyacımız olan her şeye sahibiz. Dan Önemli bir farklılık Federe Ortalaması için arayüzde artık bir içinde geçer ki reconstruction_optimizer_fn (bizim durumumuzda, kullanıcı gömmeler olarak) yerel parametreler yeniden ne zaman kullanılacaktır. Kullanımı genellikle makul SGD benzer burada, ya da biraz oranını öğrenme iyileştirici istemci daha oranını öğrenme düşürün. Aşağıda çalışan bir konfigürasyon sunuyoruz. Bu, dikkatli bir şekilde ayarlanmamıştır, bu nedenle farklı değerlerle oynamaktan çekinmeyin.
Check out belgelere fazla ayrıntı ve seçenekleri için.
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
Ayrıca eğitilmiş küresel modelimizi değerlendirmek için bir hesaplama tanımlayabiliriz.
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
Eğitim süreci durumunu başlatabilir ve inceleyebiliriz. En önemlisi, bu sunucu durumunun herhangi bir kullanıcı yerleştirmesini değil, yalnızca öğe değişkenlerini (şu anda rastgele başlatılmış) depoladığını görebiliriz.
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
Ayrıca doğrulama istemcilerinde rastgele başlatılan modelimizi değerlendirmeyi deneyebiliriz. Burada Federe Yeniden Yapılanma değerlendirmesi aşağıdakileri içerir:
- Sunucu öğesi matris gönderir \(I\) örneklenmiş değerlendirme müşterilerine
- Her müşteri donar \(I\) ve kullanıcı gömme trenler \(U_u\) SGD bir veya daha fazla aşamasını kullanarak (yeniden)
- Sunucu kullanan her müşteri hesaplar kaybı ve metrikleri \(I\) ve yeniden \(U_u\) kendi yerel verileri görünmeyen bir bölümü üzerinde
- Genel kaybı ve metrikleri hesaplamak için kullanıcılar arasında kayıpların ve ölçümlerin ortalaması alınır
Adım 1 ve 2'nin eğitim ile aynı olduğunu unutmayın. Bu bağlantı meta-öğrenme veya öğrenmeyi öğrenme bir forma promosyonu değerlendirmek aynı şekilde eğitim beri önemlidir. Bu durumda, model, yerel değişkenlerin (kullanıcı yerleştirmeleri) başarılı bir şekilde yeniden yapılandırılmasına yol açan global değişkenlerin (öğe matrisi) nasıl öğrenileceğini öğreniyor. Bu konuda daha fazla bilgi için bkz : Sn. 4.2 kağıdın.
Adil değerlendirmeyi sağlamak için 2. ve 3. adımların müşterilerin yerel verilerinin ayrık kısımları kullanılarak gerçekleştirilmesi de önemlidir. Varsayılan olarak, hem eğitim süreci hem de değerlendirme hesaplaması, yeniden yapılandırma için diğer tüm örnekleri kullanır ve yeniden yapılandırma sonrası diğer yarısını kullanır. Bu davranış kullanılarak özelleştirilebilir dataset_split_fn argüman (daha sonra daha da bu inceleyeceğiz).
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
Daha sonra bir tur antrenman yapmayı deneyebiliriz. İşleri daha gerçekçi hale getirmek için, her turda 50 müşteriyi değiştirmeden rastgele örnekleyeceğiz. Yalnızca bir tur eğitim yaptığımız için, yine de tren ölçümlerinin zayıf olmasını beklemeliyiz.
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
Şimdi birden fazla turda antrenman yapmak için bir eğitim döngüsü oluşturalım.
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
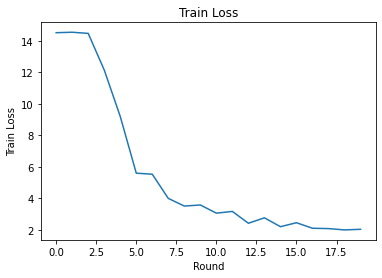
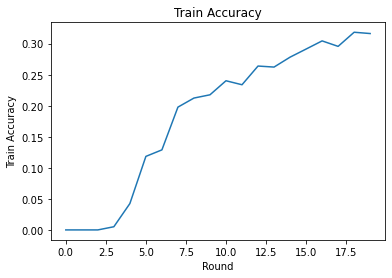
Eğitim kaybını ve isabetliliğini turlar üzerinden çizebiliriz. Bu not defterindeki hiperparametreler dikkatli bir şekilde ayarlanmamıştır, bu nedenle bu sonuçları iyileştirmek için tur başına farklı istemciler, öğrenme oranları, tur sayısı ve toplam istemci sayısı denemekten çekinmeyin.
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
Son olarak, ayarlamayı bitirdiğimizde görünmeyen bir test setindeki metrikleri hesaplayabiliriz.
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
Daha Fazla Keşif
Bu defteri tamamlamak için güzel bir çalışma. Kısmen yerel federe öğrenmeyi daha fazla keşfetmek için, artan zorluk derecesine göre kabaca sıralanan aşağıdaki alıştırmaları öneriyoruz:
Birleşik Ortalamanın tipik uygulamaları, veriler üzerinde birden çok yerel geçiş (dönem) alır (veriler üzerinde birden çok toplu iş üzerinde bir geçiş yapılmasına ek olarak). Federe Yeniden Yapılanma için, yeniden yapılandırma ve yeniden yapılandırma sonrası eğitim için adımların sayısını ayrı ayrı kontrol etmek isteyebiliriz. Geçme
dataset_split_fneğitim ve değerlendirme hesaplama inşaatçılar için argüman hem yeniden yapılanma ve rekonstrüksiyon sonrası veri setleri üzerinde adımları ve devirlerin sayısı kontrolünü sağlar. Bir alıştırma olarak, 50 adımda sınırlandırılmış 3 yerel yeniden yapılandırma eğitimi dönemi ve 50 adımda sınırlandırılmış 1 yerel yeniden yapılandırma sonrası eğitim dönemi gerçekleştirmeyi deneyin. İpucu: Eğer bulacaksınıztff.learning.reconstruction.build_dataset_split_fnyararlı. Bunu yaptıktan sonra, daha iyi sonuçlar elde etmek için bu hiperparametreleri ve öğrenme oranları ve parti boyutu gibi diğer ilgili parametreleri ayarlamayı deneyin.Federe Yeniden Yapılanma eğitimi ve değerlendirmesinin varsayılan davranışı, yeniden yapılandırma ve yeniden yapılandırma sonrası her biri için müşterilerin yerel verilerini ikiye bölmektir. Müşterilerin çok az yerel veriye sahip olduğu durumlarda, verileri yalnızca eğitim süreci için yeniden yapılandırma ve yeniden yapılandırma için yeniden kullanmak makul olabilir (değerlendirme için değil, bu haksız değerlendirmeye yol açacaktır). Eğitim süreci için bu değişikliği yapma sağlanması deneyin
dataset_split_fndeğerlendirme için hala imar ve rekonstrüksiyon sonrası veri gg ayrık tutar. İpucu:tff.learning.reconstruction.simple_dataset_split_fnyararlı olabilir.Yukarıda, biz üretilen
tff.learning.Modelkullanarak Keras modelindentff.learning.reconstruction.from_keras_model. Biz de saf TensorFlow 2.0 kullanan bir özel model uygulayabilir modeli arabirimini uygulayan . Değiştirerek deneyinget_matrix_factorization_modelinşa etmek ve genişleten bir sınıf dönmek içintff.learning.reconstruction.Modelyöntemlerini uygulamak. İpucu: kaynak kodutff.learning.reconstruction.from_keras_modeluzanan bir örneğini sağlartff.learning.reconstruction.Modelsınıfını. Ayrıca bkz EMNIST görüntü sınıflandırma eğitimde özel model uygulanması bir uzanan benzer bir egzersiz içintff.learning.Model.Bu öğreticide, sunucuya kullanıcı yerleştirmelerini göndermenin kullanıcı tercihlerini önemsiz bir şekilde sızdıracağı matris çarpanlarına ayırma bağlamında kısmen yerel birleştirilmiş öğrenmeyi motive ettik. Federe Yeniden Yapılandırmayı, iletişimi azaltırken (yerel parametreler sunucuya gönderilmediğinden) daha kişisel modelleri eğitmenin bir yolu olarak (modelin bir parçası her kullanıcı için tamamen yerel olduğundan) başka ayarlarda da uygulayabiliriz. Genel olarak, burada sunulan arabirimi kullanarak, tipik olarak tamamen global olarak eğitilmiş herhangi bir birleşik modeli alabilir ve bunun yerine değişkenlerini global değişkenler ve yerel değişkenler olarak bölebiliriz. İncelenmiştir örnek Federe Yeniden kağıt kişisel sonraki kelime tahmini: Burada, her kullanıcının, out-of-kelime kelime kelime tespitlerinin kendi yerel kümesi vardır yakalama kullanıcıların argo modelini sağlayan ve ek iletişim olmadan kişiselleştirme başarmak. Bir alıştırma olarak, Federated Reconstruction ile kullanmak için (bir Keras modeli veya özel bir TensorFlow 2.0 modeli olarak) farklı bir model uygulamayı deneyin. Bir öneri: kişisel kullanıcı yerleştirme ile bir EMNIST sınıflandırma modeli uygulayın, burada kişisel kullanıcı yerleştirme, modelin son Yoğun katmanından önce CNN görüntü özellikleriyle birleştirilir. Bu öğretici kod (örneğin çok yeniden kullanabilirsiniz
UserEmbeddingsınıfı) ve görüntünün sınıflandırma öğretici .
Hala daha kısmen yerel federe öğrenme arıyorsanız, check out Federe Yeniden kağıt ve açık kaynak Deneme kodunu .