
| | |  Ver fonte no GitHub Ver fonte no GitHub |
Documentação da API: tf.RaggedTensor tf.ragged
Configurar
import math
import tensorflow as tf
Visão geral
Seus dados vêm em muitas formas; seus tensores também devem. Os tensores irregulares são o equivalente do TensorFlow de listas de comprimento variável aninhadas. Eles facilitam o armazenamento e o processamento de dados com formas não uniformes, incluindo:
- Recursos de duração variável, como o conjunto de atores em um filme.
- Lotes de entradas sequenciais de comprimento variável, como frases ou videoclipes.
- Entradas hierárquicas, como documentos de texto subdivididos em seções, parágrafos, frases e palavras.
- Campos individuais em entradas estruturadas, como buffers de protocolo.
O que você pode fazer com um tensor irregular
Os tensores irregulares são suportados por mais de uma centena de operações do TensorFlow, incluindo operações matemáticas (como tf.add e tf.reduce_mean ), operações de matriz (como tf.concat e tf.tile ), operações de manipulação de strings (como tf.substr ), operações de fluxo de controle (como tf.while_loop e tf.map_fn ), e muitos outros:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
Há também vários métodos e operações específicos para tensores irregulares, incluindo métodos de fábrica, métodos de conversão e operações de mapeamento de valor. Para obter uma lista de operações suportadas, consulte a documentação do pacote tf.ragged .
Os tensores irregulares são compatíveis com muitas APIs do TensorFlow, incluindo Keras , Datasets , tf.function , SavedModels e tf.Example . Para obter mais informações, consulte a seção sobre APIs do TensorFlow abaixo.
Assim como com tensores normais, você pode usar a indexação no estilo Python para acessar fatias específicas de um tensor irregular. Para obter mais informações, consulte a seção sobre Indexação abaixo.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
E assim como os tensores normais, você pode usar os operadores aritméticos e de comparação do Python para realizar operações elementares. Para obter mais informações, consulte a seção sobre Operadores sobrecarregados abaixo.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
Se você precisar realizar uma transformação elementwise para os valores de um RaggedTensor , poderá usar tf.ragged.map_flat_values , que recebe uma função mais um ou mais argumentos e aplica a função para transformar os valores do RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Os tensores irregulares podem ser convertidos em list Python aninhadas e array NumPy:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
Construindo um tensor irregular
A maneira mais simples de construir um tensor ragged é usando tf.ragged.constant , que constrói o RaggedTensor correspondente a uma determinada list Python aninhada ou array NumPy :
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
Os tensores irregulares também podem ser construídos emparelhando tensores de valores planos com tensores de particionamento de linha indicando como esses valores devem ser divididos em linhas, usando métodos de classe de fábrica como tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths e tf.RaggedTensor.from_row_splits .
tf.RaggedTensor.from_value_rowids
Se você souber a qual linha cada valor pertence, poderá construir um RaggedTensor usando um tensor de particionamento de linha value_rowids :
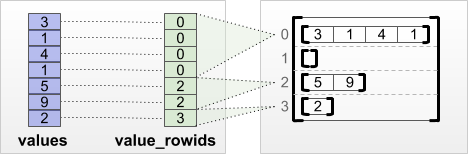
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
Se você souber o comprimento de cada linha, poderá usar um tensor de particionamento de linha row_lengths :
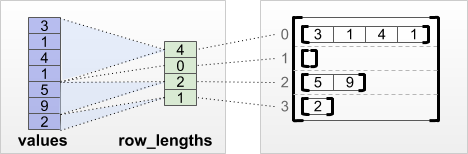
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
Se você conhece o índice onde cada linha começa e termina, então você pode usar um tensor de particionamento de linha row_splits :
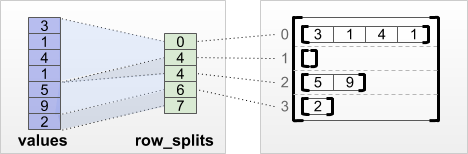
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Consulte a documentação da classe tf.RaggedTensor para obter uma lista completa de métodos de fábrica.
O que você pode armazenar em um tensor irregular
Assim como acontece com os Tensor s normais, os valores em um RaggedTensor devem ser todos do mesmo tipo; e os valores devem estar todos na mesma profundidade de aninhamento (a classificação do tensor):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
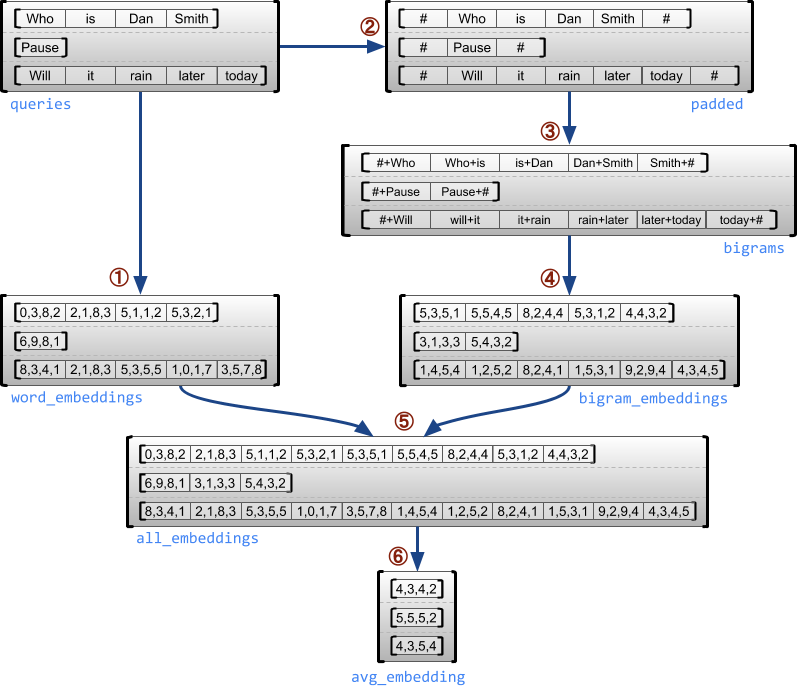
Caso de uso de exemplo
O exemplo a seguir demonstra como RaggedTensor s pode ser usado para construir e combinar embeddings de unigrama e bigrama para um lote de consultas de comprimento variável, usando marcadores especiais para o início e o final de cada frase. Para obter mais detalhes sobre as operações usadas neste exemplo, verifique a documentação do pacote tf.ragged .
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
Dimensões irregulares e uniformes
Uma dimensão irregular é uma dimensão cujas fatias podem ter comprimentos diferentes. Por exemplo, a dimensão interna (coluna) de rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] é irregular, pois as fatias de coluna ( rt[0, :] , ..., rt[4, :] ) têm comprimentos diferentes. Dimensões cujas fatias têm o mesmo comprimento são chamadas de dimensões uniformes .
A dimensão mais externa de um tensor irregular é sempre uniforme, pois consiste em uma única fatia (e, portanto, não há possibilidade de diferentes comprimentos de fatia). As dimensões restantes podem ser irregulares ou uniformes. Por exemplo, você pode armazenar as incorporações de palavras para cada palavra em um lote de frases usando um tensor irregular com forma [num_sentences, (num_words), embedding_size] , onde os parênteses ao redor (num_words) indicam que a dimensão está irregular.
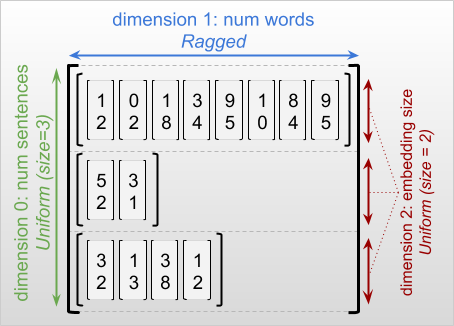
Os tensores irregulares podem ter várias dimensões irregulares. Por exemplo, você pode armazenar um lote de documentos de texto estruturado usando um tensor com forma [num_documents, (num_paragraphs), (num_sentences), (num_words)] (onde novamente os parênteses são usados para indicar dimensões irregulares).
Assim como com tf.Tensor , a classificação de um tensor irregular é seu número total de dimensões (incluindo dimensões irregulares e uniformes). Um tensor potencialmente irregular é um valor que pode ser um tf.Tensor ou um tf.RaggedTensor .
Ao descrever a forma de um RaggedTensor, as dimensões irregulares são convencionalmente indicadas colocando-as entre parênteses. Por exemplo, como você viu acima, a forma de um 3D RaggedTensor que armazena embeddings de cada palavra em um lote de frases pode ser escrita como [num_sentences, (num_words), embedding_size] .
O atributo RaggedTensor.shape retorna um tf.TensorShape para um tensor ragged onde as dimensões ragged têm tamanho None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
O método tf.RaggedTensor.bounding_shape pode ser usado para encontrar uma forma delimitadora apertada para um determinado RaggedTensor :
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Esfarrapado vs esparso
Um tensor irregular não deve ser pensado como um tipo de tensor esparso. Em particular, tensores esparsos são codificações eficientes para tf.Tensor que modelam os mesmos dados em um formato compacto; mas o tensor irregular é uma extensão do tf.Tensor que modela uma classe expandida de dados. Essa diferença é crucial ao definir as operações:
- Aplicar um op a um tensor esparso ou denso deve sempre dar o mesmo resultado.
- Aplicar um op a um tensor irregular ou esparso pode dar resultados diferentes.
Como exemplo ilustrativo, considere como as operações de matriz como concat , stack e tile são definidas para tensores irregulares versus esparsos. A concatenação de tensores irregulares une cada linha para formar uma única linha com o comprimento combinado:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
No entanto, concatenar tensores esparsos é equivalente a concatenar os tensores densos correspondentes, conforme ilustrado pelo exemplo a seguir (onde Ø indica valores ausentes):
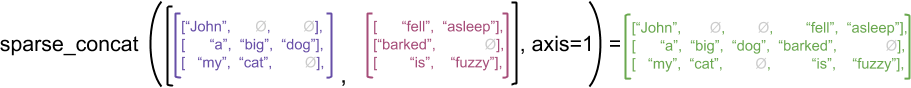
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
Para outro exemplo de por que essa distinção é importante, considere a definição de “o valor médio de cada linha” para uma operação como tf.reduce_mean . Para um tensor irregular, o valor médio de uma linha é a soma dos valores da linha dividida pela largura da linha. Mas para um tensor esparso, o valor médio de uma linha é a soma dos valores da linha dividida pela largura geral do tensor esparso (que é maior ou igual à largura da linha mais longa).
APIs do TensorFlow
Keras
tf.keras é a API de alto nível do TensorFlow para criar e treinar modelos de aprendizado profundo. Os tensores irregulares podem ser passados como entradas para um modelo Keras definindo ragged=True em tf.keras.Input ou tf.keras.layers.InputLayer . Os tensores irregulares também podem ser passados entre camadas Keras e retornados por modelos Keras. O exemplo a seguir mostra um modelo LSTM de brinquedo que é treinado usando tensores irregulares.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.Exemplo
tf.Example é uma codificação protobuf padrão para dados do TensorFlow. Os dados codificados com tf.Example s geralmente incluem recursos de comprimento variável. Por exemplo, o código a seguir define um lote de quatro mensagens tf.Example com diferentes comprimentos de recurso:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
Você pode analisar esses dados codificados usando tf.io.parse_example , que recebe um tensor de strings serializadas e um dicionário de especificação de recursos e retorna um dicionário mapeando nomes de recursos para tensores. Para ler os recursos de comprimento variável em tensores irregulares, basta usar tf.io.RaggedFeature no dicionário de especificação de recursos:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature também pode ser usado para ler recursos com várias dimensões irregulares. Para obter detalhes, consulte a documentação da API .
Conjuntos de dados
tf.data é uma API que permite criar pipelines de entrada complexos a partir de peças simples e reutilizáveis. Sua estrutura de dados central é tf.data.Dataset , que representa uma sequência de elementos, na qual cada elemento consiste em um ou mais componentes.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
Como criar conjuntos de dados com tensores irregulares
Conjuntos de dados podem ser construídos a partir de tensores irregulares usando os mesmos métodos que são usados para construí-los de tf.Tensor s ou array s NumPy, como Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Conjuntos de dados em lote e desmontagem com tensores irregulares
Conjuntos de dados com tensores irregulares podem ser agrupados (o que combina n elementos consecutivos em um único elemento) usando o método Dataset.batch .
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
Por outro lado, um conjunto de dados em lote pode ser transformado em um conjunto de dados simples usando Dataset.unbatch .
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Conjuntos de dados em lote com tensores não irregulares de comprimento variável
Se você tiver um conjunto de dados que contém tensores não irregulares e os comprimentos dos tensores variam entre os elementos, você pode agrupar esses tensores não irregulares em tensores irregulares aplicando a transformação dense_to_ragged_batch :
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
Transformando conjuntos de dados com tensores irregulares
Você também pode criar ou transformar tensores irregulares em Datasets usando Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.função
tf.function é um decorador que pré-computa gráficos do TensorFlow para funções do Python, o que pode melhorar substancialmente o desempenho do seu código do TensorFlow. Os tensores irregulares podem ser usados de forma transparente com funções @tf.function -decorated. Por exemplo, a função a seguir funciona com tensores irregulares e não irregulares:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
Se você deseja especificar explicitamente o input_signature para o tf.function , pode fazê-lo usando tf.RaggedTensorSpec .
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
Funções concretas
As funções concretas encapsulam gráficos rastreados individuais que são construídos por tf.function . Os tensores irregulares podem ser usados de forma transparente com funções concretas.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
Modelos salvos
Um SavedModel é um programa TensorFlow serializado, incluindo pesos e computação. Ele pode ser construído a partir de um modelo Keras ou de um modelo personalizado. Em ambos os casos, tensores irregulares podem ser usados de forma transparente com as funções e métodos definidos por um SavedModel.
Exemplo: salvar um modelo Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
Exemplo: salvar um modelo personalizado
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
Operadores sobrecarregados
A classe RaggedTensor sobrecarrega os operadores aritméticos e de comparação padrão do Python, facilitando a execução de matemática elementar básica:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
Como os operadores sobrecarregados realizam cálculos elementares, as entradas para todas as operações binárias devem ter a mesma forma ou ser transmitidas para a mesma forma. No caso de transmissão mais simples, um único escalar é combinado elemento a elemento com cada valor em um tensor irregular:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Para uma discussão de casos mais avançados, consulte a seção sobre Transmissão .
Os tensores irregulares sobrecarregam o mesmo conjunto de operadores que os Tensor normais: os operadores unários - , ~ e abs() ; e os operadores binários + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > e >= .
Indexação
Os tensores irregulares suportam indexação no estilo Python, incluindo indexação e fatiamento multidimensional. Os exemplos a seguir demonstram a indexação de tensor irregular com um tensor irregular 2D e 3D.
Exemplos de indexação: tensor irregular 2D
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
Exemplos de indexação: tensor irregular 3D
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
O RaggedTensor suporta indexação e fatiamento multidimensional com uma restrição: a indexação em uma dimensão irregular não é permitida. Este caso é problemático porque o valor indicado pode existir em algumas linhas, mas não em outras. Nesses casos, não é óbvio se você deve (1) gerar um IndexError ; (2) usar um valor padrão; ou (3) pule esse valor e retorne um tensor com menos linhas do que você começou. Seguindo os princípios orientadores do Python ("Em face da ambiguidade, recuse a tentação de adivinhar"), essa operação não é permitida no momento.
Conversão de tipo de tensor
A classe RaggedTensor define métodos que podem ser usados para converter entre RaggedTensor se tf.Tensor s ou tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
Avaliando tensores irregulares
Para acessar os valores em um tensor irregular, você pode:
- Use
tf.RaggedTensor.to_listpara converter o tensor irregular em uma lista Python aninhada. - Use
tf.RaggedTensor.numpypara converter o tensor irregular em um array NumPy cujos valores são arrays NumPy aninhados. - Decomponha o tensor irregular em seus componentes, usando as propriedades
tf.RaggedTensor.valuesetf.RaggedTensor.row_splits, ou métodos de particionamento de linha, comotf.RaggedTensor.row_lengthsetf.RaggedTensor.value_rowids. - Use a indexação do Python para selecionar valores do tensor irregular.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
Transmissão
Broadcasting é o processo de fazer tensores com formas diferentes terem formas compatíveis para operações elementares. Para mais informações sobre transmissão, consulte:
As etapas básicas para transmitir duas entradas x e y para que tenham formas compatíveis são:
Se
xeynão tiverem o mesmo número de dimensões, adicione dimensões externas (com tamanho 1) até que tenham.Para cada dimensão em que
xeytêm tamanhos diferentes:
- Se
xouytiverem tamanho1na dimensãod, repita seus valores na dimensãodpara corresponder ao tamanho da outra entrada. - Caso contrário, lance uma exceção (
xeynão são compatíveis com broadcast).
Onde o tamanho de um tensor em uma dimensão uniforme é um único número (o tamanho das fatias nessa dimensão); e o tamanho de um tensor em uma dimensão irregular é uma lista de comprimentos de fatias (para todas as fatias nessa dimensão).
Exemplos de transmissão
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
Aqui estão alguns exemplos de formas que não transmitem:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
Codificação RaggedTensor
Os tensores irregulares são codificados usando a classe RaggedTensor . Internamente, cada RaggedTensor consiste em:
- Um tensor de
values, que concatena as linhas de comprimento variável em uma lista achatada. - Um
row_partition, que indica como esses valores achatados são divididos em linhas.
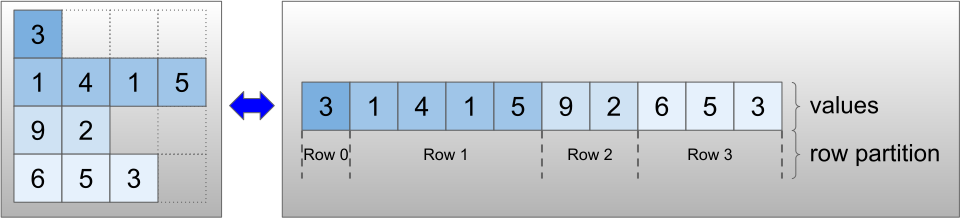
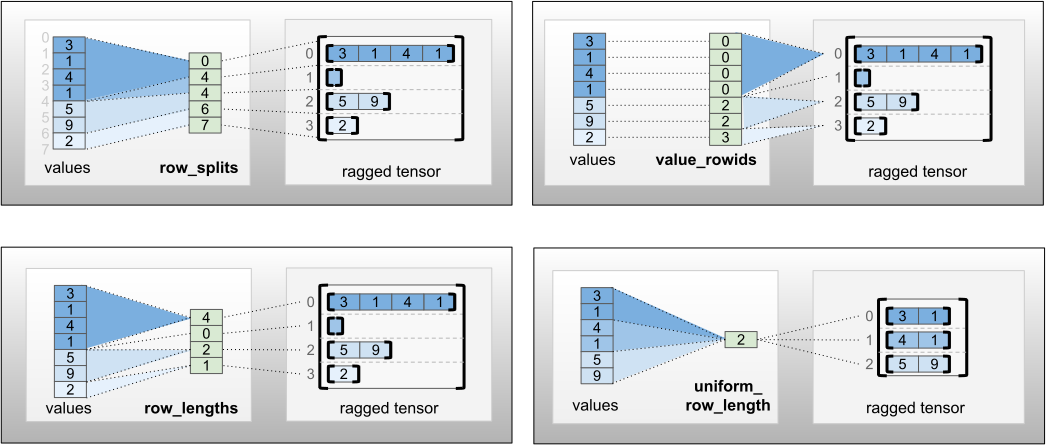
A row_partition pode ser armazenada usando quatro codificações diferentes:
-
row_splitsé um vetor inteiro que especifica os pontos de divisão entre as linhas. -
value_rowidsé um vetor inteiro que especifica o índice de linha para cada valor. -
row_lengthsé um vetor inteiro que especifica o comprimento de cada linha. -
uniform_row_lengthé um escalar inteiro que especifica um comprimento único para todas as linhas.
Um inteiro escalar nrows também pode ser incluído na codificação row_partition para contabilizar linhas vazias à direita com value_rowids ou linhas vazias com uniform_row_length .
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
A escolha de qual codificação usar para partições de linha é gerenciada internamente por tensores irregulares para melhorar a eficiência em alguns contextos. Em particular, algumas das vantagens e desvantagens dos diferentes esquemas de particionamento de linhas são:
- Indexação eficiente : A codificação
row_splitspermite indexação em tempo constante e fatiamento em tensores irregulares. - Concatenação eficiente : A codificação
row_lengthsé mais eficiente ao concatenar tensores irregulares, pois os comprimentos das linhas não mudam quando dois tensores são concatenados juntos. - Tamanho de codificação pequeno : A codificação
value_rowidsé mais eficiente ao armazenar tensores irregulares que possuem um grande número de linhas vazias, pois o tamanho do tensor depende apenas do número total de valores. Por outro lado, as codificaçõesrow_splitserow_lengthssão mais eficientes ao armazenar tensores irregulares com linhas mais longas, pois requerem apenas um valor escalar para cada linha. - Compatibilidade : O esquema
value_rowidscorresponde ao formato de segmentação usado por operações, comotf.segment_sum. O esquemarow_limitscorresponde ao formato usado por operações comotf.sequence_mask. - Dimensões uniformes : Conforme discutido abaixo, a codificação
uniform_row_lengthé usada para codificar tensores irregulares com dimensões uniformes.
Várias dimensões irregulares
Um tensor irregular com várias dimensões irregulares é codificado usando um RaggedTensor aninhado para o tensor de values . Cada RaggedTensor aninhado adiciona uma única dimensão irregular.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
A função de fábrica tf.RaggedTensor.from_nested_row_splits pode ser usada para construir um RaggedTensor com várias dimensões ragged diretamente fornecendo uma lista de tensores row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
Classificação irregular e valores planos
A classificação irregular de um tensor irregular é o número de vezes que o tensor de values subjacentes foi particionado (ou seja, a profundidade de aninhamento de objetos RaggedTensor ). O tensor de values mais internos é conhecido como flat_values . No exemplo a seguir, as conversations têm ragged_rank=3 e seus flat_values são um Tensor 1D com 24 strings:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
Dimensões internas uniformes
Os tensores irregulares com dimensões internas uniformes são codificados usando um tf.Tensor multidimensional para os flat_values (ou seja, os values mais internos).
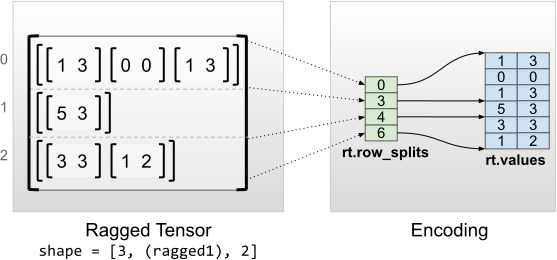
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
Dimensões não internas uniformes
Os tensores irregulares com dimensões não internas uniformes são codificados por linhas de particionamento com uniform_row_length .
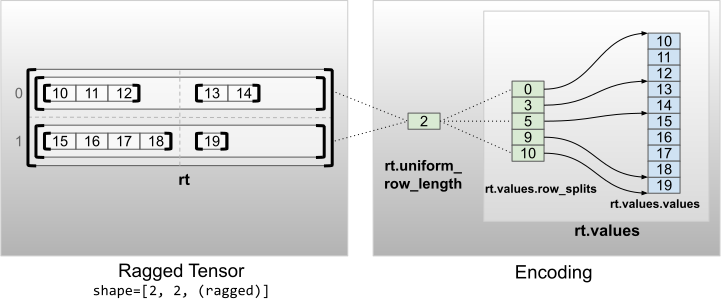
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2