
Aperçu
TensorFlow Model Analysis (TFMA) est une bibliothèque permettant d'effectuer l'évaluation de modèles.
- Pour : Ingénieurs en Machine Learning ou Data Scientists
- qui : souhaite analyser et comprendre ses modèles TensorFlow
- c'est : une bibliothèque autonome ou un composant d'un pipeline TFX
- qui : évalue les modèles sur de grandes quantités de données de manière distribuée sur les mêmes métriques définies dans la formation. Ces métriques sont comparées sur des tranches de données et visualisées dans des notebooks Jupyter ou Colab.
- contrairement à : certains outils d'introspection de modèle comme le tensorboard qui proposent l'introspection de modèle
TFMA effectue ses calculs de manière distribuée sur de grandes quantités de données à l'aide d'Apache Beam . Les sections suivantes décrivent comment configurer un pipeline d'évaluation TFMA de base. Voir l'architecture plus de détails sur l'implémentation sous-jacente.
Si vous souhaitez simplement vous lancer et commencer, consultez notre carnet Colab .
Cette page peut également être consultée sur tensorflow.org .
Types de modèles pris en charge
TFMA est conçu pour prendre en charge les modèles basés sur Tensorflow, mais peut également être facilement étendu pour prendre en charge d'autres frameworks. Historiquement, TFMA nécessitait la création d'un EvalSavedModel pour utiliser TFMA, mais la dernière version de TFMA prend en charge plusieurs types de modèles en fonction des besoins de l'utilisateur. La configuration d'un EvalSavedModel ne devrait être requise que si un modèle basé sur tf.estimator est utilisé et que des métriques de temps de formation personnalisées sont requises.
Notez que, étant donné que TFMA s'exécute désormais sur la base du modèle de diffusion, TFMA n'évaluera plus automatiquement les métriques ajoutées au moment de la formation. L'exception à ce cas est si un modèle keras est utilisé puisque keras enregistre les métriques utilisées avec le modèle enregistré. Cependant, s'il s'agit d'une exigence stricte, la dernière version de TFMA est rétrocompatible, de sorte qu'un EvalSavedModel peut toujours être exécuté dans un pipeline TFMA.
Le tableau suivant résume les modèles pris en charge par défaut :
| Type de modèle | Mesures du temps de formation | Mesures post-formation |
|---|---|---|
| TF2 (kéras) | O* | Oui |
| TF2 (générique) | N / A | Oui |
| EvalSavedModel (estimateur) | Oui | Oui |
| Aucun (pd.DataFrame, etc.) | N / A | Oui |
- Les métriques du temps de formation font référence aux métriques définies au moment de la formation et enregistrées avec le modèle (soit TFMA EvalSavedModel, soit modèle enregistré keras). Les métriques post-formation font référence aux métriques ajoutées via
tfma.MetricConfig. - Les modèles TF2 génériques sont des modèles personnalisés qui exportent des signatures pouvant être utilisées pour l'inférence et ne sont basés ni sur des keras ni sur un estimateur.
Consultez la FAQ pour plus d'informations sur la configuration et la configuration de ces différents types de modèles.
Installation
Avant d'exécuter une évaluation, une petite quantité de configuration est requise. Tout d'abord, un objet tfma.EvalConfig doit être défini pour fournir des spécifications pour le modèle, les métriques et les tranches à évaluer. Deuxièmement, un tfma.EvalSharedModel doit être créé qui pointe vers le ou les modèles réels à utiliser lors de l'évaluation. Une fois ceux-ci définis, l'évaluation est effectuée en appelant tfma.run_model_analysis avec un ensemble de données approprié. Pour plus de détails, consultez le guide de configuration .
Si vous exécutez dans un pipeline TFX, consultez le guide TFX pour savoir comment configurer TFMA pour qu'il s'exécute en tant que composant TFX Evaluator .
Exemples
Évaluation d'un modèle unique
Ce qui suit utilise tfma.run_model_analysis pour effectuer une évaluation sur un modèle de diffusion. Pour une explication des différents paramètres nécessaires, consultez le guide de configuration .
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
Pour une évaluation distribuée, construisez un pipeline Apache Beam à l'aide d'un exécuteur distribué. Dans le pipeline, utilisez tfma.ExtractEvaluateAndWriteResults pour l'évaluation et pour écrire les résultats. Les résultats peuvent être chargés pour visualisation à l'aide de tfma.load_eval_result .
Par exemple:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
Validation du modèle
Pour effectuer la validation du modèle par rapport à un candidat et à une référence, mettez à jour la configuration pour inclure un paramètre de seuil et transmettez deux modèles à tfma.run_model_analysis .
Par exemple:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
Visualisation
Les résultats de l'évaluation TFMA peuvent être visualisés dans un notebook Jupyter à l'aide des composants frontaux inclus dans TFMA. Par exemple:
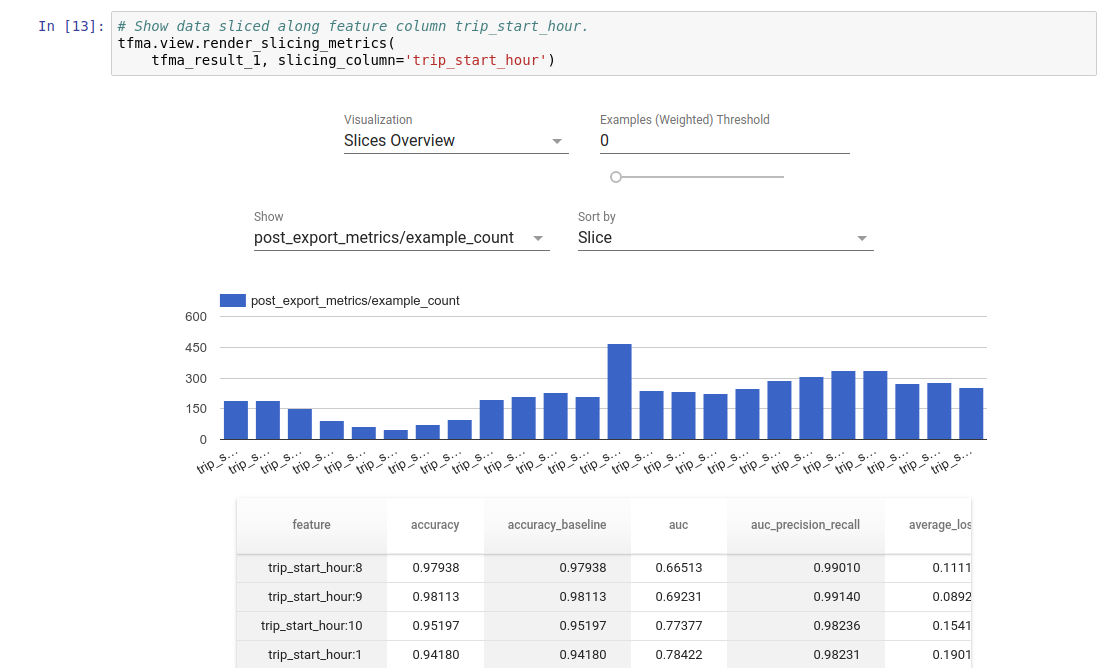 .
.