
Le prestazioni di TensorFlow Serving dipendono fortemente dall'applicazione che esegue, dall'ambiente in cui viene distribuito e da altri software con cui condivide l'accesso alle risorse hardware sottostanti. Pertanto, l'ottimizzazione delle prestazioni dipende in qualche modo dal caso e ci sono pochissime regole universali che garantiscono prestazioni ottimali in tutte le impostazioni. Detto questo, questo documento mira a catturare alcuni principi generali e best practice per l'esecuzione di TensorFlow Serving.
Utilizza la guida Richieste di inferenza del profilo con TensorBoard per comprendere il comportamento sottostante del calcolo del tuo modello sulle richieste di inferenza e utilizza questa guida per migliorare in modo iterativo le sue prestazioni.
Consigli veloci
- La latenza della prima richiesta è troppo alta? Abilita il riscaldamento del modello .
- Sei interessato a un maggiore utilizzo o throughput delle risorse? Configura il batching
Ottimizzazione delle prestazioni: obiettivi e parametri
Quando ottimizzi le prestazioni di TensorFlow Serving, di solito ci sono 2 tipi di obiettivi che potresti avere e 3 gruppi di parametri da modificare per migliorare tali obiettivi.
Obiettivi
TensorFlow Serving è un sistema di servizio online per modelli di machine learning. Come con molti altri sistemi di servizio online, il suo obiettivo prestazionale primario è massimizzare il throughput mantenendo la latenza della coda al di sotto di determinati limiti . A seconda dei dettagli e della maturità della tua applicazione, potresti interessarti di più alla latenza media che alla latenza della coda , ma alcune nozioni di latenza e throughput sono solitamente le metriche rispetto alle quali stabilisci gli obiettivi prestazionali. Tieni presente che in questa guida non discuteremo della disponibilità poiché è più una funzione dell'ambiente di distribuzione.
Parametri
Possiamo pensare approssimativamente a 3 gruppi di parametri la cui configurazione determina le prestazioni osservate: 1) il modello TensorFlow 2) le richieste di inferenza e 3) il server (hardware e binario).
1) Il modello TensorFlow
Il modello definisce il calcolo che TensorFlow Serving eseguirà alla ricezione di ciascuna richiesta in entrata.
Dietro le quinte, TensorFlow Serving utilizza il runtime TensorFlow per eseguire l'inferenza effettiva sulle tue richieste. Ciò significa che la latenza media nel servire una richiesta con TensorFlow Serving è solitamente almeno quella necessaria per eseguire l'inferenza direttamente con TensorFlow. Ciò significa che se su una determinata macchina, l'inferenza su un singolo esempio richiede 2 secondi e hai un obiettivo di latenza inferiore al secondo, devi profilare le richieste di inferenza, capire quali operazioni TensorFlow e sottografici del tuo modello contribuiscono maggiormente a tale latenza e riprogetta il tuo modello tenendo presente la latenza di inferenza come vincolo di progettazione.
Tieni presente che, sebbene la latenza media nell'esecuzione dell'inferenza con TensorFlow Serving non sia solitamente inferiore a quella dell'utilizzo diretto di TensorFlow, dove TensorFlow Serving brilla nel mantenere bassa la latenza di coda per molti client che eseguono query su molti modelli diversi, il tutto utilizzando in modo efficiente l'hardware sottostante per massimizzare il throughput .
2) Le richieste di inferenza
Superfici API
TensorFlow Serving ha due superfici API (HTTP e gRPC), entrambe le quali implementano l' API PredictionService (ad eccezione del server HTTP che non espone un endpoint MultiInference ). Entrambe le superfici API sono altamente ottimizzate e aggiungono una latenza minima, ma in pratica si osserva che la superficie gRPC è leggermente più performante.
Metodi API
In generale, si consiglia di utilizzare gli endpoint Classify e Regress poiché accettano tf.Example , che è un'astrazione di livello superiore; tuttavia, in rari casi di richieste strutturate di grandi dimensioni (O(Mb)), gli utenti esperti potrebbero trovare l'utilizzo di PredictRequest e la codifica diretta dei messaggi Protobuf in un TensorProto e il salto della serializzazione in e della deserializzazione da tf.Example una fonte di leggero miglioramento delle prestazioni.
Dimensione del lotto
Esistono due modi principali in cui l'invio in batch può migliorare le prestazioni. Puoi configurare i tuoi client per inviare richieste in batch a TensorFlow Serving oppure puoi inviare richieste individuali e configurare TensorFlow Serving per attendere fino a un periodo di tempo predeterminato ed eseguire l'inferenza su tutte le richieste che arrivano in quel periodo in un batch. La configurazione di quest'ultimo tipo di batch consente di raggiungere TensorFlow Serving a QPS estremamente elevati, consentendogli al tempo stesso di ridimensionare in modo sublineare le risorse di calcolo necessarie per tenere il passo. Questo è ulteriormente discusso nella guida alla configurazione e nel file README in batch .
3) Il Server (Hardware e Binario)
Il binario TensorFlow Serving tiene conto in modo abbastanza preciso dell'hardware su cui viene eseguito. Pertanto, dovresti evitare di eseguire altre applicazioni ad uso intensivo di calcolo o di memoria sullo stesso computer, in particolare quelle con utilizzo dinamico delle risorse.
Come con molti altri tipi di carichi di lavoro, TensorFlow Serving è più efficiente se distribuito su meno macchine più grandi (più CPU e RAM) (ovvero una Deployment con un numero inferiore replicas in termini Kubernetes). Ciò è dovuto a un migliore potenziale di implementazione multi-tenant per utilizzare l'hardware e ridurre i costi fissi (server RPC, runtime TensorFlow, ecc.).
Acceleratori
Se il tuo host ha accesso a un acceleratore, assicurati di aver implementato il tuo modello per inserire calcoli densi sull'acceleratore: questo dovrebbe essere fatto automaticamente se hai utilizzato API TensorFlow di alto livello, ma se hai creato grafici personalizzati o desideri bloccare parti specifiche di grafici su acceleratori specifici, potrebbe essere necessario posizionare manualmente alcuni sottografi sugli acceleratori (ad esempio utilizzando with tf.device('/device:GPU:0'): ... ).
CPU moderne
Le moderne CPU hanno continuamente esteso l'architettura del set di istruzioni x86 per migliorare il supporto per SIMD (Single Instruction Multiple Data) e altre funzionalità critiche per calcoli densi (ad esempio una moltiplicazione e un'addizione in un ciclo di clock). Tuttavia, per poter funzionare su macchine leggermente più vecchie, TensorFlow e TensorFlow Serving sono costruiti partendo dal modesto presupposto che le funzionalità più recenti non siano supportate dalla CPU host.
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Se vedi questa voce di registro (possibilmente estensioni diverse dalle 2 elencate) all'avvio di TensorFlow Serving, significa che puoi ricostruire TensorFlow Serving e scegliere come target la piattaforma del tuo host specifico e usufruire di prestazioni migliori. Creare TensorFlow Serving dal sorgente è relativamente semplice utilizzando Docker ed è documentato qui .
Configurazione binaria
TensorFlow Serving offre una serie di manopole di configurazione che ne regolano il comportamento in fase di esecuzione, per lo più impostate tramite flag della riga di comando . Alcuni di questi (in particolare tensorflow_intra_op_parallelism e tensorflow_inter_op_parallelism ) vengono passati per configurare il runtime di TensorFlow e sono autoconfigurati, cosa che gli utenti esperti possono ignorare facendo molti esperimenti e trovando la giusta configurazione per il loro carico di lavoro e ambiente specifici.
Durata di una richiesta di inferenza di servizio TensorFlow
Esaminiamo brevemente la vita di un esempio prototipo di richiesta di inferenza di servizio TensorFlow per vedere il percorso seguito da una richiesta tipica. Nel nostro esempio, analizzeremo una richiesta di previsione ricevuta dalla superficie dell'API gRPC TensorFlow Serving 2.0.0.
Esaminiamo innanzitutto un diagramma di sequenza a livello di componente, quindi passiamo al codice che implementa questa serie di interazioni.
Diagramma di sequenza
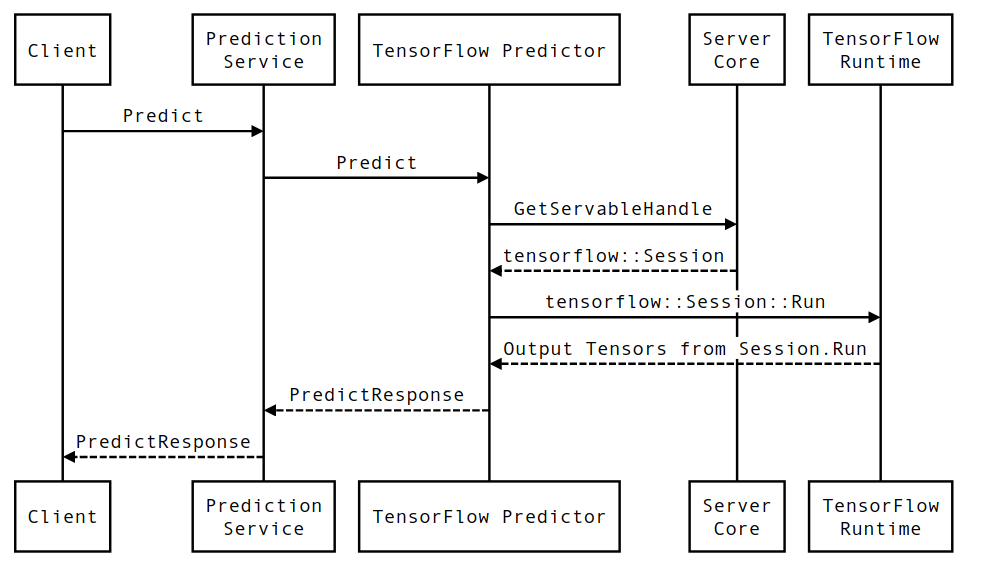
Tieni presente che Client è un componente di proprietà dell'utente, Prediction Service, Servables e Server Core sono di proprietà di TensorFlow Serving e TensorFlow Runtime è di proprietà di Core TensorFlow .
Dettagli della sequenza
-
PredictionServiceImpl::PredictricevePredictRequest - Invochiamo
TensorflowPredictor::Predict, propagando la scadenza della richiesta dalla richiesta gRPC (se ne è stata impostata una). - All'interno di
TensorflowPredictor::Predict, cerchiamo il Servable (modello) su cui la richiesta sta cercando di eseguire l'inferenza, da cui recuperiamo informazioni su SavedModel e, cosa più importante, un handle per l'oggettoSessionin cui il grafico del modello è (possibilmente parzialmente) caricato. Questo oggetto Servibile è stato creato e sottoposto a commit in memoria quando il modello è stato caricato da TensorFlow Serving. Invochiamo quindi internal::RunPredict per eseguire la previsione. - In
internal::RunPredict, dopo aver convalidato e preelaborato la richiesta, utilizziamo l'oggettoSessionper eseguire l'inferenza utilizzando una chiamata di blocco a Session::Run , a quel punto entriamo nella base di codice core di TensorFlow. Dopo cheSession::Runritorna e i nostri tensorioutputssono stati popolati, convertiamo gli output inPredictionResponsee restituiamo il risultato nello stack di chiamate.