
Panoramica
Panoramica
Questo tutorial è progettato per aiutarti a imparare a creare le tue pipeline di machine learning utilizzando TensorFlow Extended (TFX) e Apache Airflow come orchestratore. Funziona su Vertex AI Workbench e mostra l'integrazione con TFX e TensorBoard, nonché l'interazione con TFX in un ambiente Jupyter Lab.
Cosa farai?
Imparerai come creare una pipeline ML utilizzando TFX
- Una pipeline TFX è un grafico aciclico diretto, o "DAG". Faremo spesso riferimento alle pipeline come DAG.
- Le pipeline TFX sono appropriate quando si distribuirà un'applicazione ML di produzione
- Le pipeline TFX sono appropriate quando i set di dati sono grandi o possono diventare grandi
- Le pipeline TFX sono appropriate quando la coerenza tra formazione e servizio è importante
- Le pipeline TFX sono appropriate quando la gestione delle versioni per l'inferenza è importante
- Google utilizza le pipeline TFX per il machine learning di produzione
Consulta la Guida per l'utente di TFX per saperne di più.
Seguirai un tipico processo di sviluppo ML:
- Acquisizione, comprensione e pulizia dei nostri dati
- Ingegneria delle funzionalità
- Formazione
- Analisi delle prestazioni del modello
- Schiuma, risciacqua, ripeti
- Pronto per la produzione
Apache Airflow per l'orchestrazione della pipeline
Gli orchestratori TFX sono responsabili della pianificazione dei componenti della pipeline TFX in base alle dipendenze definite dalla pipeline. TFX è progettato per essere portabile in più ambienti e framework di orchestrazione. Uno degli orchestratori predefiniti supportati da TFX è Apache Airflow . Questo laboratorio illustra l'uso di Apache Airflow per l'orchestrazione della pipeline TFX. Apache Airflow è una piattaforma per creare, pianificare e monitorare i flussi di lavoro in modo programmatico. TFX utilizza Airflow per creare flussi di lavoro come grafici aciclici diretti (DAG) di attività. La ricca interfaccia utente semplifica la visualizzazione delle pipeline in esecuzione in produzione, il monitoraggio dei progressi e la risoluzione dei problemi quando necessario. I flussi di lavoro Apache Airflow sono definiti come codice. Ciò li rende più gestibili, modificabili, testabili e collaborativi. Apache Airflow è adatto per pipeline di elaborazione batch. È leggero e facile da imparare.
In questo esempio, eseguiremo una pipeline TFX su un'istanza configurando manualmente Airflow.
Gli altri orchestratori predefiniti supportati da TFX sono Apache Beam e Kubeflow. Apache Beam può essere eseguito su più backend di elaborazione dati (Beam Ruunners). Cloud Dataflow è uno di questi beam runner che può essere utilizzato per eseguire pipeline TFX. Apache Beam può essere utilizzato sia per pipeline di streaming che per pipeline di elaborazione batch.
Kubeflow è una piattaforma ML open source dedicata a rendere le distribuzioni di flussi di lavoro di machine learning (ML) su Kubernetes semplici, portatili e scalabili. Kubeflow può essere utilizzato come orchestratore per le pipeline TFFX quando devono essere distribuite sui cluster Kubernetes. Inoltre, puoi anche utilizzare il tuo orchestratore personalizzato per eseguire una pipeline TFX.
Maggiori informazioni sul flusso d'aria qui .
Set di dati sui taxi di Chicago


Utilizzerai il set di dati Taxi Trips rilasciato dalla città di Chicago.
Obiettivo del modello: classificazione binaria
Il cliente darà una mancia più o meno del 20%?
Configura il progetto Google Cloud
Prima di fare clic sul pulsante Avvia laboratorio, leggere queste istruzioni. I laboratori sono a tempo e non puoi metterli in pausa. Il timer, che si avvia quando fai clic su Avvia lab , mostra per quanto tempo le risorse Google Cloud saranno rese disponibili.
Questo laboratorio pratico ti consente di svolgere tu stesso le attività di laboratorio in un ambiente cloud reale, non in un ambiente simulato o dimostrativo. A tale scopo, ti vengono fornite nuove credenziali temporanee che utilizzi per accedere a Google Cloud per la durata del lab.
Cosa ti serve Per completare questo lab, ti serve:
- Accesso a un browser Internet standard (si consiglia il browser Chrome).
- È ora di completare il laboratorio.
Come avviare il lab e accedere a Google Cloud Console 1. Fai clic sul pulsante Avvia lab . Se devi pagare per il laboratorio, si aprirà un pop-up in cui potrai selezionare il metodo di pagamento. Sulla sinistra è presente un pannello popolato con le credenziali temporanee che devi utilizzare per questo lab.
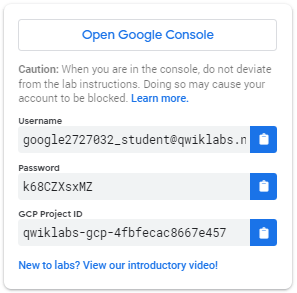
- Copia il nome utente, quindi fai clic su Apri Google Console . Il lab avvia le risorse e quindi apre un'altra scheda che mostra la pagina di accesso .
Suggerimento: apri le schede in finestre separate, affiancate.
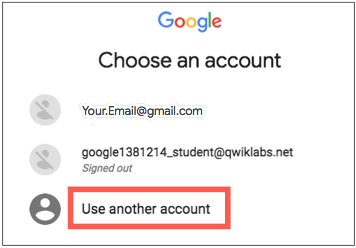
- Nella pagina di accesso , incolla il nome utente che hai copiato dal pannello di sinistra. Quindi copia e incolla la password.
- Scorrere le pagine successive:
- Accetta i termini e le condizioni.
Non aggiungere opzioni di ripristino o autenticazione a due fattori (perché si tratta di un account temporaneo).
Non iscriverti alle prove gratuite.
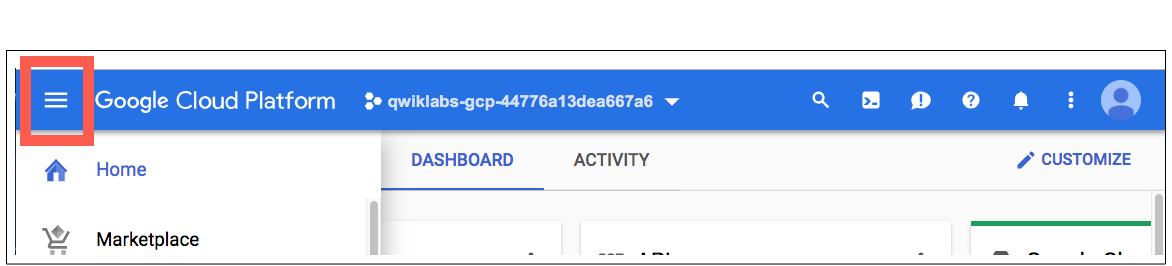
Dopo alcuni istanti, Cloud Console si apre in questa scheda.
Attiva Cloud Shell
Cloud Shell è una macchina virtuale ricca di strumenti di sviluppo. Offre una home directory persistente da 5 GB e funziona su Google Cloud. Cloud Shell fornisce l'accesso dalla riga di comando alle tue risorse Google Cloud.
In Cloud Console, nella barra degli strumenti in alto a destra, fai clic sul pulsante Attiva Cloud Shell .
Fare clic su Continua .
Sono necessari alcuni istanti per effettuare il provisioning e connettersi all'ambiente. Quando sei connesso, sei già autenticato e il progetto è impostato sul tuo _PROJECT ID . Per esempio:

gcloud è lo strumento da riga di comando per Google Cloud. Viene preinstallato su Cloud Shell e supporta il completamento con schede.
Puoi elencare il nome dell'account attivo con questo comando:
gcloud auth list
(Produzione)
ATTIVO: * ACCOUNT: student-01-xxxxxxxxxxxx@qwiklabs.net Per impostare l'account attivo, eseguire: $ gcloud config set account
ACCOUNT
Puoi elencare l'ID progetto con questo comando: gcloud config list project (Output)
progetto [principale] =
(Esempio di output)
progetto [principale] = qwiklabs-gcp-44776a13dea667a6
Per la documentazione completa di gcloud, consulta la panoramica dello strumento da riga di comando gcloud .
Abilita i servizi Google Cloud
- In Cloud Shell, utilizza gcloud per abilitare i servizi utilizzati nel lab.
gcloud services enable notebooks.googleapis.com
Distribuisci l'istanza Vertex Notebook
- Fare clic sul menu di navigazione e accedere a Vertex AI , quindi a Workbench .
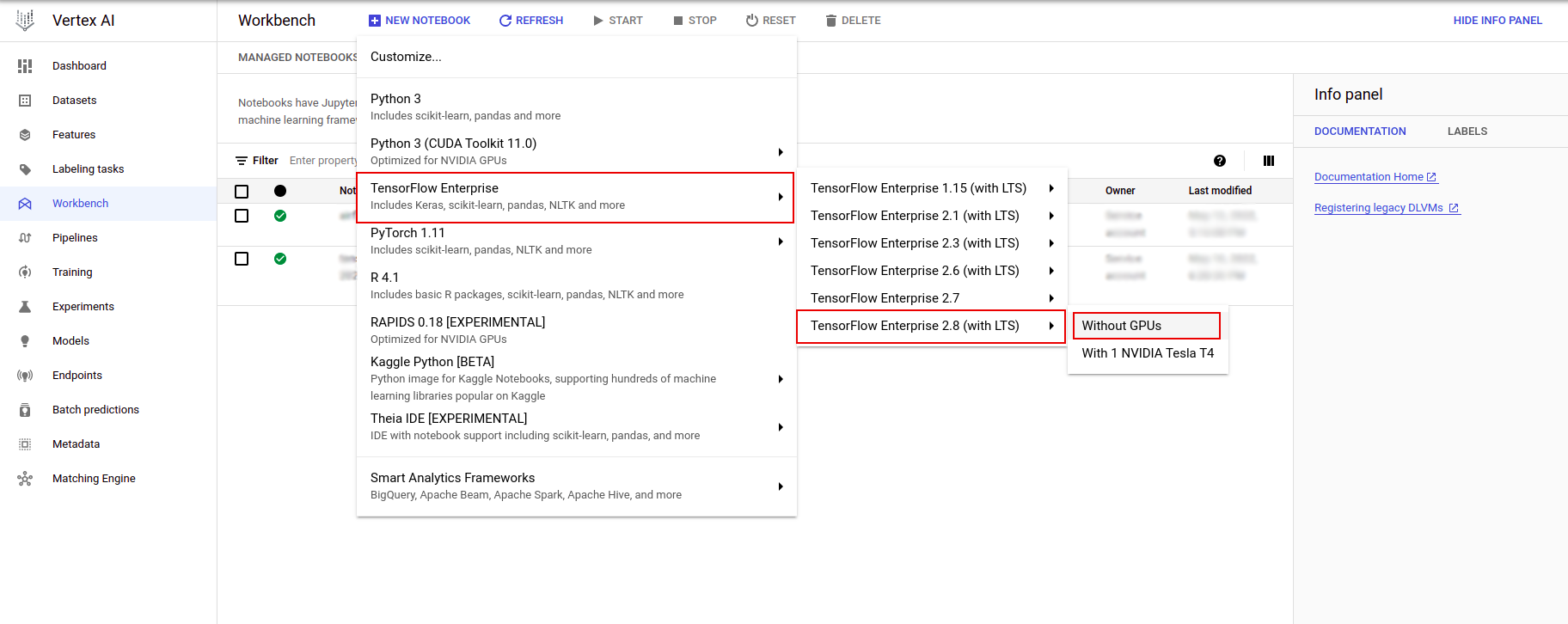
Nella pagina Istanze notebook, fare clic su Nuovo notebook .
Nel menu Personalizza istanza, seleziona TensorFlow Enterprise e scegli la versione di TensorFlow Enterprise 2.x (con LTS) > Senza GPU .
Nella finestra di dialogo Nuova istanza notebook , fare clic sull'icona della matita per modificare le proprietà dell'istanza.
Per Nome istanza , inserisci un nome per la tua istanza.
Per Regione , seleziona
us-east1e per Zona , seleziona una zona all'interno della regione selezionata.Scorri verso il basso fino a Configurazione macchina e seleziona e2-standard-2 per Tipo macchina.
Lascia i campi rimanenti con i valori predefiniti e fai clic su Crea .
Dopo alcuni minuti, la console Vertex AI visualizzerà il nome dell'istanza, seguito da Open Jupyterlab .
- Fare clic su Apri JupyterLab . Una finestra JupyterLab si aprirà in una nuova scheda.
Imposta l'ambiente
Clona il repository del laboratorio
Successivamente clonerai il repository tfx nella tua istanza JupyterLab. 1. In JupyterLab, fare clic sull'icona Terminale per aprire un nuovo terminale.
Cancel per Compilazione consigliata.
- Per clonare il repository Github
tfx, digita il seguente comando e premi Invio .
git clone https://github.com/tensorflow/tfx.git
- Per confermare di aver clonato il repository, fai doppio clic sulla directory
tfxe conferma che puoi vederne il contenuto.
Installare le dipendenze del laboratorio
- Eseguire quanto segue per accedere alla cartella
tfx/tfx/examples/airflow_workshop/taxi/setup/, quindi eseguire./setup_demo.shper installare le dipendenze del laboratorio:
cd ~/tfx/tfx/examples/airflow_workshop/taxi/setup/
./setup_demo.sh
Il codice sopra lo farà
- Installa i pacchetti richiesti.
- Crea una cartella
airflownella cartella Home. - Copia la cartella
dagsdalla cartellatfx/tfx/examples/airflow_workshop/taxi/setup/alla cartella~/airflow/. - Copia il file CSV da
tfx/tfx/examples/airflow_workshop/taxi/setup/dataa~/airflow/data.
Configurazione del server Airflow
Crea una regola firewall per accedere al server Airflow nel browser
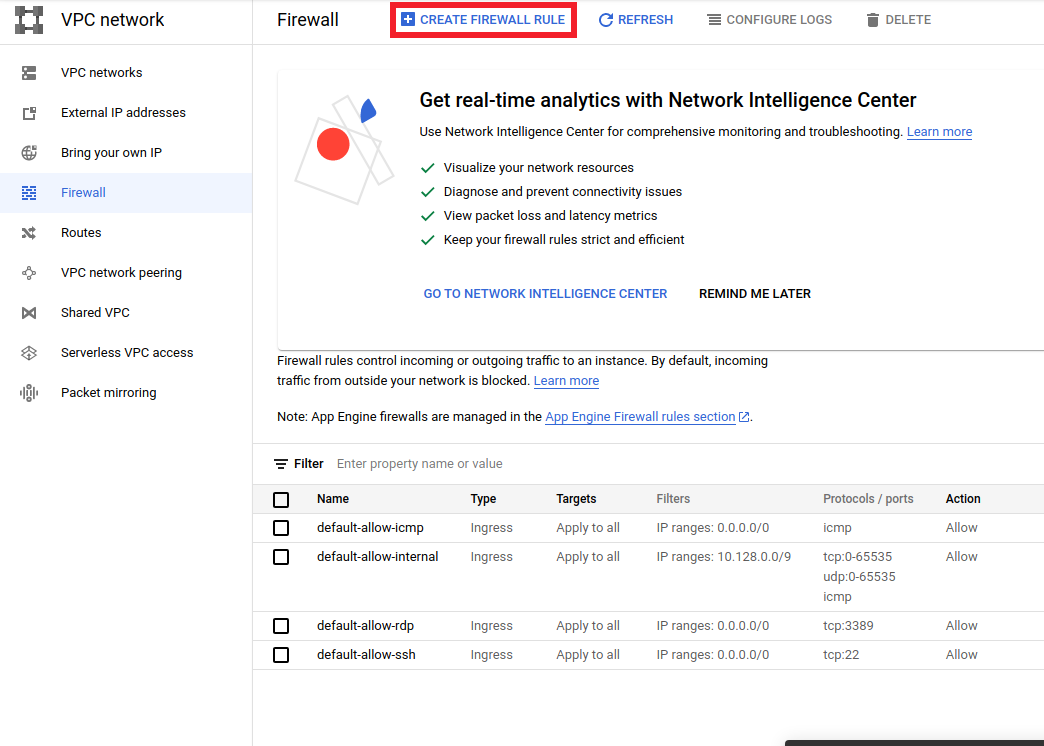
- Vai a
<a href="https://console.cloud.google.com/networking/firewalls/list">https://console.cloud.google.com/networking/firewalls/list</a>e assicurati il nome del progetto è selezionato in modo appropriato - Fare clic sull'opzione
CREATE FIREWALL RULEin alto
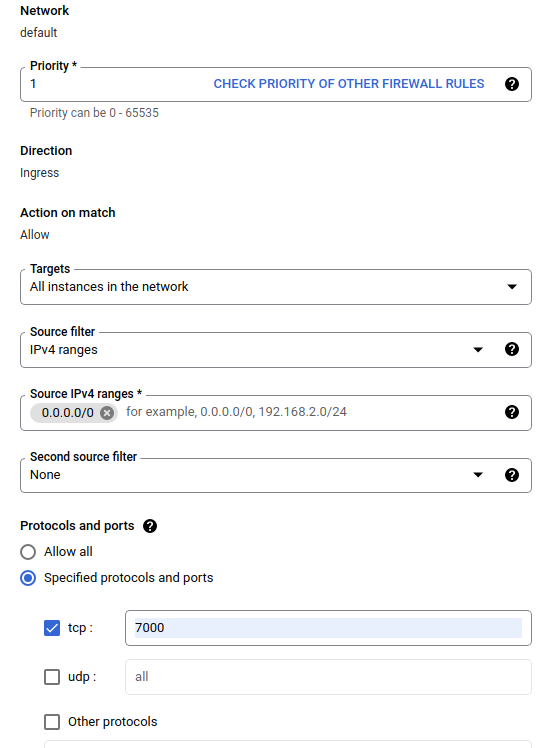
Nella finestra di dialogo Crea un firewall , seguire i passaggi elencati di seguito.
- Per Name , inserisci
airflow-tfx. - Per Priorità , selezionare
1. - Per Destinazioni , seleziona
All instances in the network. - Per Intervalli IPv4 di origine , selezionare
0.0.0.0/0 - Per Protocolli e porte , fare clic su
tcpe inserire7000nella casella accanto atcp - Fare clic su
Create.
Esegui il server Airflow dalla tua shell
Nella finestra del Terminale di Jupyter Lab, passa alla directory home, esegui il comando airflow users create per creare un utente amministratore per Airflow:
cd
airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin
Quindi eseguire il comando airflow webserver e airflow scheduler per eseguire il server. Scegli la porta 7000 poiché è consentita tramite il firewall.
nohup airflow webserver -p 7000 &> webserver.out &
nohup airflow scheduler &> scheduler.out &
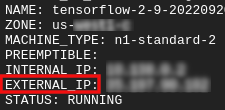
Ottieni il tuo IP esterno
- In Cloud Shell, utilizza
gcloudper ottenere l'IP esterno.
gcloud compute instances list
Esecuzione di un DAG/pipeline
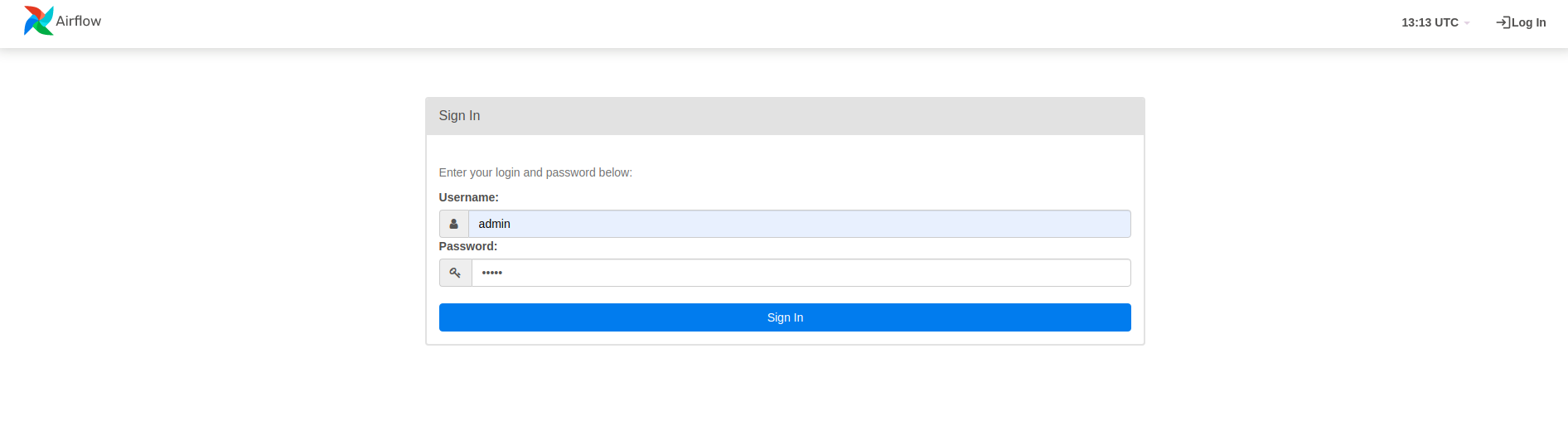
In un browser
Apri un browser e vai su http://
- Nella pagina di accesso, inserisci il nome utente (
admin) e la password (admin) che hai scelto durante l'esecuzione del comandoairflow users create.
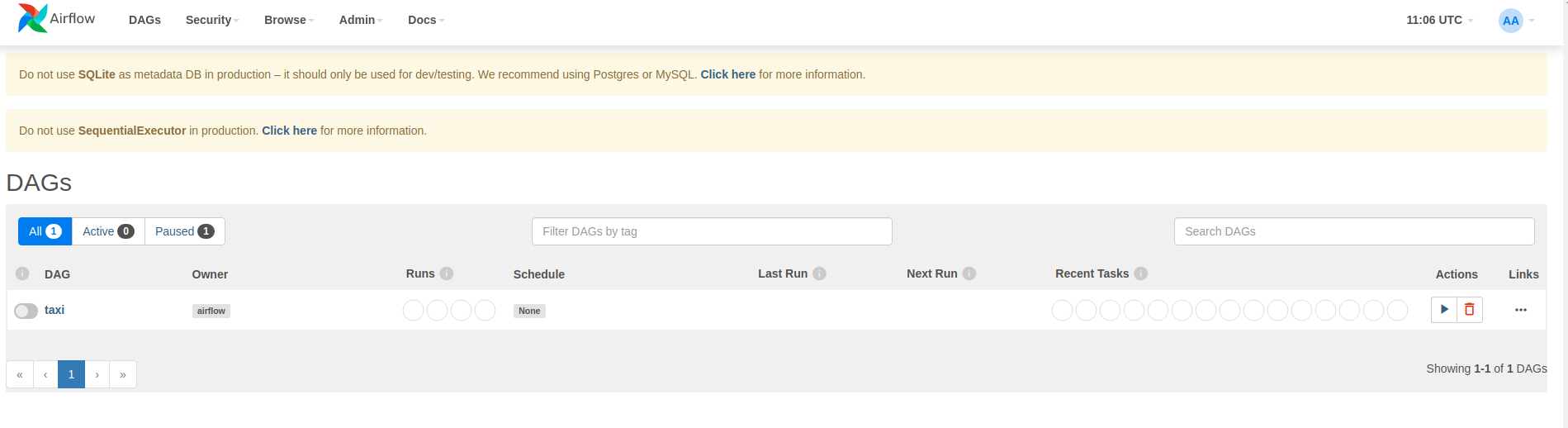
Airflow carica i DAG dai file sorgente Python. Prende ogni file e lo esegue. Quindi carica tutti gli oggetti DAG da quel file. Tutti i file .py che definiscono gli oggetti DAG verranno elencati come pipeline nella home page del flusso d'aria.
In questo tutorial, Airflow esegue la scansione della cartella ~/airflow/dags/ alla ricerca di oggetti DAG.
Se apri ~/airflow/dags/taxi_pipeline.py e scorri fino in fondo, puoi vedere che crea e memorizza un oggetto DAG in una variabile denominata DAG . Pertanto verrà elencato come pipeline nella home page del flusso d'aria come mostrato di seguito:
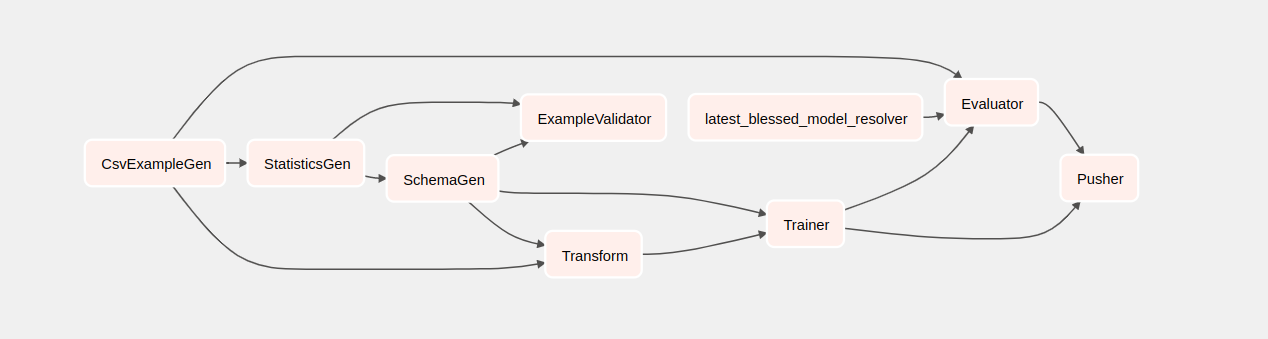
Se fai clic su taxi, verrai reindirizzato alla visualizzazione a griglia del DAG. È possibile fare clic sull'opzione Graph in alto per ottenere la visualizzazione grafica del DAG.
Attiva la pipeline dei taxi
Nella homepage sono visibili i pulsanti che possono essere utilizzati per interagire con il DAG.
Sotto l'intestazione delle azioni , fare clic sul pulsante di attivazione per attivare la pipeline.
Nella pagina Taxi DAG , utilizzare il pulsante a destra per aggiornare lo stato della vista grafico del DAG durante l'esecuzione della pipeline. Inoltre, puoi abilitare l'aggiornamento automatico per istruire Airflow ad aggiornare automaticamente la visualizzazione del grafico man mano che lo stato cambia.
Puoi anche utilizzare la CLI Airflow nel terminale per abilitare e attivare i tuoi DAG:
# enable/disable
airflow pause <your DAG name>
airflow unpause <your DAG name>
# trigger
airflow trigger_dag <your DAG name>
In attesa del completamento della pipeline
Dopo aver attivato la pipeline, nella visualizzazione DAG è possibile osservare l'avanzamento della pipeline mentre è in esecuzione. Durante l'esecuzione di ciascun componente, il colore del contorno del componente nel grafico DAG cambierà per mostrarne lo stato. Quando un componente ha terminato l'elaborazione, il contorno diventerà verde scuro per indicare che l'operazione è terminata.
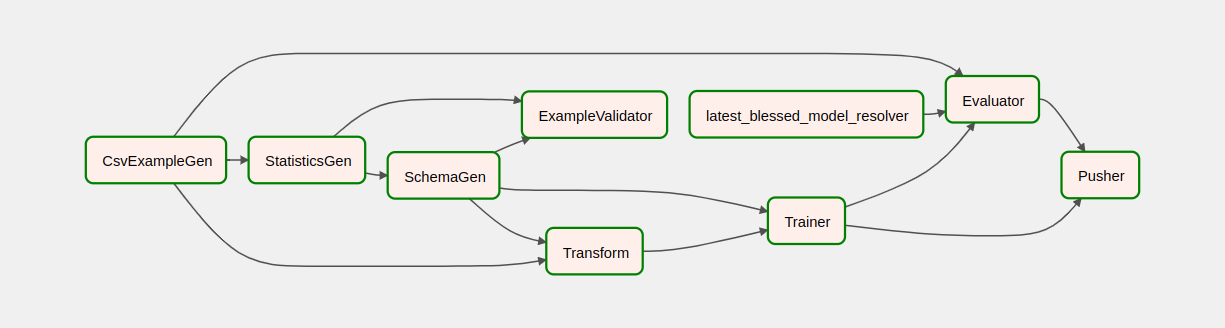
Comprendere i componenti
Ora esamineremo i componenti di questa pipeline in dettaglio e esamineremo individualmente gli output prodotti da ciascuna fase della pipeline.
In JupyterLab vai su
~/tfx/tfx/examples/airflow_workshop/taxi/notebooks/Apri notebook.ipynb.

Continuare l'attività di laboratorio nel blocco appunti ed eseguire ogni cella facendo clic sul pulsante Esegui (
 ) nella parte superiore dello schermo. In alternativa, puoi eseguire il codice in una cella con SHIFT + ENTER .
) nella parte superiore dello schermo. In alternativa, puoi eseguire il codice in una cella con SHIFT + ENTER .
Leggi la narrazione e assicurati di capire cosa sta succedendo in ogni cella.