
ভূমিকা
এই টিউটোরিয়ালটি TensorFlow Extended (TFX) এবং AIPlatform পাইপলাইনগুলিকে পরিচয় করিয়ে দেওয়ার জন্য ডিজাইন করা হয়েছে, এবং আপনাকে Google ক্লাউডে আপনার নিজস্ব মেশিন লার্নিং পাইপলাইন তৈরি করতে শিখতে সাহায্য করবে৷ এটি TFX, AI প্ল্যাটফর্ম পাইপলাইন এবং Kubeflow এর সাথে একীকরণ দেখায়, সেইসাথে Jupyter নোটবুকগুলিতে TFX এর সাথে মিথস্ক্রিয়া দেখায়।
এই টিউটোরিয়ালের শেষে, আপনি Google ক্লাউডে হোস্ট করা একটি ML পাইপলাইন তৈরি এবং চালাবেন। আপনি প্রতিটি রানের ফলাফল কল্পনা করতে সক্ষম হবেন, এবং তৈরি করা শিল্পকর্মের বংশ দেখতে পাবেন।
আপনি একটি সাধারণ ML বিকাশ প্রক্রিয়া অনুসরণ করবেন, ডেটাসেট পরীক্ষা করে শুরু করে এবং একটি সম্পূর্ণ কার্যকরী পাইপলাইন দিয়ে শেষ হবে। পথ ধরে আপনি আপনার পাইপলাইন ডিবাগ এবং আপডেট করার উপায়গুলি অন্বেষণ করবেন এবং কর্মক্ষমতা পরিমাপ করবেন৷
শিকাগো ট্যাক্সি ডেটাসেট


আপনি শিকাগো সিটি দ্বারা প্রকাশিত ট্যাক্সি ট্রিপ ডেটাসেট ব্যবহার করছেন৷
আপনি Google BigQuery- এ ডেটাসেট সম্পর্কে আরও পড়তে পারেন। BigQuery UI- তে সম্পূর্ণ ডেটাসেট অন্বেষণ করুন।
মডেল লক্ষ্য - বাইনারি শ্রেণীবিভাগ
গ্রাহক কি 20% এর বেশি বা কম টিপ দেবেন?
1. একটি Google ক্লাউড প্রকল্প সেট আপ করুন৷
1.a Google ক্লাউডে আপনার পরিবেশ সেট আপ করুন৷
শুরু করতে, আপনার একটি Google ক্লাউড অ্যাকাউন্ট প্রয়োজন৷ আপনার যদি ইতিমধ্যে একটি থাকে, তাহলে নতুন প্রকল্প তৈরি করুন এ যান।
গুগল ক্লাউড কনসোলে যান।
Google ক্লাউডের শর্তাবলীতে সম্মত হন
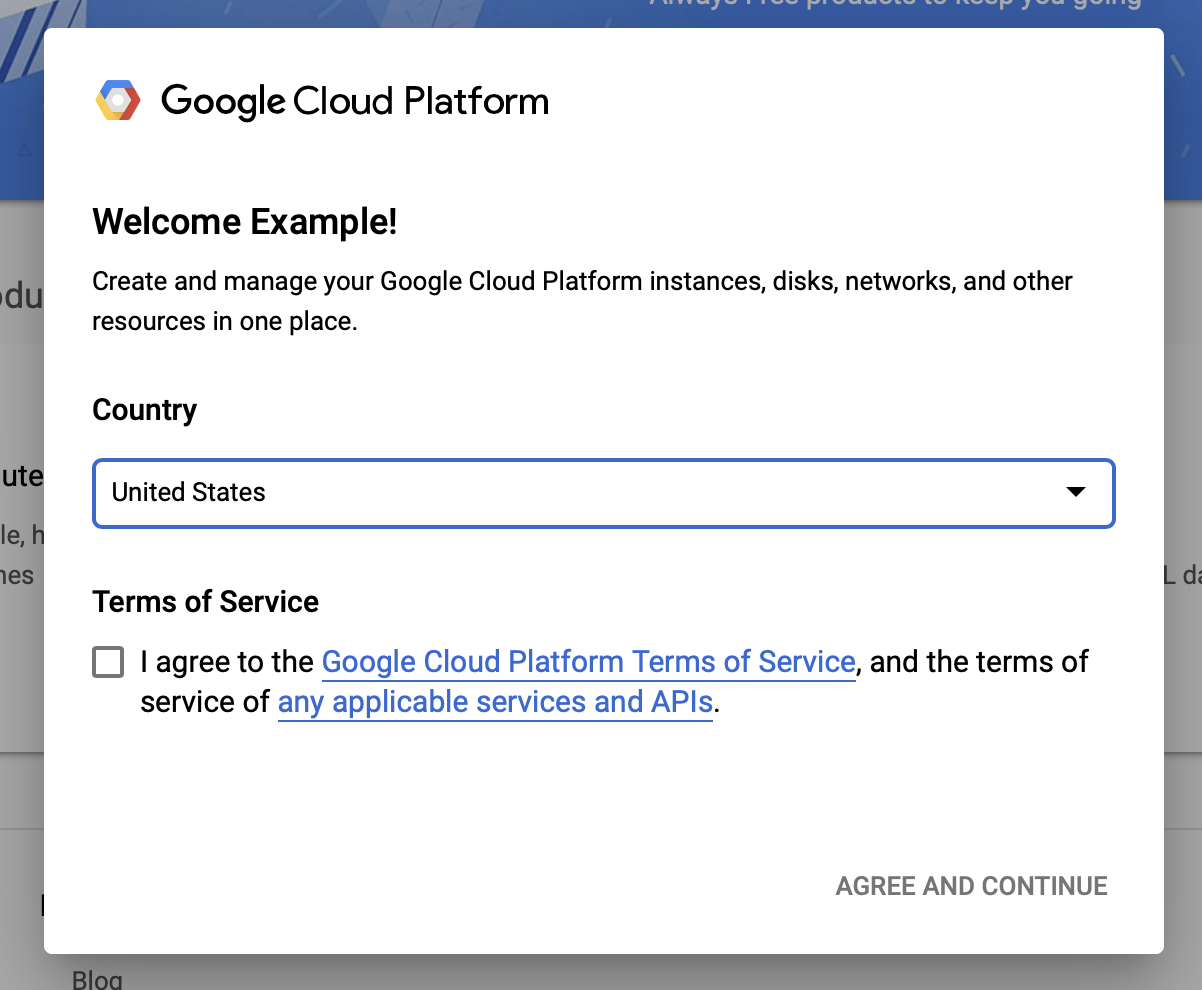
আপনি যদি একটি বিনামূল্যের ট্রায়াল অ্যাকাউন্ট দিয়ে শুরু করতে চান, তাহলে বিনামূল্যের জন্য চেষ্টা করুন (বা বিনামূল্যে শুরু করুন ) এ ক্লিক করুন।
তোমার দেশ নির্বাচন কর.
পরিষেবার শর্তাবলীতে সম্মত হন।
বিলিং বিবরণ লিখুন.
এই সময়ে আপনাকে চার্জ করা হবে না। আপনার যদি অন্য কোনো Google ক্লাউড প্রজেক্ট না থাকে, তাহলে আপনি Google ক্লাউড ফ্রি টিয়ার সীমা অতিক্রম না করে এই টিউটোরিয়ালটি সম্পূর্ণ করতে পারেন, যার মধ্যে একই সময়ে সর্বাধিক 8টি কোর চলছে৷
1.b একটি নতুন প্রকল্প তৈরি করুন।
- প্রধান Google ক্লাউড ড্যাশবোর্ড থেকে, Google ক্লাউড প্ল্যাটফর্ম শিরোনামের পাশে প্রজেক্ট ড্রপডাউনে ক্লিক করুন এবং নতুন প্রকল্প নির্বাচন করুন।
- আপনার প্রকল্পের একটি নাম দিন এবং অন্যান্য প্রকল্পের বিবরণ লিখুন
- একবার আপনি একটি প্রকল্প তৈরি করার পরে, প্রকল্প ড্রপ-ডাউন থেকে এটি নির্বাচন করতে ভুলবেন না।
2. একটি নতুন Kubernetes ক্লাস্টারে একটি AI প্ল্যাটফর্ম পাইপলাইন সেট আপ এবং স্থাপন করুন
এআই প্ল্যাটফর্ম পাইপলাইন ক্লাস্টার পৃষ্ঠায় যান।
প্রধান নেভিগেশন মেনুর অধীনে: ≡ > AI প্ল্যাটফর্ম > পাইপলাইন
একটি নতুন ক্লাস্টার তৈরি করতে + নতুন উদাহরণ ক্লিক করুন।
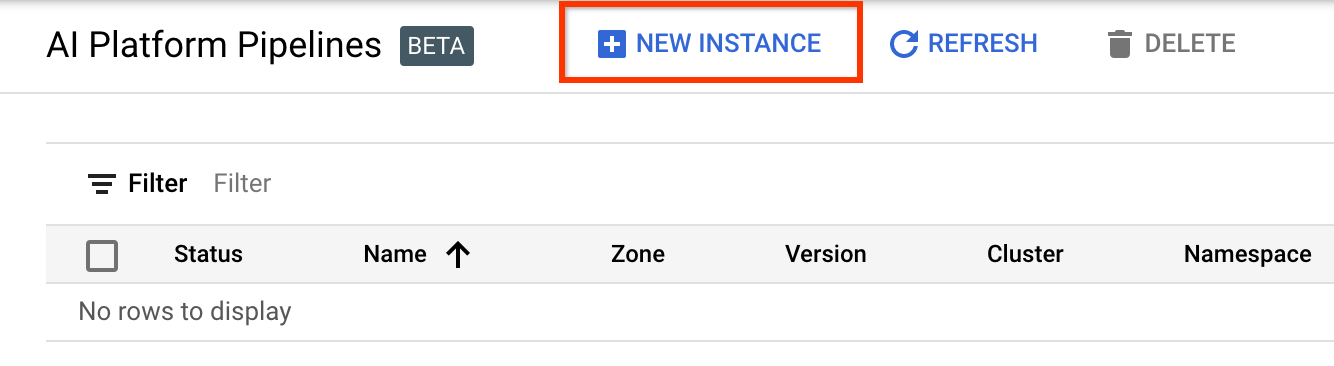
Kubeflow Pipelines ওভারভিউ পৃষ্ঠায়, Configure এ ক্লিক করুন।

Kubernetes Engine API সক্ষম করতে "সক্ষম করুন" এ ক্লিক করুন
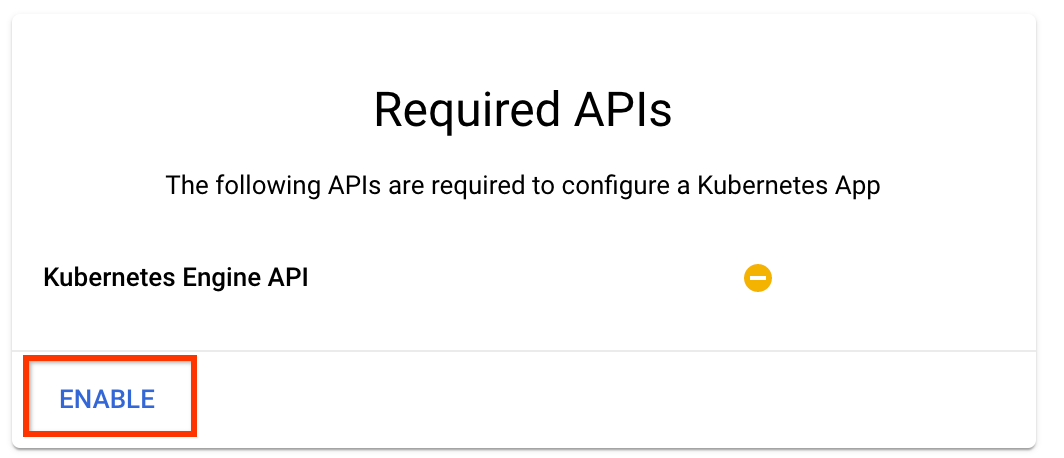
Kubeflow পাইপলাইন স্থাপন পৃষ্ঠায়:
আপনার ক্লাস্টারের জন্য একটি অঞ্চল (বা "অঞ্চল") নির্বাচন করুন। নেটওয়ার্ক এবং সাবনেটওয়ার্ক সেট করা যেতে পারে, তবে এই টিউটোরিয়ালের উদ্দেশ্যে আমরা সেগুলিকে ডিফল্ট হিসাবে রেখে দেব।
গুরুত্বপূর্ণ নিম্নলিখিত ক্লাউড APIগুলিতে অ্যাক্সেসের অনুমতি দিন লেবেলযুক্ত বাক্সটি চেক করুন৷ (আপনার প্রকল্পের অন্যান্য অংশগুলি অ্যাক্সেস করার জন্য এই ক্লাস্টারের জন্য এটি প্রয়োজনীয়। আপনি যদি এই পদক্ষেপটি মিস করেন, তাহলে এটিকে পরে ঠিক করা কিছুটা কঠিন।)
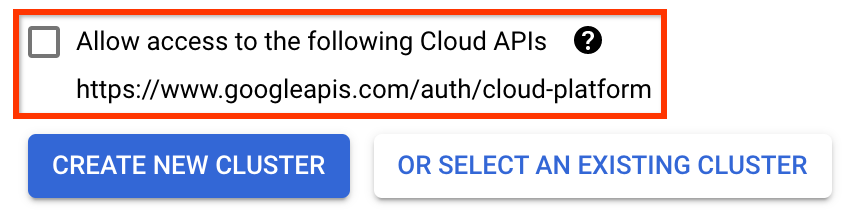
নতুন ক্লাস্টার তৈরি করুন ক্লিক করুন, এবং ক্লাস্টার তৈরি না হওয়া পর্যন্ত কয়েক মিনিট অপেক্ষা করুন। এতে কয়েক মিনিট সময় লাগবে। এটি সম্পূর্ণ হলে আপনি একটি বার্তা দেখতে পাবেন যেমন:
ক্লাস্টার "ক্লাস্টার-1" সফলভাবে "us-central1-a" জোনে তৈরি করা হয়েছে।
একটি নামস্থান এবং উদাহরণের নাম নির্বাচন করুন (ডিফল্টগুলি ব্যবহার করা ভাল)। এই টিউটোরিয়ালের উদ্দেশ্যে executor.emissary বা managedstorage.enabled চেক করবেন না।
Deploy এ ক্লিক করুন, এবং পাইপলাইন স্থাপন না হওয়া পর্যন্ত বেশ কিছু মুহূর্ত অপেক্ষা করুন। Kubeflow পাইপলাইন স্থাপন করে, আপনি পরিষেবার শর্তাবলী স্বীকার করেন।
3. ক্লাউড এআই প্ল্যাটফর্ম নোটবুক উদাহরণ সেট আপ করুন৷
Vertex AI Workbench পৃষ্ঠায় যান। প্রথমবার যখন আপনি ওয়ার্কবেঞ্চ চালাবেন তখন আপনাকে নোটবুক এপিআই সক্ষম করতে হবে।
প্রধান নেভিগেশন মেনুর অধীনে: ≡ -> Vertex AI -> Workbench
অনুরোধ করা হলে, Compute Engine API সক্ষম করুন।
টেনসরফ্লো এন্টারপ্রাইজ 2.7 (বা উপরে) ইনস্টল করে একটি নতুন নোটবুক তৈরি করুন।
নতুন নোটবুক -> টেনসরফ্লো এন্টারপ্রাইজ 2.7 -> জিপিইউ ছাড়া
একটি অঞ্চল এবং অঞ্চল নির্বাচন করুন এবং নোটবুকের উদাহরণটিকে একটি নাম দিন।
ফ্রি টিয়ার সীমার মধ্যে থাকার জন্য, এই উদাহরণে উপলব্ধ vCPU-এর সংখ্যা 4 থেকে 2 এ কমাতে আপনাকে এখানে ডিফল্ট সেটিংস পরিবর্তন করতে হতে পারে:
- নতুন নোটবুক ফর্মের নীচে উন্নত বিকল্পগুলি নির্বাচন করুন৷
মেশিন কনফিগারেশনের অধীনে আপনি 1 বা 2টি ভিসিপিইউ সহ একটি কনফিগারেশন নির্বাচন করতে চাইতে পারেন যদি আপনার বিনামূল্যে স্তরে থাকার প্রয়োজন হয়।
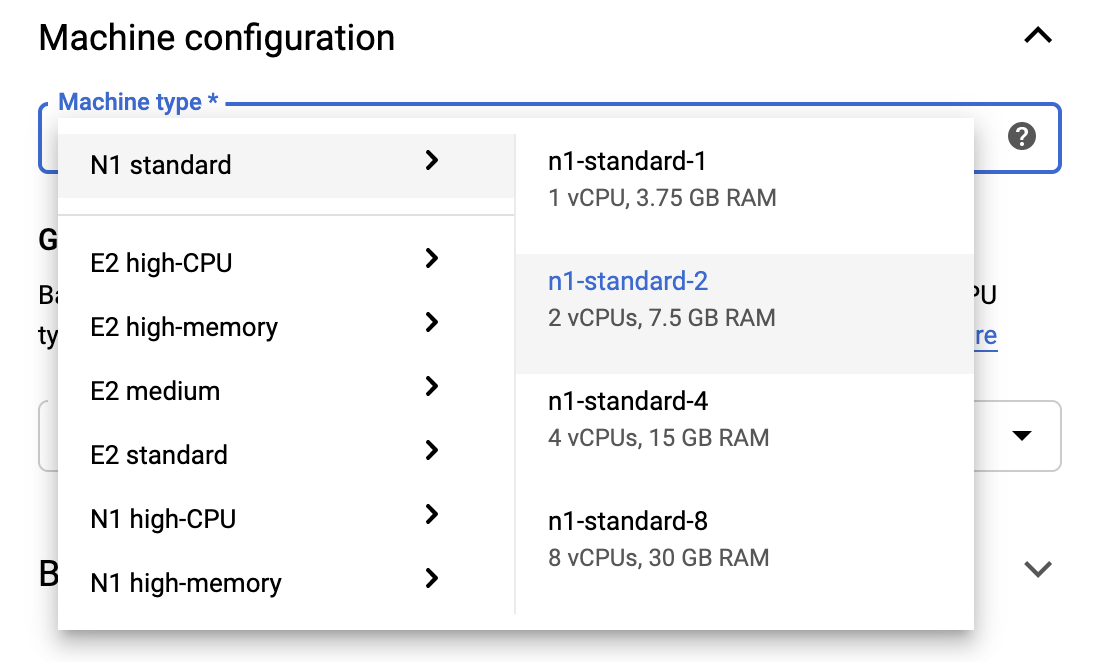
নতুন নোটবুক তৈরি হওয়ার জন্য অপেক্ষা করুন, এবং তারপরে নোটবুক API সক্ষম করুন ক্লিক করুন
4. শুরু করার নোটবুকটি চালু করুন৷
এআই প্ল্যাটফর্ম পাইপলাইন ক্লাস্টার পৃষ্ঠায় যান।
প্রধান নেভিগেশন মেনুর অধীনে: ≡ -> AI প্ল্যাটফর্ম -> পাইপলাইন
এই টিউটোরিয়ালে আপনি যে ক্লাস্টার ব্যবহার করছেন তার লাইনে, Open Pipelines Dashboard এ ক্লিক করুন।

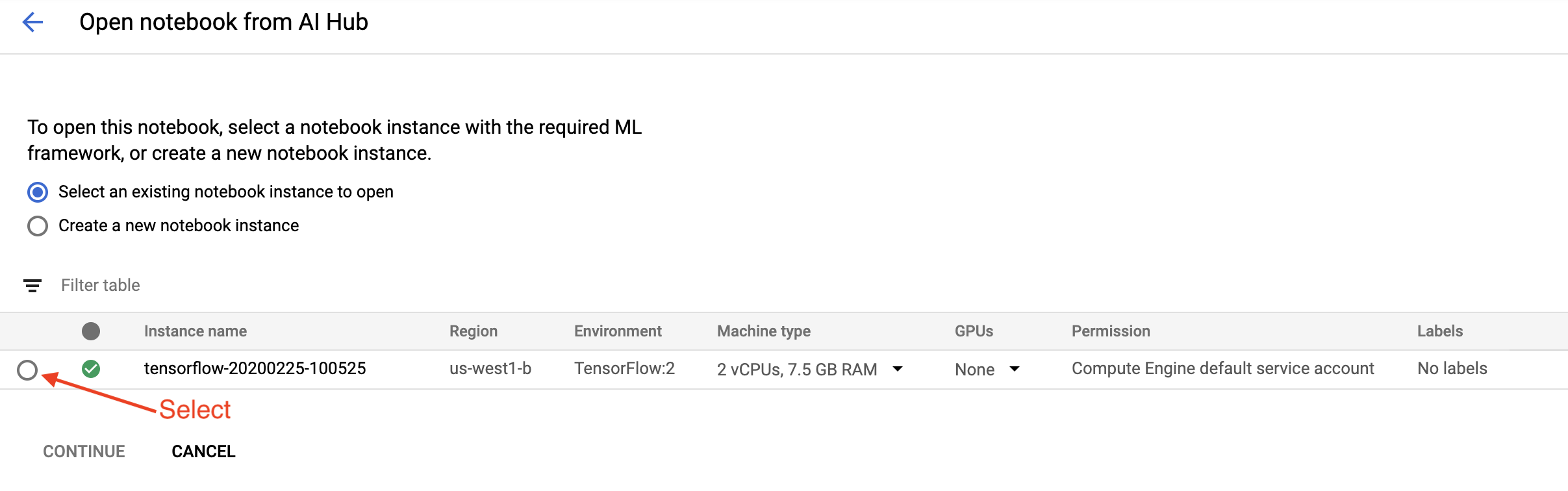
শুরু করা পৃষ্ঠায়, Google ক্লাউডে একটি ক্লাউড এআই প্ল্যাটফর্ম নোটবুক খুলুন ক্লিক করুন।

এই টিউটোরিয়ালের জন্য আপনি যে নোটবুক ইন্সট্যান্সটি ব্যবহার করছেন সেটি নির্বাচন করুন এবং চালিয়ে যান এবং তারপর নিশ্চিত করুন ।
5. নোটবুকে কাজ চালিয়ে যান
ইনস্টল করুন
শুরু করা নোটবুকটি VM-এ TFX এবং Kubeflow Pipelines (KFP) ইনস্টল করার মাধ্যমে শুরু হয় যেখানে জুপিটার ল্যাব চলছে৷
এটি তারপর TFX-এর কোন সংস্করণ ইনস্টল করা আছে তা পরীক্ষা করে, একটি আমদানি করে এবং প্রকল্প আইডি সেট ও প্রিন্ট করে:

আপনার Google ক্লাউড পরিষেবাগুলির সাথে সংযোগ করুন৷
পাইপলাইন কনফিগারেশনের জন্য আপনার প্রকল্প আইডি প্রয়োজন, যা আপনি নোটবুকের মাধ্যমে পেতে পারেন এবং একটি পরিবেশগত পরিবর্তনশীল হিসাবে সেট করতে পারেন।
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
এখন আপনার KFP ক্লাস্টার এন্ডপয়েন্ট সেট করুন।
এটি পাইপলাইন ড্যাশবোর্ডের URL থেকে পাওয়া যাবে। Kubeflow পাইপলাইন ড্যাশবোর্ডে যান এবং URL টি দেখুন। googleusercontent.com পর্যন্ত এবং সহ https:// দিয়ে শুরু হওয়া URL-এর সবকিছুই শেষ পয়েন্ট।
ENDPOINT='' # Enter YOUR ENDPOINT here.
নোটবুক তারপর কাস্টম ডকার ইমেজের জন্য একটি অনন্য নাম সেট করে:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. আপনার প্রকল্প ডিরেক্টরিতে একটি টেমপ্লেট অনুলিপি করুন
আপনার পাইপলাইনের জন্য একটি নাম সেট করতে পরবর্তী নোটবুক ঘরটি সম্পাদনা করুন৷ এই টিউটোরিয়ালে আমরা my_pipeline ব্যবহার করব।
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
নোটবুক তারপর পাইপলাইন টেমপ্লেট অনুলিপি করতে tfx CLI ব্যবহার করে। এই টিউটোরিয়ালটি বাইনারি শ্রেণীবিভাগ সম্পাদন করতে শিকাগো ট্যাক্সি ডেটাসেট ব্যবহার করে, তাই টেমপ্লেটটি taxi মডেল সেট করে:
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
নোটবুক তারপর প্রকল্প ডিরেক্টরিতে তার CWD প্রসঙ্গ পরিবর্তন করে:
%cd {PROJECT_DIR}
পাইপলাইন ফাইল ব্রাউজ করুন
ক্লাউড এআই প্ল্যাটফর্ম নোটবুকের বাম দিকে, আপনি একটি ফাইল ব্রাউজার দেখতে পাবেন। আপনার পাইপলাইন নামের সাথে একটি ডিরেক্টরি থাকা উচিত ( my_pipeline )। এটি খুলুন এবং ফাইলগুলি দেখুন। (আপনি সেগুলি খুলতে এবং নোটবুকের পরিবেশ থেকেও সম্পাদনা করতে সক্ষম হবেন।)
# You can also list the files from the shellls
উপরের tfx template copy কমান্ডটি ফাইলগুলির একটি মৌলিক স্ক্যাফোল্ড তৈরি করে যা একটি পাইপলাইন তৈরি করে। এর মধ্যে রয়েছে পাইথন সোর্স কোড, নমুনা ডেটা এবং জুপিটার নোটবুক। এই বিশেষ উদাহরণ জন্য বোঝানো হয়. আপনার নিজস্ব পাইপলাইনগুলির জন্য এইগুলি সমর্থনকারী ফাইলগুলি হবে যা আপনার পাইপলাইনের প্রয়োজন।
এখানে পাইথন ফাইলগুলির সংক্ষিপ্ত বিবরণ রয়েছে।
-
pipeline- এই ডিরেক্টরিতে পাইপলাইনের সংজ্ঞা রয়েছে-
configs.py— পাইপলাইন রানারদের জন্য সাধারণ ধ্রুবক সংজ্ঞায়িত করে -
pipeline.py— TFX উপাদান এবং একটি পাইপলাইন সংজ্ঞায়িত করে
-
-
models- এই ডিরেক্টরিতে ML মডেল সংজ্ঞা রয়েছে।-
features.pyfeatures_test.py— মডেলের বৈশিষ্ট্যগুলিকে সংজ্ঞায়িত করে -
preprocessing.py/preprocessing_test.py—tf::Transformব্যবহার করে প্রিপ্রসেসিং কাজ সংজ্ঞায়িত করে -
estimator- এই ডিরেক্টরিতে একটি অনুমান ভিত্তিক মডেল রয়েছে।-
constants.py— মডেলের ধ্রুবক সংজ্ঞায়িত করে -
model.py/model_test.py— TF এস্টিমেটর ব্যবহার করে DNN মডেলকে সংজ্ঞায়িত করে
-
-
keras- এই ডিরেক্টরিতে একটি কেরাস ভিত্তিক মডেল রয়েছে।-
constants.py— মডেলের ধ্রুবক সংজ্ঞায়িত করে -
model.py/model_test.py— কেরাস ব্যবহার করে DNN মডেলকে সংজ্ঞায়িত করে
-
-
-
beam_runner.py/kubeflow_runner.py— প্রতিটি অর্কেস্ট্রেশন ইঞ্জিনের জন্য রানারদের সংজ্ঞায়িত করুন
7. Kubeflow-এ আপনার প্রথম TFX পাইপলাইন চালান
নোটবুক tfx run সিএলআই কমান্ড ব্যবহার করে পাইপলাইন চালাবে।
স্টোরেজের সাথে সংযোগ করুন
চলমান পাইপলাইনগুলি শিল্পকর্ম তৈরি করে যা ML-মেটাডেটাতে সংরক্ষণ করতে হয়। আর্টিফ্যাক্টগুলি পেলোডগুলিকে বোঝায়, যেগুলি ফাইলগুলিকে অবশ্যই একটি ফাইল সিস্টেমে সংরক্ষণ করতে হবে বা স্টোরেজ ব্লক করতে হবে। এই টিউটোরিয়ালের জন্য, সেটআপের সময় স্বয়ংক্রিয়ভাবে তৈরি হওয়া বালতি ব্যবহার করে আমরা আমাদের মেটাডেটা পেলোড সংরক্ষণ করতে GCS ব্যবহার করব। এর নাম হবে <your-project-id>-kubeflowpipelines-default ।
পাইপলাইন তৈরি করুন
নোটবুক আমাদের নমুনা ডেটা GCS বালতিতে আপলোড করবে যাতে আমরা পরে আমাদের পাইপলাইনে এটি ব্যবহার করতে পারি।
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv
নোটবুক তারপর পাইপলাইন তৈরি করতে tfx pipeline create কমান্ড ব্যবহার করে।
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
একটি পাইপলাইন তৈরি করার সময়, একটি ডকার ইমেজ তৈরি করতে Dockerfile তৈরি করা হবে। অন্যান্য সোর্স ফাইলের সাথে এই ফাইলগুলিকে আপনার সোর্স কন্ট্রোল সিস্টেমে (উদাহরণস্বরূপ, গিট) যোগ করতে ভুলবেন না।
পাইপলাইন চালান
নোটবুকটি তারপর আপনার পাইপলাইনের একটি এক্সিকিউশন রান শুরু করতে tfx run create কমান্ড ব্যবহার করে। এছাড়াও আপনি Kubeflow Pipelines ড্যাশবোর্ডে পরীক্ষা-নিরীক্ষার অধীনে তালিকাভুক্ত এই রানটি দেখতে পাবেন।
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}
আপনি Kubeflow Pipelines ড্যাশবোর্ড থেকে আপনার পাইপলাইন দেখতে পারেন।
8. আপনার ডেটা যাচাই করুন
যেকোন ডেটা সায়েন্স বা এমএল প্রজেক্টের প্রথম কাজ হল ডেটা বোঝা এবং পরিষ্কার করা।
- প্রতিটি বৈশিষ্ট্যের জন্য ডেটা প্রকারগুলি বুঝুন
- অসঙ্গতি এবং অনুপস্থিত মান জন্য দেখুন
- প্রতিটি বৈশিষ্ট্যের জন্য বিতরণগুলি বুঝুন
উপাদান


- ExampleGen ইনপুট ডেটাসেট ইনজেস্ট করে এবং বিভক্ত করে।
- StatisticsGen ডেটাসেটের জন্য পরিসংখ্যান গণনা করে।
- SchemaGen SchemaGen পরিসংখ্যান পরীক্ষা করে এবং একটি ডেটা স্কিমা তৈরি করে।
- ExampleValidator ডেটাসেটে অসঙ্গতি এবং অনুপস্থিত মানগুলি সন্ধান করে।
জুপিটার ল্যাব ফাইল এডিটরে:
pipeline / pipeline.py এ, আপনার পাইপলাইনে এই উপাদানগুলি যুক্ত করা লাইনগুলিকে আনকমেন্ট করুন:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( টেমপ্লেট ফাইলগুলি কপি করার সময় ExampleGen ইতিমধ্যেই সক্রিয় ছিল৷)
পাইপলাইন আপডেট করুন এবং এটি পুনরায় চালান
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
পাইপলাইন পরীক্ষা করুন
Kubeflow Orchestrator-এর জন্য, KFP ড্যাশবোর্ডে যান এবং আপনার পাইপলাইন চালানোর জন্য পৃষ্ঠায় পাইপলাইন আউটপুট খুঁজুন। বাম দিকে "পরীক্ষা" ট্যাবে ক্লিক করুন এবং পরীক্ষা পৃষ্ঠায় "সমস্ত রান" ক্লিক করুন৷ আপনি আপনার পাইপলাইনের নামের সাথে রান খুঁজে পেতে সক্ষম হওয়া উচিত।
আরও উন্নত উদাহরণ
এখানে উপস্থাপিত উদাহরণ সত্যিই শুধুমাত্র আপনি শুরু করার জন্য বোঝানো হয়েছে. আরও উন্নত উদাহরণের জন্য টেনসরফ্লো ডেটা ভ্যালিডেশন কোলাব দেখুন।
একটি ডেটাসেট অন্বেষণ এবং যাচাই করতে TFDV ব্যবহার করার বিষয়ে আরও তথ্যের জন্য, tensorflow.org-এ উদাহরণগুলি দেখুন ।
9. বৈশিষ্ট্য প্রকৌশল
আপনি আপনার ডেটার ভবিষ্যদ্বাণীমূলক গুণমান বাড়াতে এবং/অথবা বৈশিষ্ট্য প্রকৌশলের মাধ্যমে মাত্রা কমাতে পারেন।
- বৈশিষ্ট্য ক্রস
- শব্দভান্ডার
- এমবেডিং
- পিসিএ
- শ্রেণীবদ্ধ এনকোডিং
TFX ব্যবহার করার একটি সুবিধা হল যে আপনি একবার আপনার রূপান্তর কোড লিখবেন এবং এর ফলে পরিবর্তিত রূপান্তরগুলি প্রশিক্ষণ এবং পরিবেশনের মধ্যে সামঞ্জস্যপূর্ণ হবে।
উপাদান

- ট্রান্সফর্ম ডেটাসেটে ফিচার ইঞ্জিনিয়ারিং করে।
জুপিটার ল্যাব ফাইল এডিটরে:
pipeline / pipeline.py এ, পাইপলাইনে ট্রান্সফর্ম যুক্ত করা লাইনটি খুঁজুন এবং আনকমেন্ট করুন।
# components.append(transform)
পাইপলাইন আপডেট করুন এবং এটি পুনরায় চালান
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
পাইপলাইন আউটপুট পরীক্ষা করুন
Kubeflow Orchestrator-এর জন্য, KFP ড্যাশবোর্ডে যান এবং আপনার পাইপলাইন চালানোর জন্য পৃষ্ঠায় পাইপলাইন আউটপুট খুঁজুন। বাম দিকে "পরীক্ষা" ট্যাবে ক্লিক করুন এবং পরীক্ষা পৃষ্ঠায় "সমস্ত রান" ক্লিক করুন৷ আপনি আপনার পাইপলাইনের নামের সাথে রান খুঁজে পেতে সক্ষম হওয়া উচিত।
আরও উন্নত উদাহরণ
এখানে উপস্থাপিত উদাহরণ সত্যিই শুধুমাত্র আপনি শুরু করার জন্য বোঝানো হয়েছে. আরও উন্নত উদাহরণের জন্য TensorFlow Transform Colab দেখুন।
10. প্রশিক্ষণ
আপনার সুন্দর, পরিষ্কার, রূপান্তরিত ডেটা দিয়ে একটি টেনসরফ্লো মডেলকে প্রশিক্ষণ দিন।
- পূর্ববর্তী ধাপ থেকে রূপান্তরগুলি অন্তর্ভুক্ত করুন যাতে সেগুলি ধারাবাহিকভাবে প্রয়োগ করা হয়
- উত্পাদনের জন্য একটি সংরক্ষিত মডেল হিসাবে ফলাফল সংরক্ষণ করুন
- টেনসরবোর্ড ব্যবহার করে প্রশিক্ষণ প্রক্রিয়াটি ভিজ্যুয়ালাইজ করুন এবং অন্বেষণ করুন
- এছাড়াও মডেল কর্মক্ষমতা বিশ্লেষণের জন্য একটি EvalSavedModel সংরক্ষণ করুন
উপাদান
- প্রশিক্ষক একটি টেনসরফ্লো মডেলকে প্রশিক্ষণ দেয়।
জুপিটার ল্যাব ফাইল এডিটরে:
pipeline / pipeline.py , পাইপলাইনে প্রশিক্ষক যুক্ত করে তা খুঁজুন এবং মন্তব্য করুন:
# components.append(trainer)
পাইপলাইন আপডেট করুন এবং এটি পুনরায় চালান
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
পাইপলাইন আউটপুট পরীক্ষা করুন
Kubeflow Orchestrator-এর জন্য, KFP ড্যাশবোর্ডে যান এবং আপনার পাইপলাইন চালানোর জন্য পৃষ্ঠায় পাইপলাইন আউটপুট খুঁজুন। বাম দিকে "পরীক্ষা" ট্যাবে ক্লিক করুন এবং পরীক্ষা পৃষ্ঠায় "সমস্ত রান" ক্লিক করুন৷ আপনি আপনার পাইপলাইনের নামের সাথে রান খুঁজে পেতে সক্ষম হওয়া উচিত।
আরও উন্নত উদাহরণ
এখানে উপস্থাপিত উদাহরণ সত্যিই শুধুমাত্র আপনি শুরু করার জন্য বোঝানো হয়েছে. আরও উন্নত উদাহরণের জন্য TensorBoard টিউটোরিয়াল দেখুন।
11. মডেল কর্মক্ষমতা বিশ্লেষণ
শুধুমাত্র শীর্ষ স্তরের মেট্রিক্সের চেয়ে বেশি বোঝা।
- ব্যবহারকারীরা শুধুমাত্র তাদের প্রশ্নের জন্য মডেল কর্মক্ষমতা অভিজ্ঞতা
- ডেটার স্লাইসে খারাপ পারফরম্যান্স শীর্ষ স্তরের মেট্রিক্স দ্বারা লুকানো যেতে পারে
- মডেল ন্যায্যতা গুরুত্বপূর্ণ
- প্রায়শই ব্যবহারকারী বা ডেটার মূল উপসেটগুলি খুবই গুরুত্বপূর্ণ এবং ছোট হতে পারে
- সমালোচনামূলক কিন্তু অস্বাভাবিক পরিস্থিতিতে পারফরম্যান্স
- প্রভাবশালীদের মতো মূল দর্শকদের জন্য পারফরম্যান্স
- আপনি যদি একটি মডেল প্রতিস্থাপন করছেন যা বর্তমানে উৎপাদনে আছে, প্রথমে নিশ্চিত করুন যে নতুনটি আরও ভাল
উপাদান
- মূল্যায়নকারী প্রশিক্ষণের ফলাফলের গভীর বিশ্লেষণ করে।
জুপিটার ল্যাব ফাইল এডিটরে:
pipeline / pipeline.py এ, পাইপলাইনে মূল্যায়নকারী যুক্ত করা লাইনটি খুঁজুন এবং আনকমেন্ট করুন:
components.append(evaluator)
পাইপলাইন আপডেট করুন এবং এটি পুনরায় চালান
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
পাইপলাইন আউটপুট পরীক্ষা করুন
Kubeflow Orchestrator-এর জন্য, KFP ড্যাশবোর্ডে যান এবং আপনার পাইপলাইন চালানোর জন্য পৃষ্ঠায় পাইপলাইন আউটপুট খুঁজুন। বাম দিকে "পরীক্ষা" ট্যাবে ক্লিক করুন এবং পরীক্ষা পৃষ্ঠায় "সমস্ত রান" ক্লিক করুন৷ আপনি আপনার পাইপলাইনের নামের সাথে রান খুঁজে পেতে সক্ষম হওয়া উচিত।
12. মডেল পরিবেশন করা
নতুন মডেল প্রস্তুত হলে, এটি তাই করুন.
- পুশার সংরক্ষিত মডেলগুলি সুপরিচিত স্থানে স্থাপন করে
স্থাপনার লক্ষ্যগুলি সুপরিচিত অবস্থান থেকে নতুন মডেলগুলি গ্রহণ করে৷
- টেনসরফ্লো পরিবেশন
- টেনসরফ্লো লাইট
- টেনসরফ্লো জেএস
- টেনসরফ্লো হাব
উপাদান
- পুশার মডেলটিকে পরিবেশনকারী পরিকাঠামোতে স্থাপন করে।
জুপিটার ল্যাব ফাইল এডিটরে:
pipeline / pipeline.py এ, পাইপলাইনে পুশার যুক্ত করা লাইনটি খুঁজুন এবং আনকমেন্ট করুন:
# components.append(pusher)
পাইপলাইন আউটপুট পরীক্ষা করুন
Kubeflow Orchestrator-এর জন্য, KFP ড্যাশবোর্ডে যান এবং আপনার পাইপলাইন চালানোর জন্য পৃষ্ঠায় পাইপলাইন আউটপুট খুঁজুন। বাম দিকে "পরীক্ষা" ট্যাবে ক্লিক করুন এবং পরীক্ষা পৃষ্ঠায় "সমস্ত রান" ক্লিক করুন৷ আপনি আপনার পাইপলাইনের নামের সাথে রান খুঁজে পেতে সক্ষম হওয়া উচিত।
উপলভ্য স্থাপনার লক্ষ্যমাত্রা
আপনি এখন আপনার মডেলকে প্রশিক্ষিত এবং যাচাই করেছেন, এবং আপনার মডেল এখন উৎপাদনের জন্য প্রস্তুত। আপনি এখন আপনার মডেলটি যেকোনও টেনসরফ্লো স্থাপনার লক্ষ্যে স্থাপন করতে পারেন, যার মধ্যে রয়েছে:
- টেনসরফ্লো সার্ভিং , সার্ভার বা সার্ভার ফার্মে আপনার মডেল পরিবেশন করার জন্য এবং REST এবং/অথবা gRPC অনুমান অনুরোধগুলি প্রক্রিয়া করার জন্য।
- TensorFlow Lite , একটি Android বা iOS নেটিভ মোবাইল অ্যাপ্লিকেশন, বা একটি Raspberry Pi, IoT, বা মাইক্রোকন্ট্রোলার অ্যাপ্লিকেশনে আপনার মডেল অন্তর্ভুক্ত করার জন্য।
- TensorFlow.js , একটি ওয়েব ব্রাউজার বা Node.JS অ্যাপ্লিকেশনে আপনার মডেল চালানোর জন্য।
আরও উন্নত উদাহরণ
উপরে উপস্থাপিত উদাহরণ সত্যিই শুধুমাত্র আপনি শুরু করার জন্য বোঝানো হয়েছে. নীচে অন্যান্য ক্লাউড পরিষেবাগুলির সাথে একীকরণের কিছু উদাহরণ রয়েছে৷
Kubeflow পাইপলাইন সম্পদ বিবেচনা
আপনার কাজের চাপের প্রয়োজনীয়তার উপর নির্ভর করে, আপনার Kubeflow পাইপলাইন স্থাপনের ডিফল্ট কনফিগারেশন আপনার চাহিদা পূরণ করতে পারে বা নাও করতে পারে। আপনি KubeflowDagRunnerConfig এ আপনার কলে pipeline_operator_funcs ব্যবহার করে আপনার রিসোর্স কনফিগারেশন কাস্টমাইজ করতে পারেন।
pipeline_operator_funcs হল OpFunc আইটেমগুলির একটি তালিকা, যা KFP পাইপলাইন স্পেকের মধ্যে তৈরি হওয়া সমস্ত ContainerOp দৃষ্টান্তগুলিকে রূপান্তরিত করে যা KubeflowDagRunner থেকে সংকলিত হয়েছে।
উদাহরণ স্বরূপ, মেমরি কনফিগার করতে আমরা set_memory_request ব্যবহার করতে পারি প্রয়োজনীয় মেমরির পরিমাণ ঘোষণা করতে। এটি করার একটি সাধারণ উপায় হল set_memory_request এর জন্য একটি র্যাপার তৈরি করা এবং পাইপলাইন OpFunc s এর তালিকায় যোগ করতে এটি ব্যবহার করা:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
অনুরূপ সম্পদ কনফিগারেশন ফাংশন অন্তর্ভুক্ত:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
BigQueryExampleGen ব্যবহার করে দেখুন
BigQuery হল একটি সার্ভারহীন, অত্যন্ত মাপযোগ্য, এবং সাশ্রয়ী ক্লাউড ডেটা গুদাম। BigQuery টিএফএক্স-এ প্রশিক্ষণের উদাহরণের উৎস হিসেবে ব্যবহার করা যেতে পারে। এই ধাপে, আমরা পাইপলাইনে BigQueryExampleGen যোগ করব।
জুপিটার ল্যাব ফাইল এডিটরে:
pipeline.py খুলতে ডাবল-ক্লিক করুন । CsvExampleGen মন্তব্য করুন এবং লাইনটি আনকমেন্ট করুন যা BigQueryExampleGen এর একটি উদাহরণ তৈরি করে। আপনাকে create_pipeline ফাংশনের query আর্গুমেন্টটিও আনকমেন্ট করতে হবে।
BigQuery-এর জন্য কোন GCP প্রোজেক্ট ব্যবহার করতে হবে তা আমাদের নির্দিষ্ট করতে হবে এবং পাইপলাইন তৈরি করার সময় beam_pipeline_args এ --project সেট করে এটি করা হয়।
configs.py খুলতে ডাবল-ক্লিক করুন । BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS এবং BIG_QUERY_QUERY এর সংজ্ঞা মুক্ত করুন। আপনার GCP প্রকল্পের জন্য সঠিক মান দিয়ে এই ফাইলে প্রোজেক্ট আইডি এবং অঞ্চলের মান প্রতিস্থাপন করা উচিত।
ডাইরেক্টরি এক লেভেল আপ পরিবর্তন করুন। ফাইল তালিকার উপরে ডিরেক্টরির নামে ক্লিক করুন। ডিরেক্টরির নাম হল পাইপলাইনের নাম যা my_pipeline যদি আপনি পাইপলাইনের নাম পরিবর্তন না করেন।
kubeflow_runner.py খুলতে ডাবল-ক্লিক করুন । create_pipeline ফাংশনের জন্য দুটি আর্গুমেন্ট, query এবং beam_pipeline_args আনকমেন্ট করুন।
এখন পাইপলাইন একটি উদাহরণ উৎস হিসাবে BigQuery ব্যবহার করার জন্য প্রস্তুত। পাইপলাইনটি আগের মতো আপডেট করুন এবং একটি নতুন এক্সিকিউশন রান তৈরি করুন যেমন আমরা ধাপ 5 এবং 6 এ করেছি।
পাইপলাইন আপডেট করুন এবং এটি পুনরায় চালান
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Dataflow চেষ্টা করুন
বেশ কিছু TFX উপাদান ডেটা-সমান্তরাল পাইপলাইন বাস্তবায়নের জন্য Apache Beam ব্যবহার করে এবং এর মানে হল আপনি Google Cloud Dataflow ব্যবহার করে ডেটা প্রসেসিং ওয়ার্কলোড বিতরণ করতে পারেন। এই ধাপে, আমরা Apache Beam-এর জন্য ডেটা প্রসেসিং ব্যাক-এন্ড হিসাবে Dataflow ব্যবহার করার জন্য Kubeflow অর্কেস্ট্রেটরকে সেট করব।
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
ডিরেক্টরি পরিবর্তন করতে pipeline ডাবল-ক্লিক করুন এবং configs.py খুলতে ডাবল-ক্লিক করুন । GOOGLE_CLOUD_REGION , এবং DATAFLOW_BEAM_PIPELINE_ARGS এর সংজ্ঞাটি মুক্ত করুন।
ডাইরেক্টরি এক লেভেল আপ পরিবর্তন করুন। ফাইল তালিকার উপরে ডিরেক্টরির নামে ক্লিক করুন। ডিরেক্টরির নাম হল পাইপলাইনের নাম যা আপনি পরিবর্তন না করলে my_pipeline ।
kubeflow_runner.py খুলতে ডাবল-ক্লিক করুন । beam_pipeline_args আনকমেন্ট করুন। (এছাড়া আপনি ধাপ 7 এ যোগ করা বর্তমান beam_pipeline_args সম্পর্কে মন্তব্য করতে ভুলবেন না।)
পাইপলাইন আপডেট করুন এবং এটি পুনরায় চালান
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
আপনি ক্লাউড কনসোলে ডেটাফ্লোতে আপনার ডেটাফ্লো কাজগুলি খুঁজে পেতে পারেন।
KFP এর সাথে ক্লাউড এআই প্ল্যাটফর্ম প্রশিক্ষণ এবং ভবিষ্যদ্বাণী ব্যবহার করে দেখুন
TFX বিভিন্ন পরিচালিত GCP পরিষেবাগুলির সাথে আন্তঃঅপারেটিং করে, যেমন ক্লাউড এআই প্ল্যাটফর্ম প্রশিক্ষণ এবং পূর্বাভাস । আপনি ক্লাউড এআই প্ল্যাটফর্ম প্রশিক্ষণ, এমএল মডেল প্রশিক্ষণের জন্য একটি পরিচালিত পরিষেবা ব্যবহার করার জন্য আপনার Trainer উপাদান সেট করতে পারেন। তাছাড়া, যখন আপনার মডেল তৈরি করা হয় এবং পরিবেশনের জন্য প্রস্তুত হয়, আপনি আপনার মডেলটিকে ক্লাউড এআই প্ল্যাটফর্ম পূর্বাভাস পরিবেশনের জন্য ঠেলে দিতে পারেন। এই ধাপে, আমরা ক্লাউড এআই প্ল্যাটফর্ম পরিষেবাগুলি ব্যবহার করার জন্য আমাদের Trainer এবং Pusher উপাদান সেট করব।
ফাইলগুলি সম্পাদনা করার আগে, আপনাকে প্রথমে AI প্ল্যাটফর্ম প্রশিক্ষণ এবং পূর্বাভাস API সক্ষম করতে হতে পারে৷
ডিরেক্টরি পরিবর্তন করতে pipeline ডাবল-ক্লিক করুন এবং configs.py খুলতে ডাবল-ক্লিক করুন । GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS এবং GCP_AI_PLATFORM_SERVING_ARGS এর সংজ্ঞাটি মুক্ত করুন। ক্লাউড AI প্ল্যাটফর্ম প্রশিক্ষণে একটি মডেলকে প্রশিক্ষণ দিতে আমরা আমাদের কাস্টম বিল্ট কন্টেইনার ইমেজ ব্যবহার করব, তাই আমাদের GCP_AI_PLATFORM_TRAINING_ARGS এ masterConfig.imageUri উপরে CUSTOM_TFX_IMAGE এর মতো একই মান সেট করা উচিত।
ডাইরেক্টরি এক লেভেল আপ পরিবর্তন করুন, এবং kubeflow_runner.py খুলতে ডাবল-ক্লিক করুন । ai_platform_training_args এবং ai_platform_serving_args আনকমেন্ট করুন।
পাইপলাইন আপডেট করুন এবং এটি পুনরায় চালান
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
আপনি ক্লাউড এআই প্ল্যাটফর্মের চাকরিতে আপনার প্রশিক্ষণের চাকরি খুঁজে পেতে পারেন। আপনার পাইপলাইন সফলভাবে সম্পন্ন হলে, আপনি ক্লাউড এআই প্ল্যাটফর্ম মডেলগুলিতে আপনার মডেলটি খুঁজে পেতে পারেন।
14. আপনার নিজস্ব ডেটা ব্যবহার করুন
এই টিউটোরিয়ালে, আপনি শিকাগো ট্যাক্সি ডেটাসেট ব্যবহার করে একটি মডেলের জন্য একটি পাইপলাইন তৈরি করেছেন। এখন পাইপলাইনে আপনার নিজস্ব ডেটা রাখার চেষ্টা করুন। আপনার ডেটা Google ক্লাউড স্টোরেজ, BigQuery, বা CSV ফাইল সহ পাইপলাইন অ্যাক্সেস করতে পারে এমন যেকোনো জায়গায় সংরক্ষণ করা যেতে পারে।
আপনার ডেটা মিটমাট করার জন্য আপনাকে পাইপলাইনের সংজ্ঞা পরিবর্তন করতে হবে।
যদি আপনার ডেটা ফাইলগুলিতে সংরক্ষণ করা হয়
-
kubeflow_runner.pyএDATA_PATHপরিবর্তন করুন, অবস্থান নির্দেশ করে।
যদি আপনার ডেটা BigQuery-এ সংরক্ষিত থাকে
- আপনার ক্যোয়ারী স্টেটমেন্টে configs.py-এ
BIG_QUERY_QUERYসংশোধন করুন। -
models/features.pyএ বৈশিষ্ট্য যোগ করুন। - প্রশিক্ষণের জন্য ইনপুট ডেটা রূপান্তর করতে
models/preprocessing.pyপরিবর্তন করুন। - আপনার ML মডেল বর্ণনা করতে
models/keras/model.pyএবংmodels/keras/constants.pyপরিবর্তন করুন।
প্রশিক্ষক সম্পর্কে আরও জানুন
প্রশিক্ষণ পাইপলাইন সম্পর্কে আরো বিস্তারিত জানার জন্য প্রশিক্ষক উপাদান নির্দেশিকা দেখুন।
পরিষ্কার আপ
এই প্রকল্পে ব্যবহৃত সমস্ত Google ক্লাউড সংস্থানগুলি পরিষ্কার করতে, আপনি টিউটোরিয়ালের জন্য ব্যবহৃত Google ক্লাউড প্রকল্পটি মুছে ফেলতে পারেন৷
বিকল্পভাবে, আপনি প্রতিটি কনসোল পরিদর্শন করে পৃথক সম্পদ পরিষ্কার করতে পারেন: - Google ক্লাউড স্টোরেজ - Google কন্টেইনার রেজিস্ট্রি - Google Kubernetes Engine