
ExampleGen TFX পাইপলাইন উপাদানটি TFX পাইপলাইনে ডেটা প্রবেশ করে। এটি উদাহরণ তৈরি করতে বাহ্যিক ফাইল/পরিষেবা গ্রহণ করে যা অন্যান্য TFX উপাদান দ্বারা পড়া হবে। এটি সামঞ্জস্যপূর্ণ এবং কনফিগারযোগ্য বিভাজন প্রদান করে এবং এমএল সেরা অনুশীলনের জন্য ডেটাসেটকে এলোমেলো করে।
- ব্যবহার করে: CSV,
TFRecord, Avro, Parquet এবং BigQuery এর মতো বাহ্যিক ডেটা উত্স থেকে ডেটা। - নির্গত হয়:
tf.Exampleরেকর্ড,tf.SequenceExampleরেকর্ড, বা প্রোটো বিন্যাস, পেলোড বিন্যাসের উপর নির্ভর করে।
ExampleGen এবং অন্যান্য উপাদান
ExampleGen এমন উপাদানগুলিতে ডেটা সরবরাহ করে যা TensorFlow ডেটা বৈধতা লাইব্রেরি ব্যবহার করে, যেমন SchemaGen , StatisticsGen , এবং Example Validator ৷ এটি ট্রান্সফর্মকে ডেটাও সরবরাহ করে, যা টেনসরফ্লো ট্রান্সফর্ম লাইব্রেরি ব্যবহার করে এবং শেষ পর্যন্ত অনুমানের সময় লক্ষ্য স্থাপনের জন্য।
তথ্য উত্স এবং বিন্যাস
বর্তমানে TFX-এর একটি স্ট্যান্ডার্ড ইনস্টলেশনে এই ডেটা উত্স এবং ফর্ম্যাটের জন্য সম্পূর্ণ ExampleGen উপাদান অন্তর্ভুক্ত রয়েছে:
কাস্টম নির্বাহকও উপলব্ধ যা এই ডেটা উত্স এবং বিন্যাসের জন্য ExampleGen উপাদানগুলির বিকাশকে সক্ষম করে:
কীভাবে কাস্টম এক্সিকিউটরগুলি ব্যবহার এবং বিকাশ করতে হয় সে সম্পর্কে আরও তথ্যের জন্য উত্স কোডে ব্যবহারের উদাহরণগুলি এবং এই আলোচনাটি দেখুন৷
উপরন্তু, এই ডেটা উত্স এবং ফর্ম্যাটগুলি কাস্টম উপাদান উদাহরণ হিসাবে উপলব্ধ:
Apache Beam দ্বারা সমর্থিত ডেটা বিন্যাসগুলি গ্রহণ করা৷
Apache Beam ডেটা উৎস এবং ফরম্যাটের একটি বিস্তৃত পরিসর থেকে ডেটা গ্রহণ সমর্থন করে, ( নীচে দেখুন )। এই ক্ষমতাগুলি TFX-এর জন্য কাস্টম ExampleGen উপাদান তৈরি করতে ব্যবহার করা যেতে পারে, যা কিছু বিদ্যমান ExampleGen উপাদান দ্বারা প্রদর্শিত হয় ( নীচে দেখুন )।
কিভাবে একটি ExampleGen কম্পোনেন্ট ব্যবহার করবেন
সমর্থিত ডেটা উত্সগুলির জন্য (বর্তমানে, CSV ফাইল, tf.Example সহ TFRecord ফাইল , tf.SequenceExample এবং প্রোটো ফর্ম্যাট এবং BigQuery প্রশ্নের ফলাফল) ExampleGen পাইপলাইন উপাদান সরাসরি স্থাপনে ব্যবহার করা যেতে পারে এবং সামান্য কাস্টমাইজেশন প্রয়োজন। যেমন:
example_gen = CsvExampleGen(input_base='data_root')
অথবা সরাসরি tf.Example সহ বাহ্যিক TFRecord আমদানি করার জন্য নীচের মত:
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
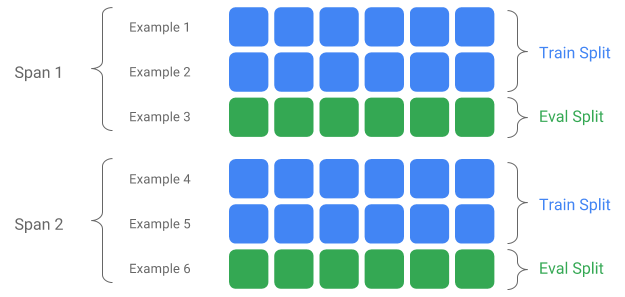
স্প্যান, সংস্করণ এবং বিভক্ত
একটি স্প্যান হল প্রশিক্ষণ উদাহরণগুলির একটি গ্রুপিং। যদি আপনার ডেটা একটি ফাইল সিস্টেমে স্থায়ী হয়, প্রতিটি স্প্যান একটি পৃথক ডিরেক্টরিতে সংরক্ষণ করা যেতে পারে। একটি স্প্যানের শব্দার্থবিদ্যা TFX-এ হার্ডকোড করা হয় না; একটি স্প্যান ডেটার একটি দিন, ডেটার এক ঘন্টা, বা আপনার কাজের জন্য অর্থপূর্ণ অন্য কোনও গ্রুপিংয়ের সাথে সম্পর্কিত হতে পারে।
প্রতিটি স্প্যান ডেটার একাধিক সংস্করণ ধারণ করতে পারে। একটি উদাহরণ দেওয়ার জন্য, যদি আপনি খারাপ মানের ডেটা পরিষ্কার করার জন্য একটি স্প্যান থেকে কিছু উদাহরণ সরিয়ে দেন, তাহলে এর ফলে সেই স্প্যানটির একটি নতুন সংস্করণ হতে পারে। ডিফল্টরূপে, TFX উপাদানগুলি একটি স্প্যানের মধ্যে সর্বশেষ সংস্করণে কাজ করে।
একটি স্প্যানের মধ্যে প্রতিটি সংস্করণকে একাধিক বিভাজনে বিভক্ত করা যেতে পারে। একটি স্প্যানকে বিভক্ত করার জন্য সবচেয়ে সাধারণ ব্যবহারের ক্ষেত্রে এটিকে প্রশিক্ষণ এবং ইভাল ডেটাতে বিভক্ত করা।
কাস্টম ইনপুট/আউটপুট বিভক্ত
ট্রেন/ইভাল স্প্লিট রেশিও কাস্টমাইজ করতে যা ExampleGen আউটপুট করবে, ExampleGen কম্পোনেন্টের জন্য output_config সেট করুন। যেমন:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
লক্ষ্য করুন কিভাবে এই উদাহরণে hash_buckets সেট করা হয়েছে।
একটি ইনপুট উত্সের জন্য যা ইতিমধ্যেই বিভক্ত হয়েছে, ExampleGen উপাদানের জন্য input_config সেট করুন:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
ফাইল ভিত্তিক উদাহরণ জেনের জন্য (যেমন CsvExampleGen এবং ImportExampleGen), pattern হল একটি গ্লোব আপেক্ষিক ফাইল প্যাটার্ন যা ইনপুট বেস পাথ দ্বারা প্রদত্ত রুট ডিরেক্টরি সহ ইনপুট ফাইলগুলিতে ম্যাপ করে। কোয়েরি-ভিত্তিক উদাহরণের জন্য (যেমন BigQueryExampleGen, PrestoExampleGen), pattern হল একটি SQL কোয়েরি।
ডিফল্টরূপে, সম্পূর্ণ ইনপুট বেস ডিরকে একটি একক ইনপুট স্প্লিট হিসাবে বিবেচনা করা হয় এবং ট্রেন এবং ইভাল আউটপুট স্প্লিট 2:1 অনুপাতের সাথে তৈরি হয়।
ExampleGen এর ইনপুট এবং আউটপুট স্প্লিট কনফিগারেশনের জন্য অনুগ্রহ করে proto/example_gen.proto দেখুন। এবং কাস্টম স্প্লিট ডাউনস্ট্রিম ব্যবহার করার জন্য ডাউনস্ট্রিম উপাদান নির্দেশিকা পড়ুন।
বিভাজন পদ্ধতি
hash_buckets বিভাজন পদ্ধতি ব্যবহার করার সময়, সমগ্র রেকর্ডের পরিবর্তে, কেউ উদাহরণগুলিকে বিভাজন করার জন্য একটি বৈশিষ্ট্য ব্যবহার করতে পারে। যদি একটি বৈশিষ্ট্য উপস্থিত থাকে, ExampleGen পার্টিশন কী হিসাবে সেই বৈশিষ্ট্যটির একটি আঙ্গুলের ছাপ ব্যবহার করবে।
এই বৈশিষ্ট্যটি উদাহরণের নির্দিষ্ট বৈশিষ্ট্যগুলির সাথে একটি স্থিতিশীল বিভাজন বজায় রাখতে ব্যবহার করা যেতে পারে: উদাহরণস্বরূপ, পার্টিশন বৈশিষ্ট্যের নাম হিসাবে "user_id" নির্বাচন করা হলে একজন ব্যবহারকারীকে সর্বদা একই বিভাজনে রাখা হবে।
একটি "বৈশিষ্ট্য" এর অর্থ কী এবং নির্দিষ্ট নামের সাথে একটি "বৈশিষ্ট্য" কীভাবে মেলাতে হয় তার ব্যাখ্যা ExampleGen বাস্তবায়ন এবং উদাহরণগুলির প্রকারের উপর নির্ভর করে।
রেডিমেড ExampleGen বাস্তবায়নের জন্য:
- যদি এটি tf.Example তৈরি করে, তাহলে একটি "বৈশিষ্ট্য" মানে tf.Example.features.feature-এ একটি এন্ট্রি।
- যদি এটি tf.SequenceExample তৈরি করে, তাহলে একটি "বৈশিষ্ট্য" মানে tf.SequenceExample.context.feature-এ একটি এন্ট্রি।
- শুধুমাত্র int64 এবং বাইট বৈশিষ্ট্য সমর্থিত।
নিম্নলিখিত ক্ষেত্রে, ExampleGen রানটাইম ত্রুটি নিক্ষেপ করে:
- উদাহরণে নির্দিষ্ট বৈশিষ্ট্যের নাম নেই।
- খালি বৈশিষ্ট্য:
tf.train.Feature()। - অ-সমর্থিত বৈশিষ্ট্য প্রকার, যেমন, ফ্লোট বৈশিষ্ট্য।
উদাহরণগুলির একটি বৈশিষ্ট্যের উপর ভিত্তি করে ট্রেন/ইভাল স্প্লিট আউটপুট করতে, ExampleGen কম্পোনেন্টের জন্য output_config সেট করুন। যেমন:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
এই উদাহরণে partition_feature_name কিভাবে সেট করা হয়েছে তা লক্ষ্য করুন।
স্প্যান
ইনপুট গ্লোব প্যাটার্নে '{SPAN}' স্পেক ব্যবহার করে স্প্যান পুনরুদ্ধার করা যেতে পারে:
- এই বৈশিষ্ট্যটি সংখ্যার সাথে মিলে যায় এবং প্রাসঙ্গিক স্প্যান নম্বরগুলিতে ডেটা ম্যাপ করে। উদাহরণস্বরূপ, 'data_{SPAN}-*.tfrecord' 'data_12-a.tfrecord', 'data_12-b.tfrecord'-এর মতো ফাইল সংগ্রহ করবে।
- ঐচ্ছিকভাবে, ম্যাপ করার সময় এই স্পেকটি পূর্ণসংখ্যার প্রস্থের সাথে নির্দিষ্ট করা যেতে পারে। উদাহরণস্বরূপ, 'data_{SPAN:2}.file' 'data_02.file' এবং 'data_27.file' (যথাক্রমে স্প্যান-2 এবং স্প্যান-27-এর জন্য ইনপুট হিসাবে) এর মতো ফাইলগুলিতে ম্যাপ করে, কিন্তু 'ডেটা_1'-এ ম্যাপ করে না। ফাইল' বা 'data_123.file'।
- যখন স্প্যান স্পেক অনুপস্থিত থাকে, তখন এটি সর্বদা স্প্যান '0' বলে ধরে নেওয়া হয়।
- যদি SPAN নির্দিষ্ট করা থাকে, পাইপলাইন সর্বশেষ স্প্যানটি প্রক্রিয়া করবে এবং মেটাডেটাতে স্প্যান নম্বর সংরক্ষণ করবে।
উদাহরণস্বরূপ, ধরা যাক ইনপুট ডেটা আছে:
- '/tmp/span-1/train/data'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/train/data'
- '/tmp/span-2/eval/data'
এবং ইনপুট কনফিগারেশন নীচের মত দেখানো হয়েছে:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
পাইপলাইন ট্রিগার করার সময়, এটি প্রক্রিয়া করবে:
- ট্রেন বিভক্ত হিসাবে '/tmp/span-2/train/data'
- '/tmp/span-2/eval/data' eval বিভক্ত হিসাবে
'2' হিসাবে স্প্যান নম্বর সহ। যদি পরে '/tmp/span-3/...' প্রস্তুত হয়, তাহলে কেবল পাইপলাইনটি আবার ট্রিগার করুন এবং এটি প্রক্রিয়াকরণের জন্য স্প্যান '3' গ্রহণ করবে। নীচে স্প্যান স্পেক ব্যবহার করার জন্য কোড উদাহরণ দেখায়:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
একটি নির্দিষ্ট স্প্যান পুনরুদ্ধার করা RangeConfig দিয়ে করা যেতে পারে, যা নীচে বিস্তারিত আছে।
তারিখ
যদি আপনার ডেটা উত্সটি তারিখ অনুসারে ফাইল সিস্টেমে সংগঠিত হয়, TFX তারিখগুলিকে সরাসরি স্প্যান নম্বরে ম্যাপিং সমর্থন করে। তারিখ থেকে স্প্যান পর্যন্ত ম্যাপিং প্রতিনিধিত্ব করার জন্য তিনটি বৈশিষ্ট্য রয়েছে: {YYYY}, {MM} এবং {DD}:
- ইনপুট গ্লোব প্যাটার্নে তিনটি চশমা সম্পূর্ণভাবে উপস্থিত হওয়া উচিত যদি কোনো নির্দিষ্ট করা থাকে:
- হয় {SPAN} স্পেক বা এই সেট স্পেসিক্সের তারিখ একচেটিয়াভাবে নির্দিষ্ট করা যেতে পারে।
- YYYY থেকে বছর, MM থেকে মাস এবং DD থেকে মাসের দিন সহ একটি ক্যালেন্ডারের তারিখ গণনা করা হয়, তারপর স্প্যান নম্বরটি ইউনিক্স যুগ (অর্থাৎ 1970-01-01) থেকে দিনের সংখ্যা হিসাবে গণনা করা হয়। উদাহরণস্বরূপ, 'log-{YYYY}{MM}{DD}.data' একটি ফাইল 'log-19700101.data' এর সাথে মেলে এবং এটিকে স্প্যান-0 এর জন্য ইনপুট হিসাবে এবং 'log-20170101.data' এর জন্য ইনপুট হিসাবে ব্যবহার করে স্প্যান-17167।
- তারিখের স্পেসগুলির এই সেটটি নির্দিষ্ট করা থাকলে, পাইপলাইন সর্বশেষ সর্বশেষ তারিখটি প্রক্রিয়া করবে এবং মেটাডেটাতে সংশ্লিষ্ট স্প্যান নম্বর সংরক্ষণ করবে।
উদাহরণস্বরূপ, ধরা যাক ক্যালেন্ডার তারিখ দ্বারা সংগঠিত ইনপুট ডেটা রয়েছে:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
এবং ইনপুট কনফিগারেশন নীচের মত দেখানো হয়েছে:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
পাইপলাইন ট্রিগার করার সময়, এটি প্রক্রিয়া করবে:
- ট্রেন বিভক্ত হিসাবে '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data' eval বিভক্ত হিসাবে
'2' হিসাবে স্প্যান নম্বর সহ। যদি পরে '/tmp/1970-01-04/...' প্রস্তুত হয়, তাহলে কেবল পাইপলাইনটিকে আবার ট্রিগার করুন এবং এটি প্রক্রিয়াকরণের জন্য স্প্যান '3' গ্রহণ করবে। নীচে তারিখ বিশেষ ব্যবহার করার জন্য কোড উদাহরণ দেখায়:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
সংস্করণ
ইনপুট গ্লোব প্যাটার্নে '{VERSION}' স্পেক ব্যবহার করে সংস্করণটি পুনরুদ্ধার করা যেতে পারে:
- এই স্পেসটি অঙ্কের সাথে মিলে যায় এবং স্প্যানের অধীনে প্রাসঙ্গিক VERSION নম্বরগুলিতে ডেটা ম্যাপ করে। মনে রাখবেন যে সংস্করণ স্পেকটি Span বা Date spec এর সাথে একত্রে ব্যবহার করা যেতে পারে।
- এই স্পেকটিও ঐচ্ছিকভাবে স্প্যান স্পেকের মতো প্রস্থের সাথে নির্দিষ্ট করা যেতে পারে। যেমন 'span-{SPAN}/version-{VERSION:4}/data-*'।
- যখন VERSION স্পেক অনুপস্থিত থাকে, তখন সংস্করণটি কোনটি নয় হিসাবে সেট করা হয়৷
- যদি SPAN এবং VERSION উভয়ই নির্দিষ্ট করা থাকে, পাইপলাইন সর্বশেষ স্প্যানের জন্য সর্বশেষ সংস্করণটি প্রক্রিয়া করবে এবং সংস্করণ নম্বরটি মেটাডেটাতে সংরক্ষণ করবে৷
- যদি VERSION নির্দিষ্ট করা হয়, কিন্তু SPAN (বা তারিখ বিশেষ) না হয়, তাহলে একটি ত্রুটি নিক্ষেপ করা হবে।
উদাহরণস্বরূপ, ধরা যাক ইনপুট ডেটা আছে:
- '/tmp/span-1/ver-1/train/data'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data'
এবং ইনপুট কনফিগারেশন নীচের মত দেখানো হয়েছে:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
পাইপলাইন ট্রিগার করার সময়, এটি প্রক্রিয়া করবে:
- ট্রেন বিভক্ত হিসাবে '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data' eval বিভক্ত হিসাবে
স্প্যান নম্বর '2' এবং সংস্করণ নম্বর '2'। যদি পরে '/tmp/span-2/ver-3/...' প্রস্তুত হয়, তাহলে কেবল পাইপলাইনটি আবার ট্রিগার করুন এবং এটি প্রক্রিয়াকরণের জন্য স্প্যান '2' এবং সংস্করণ '3' গ্রহণ করবে। নীচে সংস্করণ বৈশিষ্ট্য ব্যবহার করার জন্য কোড উদাহরণ দেখায়:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
রেঞ্জ কনফিগারেশন
TFX রেঞ্জ কনফিগারেশন ব্যবহার করে ফাইল-ভিত্তিক ExampleGen-এ একটি নির্দিষ্ট স্প্যান পুনরুদ্ধার এবং প্রক্রিয়াকরণ সমর্থন করে, একটি বিমূর্ত কনফিগার যা বিভিন্ন TFX সত্তার জন্য রেঞ্জ বর্ণনা করতে ব্যবহৃত হয়। একটি নির্দিষ্ট স্প্যান পুনরুদ্ধার করতে, একটি ফাইল-ভিত্তিক ExampleGen উপাদানের জন্য range_config সেট করুন। উদাহরণস্বরূপ, ধরা যাক ইনপুট ডেটা আছে:
- '/tmp/span-01/train/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/train/data'
- '/tmp/span-02/eval/data'
বিশেষভাবে স্প্যান '1' দিয়ে ডেটা পুনরুদ্ধার এবং প্রক্রিয়া করার জন্য, আমরা ইনপুট কনফিগারেশন ছাড়াও একটি রেঞ্জ কনফিগারেশন নির্দিষ্ট করি। উল্লেখ্য যে ExampleGen শুধুমাত্র একক-স্প্যান স্ট্যাটিক রেঞ্জ সমর্থন করে (নির্দিষ্ট পৃথক স্প্যানগুলির প্রক্রিয়াকরণ নির্দিষ্ট করতে)। সুতরাং, StaticRange-এর জন্য, start_span_number অবশ্যই end_span_number এর সমান হবে। শূন্য-প্যাডিংয়ের জন্য প্রদত্ত স্প্যান, এবং স্প্যান প্রস্থের তথ্য (যদি প্রদান করা হয়) ব্যবহার করে, ExampleGen প্রদত্ত বিভক্ত প্যাটার্নে স্প্যান স্পেকটি পছন্দসই স্প্যান নম্বর দিয়ে প্রতিস্থাপন করবে। ব্যবহারের একটি উদাহরণ নীচে দেখানো হয়েছে:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
রেঞ্জ কনফিগারেশন নির্দিষ্ট তারিখগুলি প্রক্রিয়া করার জন্যও ব্যবহার করা যেতে পারে, যদি স্প্যান স্পেকের পরিবর্তে তারিখ স্পেক ব্যবহার করা হয়। উদাহরণস্বরূপ, ধরা যাক ক্যালেন্ডার তারিখ দ্বারা সংগঠিত ইনপুট ডেটা রয়েছে:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
বিশেষভাবে 2রা জানুয়ারী, 1970 তারিখে ডেটা পুনরুদ্ধার এবং প্রক্রিয়া করার জন্য, আমরা নিম্নলিখিতগুলি করি:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
কাস্টম উদাহরণ
যদি বর্তমানে উপলব্ধ ExampleGen উপাদানগুলি আপনার প্রয়োজনের সাথে খাপ খায় না, আপনি একটি কাস্টম ExampleGen তৈরি করতে পারেন, যা আপনাকে বিভিন্ন ডেটা উত্স থেকে বা বিভিন্ন ডেটা ফর্ম্যাটে পড়তে সক্ষম করবে৷
ফাইল-ভিত্তিক ExampleGen কাস্টমাইজেশন (পরীক্ষামূলক)
প্রথমে, BaseExampleGenExecutor কে একটি কাস্টম বিম PTransform সহ প্রসারিত করুন, যা আপনার ট্রেন/ইভাল ইনপুট বিভক্ত থেকে TF উদাহরণে রূপান্তর প্রদান করে। উদাহরণস্বরূপ, CsvExampleGen নির্বাহক একটি ইনপুট CSV বিভক্ত থেকে TF উদাহরণে রূপান্তর প্রদান করে।
তারপরে, CsvExampleGen কম্পোনেন্টের মতো উপরের এক্সিকিউটরের সাথে একটি কম্পোনেন্ট তৈরি করুন। বিকল্পভাবে, নিম্নে দেখানো হিসাবে আদর্শ ExampleGen উপাদানে একটি কাস্টম নির্বাহক পাস করুন।
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
এখন, আমরা এই পদ্ধতি ব্যবহার করে Avro এবং Parquet ফাইল পড়া সমর্থন করি।
অতিরিক্ত ডেটা ফরম্যাট
Apache Beam অনেকগুলি অতিরিক্ত ডেটা ফরম্যাট পড়া সমর্থন করে৷ বিম I/O ট্রান্সফর্মের মাধ্যমে। আপনি Avro উদাহরণের অনুরূপ একটি প্যাটার্ন ব্যবহার করে Beam I/O Transforms ব্যবহার করে কাস্টম ExampleGen উপাদান তৈরি করতে পারেন
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
এই লেখার মতো বর্তমানে বিম পাইথন SDK-এর জন্য সমর্থিত ফর্ম্যাট এবং ডেটা উত্সগুলির মধ্যে রয়েছে:
- আমাজন S3
- অ্যাপাচি অভ্র
- Apache Hadoop
- অ্যাপাচি কাফকা
- Apache Parquet
- Google Cloud BigQuery
- গুগল ক্লাউড বিগটেবল
- গুগল ক্লাউড ডেটাস্টোর
- Google Cloud Pub/Sub
- Google ক্লাউড স্টোরেজ (GCS)
- মঙ্গোডিবি
সর্বশেষ তালিকার জন্য Beam ডক্স চেক করুন.
ক্যোয়ারী-ভিত্তিক ExampleGen কাস্টমাইজেশন (পরীক্ষামূলক)
প্রথমে, BaseExampleGenExecutor কে একটি কাস্টম Beam PTransform সহ প্রসারিত করুন, যা বাহ্যিক ডেটা উৎস থেকে পড়ে। তারপর, QueryBasedExampleGen প্রসারিত করে একটি সাধারণ উপাদান তৈরি করুন।
এর জন্য অতিরিক্ত সংযোগ কনফিগারেশনের প্রয়োজন হতে পারে বা নাও হতে পারে। উদাহরণস্বরূপ, BigQuery নির্বাহক একটি ডিফল্ট beam.io সংযোগকারী ব্যবহার করে পাঠ করে, যা সংযোগ কনফিগারেশনের বিশদ বিবরণকে বিমূর্ত করে। প্রেস্টো নির্বাহক , ইনপুট হিসাবে একটি কাস্টম বিম পিটি ট্রান্সফর্ম এবং একটি কাস্টম সংযোগ কনফিগারেশন প্রোটোবাফ প্রয়োজন।
যদি একটি কাস্টম ExampleGen উপাদানের জন্য একটি সংযোগ কনফিগারেশন প্রয়োজন হয়, একটি নতুন protobuf তৈরি করুন এবং এটি custom_config এর মাধ্যমে পাস করুন, যা এখন একটি ঐচ্ছিক এক্সিকিউশন প্যারামিটার৷ কনফিগার করা কম্পোনেন্ট কিভাবে ব্যবহার করবেন তার একটি উদাহরণ নিচে দেওয়া হল।
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
ExampleGen ডাউনস্ট্রিম উপাদান
কাস্টম স্প্লিট কনফিগারেশন ডাউনস্ট্রিম উপাদানগুলির জন্য সমর্থিত।
StatisticsGen
ডিফল্ট আচরণ হল সমস্ত বিভাজনের জন্য পরিসংখ্যান তৈরি করা।
যেকোনো বিভাজন বাদ দিতে, StatisticsGen কম্পোনেন্টের জন্য exclude_splits সেট করুন। যেমন:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
স্কিমাজেন
ডিফল্ট আচরণ হল সমস্ত বিভাজনের উপর ভিত্তি করে একটি স্কিমা তৈরি করা।
যেকোনো বিভাজন বাদ দিতে, SchemaGen উপাদানের জন্য exclude_splits সেট করুন। যেমন:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
উদাহরণ যাচাইকারী
ডিফল্ট আচরণ হল একটি স্কিমার বিরুদ্ধে ইনপুট উদাহরণে সমস্ত বিভাজনের পরিসংখ্যান যাচাই করা।
যেকোনো বিভাজন বাদ দিতে, ExampleValidator উপাদানের জন্য exclude_splits সেট করুন। যেমন:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
রূপান্তর
ডিফল্ট আচরণ হল 'ট্রেন' বিভক্ত থেকে মেটাডেটা বিশ্লেষণ এবং উৎপন্ন করা এবং সমস্ত বিভক্তিকে রূপান্তর করা।
বিশ্লেষণ বিভাজন এবং রূপান্তর বিভাজন নির্দিষ্ট করতে, ট্রান্সফর্ম উপাদানের জন্য splits_config সেট করুন। যেমন:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
প্রশিক্ষক এবং টিউনার
ডিফল্ট আচরণ হল 'ট্রেন' বিভাজনে ট্রেন এবং 'ইভাল' বিভাজনে মূল্যায়ন।
ট্রেনের বিভাজন নির্দিষ্ট করতে এবং বিভাজনের মূল্যায়ন করতে, প্রশিক্ষক উপাদানের জন্য train_args এবং eval_args সেট করুন। যেমন:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
মূল্যায়নকারী
ডিফল্ট আচরণ হল 'eval' বিভাজনে গণনা করা মেট্রিক্স প্রদান করা।
কাস্টম বিভাজনে মূল্যায়ন পরিসংখ্যান গণনা করতে, মূল্যায়নকারী উপাদানের জন্য example_splits সেট করুন। যেমন:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
CsvExampleGen API রেফারেন্স , FileBasedExampleGen API বাস্তবায়ন এবং ImportExampleGen API রেফারেন্সে আরও বিশদ বিবরণ পাওয়া যায়।