
introduzione
Questo tutorial è progettato per presentare TensorFlow Extended (TFX) e AIPlatform Pipelines e aiutarti a imparare a creare le tue pipeline di machine learning su Google Cloud. Mostra l'integrazione con TFX, AI Platform Pipelines e Kubeflow, nonché l'interazione con TFX nei notebook Jupyter.
Alla fine di questo tutorial, avrai creato ed eseguito una pipeline ML, ospitata su Google Cloud. Sarai in grado di visualizzare i risultati di ogni esecuzione e visualizzare la discendenza degli artefatti creati.
Seguirai un tipico processo di sviluppo ML, iniziando con l'esame del set di dati e terminando con una pipeline funzionante completa. Lungo il percorso esplorerai modi per eseguire il debug e aggiornare la pipeline e misurare le prestazioni.
Set di dati sui taxi di Chicago


Stai utilizzando il set di dati Taxi Trips rilasciato dalla città di Chicago.
Puoi leggere ulteriori informazioni sul set di dati in Google BigQuery . Esplora il set di dati completo nell'interfaccia utente di BigQuery .
Obiettivo del modello: classificazione binaria
Il cliente darà una mancia più o meno del 20%?
1. Configura un progetto Google Cloud
1.a Configura il tuo ambiente su Google Cloud
Per iniziare, hai bisogno di un account Google Cloud. Se ne hai già uno, vai avanti a Crea nuovo progetto .
Vai alla console Google Cloud .
Accetta i termini e le condizioni di Google Cloud
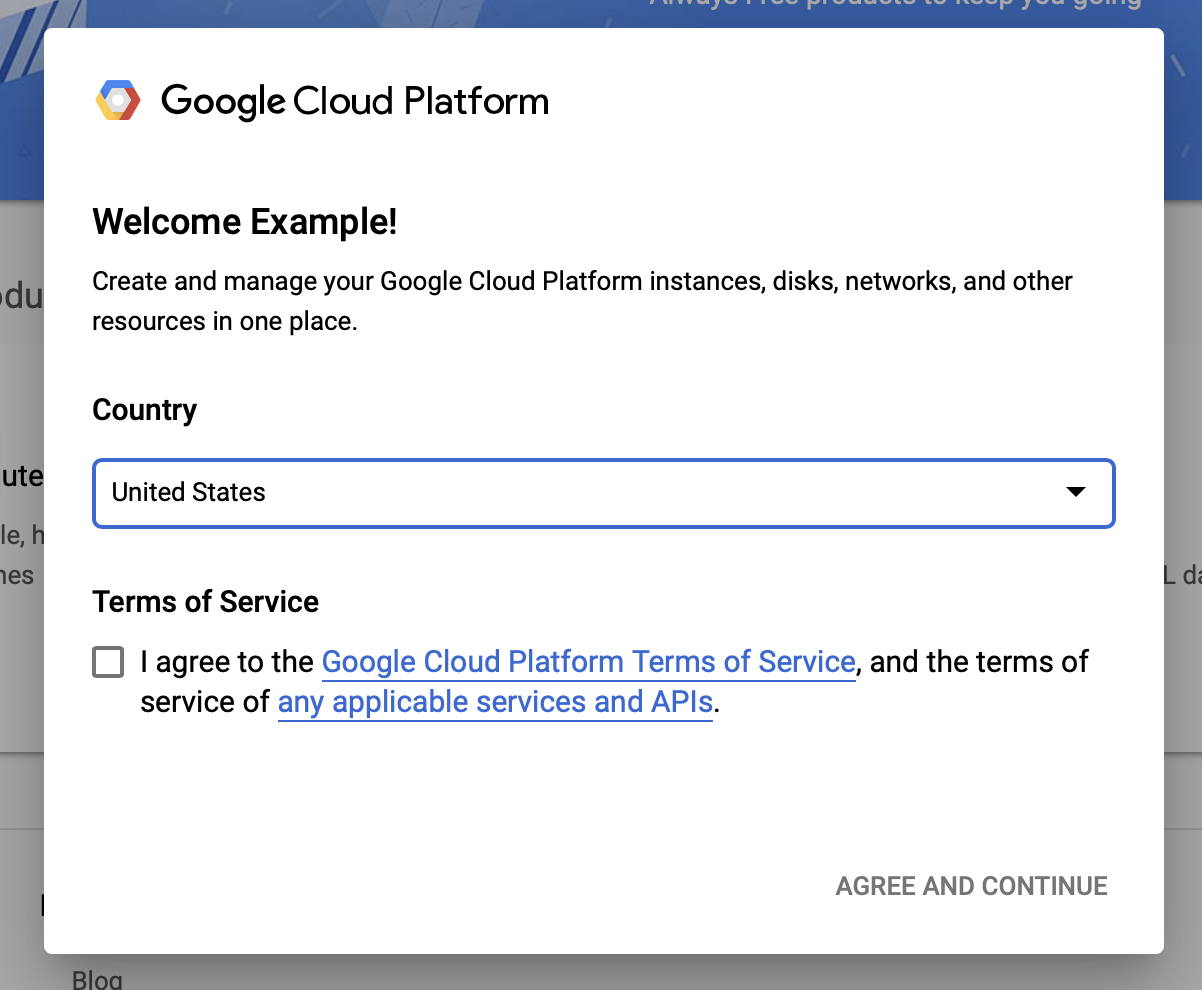
Se desideri iniziare con un account di prova gratuito, fai clic su Prova gratuitamente (o Inizia gratuitamente ).
Seleziona il tuo paese.
Accetta i termini del servizio.
Inserisci i dettagli di fatturazione.
A questo punto non ti verrà addebitato alcun costo. Se non disponi di altri progetti Google Cloud, puoi completare questo tutorial senza superare i limiti del piano gratuito di Google Cloud , che include un massimo di 8 core in esecuzione contemporaneamente.
1.b Creare un nuovo progetto.
- Dalla dashboard principale di Google Cloud , fai clic sul menu a discesa del progetto accanto all'intestazione di Google Cloud Platform e seleziona Nuovo progetto .
- Dai un nome al tuo progetto e inserisci altri dettagli del progetto
- Una volta creato un progetto, assicurati di selezionarlo dal menu a discesa del progetto.
2. Configura e distribuisci una pipeline AI Platform su un nuovo cluster Kubernetes
Vai alla pagina Cluster di pipeline AI Platform .
Nel menu di navigazione principale: ≡ > Piattaforma AI > Pipeline
Fai clic su + Nuova istanza per creare un nuovo cluster.
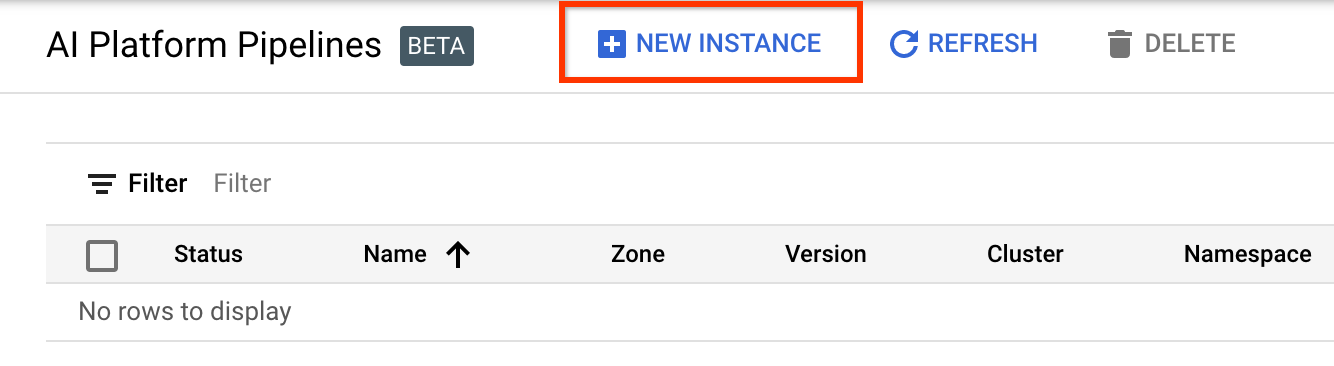
Nella pagina di panoramica delle pipeline Kubeflow , fare clic su Configura .

Fai clic su "Abilita" per abilitare l'API Kubernetes Engine
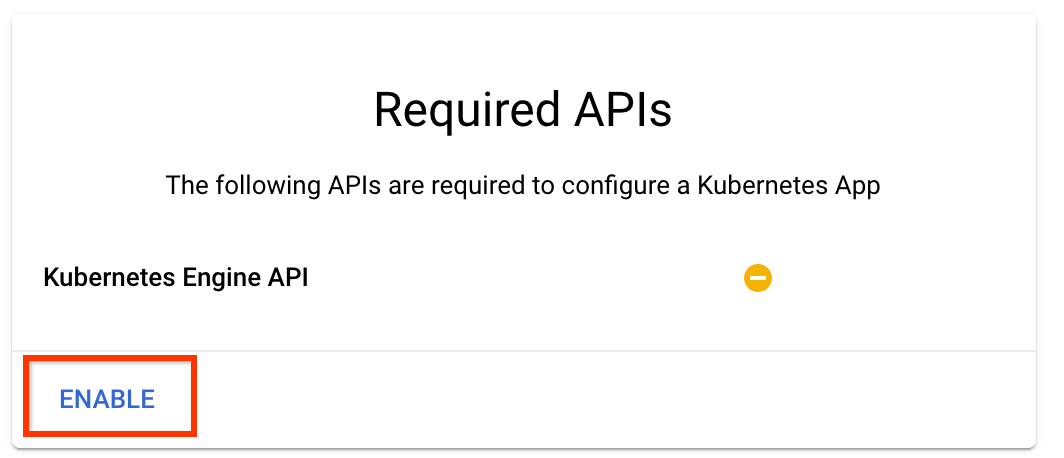
Nella pagina Distribuisci pipeline Kubeflow :
Seleziona una zona (o "regione") per il tuo cluster. È possibile impostare la rete e la sottorete, ma ai fini di questo tutorial le lasceremo come predefinite.
IMPORTANTE Seleziona la casella Consenti l'accesso alle seguenti API cloud . (Ciò è necessario affinché questo cluster possa accedere alle altre parti del tuo progetto. Se salti questo passaggio, correggerlo in seguito sarà un po' complicato.)

Fare clic su Crea nuovo cluster e attendere alcuni minuti finché il cluster non sarà stato creato. L'operazione richiederà alcuni minuti. Al termine verrà visualizzato un messaggio del tipo:
Cluster "cluster-1" creato con successo nella zona "us-central1-a".
Seleziona uno spazio dei nomi e un nome di istanza (usare le impostazioni predefinite va bene). Ai fini di questo tutorial non selezionare executor.emissary o Managedstorage.enabled .
Fare clic su Distribuisci e attendere qualche istante finché la pipeline non sarà stata distribuita. Distribuendo Kubeflow Pipelines, accetti i Termini di servizio.
3. Configura l'istanza Notebook Cloud AI Platform.
Vai alla pagina Vertex AI Workbench . La prima volta che esegui Workbench dovrai abilitare l'API Notebooks.
Nel menu di navigazione principale: ≡ -> Vertex AI -> Workbench
Se richiesto, abilita l'API Compute Engine.
Crea un nuovo notebook con TensorFlow Enterprise 2.7 (o versione successiva) installato.
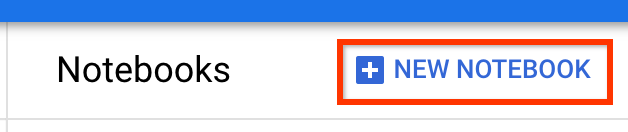
Nuovo notebook -> TensorFlow Enterprise 2.7 -> Senza GPU
Seleziona una regione e una zona e assegna un nome all'istanza del notebook.
Per rimanere entro i limiti del piano gratuito, potrebbe essere necessario modificare qui le impostazioni predefinite per ridurre il numero di vCPU disponibili per questa istanza da 4 a 2:
- Seleziona Opzioni avanzate nella parte inferiore del modulo Nuovo blocco appunti .
In Configurazione macchina potresti voler selezionare una configurazione con 1 o 2 vCPU se hai bisogno di rimanere nel livello gratuito.
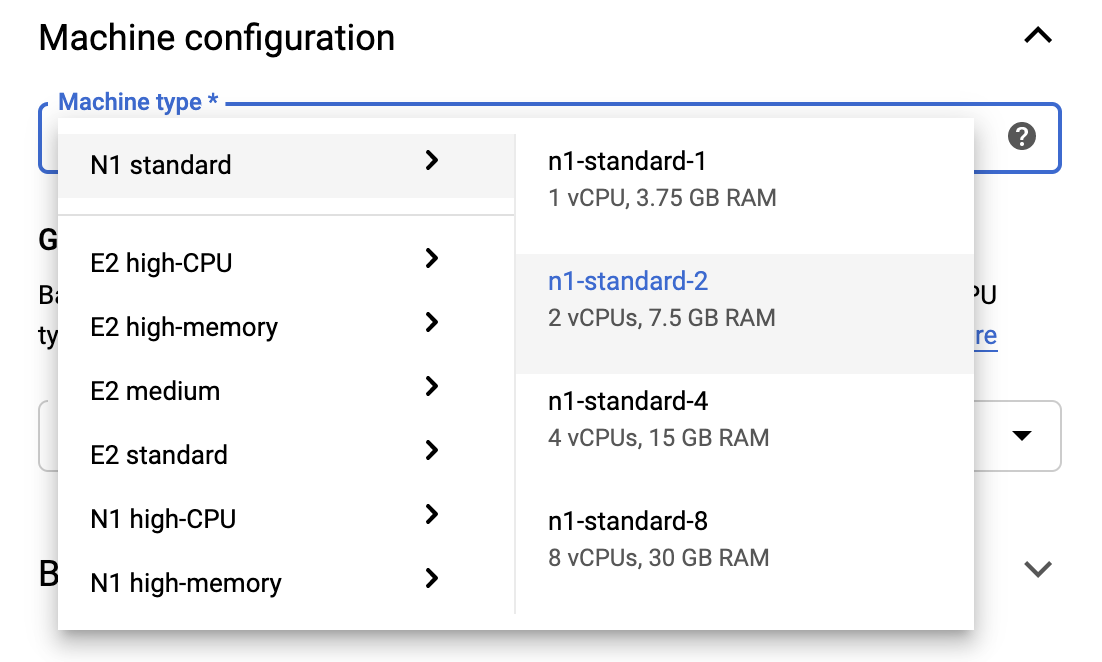
Attendi la creazione del nuovo notebook, quindi fai clic su Abilita API Notebook
4. Avviare il Notebook introduttivo
Vai alla pagina Cluster di pipeline AI Platform .
Nel menu di navigazione principale: ≡ -> Piattaforma AI -> Pipeline
Nella riga relativa al cluster che stai utilizzando in questo tutorial, fai clic su Open Pipelines Dashboard .

Nella pagina Nozioni di base , fai clic su Apri un notebook Cloud AI Platform su Google Cloud .

Seleziona l'istanza Notebook che stai utilizzando per questo tutorial e poi Continua , quindi Conferma .
5. Continua a lavorare sul Notebook
Installare
Il notebook introduttivo inizia installando TFX e Kubeflow Pipelines (KFP) nella VM su cui è in esecuzione Jupyter Lab.
Quindi controlla quale versione di TFX è installata, esegue un'importazione e imposta e stampa l'ID progetto:

Connettiti con i tuoi servizi Google Cloud
La configurazione della pipeline richiede l'ID progetto, che puoi ottenere tramite il notebook e impostare come variabile ambientale.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
Ora imposta l'endpoint del cluster KFP.
Questo può essere trovato dall'URL del dashboard Pipelines. Vai alla dashboard della pipeline Kubeflow e guarda l'URL. L'endpoint è tutto ciò che si trova nell'URL che inizia con https:// fino a googleusercontent.com incluso.
ENDPOINT='' # Enter YOUR ENDPOINT here.
Il notebook imposta quindi un nome univoco per l'immagine Docker personalizzata:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. Copia un modello nella directory del progetto
Modifica la cella successiva del notebook per impostare un nome per la pipeline. In questo tutorial utilizzeremo my_pipeline .
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
Il notebook utilizza quindi la CLI tfx per copiare il modello di pipeline. Questo tutorial utilizza il set di dati Chicago Taxi per eseguire la classificazione binaria, quindi il modello imposta il modello su taxi :
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
Il notebook modifica quindi il contesto CWD nella directory del progetto:
%cd {PROJECT_DIR}
Sfoglia i file della pipeline
Sul lato sinistro del notebook Cloud AI Platform, dovresti vedere un browser di file. Dovrebbe esserci una directory con il nome della pipeline ( my_pipeline ). Aprilo e visualizza i file. (Sarai in grado di aprirli e modificarli anche dall'ambiente del notebook.)
# You can also list the files from the shellls
Il comando tfx template copy riportato sopra ha creato un'impalcatura di base di file che costruisce una pipeline. Questi includono codici sorgente Python, dati di esempio e notebook Jupyter. Questi sono pensati per questo particolare esempio. Per le tue pipeline questi sarebbero i file di supporto richiesti dalla tua pipeline.
Ecco una breve descrizione dei file Python.
-
pipeline: questa directory contiene la definizione della pipeline-
configs.py: definisce le costanti comuni per i corridori della pipeline -
pipeline.py: definisce i componenti TFX e una pipeline
-
-
models: questa directory contiene le definizioni dei modelli ML.-
features.pyfeatures_test.py: definisce le caratteristiche del modello -
preprocessing.py/preprocessing_test.py— definisce i lavori di preelaborazione utilizzandotf::Transform -
estimator: questa directory contiene un modello basato sullo stimatore.-
constants.py— definisce le costanti del modello -
model.py/model_test.py: definisce il modello DNN utilizzando lo stimatore TF
-
-
keras: questa directory contiene un modello basato su Keras.-
constants.py— definisce le costanti del modello -
model.py/model_test.py: definisce il modello DNN utilizzando Keras
-
-
-
beam_runner.py/kubeflow_runner.py: definisce i runner per ciascun motore di orchestrazione
7. Esegui la tua prima pipeline TFX su Kubeflow
Il notebook eseguirà la pipeline utilizzando il comando CLI tfx run .
Connettiti allo spazio di archiviazione
Le pipeline in esecuzione creano artefatti che devono essere archiviati in ML-Metadata . Gli artefatti si riferiscono ai payload, ovvero file che devono essere archiviati in un file system o in un archivio a blocchi. Per questo tutorial utilizzeremo GCS per archiviare i nostri payload di metadati, utilizzando il bucket creato automaticamente durante la configurazione. Il suo nome sarà <your-project-id>-kubeflowpipelines-default .
Creare la pipeline
Il notebook caricherà i nostri dati di esempio nel bucket GCS in modo da poterli utilizzare nella nostra pipeline in un secondo momento.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv
Il notebook utilizza quindi il comando tfx pipeline create per creare la pipeline.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
Durante la creazione di una pipeline, verrà generato Dockerfile per creare un'immagine Docker. Non dimenticare di aggiungere questi file al tuo sistema di controllo del codice sorgente (ad esempio, git) insieme ad altri file sorgente.
Esegui la pipeline
Il notebook utilizza quindi il comando tfx run create per avviare un'esecuzione della pipeline. Vedrai questa esecuzione elencata anche in Esperimenti nella dashboard delle pipeline Kubeflow.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}
Puoi visualizzare la tua pipeline dalla dashboard delle pipeline Kubeflow.
8. Convalida i tuoi dati
Il primo compito in qualsiasi progetto di data science o ML è comprendere e pulire i dati.
- Comprendere i tipi di dati per ciascuna funzionalità
- Cerca anomalie e valori mancanti
- Comprendere le distribuzioni per ciascuna funzionalità
Componenti


- EsempioGen acquisisce e divide il set di dati di input.
- StatisticsGen calcola le statistiche per il set di dati.
- SchemaGen SchemaGen esamina le statistiche e crea uno schema di dati.
- EsempioValidator cerca anomalie e valori mancanti nel set di dati.
Nell'editor di file del laboratorio Jupyter:
In pipeline / pipeline.py , decommenta le righe che aggiungono questi componenti alla tua pipeline:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( ExampleGen era già abilitato quando i file modello sono stati copiati.)
Aggiorna la pipeline ed eseguila nuovamente
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Controlla la conduttura
Per Kubeflow Orchestrator, visita il dashboard KFP e trova gli output della pipeline nella pagina per l'esecuzione della pipeline. Fai clic sulla scheda "Esperimenti" a sinistra e su "Tutte le esecuzioni" nella pagina Esperimenti. Dovresti essere in grado di trovare l'esecuzione con il nome della tua pipeline.
Esempio più avanzato
L'esempio presentato qui è in realtà pensato solo per iniziare. Per un esempio più avanzato, consulta il TensorFlow Data Validation Colab .
Per ulteriori informazioni sull'utilizzo di TFDV per esplorare e convalidare un set di dati, vedere gli esempi su tensorflow.org .
9. Ingegneria delle funzionalità
Puoi aumentare la qualità predittiva dei tuoi dati e/o ridurre la dimensionalità con l'ingegneria delle funzionalità.
- Croci caratteristiche
- Vocabolari
- Incorporamenti
- PCA
- Codifica categoriale
Uno dei vantaggi dell'utilizzo di TFX è che scriverai il codice di trasformazione una volta e le trasformazioni risultanti saranno coerenti tra formazione e pubblicazione.
Componenti

- Transform esegue la progettazione delle funzionalità sul set di dati.
Nell'editor di file del laboratorio Jupyter:
In pipeline / pipeline.py , trova e rimuovi il commento dalla riga che aggiunge Transform alla pipeline.
# components.append(transform)
Aggiorna la pipeline ed eseguila nuovamente
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Controllare gli output della pipeline
Per Kubeflow Orchestrator, visita il dashboard KFP e trova gli output della pipeline nella pagina per l'esecuzione della pipeline. Fai clic sulla scheda "Esperimenti" a sinistra e su "Tutte le esecuzioni" nella pagina Esperimenti. Dovresti essere in grado di trovare l'esecuzione con il nome della tua pipeline.
Esempio più avanzato
L'esempio presentato qui è in realtà pensato solo per iniziare. Per un esempio più avanzato, consulta TensorFlow Transform Colab .
10. Formazione
Addestra un modello TensorFlow con i tuoi dati belli, puliti e trasformati.
- Includere le trasformazioni del passaggio precedente in modo che vengano applicate in modo coerente
- Salva i risultati come SavedModel per la produzione
- Visualizza ed esplora il processo di formazione utilizzando TensorBoard
- Salva anche un EvalSavedModel per l'analisi delle prestazioni del modello
Componenti
- Il formatore addestra un modello TensorFlow.
Nell'editor di file del laboratorio Jupyter:
In pipeline / pipeline.py , trova e rimuovi il commento che aggiunge Trainer alla pipeline:
# components.append(trainer)
Aggiorna la pipeline ed eseguila nuovamente
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Controllare gli output della pipeline
Per Kubeflow Orchestrator, visita il dashboard KFP e trova gli output della pipeline nella pagina per l'esecuzione della pipeline. Fai clic sulla scheda "Esperimenti" a sinistra e su "Tutte le esecuzioni" nella pagina Esperimenti. Dovresti essere in grado di trovare l'esecuzione con il nome della tua pipeline.
Esempio più avanzato
L'esempio presentato qui è in realtà pensato solo per iniziare. Per un esempio più avanzato, consulta il tutorial TensorBoard .
11. Analisi delle prestazioni del modello
Comprendere qualcosa di più dei semplici parametri di livello superiore.
- Gli utenti sperimentano le prestazioni del modello solo per le loro query
- Le scarse prestazioni su porzioni di dati possono essere nascoste da metriche di livello superiore
- L’equità del modello è importante
- Spesso i sottoinsiemi chiave di utenti o dati sono molto importanti e possono essere piccoli
- Prestazioni in condizioni critiche ma insolite
- Performance per un pubblico chiave come gli influencer
- Se stai sostituendo un modello attualmente in produzione, assicurati innanzitutto che quello nuovo sia migliore
Componenti
- Il valutatore esegue un'analisi approfondita dei risultati della formazione.
Nell'editor di file del laboratorio Jupyter:
In pipeline / pipeline.py , trova e rimuovi il commento dalla riga che aggiunge Evaluator alla pipeline:
components.append(evaluator)
Aggiorna la pipeline ed eseguila nuovamente
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Controllare gli output della pipeline
Per Kubeflow Orchestrator, visita il dashboard KFP e trova gli output della pipeline nella pagina per l'esecuzione della pipeline. Fai clic sulla scheda "Esperimenti" a sinistra e su "Tutte le esecuzioni" nella pagina Esperimenti. Dovresti essere in grado di trovare l'esecuzione con il nome della tua pipeline.
12. Servire il modello
Se il nuovo modello è pronto, fallo così.
- Pusher distribuisce SavedModels in posizioni note
Gli obiettivi di distribuzione ricevono nuovi modelli da località ben note
- Servizio TensorFlow
- TensorFlow Lite
- TensorFlowJS
- Hub TensorFlow
Componenti
- Pusher distribuisce il modello su un'infrastruttura di servizio.
Nell'editor di file del laboratorio Jupyter:
In pipeline / pipeline.py , trova e rimuovi il commento dalla riga che aggiunge Pusher alla pipeline:
# components.append(pusher)
Controllare gli output della pipeline
Per Kubeflow Orchestrator, visita il dashboard KFP e trova gli output della pipeline nella pagina per l'esecuzione della pipeline. Fai clic sulla scheda "Esperimenti" a sinistra e su "Tutte le esecuzioni" nella pagina Esperimenti. Dovresti essere in grado di trovare l'esecuzione con il nome della tua pipeline.
Obiettivi di distribuzione disponibili
Ora hai addestrato e convalidato il tuo modello e il tuo modello è ora pronto per la produzione. Ora puoi distribuire il tuo modello su qualsiasi destinazione di distribuzione TensorFlow, tra cui:
- TensorFlow Serving , per servire il tuo modello su un server o una server farm ed elaborare richieste di inferenza REST e/o gRPC.
- TensorFlow Lite , per includere il tuo modello in un'applicazione mobile nativa Android o iOS oppure in un'applicazione Raspberry Pi, IoT o microcontroller.
- TensorFlow.js , per eseguire il modello in un browser Web o in un'applicazione Node.JS.
Esempi più avanzati
L'esempio presentato sopra è in realtà pensato solo per iniziare. Di seguito sono riportati alcuni esempi di integrazione con altri servizi Cloud.
Considerazioni sulle risorse di Kubeflow Pipelines
A seconda dei requisiti del carico di lavoro, la configurazione predefinita per la distribuzione di Kubeflow Pipelines potrebbe soddisfare o meno le tue esigenze. Puoi personalizzare le configurazioni delle risorse utilizzando pipeline_operator_funcs nella chiamata a KubeflowDagRunnerConfig .
pipeline_operator_funcs è un elenco di elementi OpFunc , che trasforma tutte le istanze ContainerOp generate nella specifica della pipeline KFP compilata da KubeflowDagRunner .
Ad esempio, per configurare la memoria possiamo usare set_memory_request per dichiarare la quantità di memoria necessaria. Un modo tipico per farlo è creare un wrapper per set_memory_request e usarlo per aggiungerlo all'elenco delle pipeline OpFunc s:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
Funzioni simili di configurazione delle risorse includono:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
Prova BigQueryExampleGen
BigQuery è un data warehouse sul cloud serverless, altamente scalabile ed economico. BigQuery può essere utilizzato come fonte per esempi di formazione in TFX. In questo passaggio aggiungeremo BigQueryExampleGen alla pipeline.
Nell'editor di file del laboratorio Jupyter:
Fare doppio clic per aprire pipeline.py . Commenta CsvExampleGen e rimuovi il commento dalla riga che crea un'istanza di BigQueryExampleGen . È inoltre necessario rimuovere il commento dall'argomento query della funzione create_pipeline .
Dobbiamo specificare quale progetto GCP utilizzare per BigQuery e questo viene fatto impostando --project in beam_pipeline_args durante la creazione di una pipeline.
Fare doppio clic per aprire configs.py . Rimuovere il commento dalla definizione di BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS e BIG_QUERY_QUERY . Dovresti sostituire l'ID progetto e il valore della regione in questo file con i valori corretti per il tuo progetto GCP.
Cambia la directory di un livello superiore. Fare clic sul nome della directory sopra l'elenco dei file. Il nome della directory è il nome della pipeline che è my_pipeline se non hai modificato il nome della pipeline.
Fare doppio clic per aprire kubeflow_runner.py . Rimuovere il commento da due argomenti, query e beam_pipeline_args , per la funzione create_pipeline .
Ora la pipeline è pronta per utilizzare BigQuery come origine di esempio. Aggiorna la pipeline come prima e crea una nuova esecuzione come abbiamo fatto nei passaggi 5 e 6.
Aggiorna la pipeline ed eseguila nuovamente
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Prova Dataflow
Diversi componenti TFX utilizzano Apache Beam per implementare pipeline parallele di dati e ciò significa che puoi distribuire carichi di lavoro di elaborazione dati utilizzando Google Cloud Dataflow . In questo passaggio, imposteremo l'orchestratore Kubeflow per utilizzare Dataflow come back-end di elaborazione dati per Apache Beam.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
Fare doppio clic pipeline per cambiare directory e fare doppio clic per aprire configs.py . Rimuovere il commento dalla definizione di GOOGLE_CLOUD_REGION e DATAFLOW_BEAM_PIPELINE_ARGS .
Cambia la directory di un livello superiore. Fare clic sul nome della directory sopra l'elenco dei file. Il nome della directory è il nome della pipeline che è my_pipeline se non hai cambiato.
Fare doppio clic per aprire kubeflow_runner.py . Decommentare beam_pipeline_args . (Assicurati inoltre di commentare l'attuale beam_pipeline_args che hai aggiunto nel passaggio 7.)
Aggiorna la pipeline ed eseguila nuovamente
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Puoi trovare i tuoi job Dataflow in Dataflow in Cloud Console .
Prova la formazione e la previsione della piattaforma Cloud AI con KFP
TFX interagisce con diversi servizi GCP gestiti, come Cloud AI Platform for Training and Prediction . Puoi impostare il componente Trainer per utilizzare Cloud AI Platform Training, un servizio gestito per l'addestramento dei modelli ML. Inoltre, quando il tuo modello è stato creato e pronto per essere servito, puoi inviare il modello alla previsione della piattaforma Cloud AI per la pubblicazione. In questo passaggio, imposteremo i nostri componenti Trainer e Pusher per utilizzare i servizi Cloud AI Platform.
Prima di modificare i file, potresti dover abilitare l'API AI Platform Training & Prediction .
Fare doppio clic pipeline per cambiare directory e fare doppio clic per aprire configs.py . Rimuovere il commento dalla definizione di GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS e GCP_AI_PLATFORM_SERVING_ARGS . Utilizzeremo la nostra immagine del contenitore personalizzata per addestrare un modello in Cloud AI Platform Training, quindi dovremmo impostare masterConfig.imageUri in GCP_AI_PLATFORM_TRAINING_ARGS sullo stesso valore di CUSTOM_TFX_IMAGE sopra.
Cambia la directory di un livello superiore e fai doppio clic per aprire kubeflow_runner.py . Rimuovere il commento ai_platform_training_args e ai_platform_serving_args .
Aggiorna la pipeline ed eseguila nuovamente
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Puoi trovare i tuoi lavori di formazione in Lavori sulla piattaforma Cloud AI . Se la pipeline è stata completata correttamente, puoi trovare il tuo modello in Modelli della piattaforma Cloud AI .
14. Usa i tuoi dati
In questo tutorial hai creato una pipeline per un modello utilizzando il set di dati Chicago Taxi. Ora prova a inserire i tuoi dati nella pipeline. I tuoi dati possono essere archiviati ovunque la pipeline possa accedervi, inclusi Google Cloud Storage, BigQuery o file CSV.
È necessario modificare la definizione della pipeline per adattarla ai dati.
Se i tuoi dati sono archiviati in file
- Modifica
DATA_PATHinkubeflow_runner.py, indicando la posizione.
Se i tuoi dati sono archiviati in BigQuery
- Modifica
BIG_QUERY_QUERYin configs.py nella tua istruzione di query. - Aggiungi funzionalità in
models/features.py. - Modifica
models/preprocessing.pyper trasformare i dati di input per l'addestramento . - Modifica
models/keras/model.pyemodels/keras/constants.pyper descrivere il tuo modello ML .
Ulteriori informazioni su Formatore
Consulta la guida ai componenti del formatore per ulteriori dettagli sulle pipeline di formazione.
Pulire
Per ripulire tutte le risorse Google Cloud utilizzate in questo progetto, puoi eliminare il progetto Google Cloud utilizzato per il tutorial.
In alternativa, puoi ripulire le singole risorse visitando ciascuna console: - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine