
Este tutorial le muestra cómo usar TensorFlow Transform (la biblioteca tf.Transform ) para implementar el preprocesamiento de datos para el aprendizaje automático (ML). La biblioteca tf.Transform para TensorFlow le permite definir transformaciones de datos tanto a nivel de instancia como de paso completo a través de canalizaciones de preprocesamiento de datos. Estas canalizaciones se ejecutan de manera eficiente con Apache Beam y crean como subproductos un gráfico de TensorFlow para aplicar las mismas transformaciones durante la predicción que cuando se sirve el modelo.
Este tutorial proporciona un ejemplo de un extremo a otro utilizando Dataflow como ejecutor para Apache Beam. Se supone que está familiarizado con BigQuery , Dataflow, Vertex AI y la API TensorFlow Keras . También se supone que tiene cierta experiencia en el uso de Jupyter Notebooks, como con Vertex AI Workbench .
Este tutorial también supone que está familiarizado con los conceptos de tipos, desafíos y opciones de preprocesamiento en Google Cloud, como se describe en Preprocesamiento de datos para ML: opciones y recomendaciones .
Objetivos
- Implemente la canalización de Apache Beam utilizando la biblioteca
tf.Transform. - Ejecute la canalización en Dataflow.
- Implemente el modelo TensorFlow usando la biblioteca
tf.Transform. - Entrene y utilice el modelo para predicciones.
Costos
Este tutorial utiliza los siguientes componentes facturables de Google Cloud:
Para estimar el costo de ejecutar este tutorial, suponiendo que utilice todos los recursos durante un día completo, utilice la calculadora de precios preconfigurada.
Antes de comenzar
En la consola de Google Cloud, en la página de selección de proyectos, selecciona o crea un proyecto de Google Cloud .
Asegúrese de que la facturación esté habilitada para su proyecto de nube. Aprenda cómo verificar si la facturación está habilitada en un proyecto .
Habilite las API de Dataflow, Vertex AI y Notebooks. Habilitar las API
Cuadernos Jupyter para esta solución
Los siguientes cuadernos de Jupyter muestran el ejemplo de implementación:
- El cuaderno 1 cubre el preprocesamiento de datos. Los detalles se proporcionan más adelante en la sección Implementación de la canalización de Apache Beam .
- El cuaderno 2 cubre el entrenamiento de modelos. Los detalles se proporcionan en la sección Implementación del modelo TensorFlow más adelante.
En las siguientes secciones, clonará estos cuadernos y luego los ejecutará para aprender cómo funciona el ejemplo de implementación.
Lanzar una instancia de cuadernos administrada por el usuario
En la consola de Google Cloud, vaya a la página Vertex AI Workbench .
En la pestaña Libretas administradas por el usuario , haga clic en +Nueva libreta .
Seleccione TensorFlow Enterprise 2.8 (con LTS) sin GPU para el tipo de instancia.
Haga clic en Crear .
Después de crear el cuaderno, espere a que el proxy de JupyterLab termine de inicializarse. Cuando esté listo, se muestra Open JupyterLab junto al nombre del cuaderno.
Clonar el cuaderno
En la pestaña Cuadernos administrados por el usuario , junto al nombre del cuaderno, haga clic en Abrir JupyterLab . La interfaz de JupyterLab se abre en una nueva pestaña.
Si JupyterLab muestra un cuadro de diálogo Compilación recomendada , haga clic en Cancelar para rechazar la compilación sugerida.
En la pestaña Iniciador , haga clic en Terminal .
En la ventana de la terminal, clona el cuaderno:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Implementar la canalización Apache Beam
Esta sección y la siguiente Ejecutar la canalización en Dataflow brindan una descripción general y un contexto para el Cuaderno 1. El cuaderno proporciona un ejemplo práctico para describir cómo usar la biblioteca tf.Transform para preprocesar datos. Este ejemplo utiliza el conjunto de datos Natality, que se utiliza para predecir el peso de los bebés en función de varios datos de entrada. Los datos se almacenan en la tabla pública de natalidad de BigQuery.
Ejecutar el cuaderno 1
En la interfaz de JupyterLab, haga clic en Archivo > Abrir desde ruta y luego ingrese la siguiente ruta:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbHaga clic en Editar > Borrar todas las salidas .
En la sección Instalar paquetes requeridos , ejecute la primera celda para ejecutar el comando
pip install apache-beam.La última parte del resultado es la siguiente:
Successfully installed ...Puede ignorar los errores de dependencia en la salida. No es necesario reiniciar el kernel todavía.
Ejecute la segunda celda para ejecutar el comando
pip install tensorflow-transform. La última parte del resultado es la siguiente:Successfully installed ... Note: you may need to restart the kernel to use updated packages.Puede ignorar los errores de dependencia en la salida.
Haga clic en Kernel > Reiniciar kernel .
Ejecute las celdas en las secciones Confirmar los paquetes instalados y Crear setup.py para instalar paquetes en contenedores de Dataflow .
En la sección Establecer indicadores globales , junto a
PROJECTyBUCKET, reemplaceyour-projectcon su ID de proyecto en la nube y luego ejecute la celda.Ejecute todas las celdas restantes hasta la última celda del cuaderno. Para obtener información sobre qué hacer en cada celda, consulte las instrucciones en el cuaderno.
Descripción general del oleoducto
En el ejemplo del cuaderno, Dataflow ejecuta la canalización tf.Transform a escala para preparar los datos y producir los artefactos de transformación. Las secciones posteriores de este documento describen las funciones que realizan cada paso del proceso. Los pasos generales del proceso son los siguientes:
- Leer datos de entrenamiento de BigQuery.
- Analice y transforme datos de entrenamiento utilizando la biblioteca
tf.Transform. - Escribe datos de entrenamiento transformados en Cloud Storage en formato TFRecord .
- Leer datos de evaluación de BigQuery.
- Transforme los datos de evaluación utilizando el gráfico
transform_fnproducido en el paso 2. - Escribe datos de entrenamiento transformados en Cloud Storage en formato TFRecord.
- Escribe artefactos de transformación en Cloud Storage que se usarán más adelante para crear y exportar el modelo.
El siguiente ejemplo muestra el código Python para la canalización general. Las secciones siguientes proporcionan explicaciones y listados de códigos para cada paso.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
Leer datos de entrenamiento sin procesar de BigQuery
El primer paso es leer los datos de entrenamiento sin procesar de BigQuery usando la función read_from_bq . Esta función devuelve un objeto raw_dataset extraído de BigQuery. Pasas un valor data_size y pasas un valor step de train o eval . La consulta de origen de BigQuery se construye mediante la función get_source_query , como se muestra en el siguiente ejemplo:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
Antes de realizar el preprocesamiento tf.Transform , es posible que deba realizar el procesamiento típico basado en Apache Beam, incluido el procesamiento de mapas, filtros, grupos y ventanas. En el ejemplo, el código limpia los registros leídos de BigQuery mediante el método beam.Map(prep_bq_row) , donde prep_bq_row es una función personalizada. Esta función personalizada convierte el código numérico de una característica categórica en etiquetas legibles por humanos.
Además, para usar la biblioteca tf.Transform para analizar y transformar el objeto raw_data extraído de BigQuery, debes crear un objeto raw_dataset , que es una tupla de objetos raw_data y raw_metadata . El objeto raw_metadata se crea utilizando la función create_raw_metadata , de la siguiente manera:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
Cuando ejecuta la celda en el cuaderno que sigue inmediatamente a la celda que define este método, se muestra el contenido del objeto raw_metadata.schema . Incluye las siguientes columnas:
-
gestation_weeks(tipo:FLOAT) -
is_male(tipo:BYTES) -
mother_age(tipo:FLOAT) -
mother_race(tipo:BYTES) -
plurality(tipo:FLOAT) -
weight_pounds(tipo:FLOAT)
Transforme los datos de entrenamiento sin procesar
Imagine que desea aplicar transformaciones de preprocesamiento típicas a las características sin procesar de entrada de los datos de entrenamiento para prepararlos para ML. Estas transformaciones incluyen operaciones de paso completo y de nivel de instancia, como se muestra en la siguiente tabla:
| Característica de entrada | Transformación | Estadísticas necesarias | Tipo | Característica de salida |
|---|---|---|---|---|
weight_pound | Ninguno | Ninguno | N / A | weight_pound |
mother_age | Normalizar | media, var | pase completo | mother_age_normalized |
mother_age | Bucketización de igual tamaño | cuantiles | pase completo | mother_age_bucketized |
mother_age | Calcular el registro | Ninguno | nivel de instancia | mother_age_log |
plurality | Indique si se trata de bebés únicos o múltiples | Ninguno | nivel de instancia | is_multiple |
is_multiple | Convertir valores nominales a índice numérico | vocabulario | pase completo | is_multiple_index |
gestation_weeks | Escala entre 0 y 1 | mínimo, máximo | pase completo | gestation_weeks_scaled |
mother_race | Convertir valores nominales a índice numérico | vocabulario | pase completo | mother_race_index |
is_male | Convertir valores nominales a índice numérico | vocabulario | pase completo | is_male_index |
Estas transformaciones se implementan en una función preprocess_fn , que espera un diccionario de tensores ( input_features ) y devuelve un diccionario de características procesadas ( output_features ).
El siguiente código muestra la implementación de la función preprocess_fn , utilizando las API de transformación de paso completo tf.Transform (con el prefijo tft. ) y TensorFlow (con el prefijo tf. ) a nivel de instancia:
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
El marco tf.Transform tiene varias otras transformaciones además de las del ejemplo anterior, incluidas las que se enumeran en la siguiente tabla:
| Transformación | Se aplica a | Descripción |
|---|---|---|
scale_by_min_max | Funciones numéricas | Escala una columna numérica al rango [ output_min , output_max ] |
scale_to_0_1 | Funciones numéricas | Devuelve una columna que es la columna de entrada escalada para tener un rango [ 0 , 1 ] |
scale_to_z_score | Funciones numéricas | Devuelve una columna estandarizada con media 0 y varianza 1 |
tfidf | Características del texto | Asigna los términos en x a su frecuencia de términos * frecuencia inversa del documento |
compute_and_apply_vocabulary | Características categóricas | Genera un vocabulario para una característica categórica y lo asigna a un número entero con este vocabulario |
ngrams | Características del texto | Crea un SparseTensor de n-gramas |
hash_strings | Características categóricas | Hashes cadenas en cubos |
pca | Funciones numéricas | Calcula PCA en el conjunto de datos utilizando covarianza sesgada |
bucketize | Funciones numéricas | Devuelve una columna agrupada en cubos de igual tamaño (basada en cuantiles), con un índice de cubo asignado a cada entrada |
Para aplicar las transformaciones implementadas en la función preprocess_fn al objeto raw_train_dataset producido en el paso anterior de la canalización, se utiliza el método AnalyzeAndTransformDataset . Este método espera el objeto raw_dataset como entrada, aplica la función preprocess_fn y produce el objeto transformed_dataset y el gráfico transform_fn . El siguiente código ilustra este procesamiento:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
Las transformaciones se aplican a los datos sin procesar en dos fases: la fase de análisis y la fase de transformación. La Figura 3 más adelante en este documento muestra cómo el método AnalyzeAndTransformDataset se descompone en el método AnalyzeDataset y el método TransformDataset .
La fase de análisis
En la fase de análisis, los datos de entrenamiento sin procesar se analizan en un proceso completo para calcular las estadísticas necesarias para las transformaciones. Esto incluye calcular la media, la varianza, el mínimo, el máximo, los cuantiles y el vocabulario. El proceso de análisis espera un conjunto de datos sin procesar (datos sin procesar más metadatos sin procesar) y produce dos resultados:
-
transform_fn: un gráfico de TensorFlow que contiene las estadísticas calculadas de la fase de análisis y la lógica de transformación (que utiliza las estadísticas) como operaciones a nivel de instancia. Como se analiza más adelante en Guardar el gráfico , el gráficotransform_fnse guarda para adjuntarlo a la funciónserving_fndel modelo. Esto hace posible aplicar la misma transformación a los puntos de datos de predicción en línea. -
transform_metadata: un objeto que describe el esquema esperado de los datos después de la transformación.
La fase de análisis se ilustra en el siguiente diagrama, figura 1:

tf.Transform . Los analizadores tf.Transform incluyen min , max , sum , size , mean , var , covariance , quantiles , vocabulary y pca .
La fase de transformación
En la fase de transformación, el gráfico transform_fn que se produce en la fase de análisis se utiliza para transformar los datos de entrenamiento sin procesar en un proceso a nivel de instancia para producir los datos de entrenamiento transformados. Los datos de entrenamiento transformados se emparejan con los metadatos transformados (producidos por la fase de análisis) para producir el conjunto de datos transformed_train_dataset .
La fase de transformación se ilustra en el siguiente diagrama, figura 2:

tf.Transform . Para preprocesar las funciones, llama a las transformaciones tensorflow_transform requeridas (importadas como tft en el código) en tu implementación de la función preprocess_fn . Por ejemplo, cuando llama a las operaciones tft.scale_to_z_score , la biblioteca tf.Transform traduce esta llamada a función en analizadores de media y varianza, calcula las estadísticas en la fase de análisis y luego aplica estas estadísticas para normalizar la característica numérica en la fase de transformación. Todo esto se hace automáticamente llamando al método AnalyzeAndTransformDataset(preprocess_fn) .
La entidad transformed_metadata.schema producida por esta llamada incluye las siguientes columnas:
-
gestation_weeks_scaled(tipo:FLOAT) -
is_male_index(tipo:INT, is_categorical:True) -
is_multiple_index(tipo:INT, is_categorical:True) -
mother_age_bucketized(tipo:INT, is_categorical:True) -
mother_age_log(tipo:FLOAT) -
mother_age_normalized(tipo:FLOAT) -
mother_race_index(tipo:INT, is_categorical:True) -
weight_pounds(tipo:FLOAT)
Como se explica en Operaciones de preprocesamiento en la primera parte de esta serie, la transformación de características convierte características categóricas en una representación numérica. Después de la transformación, las características categóricas se representan mediante valores enteros. En la entidad transformed_metadata.schema , el indicador is_categorical para columnas de tipo INT indica si la columna representa una característica categórica o una característica numérica verdadera.
Escribir datos de entrenamiento transformados
Después de que los datos de entrenamiento se preprocesen con la función preprocess_fn a través de las fases de análisis y transformación, puede escribir los datos en un receptor para usarlos para entrenar el modelo de TensorFlow. Cuando ejecutas la canalización de Apache Beam usando Dataflow, el receptor es Cloud Storage. De lo contrario, el sumidero es el disco local. Aunque puede escribir los datos como un archivo CSV de archivos formateados de ancho fijo, el formato de archivo recomendado para los conjuntos de datos de TensorFlow es el formato TFRecord. Este es un formato binario simple orientado a registros que consta de mensajes de búfer de protocolo tf.train.Example .
Cada registro tf.train.Example contiene una o más funciones. Estos se convierten en tensores cuando se introducen en el modelo para su entrenamiento. El siguiente código escribe el conjunto de datos transformado en archivos TFRecord en la ubicación especificada:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
Leer, transformar y escribir datos de evaluación
Después de transformar los datos de entrenamiento y producir el gráfico transform_fn , puede usarlo para transformar los datos de evaluación. Primero, lee y limpia los datos de evaluación de BigQuery usando la función read_from_bq descrita anteriormente en Leer datos de entrenamiento sin procesar de BigQuery y pasando un valor de eval para el parámetro step . Luego, utiliza el siguiente código para transformar el conjunto de datos de evaluación sin procesar ( raw_dataset ) al formato transformado esperado ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
Cuando transforma los datos de evaluación, solo se aplican operaciones a nivel de instancia, utilizando tanto la lógica del gráfico transform_fn como las estadísticas calculadas a partir de la fase de análisis en los datos de entrenamiento. En otras palabras, no se analizan los datos de evaluación de forma completa para calcular nuevas estadísticas, como la media y la varianza para la normalización de puntuación z de características numéricas en los datos de evaluación. En su lugar, utiliza las estadísticas calculadas a partir de los datos de entrenamiento para transformar los datos de evaluación a nivel de instancia.
Por lo tanto, se utiliza el método AnalyzeAndTransform en el contexto de datos de entrenamiento para calcular las estadísticas y transformar los datos. Al mismo tiempo, se utiliza el método TransformDataset en el contexto de transformar datos de evaluación para transformar solo los datos utilizando las estadísticas calculadas en los datos de entrenamiento.
Luego, escribe los datos en un receptor (Cloud Storage o disco local, según el corredor) en el formato TFRecord para evaluar el modelo de TensorFlow durante el proceso de entrenamiento. Para hacer esto, use la función write_tfrecords que se analiza en Escribir datos de entrenamiento transformados . El siguiente diagrama, figura 3, muestra cómo se utiliza el gráfico transform_fn que se produce en la fase de análisis de los datos de entrenamiento para transformar los datos de evaluación.

transform_fn .guardar el gráfico
Un paso final en la canalización de preprocesamiento tf.Transform es almacenar los artefactos, que incluye el gráfico transform_fn que se produce en la fase de análisis de los datos de entrenamiento. El código para almacenar los artefactos se muestra en la siguiente función write_transform_artefacts :
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
Estos artefactos se utilizarán más adelante para entrenar modelos y exportarlos para su publicación. También se producen los siguientes artefactos, como se muestra en la siguiente sección:
-
saved_model.pb: representa el gráfico de TensorFlow que incluye la lógica de transformación (el gráficotransform_fn), que se adjuntará a la interfaz de servicio del modelo para transformar los puntos de datos sin procesar al formato transformado. -
variables: incluye las estadísticas calculadas durante la fase de análisis de los datos de entrenamiento y se utiliza en la lógica de transformación en el artefactosaved_model.pb. -
assets: incluye archivos de vocabulario, uno para cada característica categórica procesada con el métodocompute_and_apply_vocabulary, que se usará durante la publicación para convertir un valor nominal bruto de entrada en un índice numérico. -
transformed_metadata: un directorio que contiene el archivoschema.jsonque describe el esquema de los datos transformados.
Ejecute la canalización en Dataflow
Después de definir la canalización tf.Transform , ejecuta la canalización mediante Dataflow. El siguiente diagrama, figura 4, muestra el gráfico de ejecución de Dataflow de la canalización tf.Transform descrita en el ejemplo.
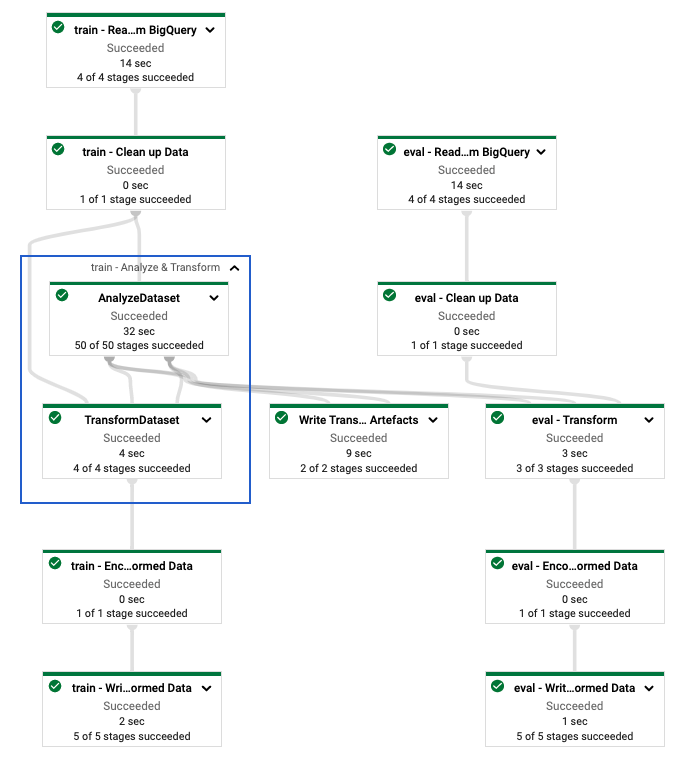
tf.Transform . Después de ejecutar la canalización de Dataflow para preprocesar los datos de entrenamiento y evaluación, puede explorar los objetos producidos en Cloud Storage ejecutando la última celda del cuaderno. Los fragmentos de código de esta sección muestran los resultados, donde YOUR_BUCKET_NAME es el nombre de su depósito de Cloud Storage.
Los datos de entrenamiento y evaluación transformados en formato TFRecord se almacenan en la siguiente ubicación:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
Los artefactos de transformación se producen en la siguiente ubicación:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
La siguiente lista es el resultado de la canalización y muestra los objetos y artefactos de datos producidos:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
Implementar el modelo TensorFlow
Esta sección y la siguiente, Entrenar y usar el modelo para predicciones , brindan una descripción general y un contexto para el Cuaderno 2. El cuaderno proporciona un modelo de aprendizaje automático de ejemplo para predecir el peso de los bebés. En este ejemplo, se implementa un modelo de TensorFlow utilizando la API de Keras. El modelo utiliza los datos y artefactos producidos por la canalización de preprocesamiento tf.Transform explicada anteriormente.
Ejecute el cuaderno 2
En la interfaz de JupyterLab, haga clic en Archivo > Abrir desde ruta y luego ingrese la siguiente ruta:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbHaga clic en Editar > Borrar todas las salidas .
En la sección Instalar paquetes requeridos , ejecute la primera celda para ejecutar el comando
pip install tensorflow-transform.La última parte del resultado es la siguiente:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.Puede ignorar los errores de dependencia en la salida.
En el menú Kernel , seleccione Reiniciar Kernel .
Ejecute las celdas en las secciones Confirmar los paquetes instalados y Crear setup.py para instalar paquetes en contenedores de Dataflow .
En la sección Establecer indicadores globales , junto a
PROJECTyBUCKET, reemplaceyour-projectcon su ID de proyecto en la nube y luego ejecute la celda.Ejecute todas las celdas restantes hasta la última celda del cuaderno. Para obtener información sobre qué hacer en cada celda, consulte las instrucciones en el cuaderno.
Descripción general de la creación del modelo.
Los pasos para crear el modelo son los siguientes:
- Cree columnas de características utilizando la información del esquema que se almacena en el directorio
transformed_metadata. - Cree el modelo amplio y profundo con la API de Keras utilizando las columnas de características como entrada al modelo.
- Cree la función
tfrecords_input_fnpara leer y analizar los datos de entrenamiento y evaluación utilizando los artefactos de transformación. - Entrenar y evaluar el modelo.
- Exporte el modelo entrenado definiendo una función
serving_fnque tenga adjunto el gráficotransform_fn. - Inspeccione el modelo exportado utilizando la herramienta
saved_model_cli. - Utilice el modelo exportado para la predicción.
Este documento no explica cómo construir el modelo, por lo que no analiza en detalle cómo se construyó o entrenó el modelo. Sin embargo, las siguientes secciones muestran cómo la información almacenada en el directorio transform_metadata , que se produce mediante el proceso tf.Transform , se utiliza para crear las columnas de características del modelo. El documento también muestra cómo el gráfico transform_fn , que también se produce mediante el proceso tf.Transform , se utiliza en la función serving_fn cuando el modelo se exporta para su publicación.
Utilice los artefactos de transformación generados en el entrenamiento de modelos.
Cuando entrenas el modelo de TensorFlow, utilizas los objetos train y eval transformados producidos en el paso anterior de procesamiento de datos. Estos objetos se almacenan como archivos fragmentados en formato TFRecord. La información del esquema en el directorio transformed_metadata generado en el paso anterior puede ser útil para analizar los datos (objetos tf.train.Example ) para introducirlos en el modelo para entrenamiento y evaluación.
Analizar los datos
Debido a que lee archivos en formato TFRecord para alimentar el modelo con datos de entrenamiento y evaluación, necesita analizar cada objeto tf.train.Example en los archivos para crear un diccionario de características (tensores). Esto garantiza que las características se asignan a la capa de entrada del modelo mediante las columnas de características, que actúan como la interfaz de evaluación y entrenamiento del modelo. Para analizar los datos, utiliza el objeto TFTransformOutput que se crea a partir de los artefactos generados en el paso anterior:
Cree un objeto
TFTransformOutputa partir de los artefactos que se generan y guardan en el paso de preprocesamiento anterior, como se describe en la sección Guardar el gráfico :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Extraiga un objeto
feature_specdel objetoTFTransformOutput:tf_transform_output.transformed_feature_spec()Utilice el objeto
feature_specpara especificar las características contenidas en el objetotf.train.Examplecomo en la funcióntfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
Crear las columnas de características
La canalización produce la información del esquema en el directorio transformed_metadata que describe el esquema de los datos transformados que espera el modelo para entrenamiento y evaluación. El esquema contiene el nombre de la característica y el tipo de datos, como los siguientes:
-
gestation_weeks_scaled(tipo:FLOAT) -
is_male_index(tipo:INT, is_categorical:True) -
is_multiple_index(tipo:INT, is_categorical:True) -
mother_age_bucketized(tipo:INT, is_categorical:True) -
mother_age_log(tipo:FLOAT) -
mother_age_normalized(tipo:FLOAT) -
mother_race_index(tipo:INT, is_categorical:True) -
weight_pounds(tipo:FLOAT)
Para ver esta información, utilice los siguientes comandos:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
El siguiente código muestra cómo se utiliza el nombre de la característica para crear columnas de características:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
El código crea una columna tf.feature_column.numeric_column para funciones numéricas y una columna tf.feature_column.categorical_column_with_identity para funciones categóricas.
También puede crear columnas de funciones extendidas, como se describe en Opción C: TensorFlow en la primera parte de esta serie. En el ejemplo utilizado para esta serie, se crea una nueva característica, mother_race_X_mother_age_bucketized , cruzando las características mother_race y mother_age_bucketized usando la columna de características tf.feature_column.crossed_column . La representación densa y de baja dimensión de esta característica cruzada se crea utilizando la columna de características tf.feature_column.embedding_column .
El siguiente diagrama, figura 5, muestra los datos transformados y cómo se utilizan los metadatos transformados para definir y entrenar el modelo de TensorFlow:

Exportar el modelo para servir la predicción.
Después de entrenar el modelo de TensorFlow con la API de Keras, exporta el modelo entrenado como un objeto SavedModel, para que pueda servir nuevos puntos de datos para la predicción. Cuando exporta el modelo, debe definir su interfaz, es decir, el esquema de características de entrada que se espera durante la entrega. Este esquema de características de entrada se define en la función serving_fn , como se muestra en el siguiente código:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
Durante la publicación, el modelo espera los puntos de datos en su forma sin procesar (es decir, características sin procesar antes de las transformaciones). Por lo tanto, la función serving_fn recibe las características sin procesar y las almacena en un objeto features como un diccionario de Python. Sin embargo, como se analizó anteriormente, el modelo entrenado espera los puntos de datos en el esquema transformado. Para convertir las características sin procesar en los objetos transformed_features que espera la interfaz del modelo, aplique el gráfico transform_fn guardado al objeto features con los siguientes pasos:
Cree el objeto
TFTransformOutputa partir de los artefactos generados y guardados en el paso de preprocesamiento anterior:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)Cree un objeto
TransformFeaturesLayera partir del objetoTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()Aplique el gráfico
transform_fnusando el objetoTransformFeaturesLayer:transformed_features = model.tft_layer(features)
El siguiente diagrama, figura 6, ilustra el paso final de exportar un modelo para servir:

transform_fn adjunto. Entrene y utilice el modelo para predicciones.
Puedes entrenar el modelo localmente ejecutando las celdas del cuaderno. Para ver ejemplos de cómo empaquetar el código y entrenar su modelo a escala usando Vertex AI Training, consulte los ejemplos y las guías en el repositorio de GitHub de Google Cloud cloudml-samples .
Cuando inspecciona el objeto SavedModel exportado usando la herramienta saved_model_cli , ve que los elementos inputs de la definición de firma signature_def incluyen las características sin procesar, como se muestra en el siguiente ejemplo:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
Las celdas restantes del cuaderno le muestran cómo usar el modelo exportado para una predicción local y cómo implementar el modelo como un microservicio usando Vertex AI Prediction. Es importante resaltar que el punto de datos de entrada (muestra) está en el esquema sin formato en ambos casos.
Limpiar
Para evitar incurrir en cargos adicionales en su cuenta de Google Cloud por los recursos utilizados en este tutorial, elimine el proyecto que contiene los recursos.
Eliminar el proyecto
En la consola de Google Cloud, vaya a la página Administrar recursos .
En la lista de proyectos, seleccione el proyecto que desea eliminar y luego haga clic en Eliminar .
En el cuadro de diálogo, escriba el ID del proyecto y luego haga clic en Apagar para eliminar el proyecto.
¿Qué sigue?
- Para conocer los conceptos, los desafíos y las opciones del preprocesamiento de datos para el aprendizaje automático en Google Cloud, consulte el primer artículo de esta serie, Preprocesamiento de datos para ML: opciones y recomendaciones .
- Para obtener más información sobre cómo implementar, empaquetar y ejecutar una canalización tf.Transform en Dataflow, consulte el ejemplo Predicción de ingresos con conjunto de datos del censo .
- Realice la especialización de Coursera en ML con TensorFlow en Google Cloud .
- Conozca las mejores prácticas para la ingeniería de ML en Rules of ML .
- Para obtener más arquitecturas de referencia, diagramas y mejores prácticas, explore el Centro de arquitectura en la nube .